1. 定位导航
分治算法经常会产生递归式。
例如:
text
T(n) = 2T(n/2) + n
T(n) = 2T(n/2) + 1
T(n) = 2T(n/2) + n²这些递归式看起来相似,但结果可能完全不同:
text
O(n log n)
O(n)
O(n²)主方法就是一种快速判断工具。
它不需要每次完整画递归树,而是通过比较两个关键量来判断结果。
2. 概念术语
| 术语 | 含义 | 举例 |
|---|---|---|
| 主方法 | 求解一类分治递归式的快速方法 | T(n)=aT(n/b)+f(n) |
| a | 子问题个数 | 2T(n/2) 中的 2 |
| b | 子问题规模缩小倍数 | T(n/2) 中的 2 |
| f(n) | 分解与合并的额外成本 | 归并排序合并成本 n |
| 基准项 | 递归展开形成的叶子侧规模 | n^(log_b a) |
| 情况 1 | f(n) 比基准项小 | 递归成本主导 |
| 情况 2 | f(n) 与基准项同级 | 每层成本相近 |
| 情况 3 | f(n) 比基准项大 | 合并成本主导 |
关键澄清:
- 主方法不是所有递归式都能用。
- 它主要适用于
T(n)=aT(n/b)+f(n)这种形式。 - 判断关键是比较
f(n)和n^(log_b a)。 - 不要只看
a和b,f(n)经常决定最终结果。
3. 主方法解决哪类问题
主方法适用于形如:
T(n)=aT(n/b)+f(n) T(n) = aT(n/b) + f(n) T(n)=aT(n/b)+f(n)
的递归式。
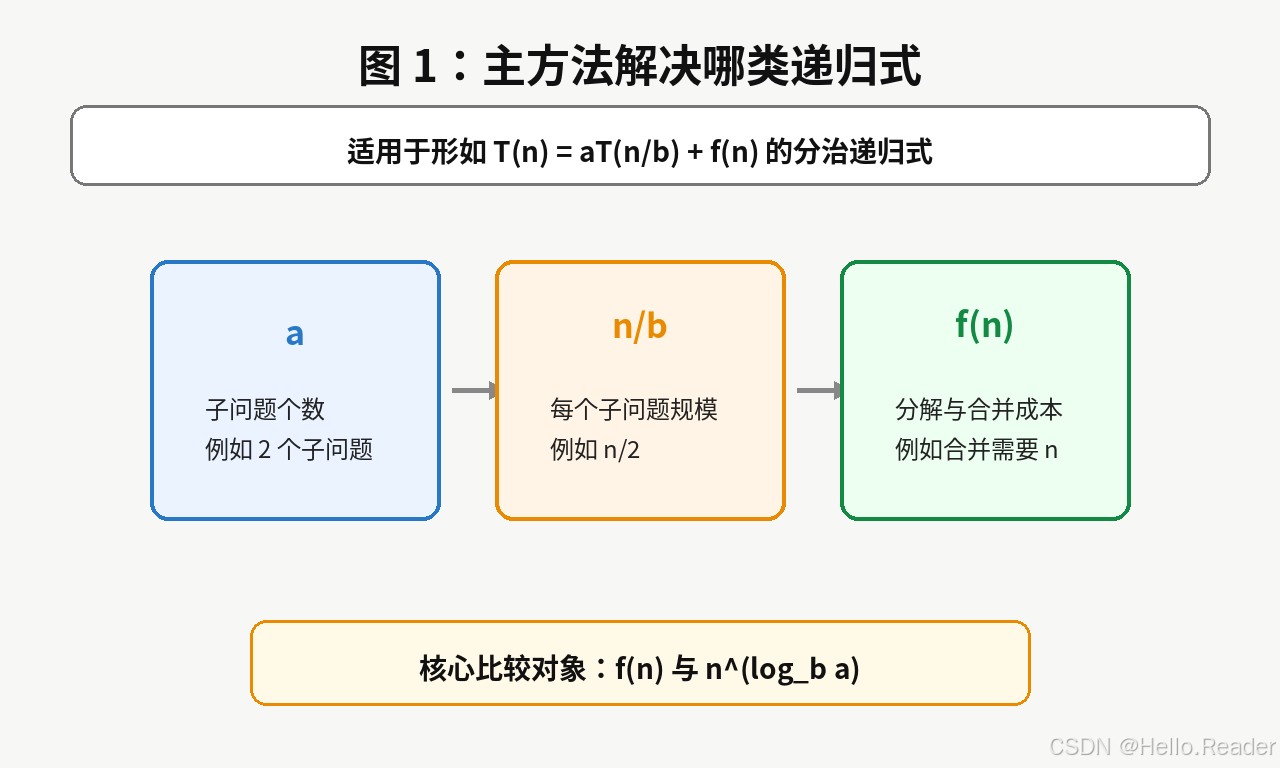
其中:
a表示子问题个数;n/b表示每个子问题的规模;f(n)表示除了递归子问题之外,本层额外做的工作。
比如归并排序:
T(n)=2T(n/2)+n T(n) = 2T(n/2) + n T(n)=2T(n/2)+n
对应关系是:
| 部分 | 值 | 含义 |
|---|---|---|
| a | 2 | 拆成两个子问题 |
| b | 2 | 每个子问题规模是原来一半 |
| f(n) | n | 合并两个有序数组需要线性时间 |
4. 核心比较对象:f(n) 与 n^(log_b a)
主方法最关键的一步是计算:
nlogba n^{\log_b a} nlogba
这个量可以理解为递归树中"子问题扩张出来的基准增长"。
然后比较:
text
f(n) 和 n^(log_b a)谁更强。
以归并排序为例:
T(n)=2T(n/2)+n T(n) = 2T(n/2) + n T(n)=2T(n/2)+n
这里:
a=2,b=2 a = 2,\quad b = 2 a=2,b=2
所以:
nlogba=nlog22=n n^{\log_b a} = n^{\log_2 2} = n nlogba=nlog22=n
而:
f(n)=n f(n) = n f(n)=n
两者同级,所以属于情况 2。
结果是:
T(n)=Θ(nlogn) T(n) = \Theta(n \log n) T(n)=Θ(nlogn)
5. 主方法的三种情况
主方法可以分成三种情况。
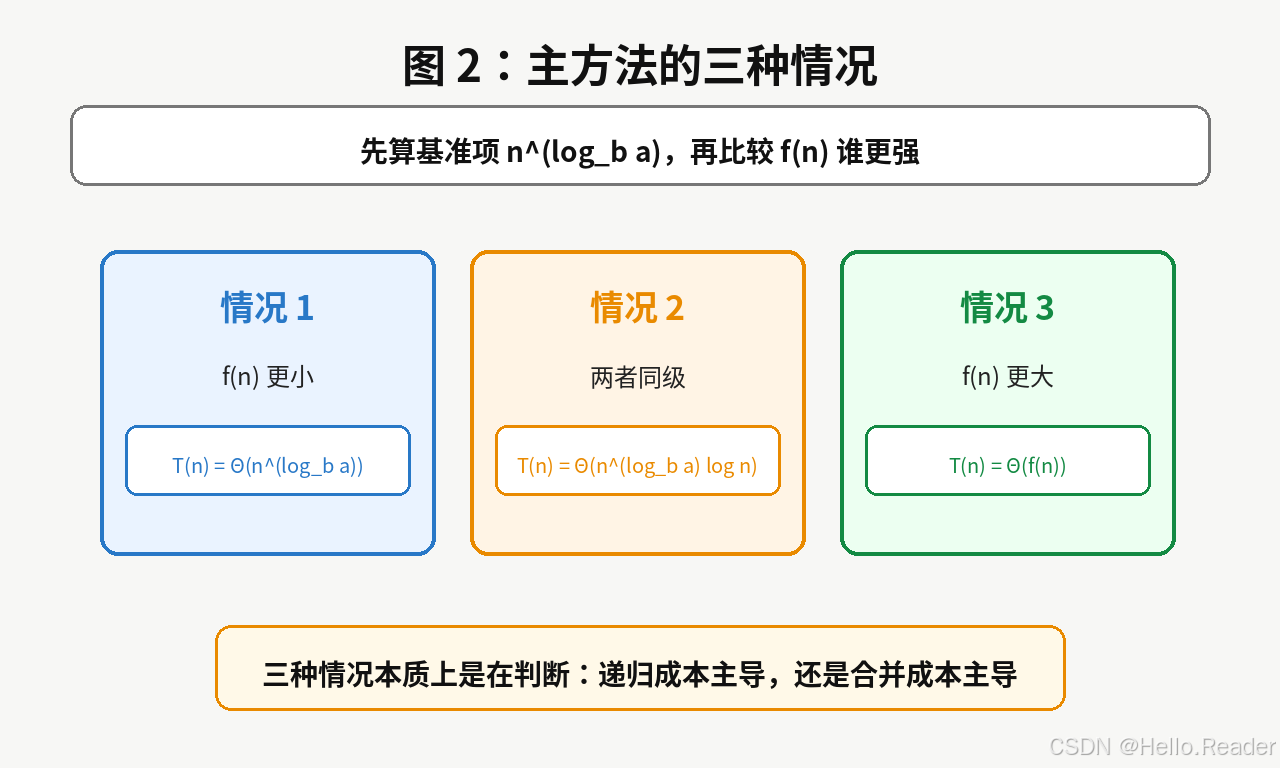
5.1 情况 1:f(n) 更小
如果:
f(n) f(n) f(n)
比:
nlogba n^{\log_b a} nlogba
小一个多项式级别,那么递归成本主导。
结果是:
T(n)=Θ(nlogba) T(n) = \Theta(n^{\log_b a}) T(n)=Θ(nlogba)
直觉:
text
越往下递归,子问题数量增长带来的成本更重要。5.2 情况 2:f(n) 与基准项同级
如果:
f(n)=Θ(nlogba) f(n) = \Theta(n^{\log_b a}) f(n)=Θ(nlogba)
那么每一层贡献差不多。
结果是:
T(n)=Θ(nlogbalogn) T(n) = \Theta(n^{\log_b a} \log n) T(n)=Θ(nlogbalogn)
直觉:
text
每一层都差不多,总共约 log n 层,所以多乘一个 log n。5.3 情况 3:f(n) 更大
如果:
f(n) f(n) f(n)
比:
nlogba n^{\log_b a} nlogba
大一个多项式级别,并且满足一定的正则条件,那么本层额外工作主导。
结果是:
T(n)=Θ(f(n)) T(n) = \Theta(f(n)) T(n)=Θ(f(n))
直觉:
text
上层合并成本已经足够大,递归子问题反而不是主导。6. 动态推演:三种情况如何判断
下面用动态图观察三种关系。

可以这样理解:
- 情况 1:
f(n)比基准项更小,递归展开更重要; - 情况 2:
f(n)和基准项同级,每层成本接近; - 情况 3:
f(n)比基准项更大,当前层工作更重要。
7. 典型例子
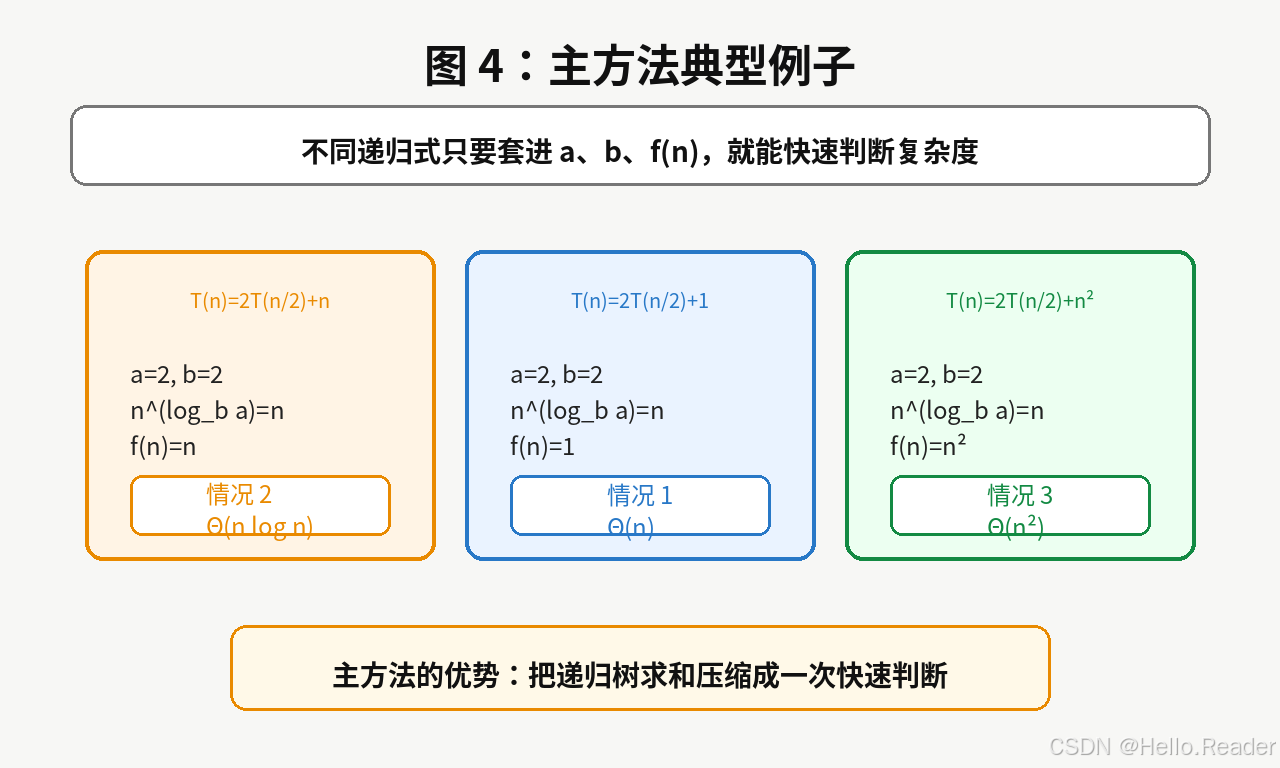
7.1 例子一:T(n)=2T(n/2)+n
这里:
a=2,b=2,f(n)=n a=2,\quad b=2,\quad f(n)=n a=2,b=2,f(n)=n
基准项:
nlog22=n n^{\log_2 2}=n nlog22=n
f(n) 和基准项同级,属于情况 2。
所以:
T(n)=Θ(nlogn) T(n)=\Theta(n\log n) T(n)=Θ(nlogn)
7.2 例子二:T(n)=2T(n/2)+1
这里:
a=2,b=2,f(n)=1 a=2,\quad b=2,\quad f(n)=1 a=2,b=2,f(n)=1
基准项:
nlog22=n n^{\log_2 2}=n nlog22=n
f(n) 比基准项小,属于情况 1。
所以:
T(n)=Θ(n) T(n)=\Theta(n) T(n)=Θ(n)
7.3 例子三:T(n)=2T(n/2)+n²
这里:
a=2,b=2,f(n)=n2 a=2,\quad b=2,\quad f(n)=n^2 a=2,b=2,f(n)=n2
基准项:
nlog22=n n^{\log_2 2}=n nlog22=n
f(n) 比基准项大,属于情况 3。
所以:
T(n)=Θ(n2) T(n)=\Theta(n^2) T(n)=Θ(n2)
8. 判断流程
使用主方法时,可以按照下面流程来。

第一步:确认递归式形式
先确认是否形如:
T(n)=aT(n/b)+f(n) T(n)=aT(n/b)+f(n) T(n)=aT(n/b)+f(n)
如果形式不匹配,不要硬套。
第二步:计算基准项
计算:
nlogba n^{\log_b a} nlogba
第三步:比较强弱
比较:
text
f(n) 与 n^(log_b a)谁更大、谁更小,或者是否同级。
第四步:套用三种情况
根据比较结果,选择情况 1、情况 2 或情况 3。
9. 代码实践:自动套用简单主方法
下面写一个简单的 Python 小工具,只处理 f(n)=n^k 这种常见形式。
python
import math
def master_method(a, b, k):
"""
处理递归式:
T(n) = aT(n/b) + n^k
参数:
a: 子问题个数
b: 子问题缩小倍数
k: f(n)=n^k 中的 k
"""
critical = math.log(a, b)
print(f"a = {a}, b = {b}, f(n) = n^{k}")
print(f"基准指数 log_b(a) = {critical:.4f}")
if k < critical:
print("情况 1:f(n) 更小")
print(f"T(n) = Θ(n^{critical:.4f})")
elif abs(k - critical) < 1e-9:
print("情况 2:f(n) 与基准项同级")
print(f"T(n) = Θ(n^{critical:.4f} log n)")
else:
print("情况 3:f(n) 更大")
print(f"T(n) = Θ(n^{k})")
master_method(2, 2, 1)
print()
master_method(2, 2, 0)
print()
master_method(2, 2, 2)输出示例:
text
a = 2, b = 2, f(n) = n^1
基准指数 log_b(a) = 1.0000
情况 2:f(n) 与基准项同级
T(n) = Θ(n^1.0000 log n)
a = 2, b = 2, f(n) = n^0
基准指数 log_b(a) = 1.0000
情况 1:f(n) 更小
T(n) = Θ(n^1.0000)
a = 2, b = 2, f(n) = n^2
基准指数 log_b(a) = 1.0000
情况 3:f(n) 更大
T(n) = Θ(n^2)这个工具不是完整的数学证明器,但可以帮助快速建立判断直觉。
10. 常见误区
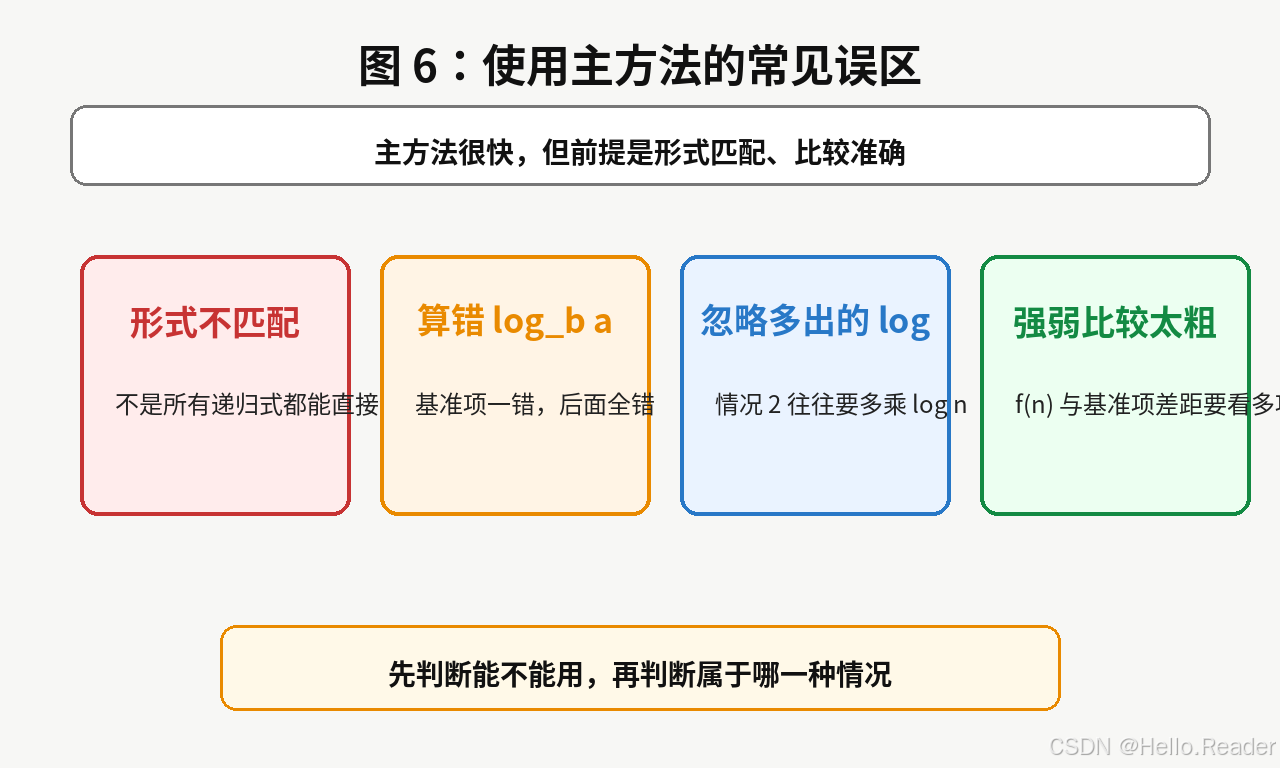
误区一:看到递归式就硬套主方法
不是所有递归式都能直接套。
例如:
text
T(n)=T(n-1)+n它不是 aT(n/b)+f(n) 形式,就不适合直接用这个版本的主方法。
误区二:算错 log_b a
主方法的核心基准项是:
nlogba n^{\log_b a} nlogba
如果这里算错,后面判断都会错。
误区三:忘记情况 2 里的 log n
当:
f(n)=Θ(nlogba) f(n)=\Theta(n^{\log_b a}) f(n)=Θ(nlogba)
结果不是简单的:
Θ(nlogba) \Theta(n^{\log_b a}) Θ(nlogba)
而是:
Θ(nlogbalogn) \Theta(n^{\log_b a}\log n) Θ(nlogbalogn)
误区四:只凭直觉比较大小
比较 f(n) 和基准项时,要看增长量级,不是看某个小规模下的数值。
11. 现代延伸
主方法不仅用于排序,也常用于分析很多分治或递归系统。
| 场景 | 可能出现的递归式 |
|---|---|
| 归并排序 | T(n)=2T(n/2)+n |
| 二分查找 | T(n)=T(n/2)+1 |
| 分治统计 | T(n)=2T(n/2)+n |
| 分块计算 | T(n)=aT(n/b)+f(n) |
| 并行归约 | T(n)=2T(n/2)+1 |
| 多路分治 | T(n)=kT(n/k)+n |
工程里很多"拆分---递归处理---合并"的流程,都可以先写出递归式,再用类似方法估算增长趋势。
比如大文件分块处理、分布式聚合、多级归并、并行任务树,都可以借助这种思路快速判断瓶颈来自哪里。
12. 思考题
- 主方法适用于哪类递归式?
T(n)=2T(n/2)+n为什么是情况 2?T(n)=2T(n/2)+1为什么是情况 1?T(n)=2T(n/2)+n²为什么是情况 3?- 为什么情况 2 的结果要多乘一个
log n? T(n)=3T(n/3)+n的复杂度是多少?
13. 本篇小结
本篇讲清楚了主方法。
核心结论是:
- 主方法用于快速求解
T(n)=aT(n/b)+f(n)类型的递归式; a表示子问题个数;b表示子问题规模缩小倍数;f(n)表示本层额外工作;- 核心比较对象是
f(n)和n^(log_b a); - 情况 1:
f(n)更小,结果看基准项; - 情况 2:两者同级,结果多乘一个
log n; - 情况 3:
f(n)更大,结果看f(n); - 使用前要先确认递归式形式是否匹配。
主方法可以理解成递归树分析的快捷版。
递归树帮你看懂原因,主方法帮你快速得到结果。