目录
-
[0. 环境安装](#0. 环境安装)
- 基础环境安装
- [安装 Transformers 相关库](#安装 Transformers 相关库)
-
[1. Pipeline](#1. Pipeline)
- [1.1 文本分类 Pipeline](#1.1 文本分类 Pipeline)
- [1.2 文本生成 Pipeline](#1.2 文本生成 Pipeline)
- [1.3 问答 Pipeline](#1.3 问答 Pipeline)
- [1.4 Transformers 标准工作流程](#1.4 Transformers 标准工作流程)
-
[2. Tokenizer](#2. Tokenizer)
- [2.1 Tokenizer 流程](#2.1 Tokenizer 流程)
- [2.2 Tokenizer 小结](#2.2 Tokenizer 小结)
-
[3. Model](#3. Model)
- [3.1 加载模型的类](#3.1 加载模型的类)
- [3.2 模型推理](#3.2 模型推理)
- [3.3 Model 小结](#3.3 Model 小结)
-
[4. Config](#4. Config)
- [4.1 查看模型 Config](#4.1 查看模型 Config)
- [4.2 保存和加载 Config](#4.2 保存和加载 Config)
-
[5. Datasets](#5. Datasets)
- [5.1 加载 CSV 数据集](#5.1 加载 CSV 数据集)
- [5.2 数据预处理](#5.2 数据预处理)
-
[6. Evaluate](#6. Evaluate)
- [6.1 accuracy](#6.1 accuracy)
- [6.2 precision、recall 和 F1](#6.2 precision、recall 和 F1)
- [6.3 compute_metrics](#6.3 compute_metrics)
-
[7. Trainer](#7. Trainer)
- [7.1 TrainingArguments](#7.1 TrainingArguments)
- [7.2 训练](#7.2 训练)
- [7.3 模型推理](#7.3 模型推理)
Hugging Face Transformers 是目前使用最广泛的预训练模型工具库之一。它把大量已经训练好的模型统一封装成相似的调用方式,使我们可以用较少的代码完成文本分类、文本生成、问答、摘要、翻译、命名实体识别等任务。
Github 地址:https://github.com/HaoYuanxinn/huggingface_transformers-01basic
本文使用 PyTorch 框架,跑通 Transformers 的核心流程:
使用 pipeline 快速推理
理解 Tokenizer
理解 Model 和 Config
使用 Datasets 加载和处理数据
使用 Evaluate 计算指标
使用 Trainer 训练文本分类模型
保存模型
重新加载模型并推理
0. 环境安装
基础环境安装
创建一个名为hf的环境,使用python 3.10版本
bash
conda create -n hf python=3.10 -y
conda activate hf安装 PyTorch
bash
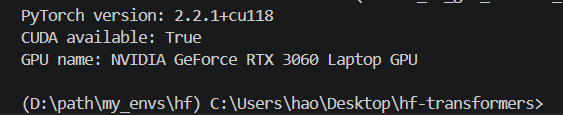
pip install torch==2.2.1 torchvision==0.17.1 torchaudio==2.2.1 --index-url https://download.pytorch.org/whl/cu118安装后检查 PyTorch,在 check_env.py 中写入:
python
import torch
print("PyTorch version:", torch.__version__)
print("CUDA available:", torch.cuda.is_available())
if torch.cuda.is_available():
print("GPU name:", torch.cuda.get_device_name(0))运行:
安装 Transformers 相关库
创建 requirements.txt:
transformers== 4.38.2
datasets== 2.18.0
evaluate== 0.4.1
accelerate== 0.27.2
scikit-learn
pandas
numpy==1.26.4
sentencepiece
protobuf
安装:
bash
python -m pip install -r requirements.txt各库的作用如下:
| 库 | 作用 |
|---|---|
transformers |
加载和使用预训练模型 |
datasets |
加载、划分、预处理数据集 |
evaluate |
计算准确率、F1 等评估指标 |
accelerate |
训练加速和多设备管理,Trainer 内部也会用到 |
scikit-learn |
计算分类指标时常用 |
pandas |
读取和处理 CSV 数据 |
numpy |
数值计算 |
sentencepiece |
某些模型的分词器依赖 |
protobuf |
某些 tokenizer 或模型配置可能依赖 |
在 check_env.py 中补充:
python
import torch
import transformers
import datasets
import evaluate
print("PyTorch version:", torch.__version__)
print("CUDA available:", torch.cuda.is_available())
if torch.cuda.is_available():
print("GPU name:", torch.cuda.get_device_name(0))
print("Transformers version:", transformers.__version__)
print("Datasets version:", datasets.__version__)
print("Evaluate version:", evaluate.__version__)运行得到:

1. Pipeline
pipeline 是 Transformers 提供的高级推理接口。它把下面几步封装在一起:
加载模型
→ 加载 tokenizer
→ 文本预处理
→ 模型前向推理
→ 输出后处理
使用 pipeline 时,我们可以用很少的代码完成一个任务。适合快速验证模型效果。后面我们会把 pipeline 背后的 Tokenizer 和 Model 拆开讲。
1.1 文本分类 Pipeline
创建 pipeline_demo.py,创建一个情感分析器
python
from transformers import pipeline
classifier = pipeline("sentiment-analysis")
result = classifier("I really like Hugging Face Transformers.")
print(result)这里的:sentiment-analysis表示要执行的任务类型是情感分析。
pipeline("sentiment-analysis") 会自动选择一个默认的情感分析模型、下载模型文件和 tokenizer 文件、加载模型到当前环境,最终返回一个可以直接调用的分类器对象。所以 classifier 就是一个已经准备好的情感分析模型接口。
运行脚本,输出:
text
[{'label': 'POSITIVE', 'score': 0.9974092841148376}]其中label 表示模型预测的类别;score 表示模型对该类别的置信度
批量输入
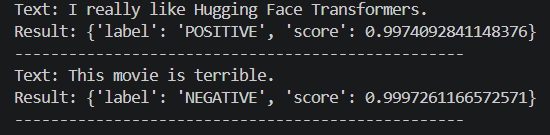
pipeline 支持传入一个字符串,也支持传入字符串列表。修改代码:
python
from transformers import pipeline
classifier = pipeline("sentiment-analysis")
texts = [
"I really like Hugging Face Transformers.",
"This movie is terrible."
]
results = classifier(texts)
for text, result in zip(texts, results):
print("Text:", text)
print("Result:", result)
print("-" * 50)输出:
指定模型
默认情况下,pipeline("sentiment-analysis") 会自动选择一个默认模型。也可指定模型名称:
python
classifier = pipeline(
task="sentiment-analysis",
model="distilbert-base-uncased-finetuned-sst-2-english"
)distilbert 表示模型架构是 DistilBERT。它是 BERT 的轻量化版本,速度更快,模型更小;base表示基础规模版本;uncased表示模型不区分大小写;finetuned表示这个模型不是原始预训练模型,而是在某个具体任务上进一步微调过。
sst-2表示它是在 SST-2 情感分类数据集上微调的。SST-2 是一个常见的英文情感分析数据集,主要用于二分类;english表示适用于英文文本。
因此这个模型可以理解为:一个基于 DistilBERT 的英文情感分析模型,不区分大小写,并且已经在 SST-2 数据集上微调过。
1.2 文本生成 Pipeline
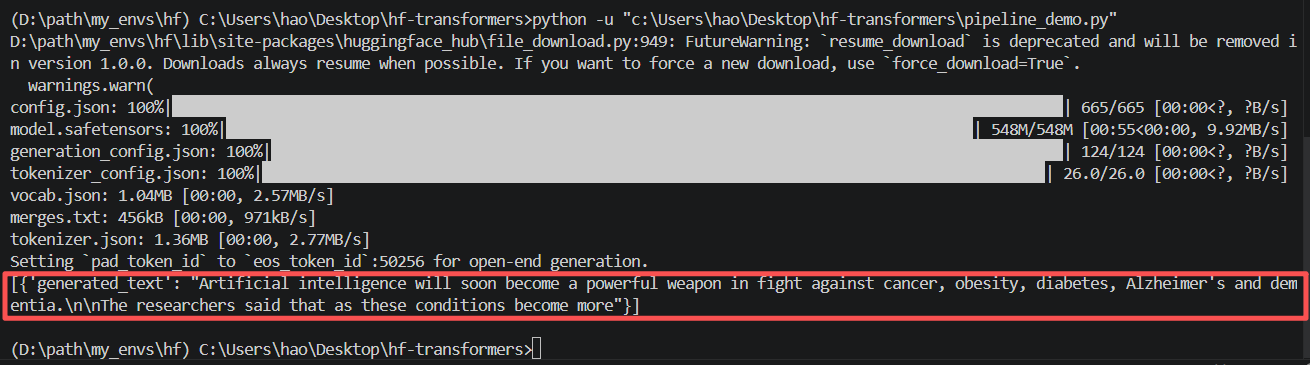
继续在 pipeline_demo.py 中:
python
from transformers import pipeline
generator = pipeline(
task="text-generation",
model="gpt2"
)
result = generator(
"Artificial intelligence will",
max_new_tokens=30
)
print(result)调用GPT-2 模型创建一个文本生成器,输入的提示词是:Artificial intelligence will,模型会根据这个开头继续生成后面的英文内容。
max_new_tokens=30表示最多新生成 30 个 token
1.3 问答 Pipeline
python
from transformers import pipeline
qa = pipeline("question-answering")
context = "Hugging Face is a company that provides open-source tools for machine learning."
question = "What does Hugging Face provide?"
result = qa(
question=question,
context=context
)
print(result)这里是问答任务的演示,这种 question-answering 会从提供的 context 中找到最可能的答案片段。context 的意思是上下文或参考材料。问答模型会根据这段内容来回答问题。
输出:
text
{'score': 0.7675297856330872, 'start': 40, 'end': 57, 'answer': 'open-source tools'}start与end分别是答案在原文中的开始、结束位置;answer是模型抽取出的答案;score代表置信度。
1.4 Transformers 标准工作流程
Pipeline 适合快速验证 模型效果,它可以自动处理 tokenizer、model 和后处理。但不容易理解底层流程;我们需要知道Tokenizer 和 Model 到底做了什么。
Transformers 中,训练任务通常包含以下流程:
原始数据
→ Datasets 加载
→ Tokenizer 批量编码
→ Model 加载
→ Evaluate 定义指标
→ Trainer 训练
→ 保存模型
→ 重新加载模型
→ 推理
各组件功能如下:
| 组件 | 作用 |
|---|---|
Pipeline |
快速推理接口 |
Tokenizer |
把文本转换成模型能处理的数字 |
Model |
预训练模型本体 |
Config |
模型结构和任务配置 |
Datasets |
数据加载、划分、批量处理 |
Evaluate |
计算评估指标 |
Trainer |
封装训练循环、评估、保存 |
2. Tokenizer
神经网络不能直接处理字符串。比如一句话 I love Transformers. 模型不能直接理解这句话,必须先把文本转换成数字 ID:
text
[101, 1045, 2293, 19081, 1012, 102]这些数字被称为 input_ids,每个数字都对应词表中的一个 token。把原始文本转换成模型可以处理的数字输入,这个过程就是 tokenizer 的工作。
当然它的工作不只是表面上简单的分词,Tokenizer 主要负责:
原始文本
→ 文本规范化
→ 分词 / 子词切分
→ token 转换为 ID
→ 添加特殊 token
→ padding 补齐
→ truncation 截断
→ 构造 attention_mask
→ 返回模型可用的输入格式
通常使用 AutoTokenizer ,它会根据 model_name 自动读取模型配置,并选择正确的 tokenizer 类型。
2.1 Tokenizer 流程
创建 tokenizer_demo.py:
python
from transformers import AutoTokenizer
model_name = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(model_name)
text = "I love Transformers."
encoded = tokenizer(text)
print(encoded)AutoTokenizer 根据 model_name 自动加载对应的 tokenizer。用这个分词器对输入文本分词
输出:
python
{'input_ids': [101, 1045, 2293, 19081, 1012, 102], 'attention_mask': [1, 1, 1, 1, 1, 1]}input_ids表示每个 token 在词表中的编号 。attention_mask用来标记哪些位置是真实 token,哪些位置是 padding;这里所有位置都是 1,说明没有 padding,所有 token 都是真实文本内容。
分词和转换
encoded = tokenizer(text)是完整编码过程,包括分词、转 ID、添加特殊 token、生成 attention_mask 等步骤。可以将分词和转 ID 单独写出来,也就是将这行代码替换为:
python
tokens = tokenizer.tokenize(text)
print(tokens)
ids = tokenizer.convert_tokens_to_ids(tokens)
print(ids)输出:
text
['i', 'love', 'transformers', '.']
[1045, 2293, 19081, 1012]与第一次的输出相比,这里少了 101 和 102 这两个编码,因为完整编码流程通常会自动添加特殊 token
解码 input_ids
加入解码,把数字 ID 还原成文本
python
decoded = tokenizer.decode(encoded["input_ids"])
print(decoded)多了这样一句输出:
text
[CLS] i love transformers. [SEP]在分词、转换之后,tokenizer 在输入前后添加了特殊标记。这里的两个标记分别表示开始和结束。
对于 BERT / DistilBERT 这类模型,常见特殊标记:
| 特殊 token | 含义 |
|---|---|
[CLS] |
分类任务常用的起始标记 |
[SEP] |
分隔句子或表示结束 |
[PAD] |
padding 补齐标记 |
[UNK] |
未知词 |
[MASK] |
掩码语言模型中的遮盖标记 |
padding、truncation 和 max_length
实际训练或推理时,不会只处理一句话,在处理多条文本,每个 batch 中的文本长度不一样。为了组成张量,需要把长度补齐。
例如:
python
from transformers import AutoTokenizer
model_name = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(model_name)
texts = [
"I love Transformers.",
"This is a very useful library for NLP tasks."
]
encoded = tokenizer(texts)
print(encoded)这时 input_ids 会变成一个二维结构:
python
{'input_ids':
[[101, 1045, 2293, 19081, 1012, 102],
[101, 2023, 2003, 1037, 2200, 6179, 3075, 2005, 17953, 2361, 8518, 1012, 102]],
'attention_mask':
[[1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]}这里第一句话长度较短,第二句话较长。要把它们组成一个 batch 输入模型,需要补齐到相同长度。这就需要 padding。
使用 padding=True 可以把同一个 batch 中的文本补齐到相同长度。
python
encoded = tokenizer(
texts,
padding=True
)输出变为:
python
{'input_ids':
[[101, 1045, 2293, 19081, 1012, 102, 0, 0, 0, 0, 0, 0, 0],
[101, 2023, 2003, 1037, 2200, 6179, 3075, 2005, 17953, 2361, 8518, 1012, 102]],
'attention_mask':
[[1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]}此外,模型通常有最大输入长度限制。很多 BERT 类模型最大长度是 512 个 token。文本太长,就需要截断。
python
encoded = tokenizer(
texts,
padding="max_length",
truncation=True,
max_length=16
)truncation=True 表示如果文本超过最大长度,进行截断,最大 token 长度设置为 16。这里的 padding="max_length" 表示无论当前 batch 中最长文本多长,都统一补齐到 max_length=16。
attention_mask
padding 之后,输入中会出现一些补齐位置。例如:
[101, 1045, 2293, 19081, 1012, 102, 0, 0, 0, 0, 0, 0, 0]后面有很多为了凑齐长度补充的 0 ,表示这个位置是 padding,不是真实文本。模型在计算注意力时,不应该把 padding 位置当成真实词语。因此需要 attention_mask
返回 PyTorch Tensor
模型输入需要 PyTorch 张量:
python
encoded = tokenizer(
texts,
padding="max_length",
truncation=True,
max_length=16,
return_tensors="pt"
)
print(encoded)
print(encoded["input_ids"].shape)
print(encoded["attention_mask"].shape)return_tensors="pt" 表示返回 PyTorch Tensor。
输出 shape :
text
torch.Size([2, 16])
torch.Size([2, 16])2 表示 batch 中有 2 条文本,16 表示每条文本被处理成 16 个 token 的长度
2.2 Tokenizer 小结
总的来说,Tokenizer 把人类可读的文本转换成模型可以计算的数字 。它不仅会完成分词,还会根据模型对应的词表把 token 转换成 input_ids,并按照模型要求添加特殊 token、处理 padding 和 truncation,同时生成 attention_mask 来告诉模型哪些位置是真实文本、哪些位置只是补齐内容。在 Hugging Face Transformers 中,最常用的方式是通过 AutoTokenizer.from_pretrained("模型名称") 加载与模型匹配的 tokenizer,然后调用 tokenizer() 对单条或多条文本进行编码。实际训练和推理时,通常会设置 padding=True、truncation=True、max_length=128 和 return_tensors="pt",得到可以直接输入 PyTorch 模型的标准化张量数据。
3. Model
Tokenizer 负责把文本变成数字,Model 负责对这些数字进行计算。模型接收Tokenizer 的输入后,会输出每个类别对应的分数。
如对于二分类情感分析任务,模型输出的 logits 类似:
text
logits = [[-2.1, 3.5]]这里两个分数分别对应两个类别。如果映射关系是:0: "NEGATIVE", 1: "POSITIVE",那么 3.5 对应第 1 类,且它大于 -2.1,所以模型最终预测为:POSITIVE
对于文本分类任务,整体流程可以表达为:
原始文本
→ Tokenizer 编码
→ input_ids / attention_mask
→ Model 前向传播
→ logits
→ 预测类别
3.1 加载模型的类
Transformers 中最常见的用于加载模型的类是:AutoModel.from_pretrained(...) 和AutoModelForSequenceClassification.from_pretrained(...),它们的区别在于是否包含具体任务所需的输出层。
| 类 | 作用 |
|---|---|
AutoModel |
只加载基础模型主体,不带具体任务头 |
AutoModelForSequenceClassification |
加载基础模型,并添加文本分类头 |
AutoModelForTokenClassification |
用于命名实体识别等 token 分类任务 |
AutoModelForQuestionAnswering |
用于抽取式问答任务 |
AutoModelForCausalLM |
用于 GPT 类因果语言模型 |
AutoModelForSeq2SeqLM |
用于 T5、BART 等编码器-解码器生成模型 |
对 DistilBERT 而言:AutoModel.from_pretrained(model_name) 加载的是 DistilBERT 的主体部分。输出文本的隐藏状态,例如每个 token 对应的向量表示。而:AutoModelForSequenceClassification.from_pretrained(model_name)加载的是DistilBERT 主体 + 分类头。分类头会把模型提取到的语义特征进一步映射成类别分数,也就是 logits。
要做文本分类任务,应该使用:AutoModelForSequenceClassification
3.2 模型推理
创建文件:model_demo.py
python
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
model_name = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)
text = "I love Transformers."
inputs = tokenizer(
text,
return_tensors="pt"
)
model.eval() ## 把模型切换到推理模式
with torch.no_grad(): ## 不计算梯度。推理不需要更新参数
outputs = model(**inputs)
print(outputs)
print("logits:", outputs.logits)
python
outputs = model(**inputs)**inputs 是 Python 的字典解包语法。等价于:
python
model(
input_ids=inputs["input_ids"],
attention_mask=inputs["attention_mask"]
)运行输出:
text
SequenceClassifierOutput(loss=None, logits=tensor([[-3.5493, 3.7720]]), hidden_states=None, attentions=None)
logits: tensor([[-3.5493, 3.7720]])从 logits 得到预测类别
添加代码:
python
logits = outputs.logits
predicted_class_id = torch.argmax(logits, dim=-1).item()
print("logits:", logits)
print("predicted class id:", predicted_class_id)
print("label:", model.config.id2label[predicted_class_id])其中:
python
torch.argmax(logits, dim=-1)表示在最后一个维度上寻找最大值对应的索引。也就是类别维度。.item() 将其转成数值 ID 。输出:
text
logits: tensor([[-3.5493, 3.7720]])
predicted class id: 1
label: POSITIVE模型的类别映射关系可以查看:
python
print(model.config.id2label)
print(model.config.label2id)logits是原始分数。可以使用 softmax 转成概率
python
probs = torch.softmax(logits, dim=-1)
print("probabilities:", probs)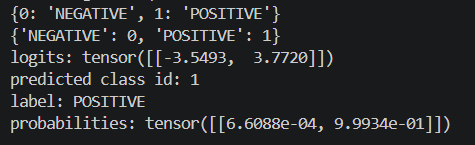
GPU 推理
在 CUDA 环境下,应该把模型和输入都移动到 GPU 上进行推理
python
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 如果 CUDA 可用,就使用 GPU;否则使用 CPU
model = model.to(device) # 把模型参数移动到对应设备上
inputs = {key: value.to(device) for key, value in inputs.items()} # 把 tokenizer 生成的输入张量也移动到同一个设备上。3.3 Model 小结
前面介绍过, pipeline 自动完成了所有步骤
python
from transformers import pipeline
classifier = pipeline(
task="sentiment-analysis",
model="distilbert-base-uncased-finetuned-sst-2-english"
)
result = classifier("I love Transformers.")
print(result)内部大致做了:
加载 tokenizer
加载 model
文本编码
模型前向传播
logits 转概率
选择最大概率类别
把结果整理成 label 和 score
而本节手动调用 Model,需要自己写:
text
tokenizer(...)
model(**inputs)
outputs.logits
torch.softmax(...)
torch.argmax(...)
model.config.id2label[...]这种更底层的写法适合训练、微调和理解模型输入输出
4. Config
Config 可以理解为模型的结构配置文件。它保存了模型结构参数、任务类型信息以及标签映射关系。在 Hugging Face 模型目录中,通常会有一个文件:config.json,这个文件记录的就是模型配置。
以文本分类任务为例,模型需要知道自己有几个类别。这个信息就保存在 config 中:num_labels = 2。前面模型预测时用到的:
python
model.config.id2label[predicted_class_id]就是在读取 config 中保存的类别映射关系。
4.1 查看模型 Config
创建文件:config_demo.py
python
from transformers import AutoModelForSequenceClassification
model_name = "distilbert-base-uncased-finetuned-sst-2-english"
model = AutoModelForSequenceClassification.from_pretrained(model_name)
print(model.config)读取当前模型对应的配置对象。运行后输出一大段模型配置信息。
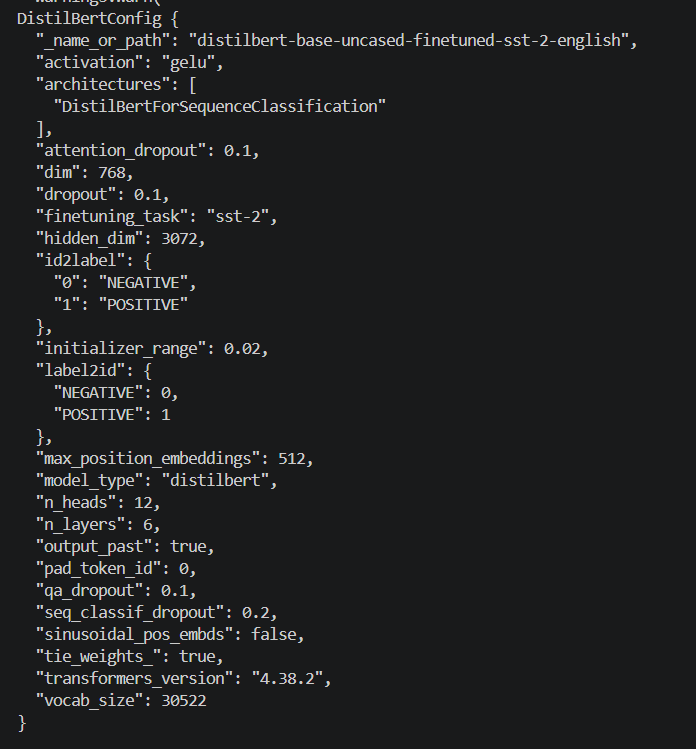
也可以不加载模型权重,只单独加载 config。
python
from transformers import AutoConfig
model_name = "distilbert-base-uncased-finetuned-sst-2-english"
config = AutoConfig.from_pretrained(model_name)
print(config)运行代码:
python
from transformers import AutoConfig
model_name = "distilbert-base-uncased-finetuned-sst-2-english"
config = AutoConfig.from_pretrained(model_name)
print("model_type:", config.model_type)
print("num_labels:", config.num_labels)
print("id2label:", config.id2label)
print("label2id:", config.label2id)
print("vocab_size:", config.vocab_size)
print("hidden_size:", config.hidden_size)
print("num_hidden_layers:", config.num_hidden_layers)
print("num_attention_heads:", config.num_attention_heads)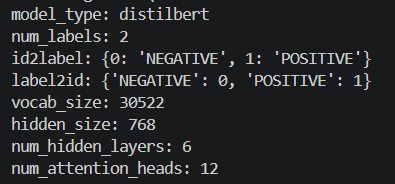
字段含义如下:
| 字段 | 含义 |
|---|---|
model_type |
模型类型 |
num_labels |
分类类别数 |
id2label |
类别 ID 到标签名称的映射 |
label2id |
标签名称到类别 ID 的映射 |
vocab_size |
词表大小 |
hidden_size |
隐藏层维度 |
num_hidden_layers |
Transformer 层数 |
num_attention_heads |
注意力头数 |
dropout |
dropout 概率 |
max_position_embeddings |
最大位置编码长度 |
4.2 保存和加载 Config
Transformers 会把模型、tokenizer 和 config 一起保存。例如:
python
save_dir = "./my_model"
model.save_pretrained(save_dir)
tokenizer.save_pretrained(save_dir)保存后目录中通常会有文件:config.json,保存的就是模型配置。
以后可以从本地目录重新加载:
python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
save_dir = "./my_model"
tokenizer = AutoTokenizer.from_pretrained(save_dir)
model = AutoModelForSequenceClassification.from_pretrained(save_dir)5. Datasets
接下来需要解决一个更实际的问题:数据从哪里来,如何整理成模型可以训练的格式 。Hugging Face 提供了 datasets 库,用来方便地加载、划分和预处理数据集。对于文本分类任务,数据处理的大致流程是:
准备原始数据
→ 加载数据集
→ 划分训练集和验证集
→ 使用 tokenizer 编码文本
→ 删除模型不需要的原始列
→ 设置为 PyTorch Tensor 格式
→ 送入模型或 Trainer
datasets 是 Hugging Face 提供的数据集处理库。在传统写法中,读取 CSV 文件会使用 pandas,然后自己手动写循环、划分数据、构造 Tensor。而使用 datasets 后,可以更方便地完成这些工作,尤其适合和 Transformers 配合使用。
在根目录下新建 data/sentiment.csv,用于保存数据。写入内容:
text,label
I love this movie,1
This film is terrible,0
The product is very useful,1
I hate this experience,0
This course is excellent,1
The service is bad,0
The book is interesting,1
The food tastes awful,0
I am happy with the result,1
This is a disappointing day,0
这个 CSV 文件有两列:text是输入文本,label代表文本对应的分类标签;规定 1 表示正向情感,0 表示负向情感
5.1 加载 CSV 数据集
创建文件 datasets_demo.py
python
from datasets import load_dataset
raw_dataset = load_dataset(
"csv",
data_files="data/sentiment.csv"
)
dataset = raw_dataset["train"].train_test_split(
test_size=0.2,
seed=42
)
print(dataset)
print("train size:", len(dataset["train"]))
print("test size:", len(dataset["test"]))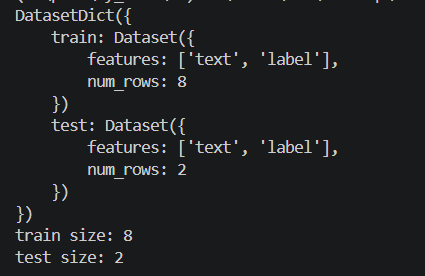
这里只提供了一个 CSV 文件,所以默认会生成一个名为 train 的 split:raw_dataset"train" 表示训练数据部分。
划分训练集和验证集:
python
dataset = raw_dataset["train"].train_test_split(
test_size=0.2,
seed=42
)其中 test_size=0.2 表示把 20% 的数据划分出去。seed=42 表示固定随机种子。划分数据时,本质上会随机打乱数据。如果不设置 seed,每次运行划分结果可能不同。设置 seed=42 后,每次运行会得到相同的划分结果,便于复现实验。
虽然这里生成的 split 名字叫 test,但可以先把它当作验证集使用:
python
train_dataset = dataset["train"] # 训练
eval_dataset = dataset["test"] # 评估DatasetDict 和 Dataset
加载数据后,输出中有两个概念。DatasetDict 包含多个数据划分的字典,而 Dataset 代表某一个具体的数据划分
例如:raw_dataset 是 DatasetDict。划分出训练集和验证集,结构变成:
text
DatasetDict({
train: Dataset(...),
test: Dataset(...)
})分别表示训练集和测试集
5.2 数据预处理
前文已经介绍过用 tokenizer 对 text 列进行编码。
python
encoded = tokenizer(
text,
padding="max_length",
truncation=True,
max_length=64
)datasets 中最常用的预处理方法是:dataset.map(...),它可以把一个函数应用到整个数据集上。
python
from datasets import load_dataset
from transformers import AutoTokenizer
model_name = "distilbert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
raw_dataset = load_dataset(
"csv",
data_files="data/sentiment.csv"
)
dataset = raw_dataset["train"].train_test_split(
test_size=0.2,
seed=42
)
def tokenize_function(examples):
return tokenizer(
examples["text"],
padding="max_length",
truncation=True,
max_length=64
)
tokenized_dataset = dataset.map(
tokenize_function,
batched=True
)
print(tokenized_dataset)
print(tokenized_dataset["train"][0])定义了一个函数,接收一批样本,并返回 tokenizer 编码后的结果。
python
def tokenize_function(examples):
return tokenizer(
examples["text"],
padding="max_length",
truncation=True,
max_length=64
)用 map 对 dataset 中的所有数据执行 tokenize_function。batched=True 表示批量处理,传入函数的是一批样本。
python
tokenized_dataset = dataset.map(
tokenize_function,
batched=True
)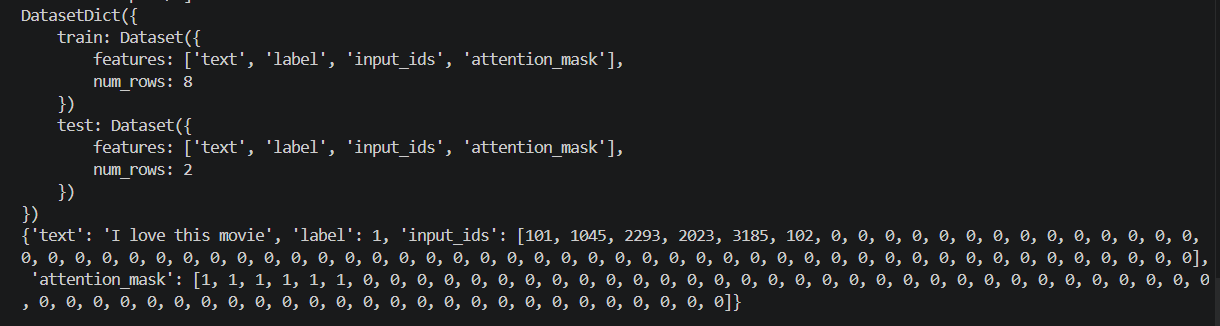
打印其中一个样本可以看到,多了 input_ids、attention_mask 两个维度,tokenizer 已经把原始文本转换成模型需要的输入格式。但是现在数据中仍然保留了原始的 text。训练模型时,模型不需要字符串形式的 text,所以后面可以把它删除。
添加一行代码删除文本列:
python
tokenized_dataset = tokenized_dataset.remove_columns(["text"])后续要和 PyTorch 模型、Trainer 或 DataLoader 配合使用,可以设置为 PyTorch 格式:
python
tokenized_dataset.set_format("torch")输出中的 input_ids、attention_mask 和 label 会变成 PyTorch Tensor。可以直接用于 PyTorch 训练流程。
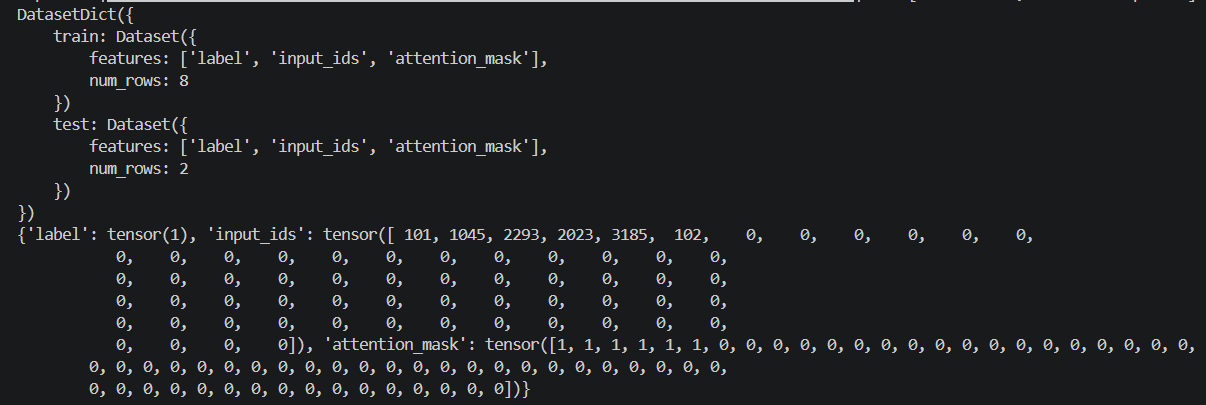
完成这一节后,数据已经变成模型可以直接使用的格式。下一步就可以进入 Trainer,使用这些数据对模型进行微调。
6. Evaluate
模型训练时经常看到一个指标 loss,loss 越低,通常说明模型在训练集上拟合得越好。但是,loss 并不能直接告诉我们模型到底预测对了多少样本、正类识别得好不好、是否存在类别不平衡问题......这些问题就需要通过评估指标来回答。
Hugging Face 提供了 evaluate 库,用来统一加载和计算各种评估指标。本节将从最简单的 accuracy 开始,逐步讲解如何使用 evaluate,以及如何把它接入 Trainer。
evaluate 的基本使用流程可以概括为:
加载指标
→ 准备 predictions 模型预测结果
→ 准备 references 真实标签
→ 调用 compute()
→ 得到指标结果
6.1 accuracy
新建 evaluate_demo.py
python
import evaluate
accuracy = evaluate.load("accuracy")
predictions = [0, 1, 1, 0]
references = [0, 1, 0, 0]
result = accuracy.compute(
predictions=predictions,
references=references
)
print(result)首先加载 accuracy 指标
python
accuracy = evaluate.load("accuracy")引入待评估的结果,predictions 和 references
| 参数 | 含义 |
|---|---|
predictions |
模型预测结果 |
references |
真实标签,也叫 ground truth |
accuracy.compute(...) 计算准确率,输出:{'accuracy': 0.75},准确率是 75%。
6.2 precision、recall 和 F1
分类任务中还常用:precision、recall、F1-score,以二分类任务为例,假设 1 表示正类,0 表示负类。
precision 表示模型预测为正类的样本中,有多少是真的正类。如果 precision 很低,说明模型把很多负类误判成了正类;recall 表示所有真实正类样本中,有多少被模型找出来了; recall 很低,说明模型漏掉了很多正类。F1-score 是 precision 和 recall 的综合指标。
evaluate 可以分别加载这些指标。
python
import evaluate
predictions = [0, 1, 1, 0, 1, 0]
references = [0, 1, 0, 0, 1, 1]
precision = evaluate.load("precision")
recall = evaluate.load("recall")
f1 = evaluate.load("f1")
precision_result = precision.compute(
predictions=predictions,
references=references
)
recall_result = recall.compute(
predictions=predictions,
references=references
)
f1_result = f1.compute(
predictions=predictions,
references=references
)
print("precision:", precision_result)
print("recall:", recall_result)
print("f1:", f1_result)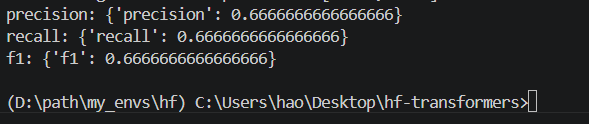
多分类任务中的 average 参数
对于多分类任务,例如:
0:negative
1:neutral
2:positive
每个类别都可以分别计算 precision、recall 和 F1。这时就需要指定如何对多个类别的结果进行平均,常见方式包括:
| 参数 | 含义 |
|---|---|
average="macro" |
对每个类别分别计算指标,再简单平均;每个类别权重相同 |
average="weighted" |
对每个类别分别计算指标,再按样本数量加权平均 |
average="micro" |
从整体样本级别统计 TP、FP、FN 后计算指标 |
只需加一个 average 参数
python
result = f1.compute(
predictions=predictions,
references=references,
average="macro"
)输出:
{'f1': 0.8222222222222223}6.3 compute_metrics
在 Transformers 的 Trainer 训练流程中,可以通过 compute_metrics 函数计算评估指标。训练过程中,Trainer 会在评估阶段把模型输出和真实标签传给 compute_metrics。
python
import numpy as np
import evaluate
accuracy = evaluate.load("accuracy")
def compute_metrics(eval_pred):
logits = eval_pred.predictions
labels = eval_pred.label_ids
predictions = np.argmax(logits, axis=-1)
return accuracy.compute(
predictions=predictions,
references=labels
)
python
logits = eval_pred.predictions
labels = eval_pred.label_ids表示从 Trainer 传入的评估结果中取出模型输出和真实标签。eval_pred.predictions 表示模型预测输出,eval_pred.label_ids 表示真实标签。对于普通文本分类任务,eval_pred.predictions 通常就是 logits。
多分类任务中的 compute_metrics
如果是多分类任务,为 precision、recall 和 F1 指定 average 参数。例如三分类任务:
0:negative
1:neutral
2:positive
python
import numpy as np
import evaluate
accuracy = evaluate.load("accuracy")
precision = evaluate.load("precision")
recall = evaluate.load("recall")
f1 = evaluate.load("f1")
def compute_metrics(eval_pred):
logits = eval_pred.predictions
labels = eval_pred.label_ids
predictions = np.argmax(logits, axis=-1)
accuracy_result = accuracy.compute(
predictions=predictions,
references=labels
)
precision_result = precision.compute(
predictions=predictions,
references=labels,
average="macro"
)
recall_result = recall.compute(
predictions=predictions,
references=labels,
average="macro"
)
f1_result = f1.compute(
predictions=predictions,
references=labels,
average="macro"
)
return {
"accuracy": accuracy_result["accuracy"],
"precision": precision_result["precision"],
"recall": recall_result["recall"],
"f1": f1_result["f1"]
}zero_division 参数
有时模型可能完全没有预测出某个类别。例如真实标签中有正类,但模型一个正类都没有预测出来。此时 precision 或 recall 计算中可能出现除零情况。为了避免警告或异常,设置:
python
precision_result = precision.compute(
predictions=predictions,
references=labels,
zero_division=0
)如果某个指标无法正常计算,就把结果设为 0。
7. Trainer
如果不用 Trainer,我们需要自己写 PyTorch 训练循环,例如:
python
for epoch in range(num_epochs):
for batch in train_dataloader:
outputs = model(**batch)
loss = outputs.loss
loss.backward()
optimizer.step()
optimizer.zero_grad()实际训练时没这么简单,还要继续处理:切换到训练/验证模式、训练/验证集 DataLoader、优化器、学习率调度器、梯度清零、反向传播、参数更新、验证集评估、日志打印、checkpoint 保存、最优模型加载、GPU / 多 GPU / 混合精度配置......这些流程写起来比较重复。
Trainer 的作用就是把这些常见训练流程封装起来。我们只需要准备好模型、数据集、训练参数和评估函数,就可以开始训练。
基本结构如下:
python
from transformers import Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
tokenizer=tokenizer,
compute_metrics=compute_metrics
)7.1 TrainingArguments
TrainingArguments 管理训练超参数和策略。例如:
python
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir="outputs/text_cls_model",
learning_rate=2e-5,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
num_train_epochs=3,
evaluation_strategy="epoch",
save_strategy="epoch",
logging_steps=10,
load_best_model_at_end=True,
metric_for_best_model="accuracy"
)常见参数如下:
| 参数 | 含义 |
|---|---|
output_dir |
模型、日志、checkpoint 保存路径 |
learning_rate |
学习率 |
per_device_train_batch_size |
每张设备上的训练 batch size |
per_device_eval_batch_size |
每张设备上的验证 batch size |
num_train_epochs |
训练轮数 |
evaluation_strategy |
什么时候进行验证集评估,epoch表示每个 epoch 结束后评估一次 |
save_strategy |
什么时候保存 checkpoint |
logging_steps |
每多少个 step 打印一次日志 |
load_best_model_at_end |
训练结束后是否加载最佳模型 |
metric_for_best_model |
用哪个指标判断最佳模型 |
greater_is_better |
指标越大越好还是越小越好 |
save_total_limit |
最多保留几个 checkpoint |
weight_decay |
权重衰减 |
fp16 |
是否开启半精度训练 |
7.2 训练
使用 5.Datasets 保存的 csv 文件作为训练集演示,整体流程如下:
准备 CSV 数据
→ 使用 datasets 加载数据
→ 划分训练集和验证集
→ 使用 tokenizer 预处理文本
→ 加载预训练模型
→ 定义评估指标
→ 定义 TrainingArguments
→ 创建 Trainer
→ 开始训练
→ 保存模型
新建 trainer_demo.py,
加载数据:
python
raw_dataset = load_dataset("glue", "sst2")数据集使用 GLUE / SST-2 。这是标准英文情感二分类数据集,这里不用自己 train_test_split,因为 SST-2 已经自带训练集和验证集。字段是 sentence 和 label。
tokenizer
演示的是使用自己的 CSV 数据进行微调,选择基础预训练模型:
python
model_name = "distilbert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_name)定义 tokenizer 预处理函数:
python
def tokenize_function(examples):
return tokenizer(
examples["sentence"],
padding="max_length",
truncation=True,
max_length=64
)examples"sentence" 表示取出文本列。
执行批量预处理:
python
tokenized_dataset = raw.dataset.map(
tokenize_function,
batched=True
)
tokenized_dataset = tokenized_dataset.remove_columns(["sentence", "idx"])
tokenized_dataset.set_format("torch")配置标签映射
CSV 中规定 0 表示 negative,1 表示 positive,因此可以设置:
python
id2label = {
0: "negative",
1: "positive"
}
label2id = {
"negative": 0,
"positive": 1
}通过 AutoConfig 创建配置:
python
config = AutoConfig.from_pretrained(
model_name,
num_labels=2,
id2label=id2label,
label2id=label2id
)加载模型
python
model = AutoModelForSequenceClassification.from_pretrained(
model_name,
config=config
)定义评估指标
加载 accuracy:
python
accuracy = evaluate.load("accuracy")定义 compute_metrics:
python
def compute_metrics(eval_pred):
logits = eval_pred.predictions
labels = eval_pred.label_ids
predictions = np.argmax(logits, axis=-1)
return accuracy.compute(
predictions=predictions,
references=labels
)最后用预测标签和真实标签计算 accuracy
python
accuracy.compute(
predictions=predictions,
references=labels
)定义 TrainingArguments
定义训练参数:
python
training_args = TrainingArguments(
output_dir="outputs/text_cls_model",
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=3,
evaluation_strategy="epoch",
save_strategy="epoch",
logging_steps=100,
load_best_model_at_end=True,
metric_for_best_model="accuracy",
greater_is_better=True,
save_total_limit=2,
report_to="none",
weight_decay=0.01,
fp16=True,
seed=42
)用 accuracy 判断哪个模型最好,accuracy 越大越好。
创建 Trainer
python
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset["train"],
eval_dataset=tokenized_dataset["validation"],
tokenizer=tokenizer,
compute_metrics=compute_metrics
)评估模型
训练结束后,调用:
python
eval_result = trainer.evaluate()
print(eval_result)评估模型指标
保存最终模型
训练完成后,可以保存模型:
python
trainer.save_model("outputs/final_text_cls_model")
tokenizer.save_pretrained("outputs/final_text_cls_model")之后可以从本地重新加载模型:
python
from transformers import pipeline
classifier = pipeline(
task="sentiment-analysis",
model="outputs/final_text_cls_model",
tokenizer="outputs/final_text_cls_model"
)
result = classifier("I love this method.")
print(result)这样就可以使用自己微调后的模型进行预测。
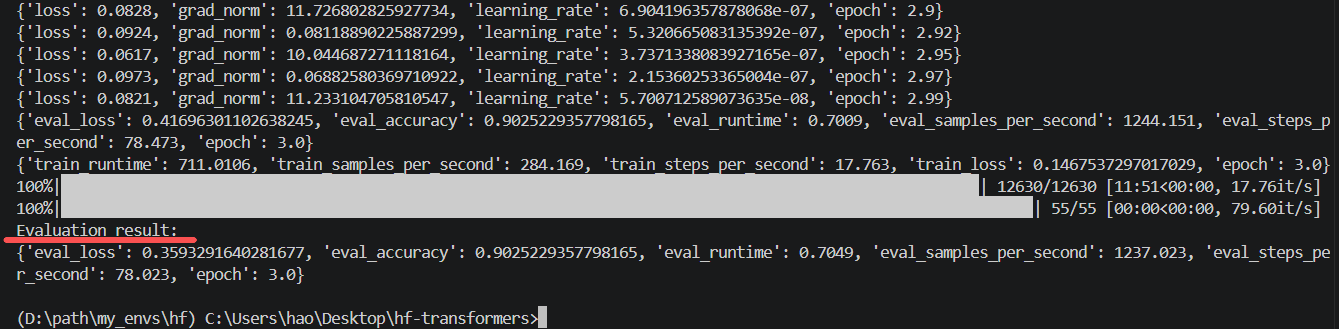
完整训练脚本
python
import numpy as np
import evaluate
from datasets import load_dataset
from transformers import AutoTokenizer
from transformers import AutoConfig
from transformers import AutoModelForSequenceClassification
from transformers import TrainingArguments
from transformers import Trainer
model_name = "distilbert-base-uncased"
id2label = {
0: "negative",
1: "positive"
}
label2id = {
"negative": 0,
"positive": 1
}
raw_dataset = load_dataset("glue", "sst2")
tokenizer = AutoTokenizer.from_pretrained(model_name)
def tokenize_function(examples):
return tokenizer(
examples["sentence"],
padding="max_length",
truncation=True,
max_length=64
)
tokenized_dataset = raw_dataset.map(
tokenize_function,
batched=True
)
tokenized_dataset = tokenized_dataset.remove_columns(["sentence", "idx"])
tokenized_dataset.set_format("torch")
config = AutoConfig.from_pretrained(
model_name,
num_labels=2,
id2label=id2label,
label2id=label2id
)
model = AutoModelForSequenceClassification.from_pretrained(
model_name,
config=config
)
accuracy = evaluate.load("accuracy")
def compute_metrics(eval_pred):
logits = eval_pred.predictions
labels = eval_pred.label_ids
predictions = np.argmax(logits, axis=-1)
return accuracy.compute(
predictions=predictions,
references=labels
)
training_args = TrainingArguments(
output_dir="outputs/text_cls_model",
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=3,
evaluation_strategy="epoch",
save_strategy="epoch",
logging_steps=100,
load_best_model_at_end=True,
metric_for_best_model="accuracy",
greater_is_better=True,
save_total_limit=2,
report_to="none",
weight_decay=0.01,
fp16=True,
seed=42
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset["train"],
eval_dataset=tokenized_dataset["validation"],
tokenizer=tokenizer,
compute_metrics=compute_metrics
)
trainer.train()
eval_result = trainer.evaluate()
print("Evaluation result:")
print(eval_result)
trainer.save_model("outputs/final_text_cls_model")
tokenizer.save_pretrained("outputs/final_text_cls_model")7.3 模型推理
新建文件 predict_demo.py,使用 Pipeline 做模型推理
python
from transformers import pipeline
model_dir = "outputs/final_text_cls_model"
classifier = pipeline(
task="sentiment-analysis",
model=model_dir,
tokenizer=model_dir
)
texts = [
"I love this course.",
"This experience is terrible.",
"The product is very useful."
]
results = classifier(texts)
for text, result in zip(texts, results):
print("text:", text)
print("result:", result)
print("-" * 50)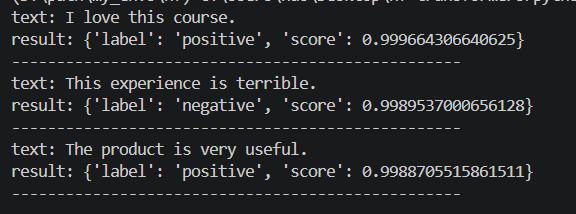
动态 padding
代码中 padding="max_length" 会把所有文本都补齐到:max_length=64。实际训练中,也可以使用动态 padding,每个 batch 内部补齐到当前 batch 最长文本的长度。tokenizer 时不写 padding="max_length",只做截断:
python
def tokenize_function(examples):
return tokenizer(
examples["text"],
truncation=True,
max_length=64
)使用:
python
from transformers import DataCollatorWithPadding
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset["train"],
eval_dataset=tokenized_dataset["test"],
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics
)Trainer 是 Transformers 提供的高层训练接口,可以自动完成标准训练流程。
到这里,已经完成了从数据集加载、tokenizer 预处理、模型加载、指标计算到 Trainer 微调的完整流程。
本文介绍了 Transformers 基础入门流程。标准训练流程如下:
- 准备数据
- 使用 Datasets 加载数据
- 使用 Tokenizer 编码文本
- 使用 AutoModelForSequenceClassification 加载模型
- 使用 Evaluate 定义评估指标
- 使用 TrainingArguments 设置训练参数
- 使用 Trainer 启动训练
- 保存模型和 tokenizer
- 重新加载模型推理