前言
监控再精准,告警推不到人就是白搭。Prometheus 配 Alertmanager 是云原生监控的经典组合,但 Alertmanager 原生不支持钉钉 Webhook,集成过程中踩坑是常事------消息格式乱、告警发不出去、恢复通知丢失,或者安全配置不当机器人被滥用。生产环境用不起来,等于没装。
解法是 prometheus-webhook-dingtalk,社区验证过的成熟中间件,打通 Prometheus 和钉钉之间的最后一公里。这篇就讲完整的链路:钉钉机器人创建、webhook 中间件部署、Alertmanager 路由策略、消息模板优化,全部生产级别可直接跑通。

1.为什么将Prometheus告警推送到钉钉?
将Prometheus告警推送到钉钉,不仅是技术集成的一步,更是提升团队运维效率与系统可靠性的关键实践。以下是几个核心原因:
- 告警触达更及时,响应更迅速
钉钉作为国内企业广泛使用的即时通讯工具,几乎全员在线、消息必达。将告警直接推送至运维群或值班群,能确保问题在第一时间被看到,大幅缩短MTTR,避免小故障演变为大事故。
- 统一告警入口,避免信息碎片化
传统方式可能依赖邮件、短信、Slack等多种渠道,容易造成告警分散、遗漏或重复处理。通过钉钉集中接收所有Prometheus告警,团队可在一个平台完成告警确认、讨论与协同处置,提升协作效率。
- 支持富文本与结构化展示,信息更清晰
借助prometheus-webhook-dingtalk等中间件,告警消息可渲染为卡片式富文本,清晰展示:
- 告警名称(如HighCPUUsage)
- 严重等级(critical / warning)
- 故障实例(instance=192.168.1.10:9100)
- 触发时间与持续时长
- 快速跳转链接(直达 Grafana或Prometheus UI)
相比纯文本邮件,钉钉消息一目了然,减少信息解读成本。
- 低成本、高可用的告警通道
相比短信或电话告警,钉钉推送零成本、无额度限制,且依托阿里云基础设施,服务稳定可靠。对于大多数非P0级别告警,钉钉是性价比极高的通知渠道。
2.前提条件
-
本机已经部署prometheus和alertmanager
-
具备一个可用的钉钉群,并拥有管理员权限
-
可创建钉钉自定义机器人
-
部署节点具备外网访问能力
-
Alertmanager与webhook服务网络互通
- Alertmanager所在主机必须能通过HTTP/HTTPS访问prometheus-webhook-dingtalk服务的地址
- 若两者部署在同一主机,注意Docker网络隔离问题(避免使用127.0.0.1,建议用宿主机IP或Docker自定义网络)。
- 安装必要工具(用于部署与调试)
-
Docker(推荐方式部署webhook服务)或systemd(二进制部署)
-
curl / jq(用于测试API和解析JSON)
-
文本编辑器(如vim、nano)用于编写配置文件
示例:检查Docker是否安装
shell
docker --version3.prometheus配置alertmanager
进入到prometheus配置文件,编辑配置文件,按照如图设置:
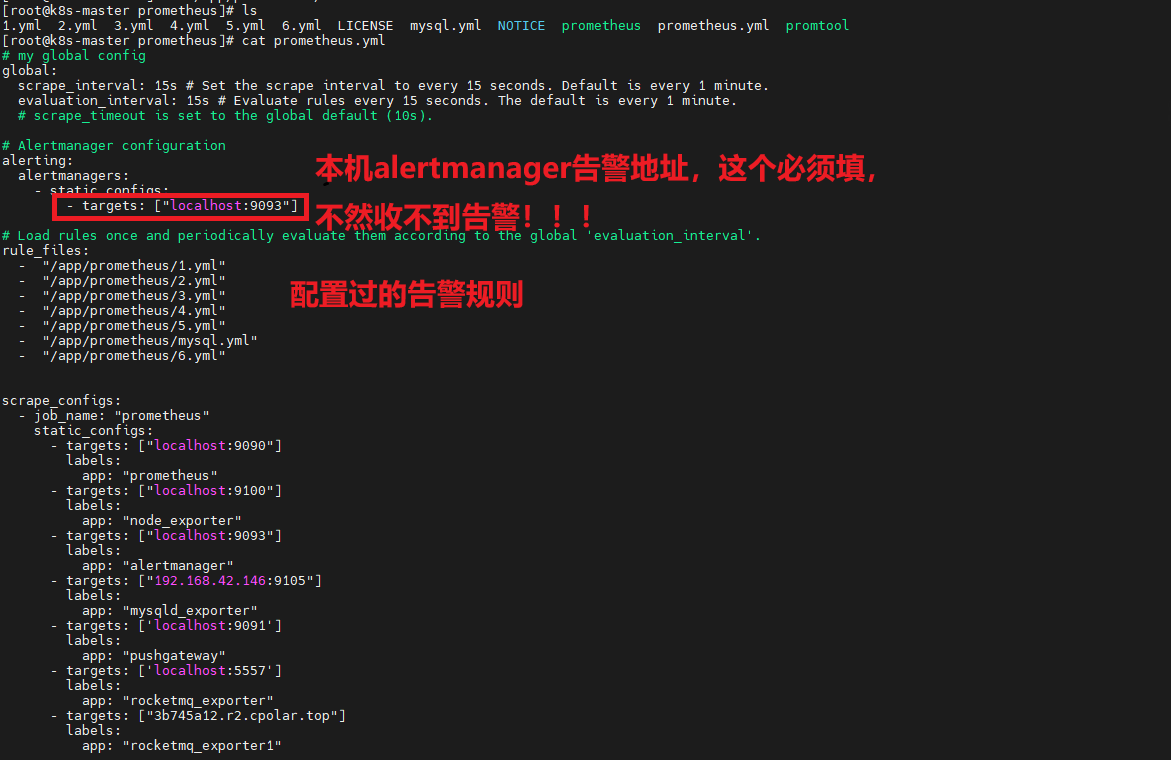
编辑后,重启prometheus:
shell
systemctl restart prometheus4.获取钉钉Webhook URL
打开钉钉群 → 点击右上角设置:
找到智能群助手 → 添加机器人:
添加自定义机器人:
点击添加:
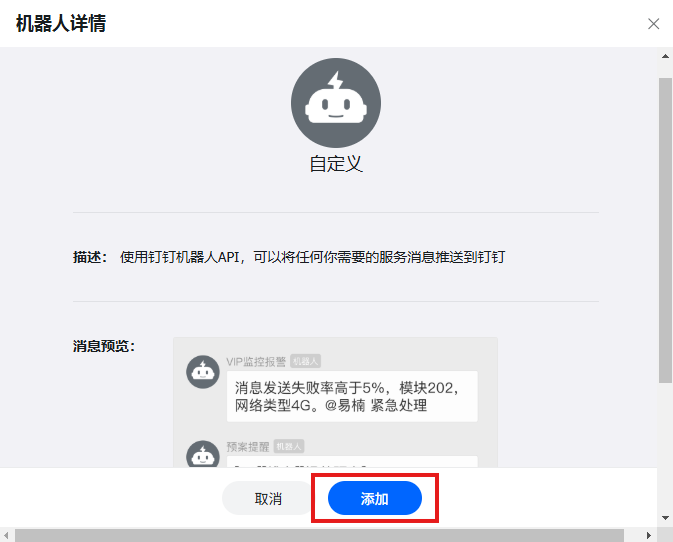
给机器人起个名字,我这里是"prometheus告警":
设置发消息关键词,因为现在钉钉对安全严格,所以需要设置限制,,也可以设置加签或者IP地址:
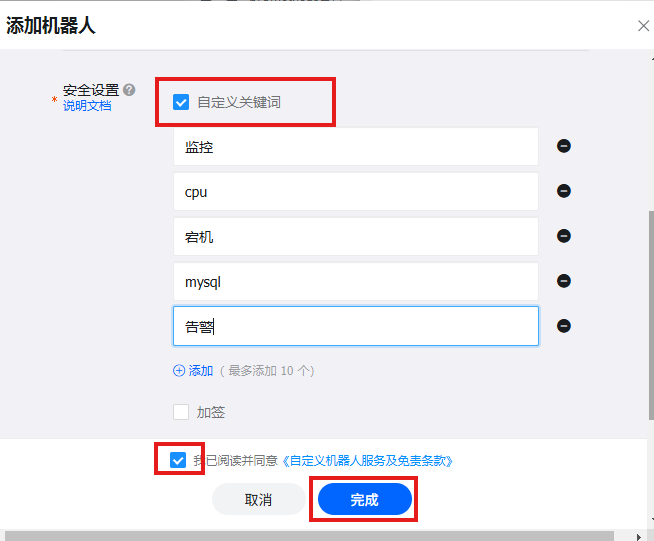
点击完成后,复制生成的Webhook,留着备用:
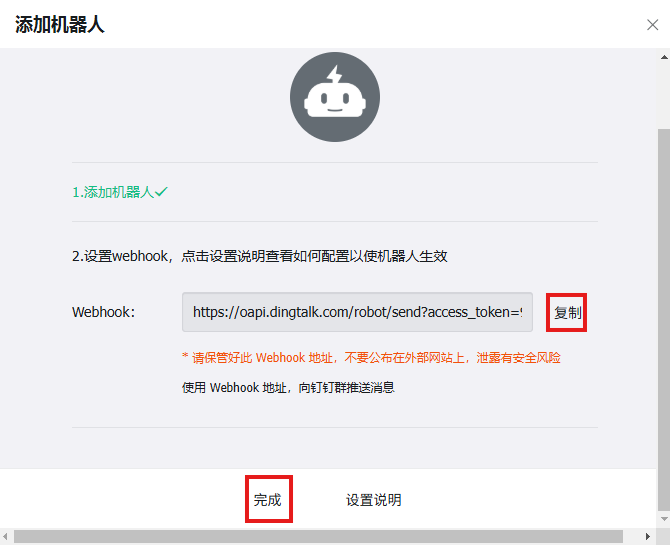
5.部署prometheus-webhook-dingtalk服务
创建配置文件dingtalk.yaml:
shell
cat > dingtalk.yaml <<EOF
targets:
webhook1:
url: https://oapi.dingtalk.com/robot/send?access_token=你的_access_token
EOF启动容器(假设配置文件在当前目录):
shell
docker run -d \
--name dingtalk-webhook \
-p 8060:8060 \
-v $(pwd)/dingtalk.yaml:/etc/prometheus-webhook-dingtalk/config.yml \
--restart always \
timonwong/prometheus-webhook-dingtalk:latest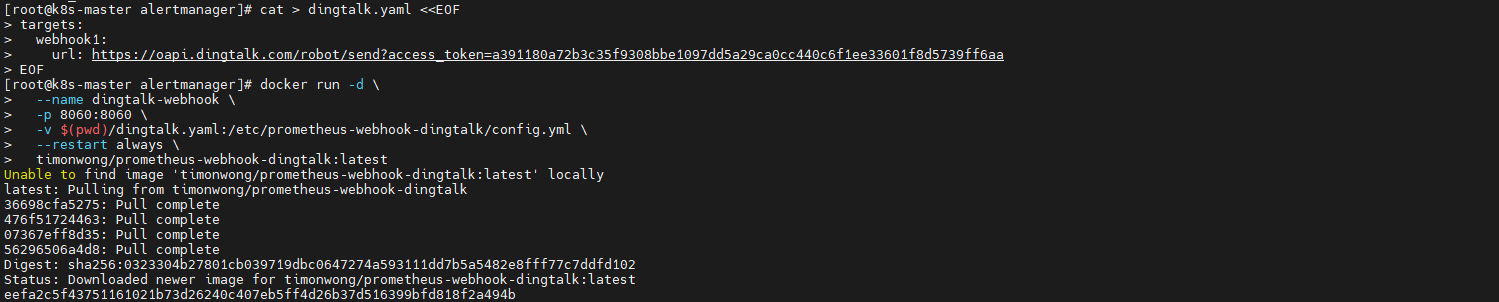
6.配置Alertmanager告警
配置Alertmanager配置文件,配置到告警自动发送到钉钉:
shell
vi alertmanager.yml
shell
global:
resolve_timeout: 2m
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 1h
receiver: 'dingtalk-webhook'
receivers:
- name: 'dingtalk-webhook'
webhook_configs:
- url: 'http://<你的服务器IP> :8060/dingtalk/webhook1/send'
send_resolved: true
shell
systemctl restart alertmanager替换 <你的服务器IP> 为运行prometheus-webhook-dingtalk的主机IP(如果是本机且Alertmanager也在本机,可用127.0.0.1,但注意Docker网络)

告警成功!
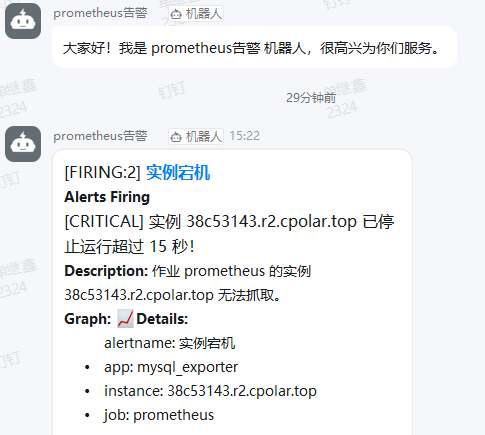
7.告警多个钉钉群(拓展)
配置多个钉钉群告警,是为了实现告警的精准投递与职责分离------让不同团队(如运维、开发、安全)只接收与其相关的告警,避免信息过载,提升响应效率,并支持告警分级、环境隔离和故障升级等高级运维场景,从而构建高效、可靠、可扩展的监控告警体系。
获取另一个群的webhook(步骤和第4章节一致)。
配置文件dingtalk.yaml,添加两个钉钉群链接:
shell
vi dingtalk.yaml
shell
targets:
ops-team:
url: https://oapi.dingtalk.com/robot/send?access_token=a391180a72b3c35f9308bbe1097dd5a29ca0cc440c6f1ee33601f8d5739ff6aa
secret: secret1
dev-team:
url: https://oapi.dingtalk.com/robot/send?access_token=3e373b6623264d1c71098acde924328d0e16753820a17475aa95bd6655111e04
secret: secret2启动docker容器:
shell
docker run -d \
--name dingtalk-webhook \
-p 8060:8060 \
-v $(pwd)/dingtalk.yaml:/etc/prometheus-webhook-dingtalk/config.yml \
--restart always \
timonwong/prometheus-webhook-dingtalk:latest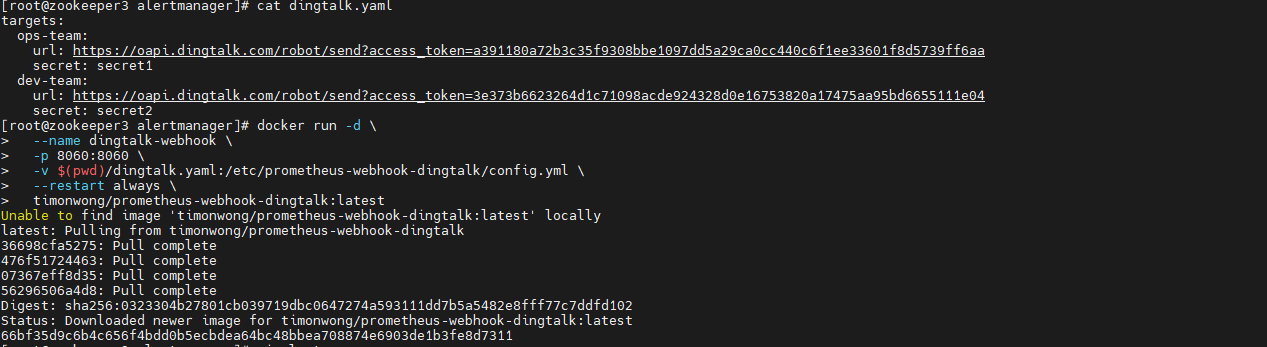
配置Alertmanager的alertmanager.yml:
shell
vi alertmanager.yml
shell
global:
resolve_timeout: 2m
# 主路由:所有告警走这个路径
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 1h
receiver: 'broadcast' # ← 指向一个组合 receiver
# 定义 receivers
receivers:
- name: 'broadcast'
webhook_configs:
# 发给 ops 钉钉群
- url: 'http://<你的服务器IP>/dingtalk/ops-team/send'
send_resolved: true
# 发给 dev 钉钉群
- url: 'http://<你的服务器IP>/dingtalk/dev-team/send'
send_resolved: true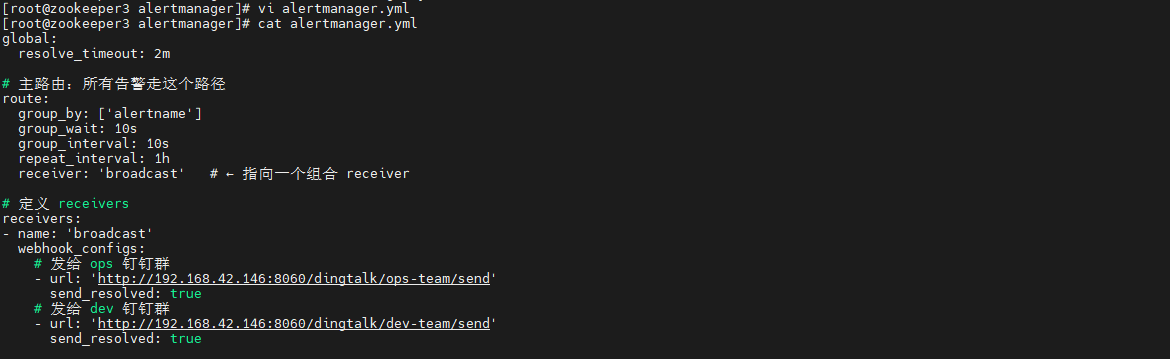
配置完成后,重启alertmanager服务:
shell
systemctl restart alertmanager
等响应一会就可以在两个群聊中都看见告警啦!
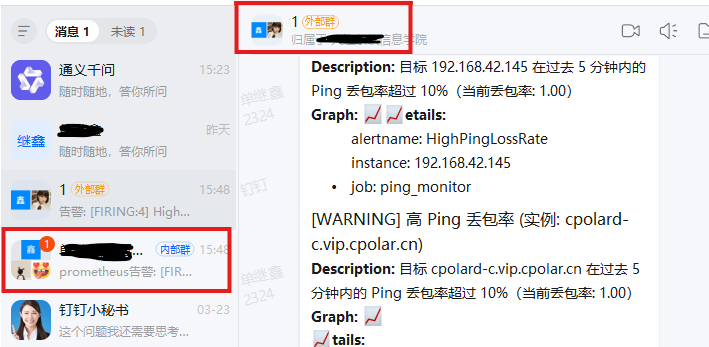
在典型的云原生监控架构中,Prometheus负责采集指标并触发告警规则,而Alertmanager则运行在独立节点上,专职处理告警的去重、分组与通知。然而,在实际部署中,我们常常面临一个现实挑战:Prometheus与Alertmanager并不在同一个局域网内------例如,Prometheus部署在企业内网或私有云环境中,而Alertmanager可能托管在另一台隔离的服务器、边缘节点,甚至临时调试机上。
由于内网环境通常无法被外部直接访问,Prometheus默认通过HTTP向 http://:9093/api/v1/alerts 推送告警时,会因网络不通而失败,导致"告警静默",严重削弱监控系统的可靠性。此时,我们需要一种安全、轻量且无需复杂网络配置(如公网IP、端口映射、NAT穿透或 VPN)的方式来打通内外网通信。内网穿透工具Cpolar正是为此而生------它能将Alertmanager所在内网的服务,通过加密隧道暴露到公网,生成一个临时或固定的公网地址,让Prometheus无论身处何地,都能稳定推送告警。接下来,我们将演示如何借助Cpolar,轻松实现跨网络的Prometheus-Alertmanager告警链路。
8.安装cpolar实现随时随地开发
8.1 什么是cpolar?
cpolar是一款安全高效的内网穿透工具,无需公网IP或复杂配置,只需一条命令,即可将本地服务器、Web服务或任意端口映射到公网,让你随时随地远程访问内网应用,特别适合开发调试、远程运维和应急部署等场景。
8.2 部署cpolar
cpolar 可以将你本地电脑中的服务(如 SSH、Web、数据库)映射到公网。即使你在家里或外出时,也可以通过公网地址连接回本地运行的开发环境。
❤️以下是安装cpolar步骤:
使用一键脚本安装命令:
shell
sudo curl https://get.cpolar.sh | sh
安装完成后,执行下方命令查看cpolar服务状态:(如图所示即为正常启动)
shell
sudo systemctl status cpolar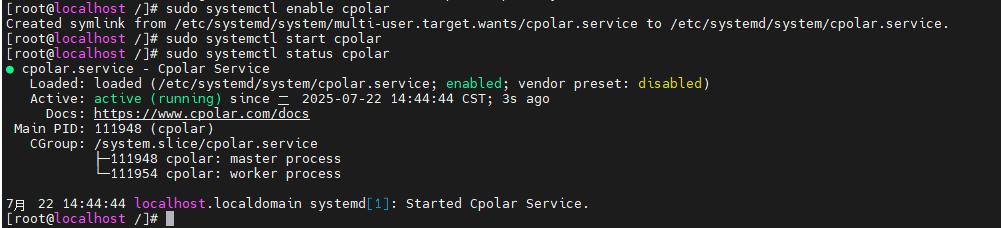
Cpolar安装和成功启动服务后,在浏览器上输入虚拟机主机IP加9200端口即:【http://ip:9200】访问Cpolar管理界面,使用Cpolar官网注册的账号登录,登录后即可看到cpolar web 配置界面,接下来在web 界面配置即可:
打开浏览器访问本地9200端口,使用cpolar账户密码登录即可,登录后即可对隧道进行管理。
9.配置公网地址
通过配置,你可以在本地WSL或Linux系统上运行SSH服务,并通过Cpolar将其映射到公网,从而实现从任意设备远程连接开发环境的目的。
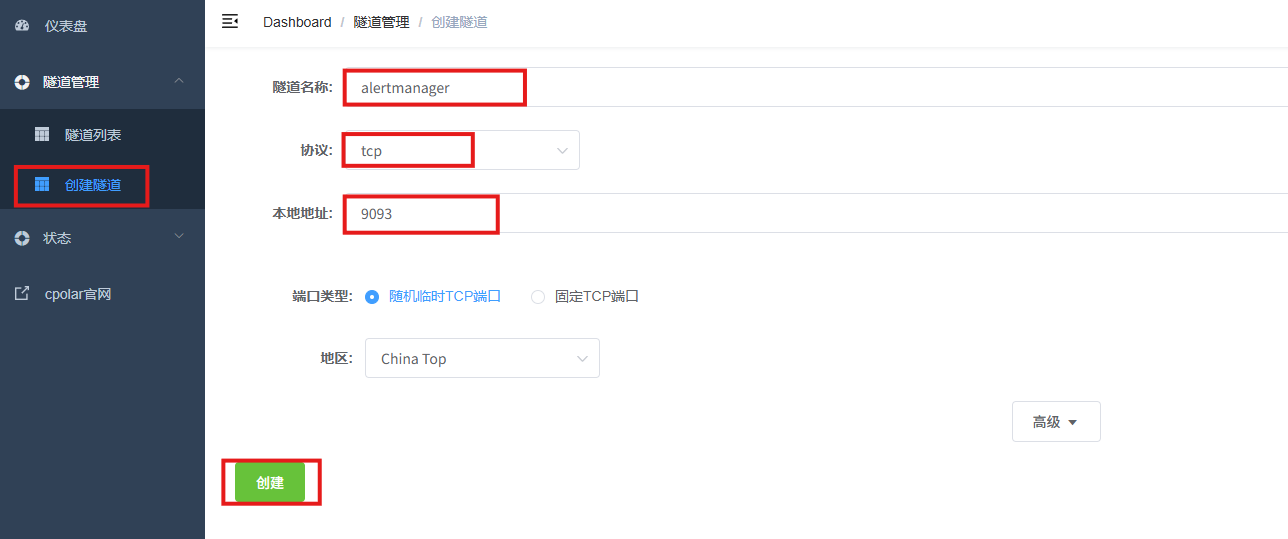
- 隧道名称:可自定义,本例使用了:alertmanager,注意不要与已有的隧道名称重复
- 协议:tcp
- 本地地址:9093
- 端口类型:随机临时TCP端口
- 地区:China Top
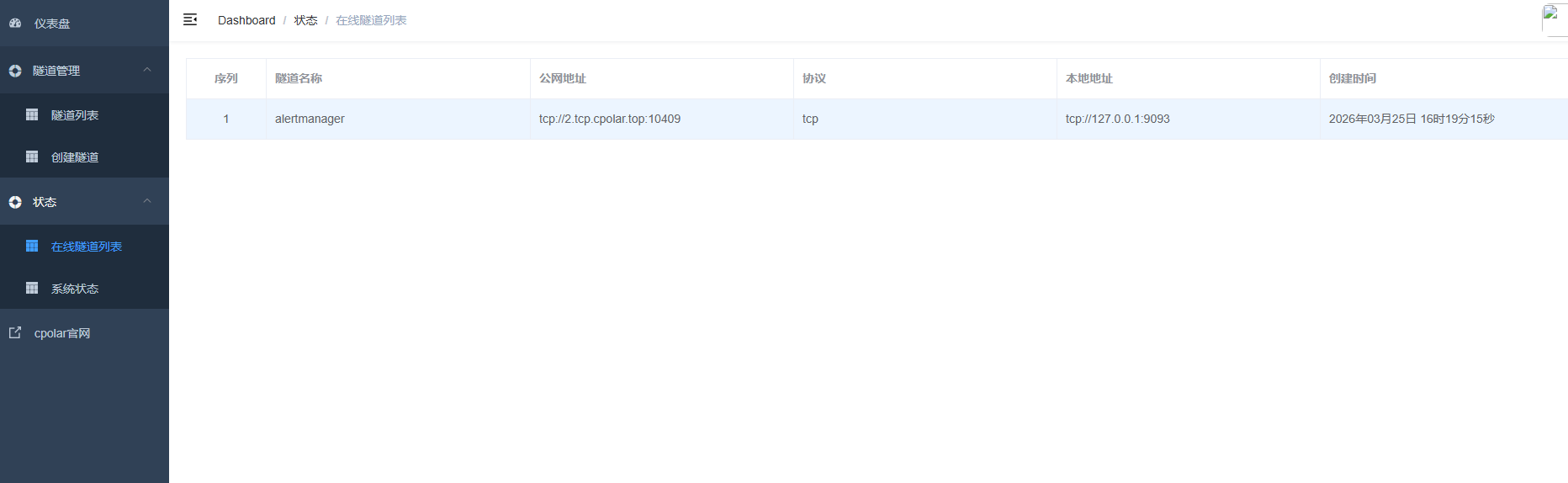
创建成功后,打开左侧在线隧道列表,可以看到刚刚通过创建隧道生成了公网地址,接下来就可以在其他电脑或者移动端设备(异地)上,使用任意一个地址在终端中访问即可。
- tcp 表示使用的协议类型
- 2.tcp.cpolar.top是 Cpolar 提供的域名
- 10409是随机分配的公网端口号
在prometheus上使用不同局域网的alertmanager,修改prometheus的配置文件:
shell
vi prometheus.yml
shell
alerting:
alertmanagers:
- static_configs:
- targets: ["2.tcp.cpolar.top:10409"]
重启服务:
shell
systemctl restart alertmanager重启服务后,钉钉仍在告警:
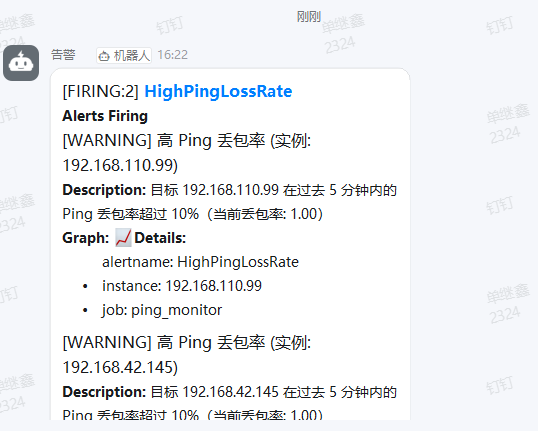
10.保留固定TCP公网地址
使用cpolar为其配置TCP地址,该地址为固定地址,不会随机变化。
选择区域和描述:有一个下拉菜单,当前选择的是"China VIP"。
右侧输入框,用于填写描述信息。
保留按钮:在右侧有一个橙色的"保留"按钮,点击该按钮可以保留所选的TCP地址。
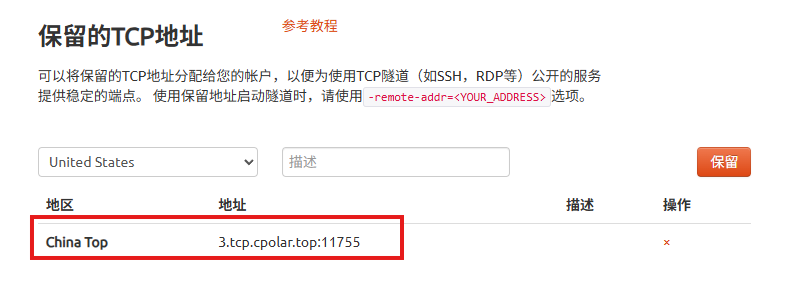
列表中显示了一条已保留的TCP地址记录。
-
地区:显示为"China Top"。
-
地址:显示为"3.tcp.cpolar.top:11755"。
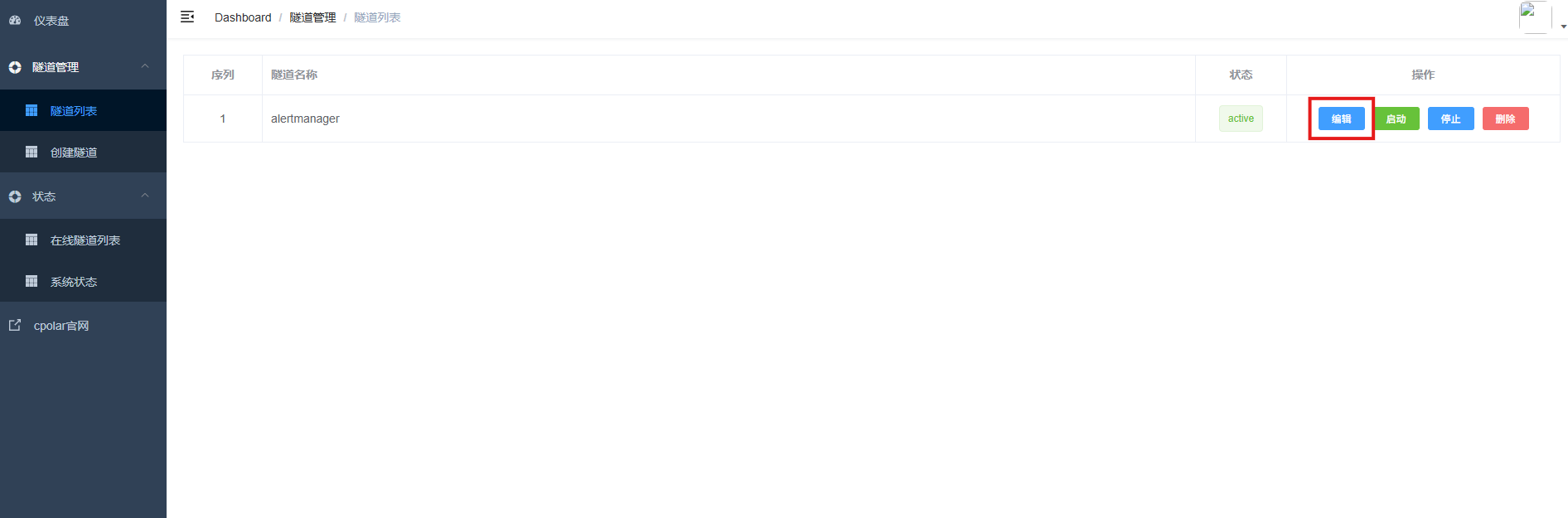
登录cpolar web UI管理界面,点击左侧仪表盘的隧道管理------隧道列表,找到所要配置的隧道ssh,点击右侧的编辑。
修改隧道信息,将保留成功的TCP端口配置到隧道中。
- 端口类型:选择固定TCP端口
- 预留的TCP地址:填写保留成功的TCP地址
点击更新。
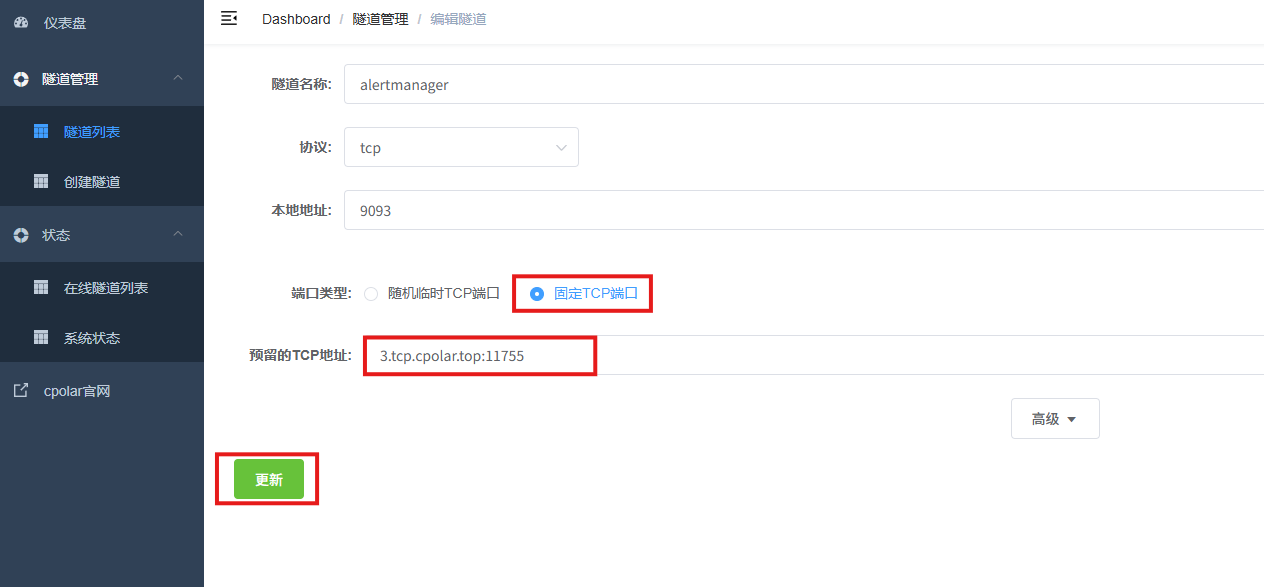
创建完成后,打开在线隧道列表,此时可以看到随机的公网地址已经发生变化,地址名称也变成了保留和固定的TCP地址。
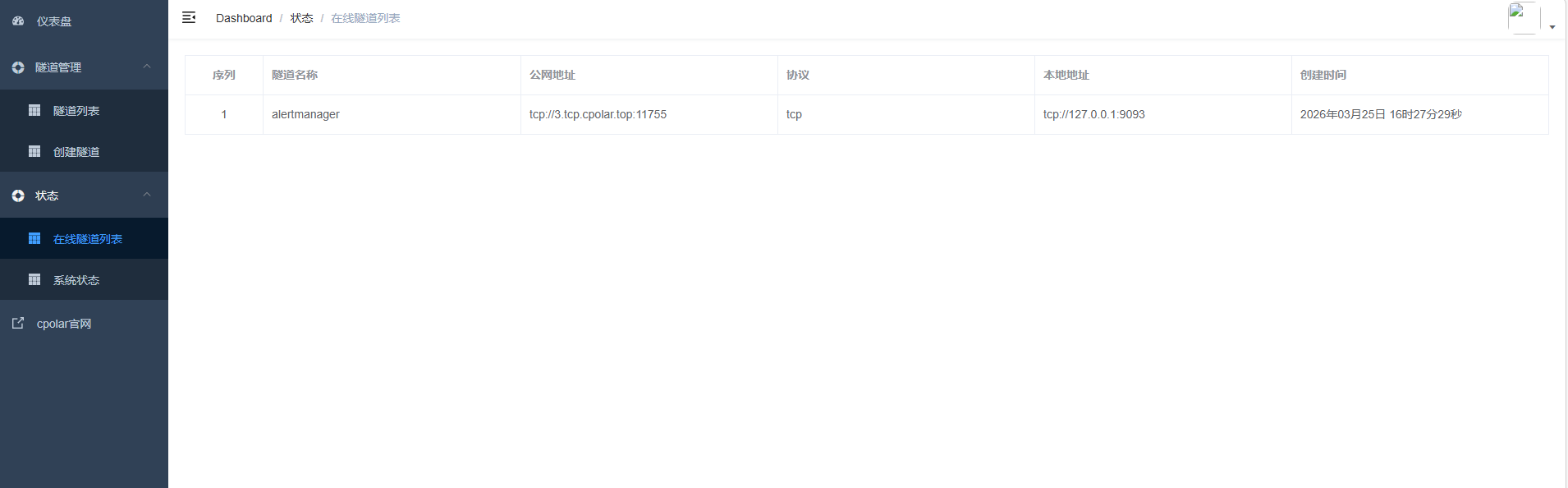
这样我们的TCP地址就固定成功啦!
总结
整套方案跑通之后,Prometheus 的告警才算真正触达责任人------哪个告警、哪台机器、多长时间、跳转到哪个 Grafana 链接,一目了然。不同团队按职责分开发推送,多群分发也好、告警分级也罢,Alertmanager 的路由规则都能兜住。跨网络问题交给 cpolar 固定 TCP 隧道,告警链路稳定不掉线。
运维这件事,不怕出问题,怕的是出了问题没人知道。这套链路建好,告警才真正"响"在该响的地方。