论文题目 :Parametric Point Cloud Completion for Polygonal Surface Reconstruction
作者 :Zhaiyu Chen, Yuqing Wang, Liangliang Nan, Xiao Xiang Zhu
单位 :Technical University of Munich, Delft University of Technology, Munich Center for Machine Learning
发表会议 :ECCV(European Conference on Computer Vision)
关键词:点云补全,参数化补全,多边形表面重建,平面基元,二分图匹配
1. 引言:为什么"补点"不再是好办法?
在三维重建中,从残缺的点云恢复出完整、规整的多边形表面一直是个棘手问题。主流思路是先"补点"再"表面重建",但补全算法只关心点的位置,忽略了高层几何结构,导致重建结果崩塌。慕尼黑工业大学和代尔夫特理工大学 提出的 PaCo 直接换了一种思维:不补点,而是补"参数化平面基元"。
这种参数化补全新范式让多边形表面重建在高缺失率下依然稳健,论文已开源。本文将按照漏斗式叙事,从问题根源讲起,拆解核心设计,并给出实验验证。

点云补全(PCN、PoinTr、AdaPoinTr 等)在填坑方面取得了长足进步,但一旦把它和多边形表面重建(如 PolyFit、KSR)串联起来,效果就急转直下------要么重建残缺,要么面片杂乱,甚至直接失败。根本矛盾在于:
- 点云补全:追求点集的 Chamfer Distance 最小,输出一堆无结构的 3D 点;
- 多边形表面重建 :需要分段平面结构(每个面是一个参数化平面 + 一组共面内点)。
这种"点"与"结构"的错位,使得传统流水线在遮挡严重时必然崩溃。另一条路------直接在不完整输入上做重建(PolyFit、BSP-Net 等)------又因为看不到完整的平面证据而大量失败。
PaCo 提出了一种新范式:参数化补全(Parametric Completion) 。它不再输出点坐标,而是直接输出一组 参数化平面基元(plane primitives),每个基元携带:平面参数、内部点分布和置信度。有了这些基元,只需简单组装就能得到高保真多边形网格。
2. 相关工作:三条路线,各自跛脚
2.1 点云补全
PCN、PoinTr、AdaPoinTr、ODGNet 等方法能恢复缺失区域的点,但它们输出的是无结构点集,缺乏对平面性等高层几何的编码。即使把补全后的点送入 PolyFit 等求解器,提取出的平面对依然脆弱,重建易失败。
2.2 多边形表面重建
传统方法 PolyFit、KSR、COMPOD 依赖从输入点云中提取平面基元(如 RANSAC、GoCoPP),然后通过组合优化得到多边形网格。输入残缺时,基元提取不完整,重建必然失败。神经方法如 BSP-Net、SECAD-Net 虽然端到端,但对不完整数据泛化极差,常产生过度简化的结果。
2.3 几何简化
"先密后简"路线先用泊松重建生成密集网格,再用 QEM、RoLoPM 等简化,但难以保留 CAD 模型那种规则的平面性,面数多且不规整。
三条路共同痛点:没有一种表示能直接从残缺数据中捕获完整的平面结构。PaCo 正是要填补这一空白。
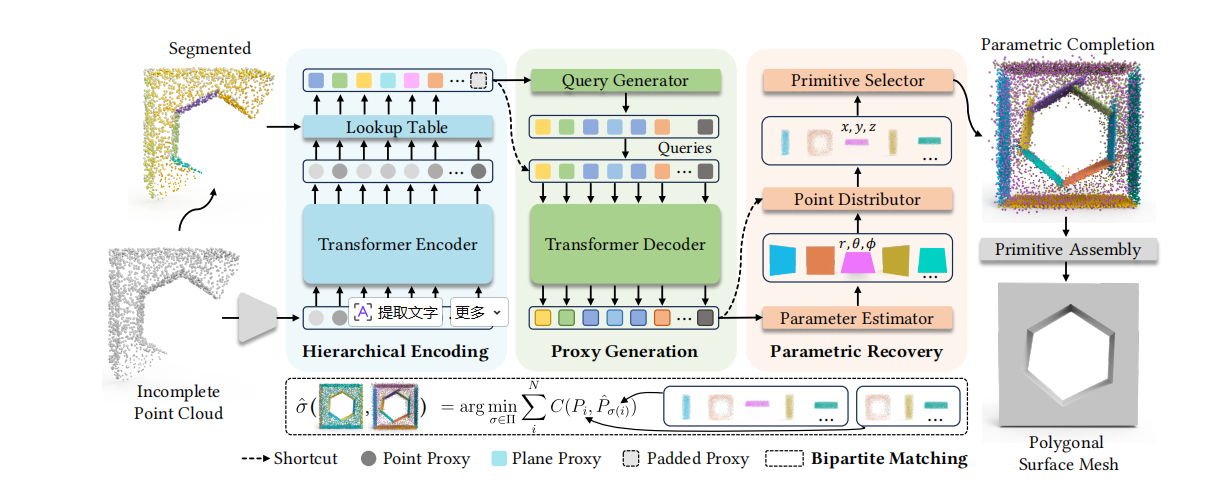
3. 方法:从残缺点云直接"长"出平面基元
PaCo 的整体流程为:分层编码 → 代理生成 → 参数恢复 → 集合匹配优化。
3.1 分层编码:从点到面,逐级上卷
给定残缺点云 X={xi}i=1NxX = \{x_i\}_{i=1}^{N_x}X={xi}i=1Nx,先用 GoCoPP 将其分割为若干平面片段 S={si}S = \{s_i\}S={si},得到"点→面"的映射表 f:X→Sf: X \to Sf:X→S。编码器逐级构建三个层次的特征:
- 点代理 (Point Proxies) :将局部点集聚合成一个特征向量 X′X'X′,代表一个"点块"。
- 平面代理 (Plane Proxies) :利用映射表 f′:X′→Sf' : X' \to Sf′:X′→S,通过 sum pooling 聚合同一平面的所有点代理,再注入平面法向量的 MLP 嵌入,得到第 iii 个平面代理:
vi=sum(Xi′)+Φ(ni)(1) v_i = \text{sum}(X_i') + \Phi(n_i) \tag{1} vi=sum(Xi′)+Φ(ni)(1)
其中 nin_ini 是该平面的法向量。最终得到一组平面代理 V={vi}i=1KV = \{v_i\}_{i=1}^KV={vi}i=1K。聚合时保留 sum 而非 mean 是为了保留平面尺度信息,这对恢复内点数量至关重要。
3.2 代理生成:猜出那些完全缺失的面
仅靠可见平面的代理无法应对严重遮挡,模型必须"想象"出完全缺失的平面。
- 先将 VVV 补零到固定大小,经 MLP 得到输入查询 QIQ_IQI;
- 另一可学习的查询生成器输出缺失部分查询 QGQ_GQG;
- 用查询排序策略选择前 MMM 个查询 Q={qi}i=1MQ = \{q_i\}_{i=1}^MQ={qi}i=1M;
- Transformer 解码器让 QQQ 关注 VVV,输出补全后的平面代理提议。
这个阶段的关键是:用 Transformer 的注意力机制融合全局上下文,推演出应该出现但不可见的平面。
3.3 参数恢复:一个平面需要三样东西
每个平面基元必须同时具备参数、内点集和存在概率。PaCo 用三个头进行预测:
参数估计器 :输入平面代理,输出极坐标下的平面参数 (ri,θi,ϕi)(r_i, \theta_i, \phi_i)(ri,θi,ϕi),避免 Cartesian 表示在轴对齐平面附近的退化问题。
点分配器 :平面形状由附着在其上的点集决定。对第 iii 个平面的第 jjj 个点,预测其在平面上的极角 (θij,ϕij)(\theta_{ij}, \phi_{ij})(θij,ϕij),然后通过平面参数反推半径:
rij=ricos(Δϕ)sin(θij)sin(θi)+cos(θij)cos(θi)(2) r_{ij} = \frac{r_i}{\cos(\Delta \phi)\sin(\theta_{ij})\sin(\theta_i) + \cos(\theta_{ij})\cos(\theta_i)} \tag{2} rij=cos(Δϕ)sin(θij)sin(θi)+cos(θij)cos(θi)ri(2)
其中 Δϕ=ϕij−ϕi\Delta \phi = \phi_{ij} - \phi_iΔϕ=ϕij−ϕi。
基元选择器 :为每个基元预测置信度 κi∈0,1\kappa_i \in 0,1κi∈0,1,表示该面是否真正属于物体表面。训练时通过二分匹配决定监督信号,推理时按阈值筛选。
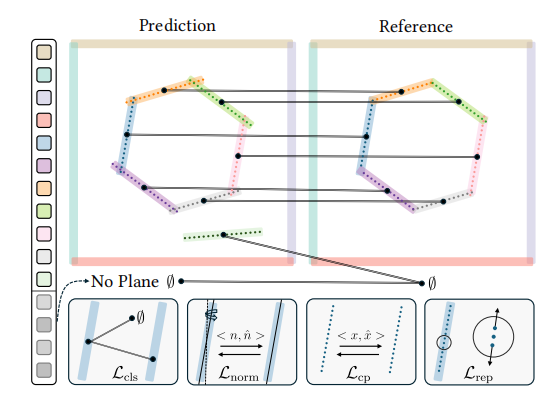
3.4 集合匹配与损失
真值是一组不定数量的平面基元 PPP,预测集 P^\hat{P}P^ 固定为 MMM 个。通过 匈牙利算法 寻找最优排列 σ^\hat{\sigma}σ^,最小化总匹配成本:
σ^=argminσ∈Π∑i=1MC(pi,p^σ(i))(4) \hat{\sigma} = \arg\min_{\sigma \in \Pi} \sum_{i=1}^{M} C(p_i, \hat{p}_{\sigma(i)}) \tag{4} σ^=argσ∈Πmini=1∑MC(pi,p^σ(i))(4)
其中单项匹配代价定义为:
C(pi,p^σ(i))=Lcls+β1Lnorm+β2Lcp+β3Lrep(3) C(p_i, \hat{p}{\sigma(i)}) = \mathcal{L}{\text{cls}} + \beta_1 \mathcal{L}{\text{norm}} + \beta_2 \mathcal{L}{\text{cp}} + \beta_3 \mathcal{L}_{\text{rep}} \tag{3} C(pi,p^σ(i))=Lcls+β1Lnorm+β2Lcp+β3Lrep(3)
各损失项具体含义:
- 分类损失 Lcls\mathcal{L}_{\text{cls}}Lcls:鼓励选择器对匹配上的基元输出高置信度,对填充的 ∅\emptyset∅ 输出低置信度:
Lcls=−1{c^i=1}logκσ^(i)−1{c^i=0}log(1−κσ^(i))(5) \mathcal{L}{\text{cls}} = -\mathbb{1}{\{\hat{c}i=1\}} \log \kappa{\hat{\sigma}(i)} - \mathbb{1}_{\{\hat{c}i=0\}} \log (1-\kappa{\hat{\sigma}(i)}) \tag{5} Lcls=−1{c^i=1}logκσ^(i)−1{c^i=0}log(1−κσ^(i))(5)
- 法线损失 Lnorm\mathcal{L}_{\text{norm}}Lnorm:同时使用余弦相似度和 L2 距离约束平面法向:
Lnorm=1{c^i=1}⋅λ(1−cos(∠(ni,n^σ^(i))))+1{c^i=1}⋅∥ni−n^σ^(i)∥2(6) \mathcal{L}{\text{norm}} = \mathbb{1}{\{\hat{c}i=1\}} \cdot \lambda(1 - \cos(\angle(n_i, \hat{n}{\hat{\sigma}(i)}))) + \mathbb{1}_{\{\hat{c}i=1\}} \cdot \|n_i - \hat{n}{\hat{\sigma}(i)}\|^2 \tag{6} Lnorm=1{c^i=1}⋅λ(1−cos(∠(ni,n^σ^(i))))+1{c^i=1}⋅∥ni−n^σ^(i)∥2(6)
- 平面 Chamber 损失 Lcp\mathcal{L}_{\text{cp}}Lcp:衡量匹配对内部点集的相似度:
Lcp=1{c^i=1}⋅CD(pi,p^σ(i))(7) \mathcal{L}{\text{cp}} = \mathbb{1}{\{\hat{c}i=1\}} \cdot CD(p_i, \hat{p}{\sigma(i)}) \tag{7} Lcp=1{c^i=1}⋅CD(pi,p^σ(i))(7)
- 全局 Chamber 损失 Lco\mathcal{L}_{\text{co}}Lco:对所有被选中的基元点云整体求 CD:
Lco=CD({pi∣ci=1},{p^i∣c^i=1})(8) \mathcal{L}_{\text{co}} = CD(\{p_i \mid c_i=1\}, \{\hat{p}_i \mid \hat{c}_i=1\}) \tag{8} Lco=CD({pi∣ci=1},{p^i∣c^i=1})(8)
- 排斥损失 Lrep\mathcal{L}_{\text{rep}}Lrep:防止内点聚集在平面中心,促进均匀分布:
Lrep=∑i=1T∑i′∈K(i)−∥x^i′−x^i∥⋅exp(−ω∥x^i′−x^i∥2)(9) \mathcal{L}{\text{rep}} = \sum{i=1}^{T} \sum_{i' \in K(i)} -\| \hat{x}_{i'} - \hat{x}i \| \cdot \exp(-\omega \| \hat{x}{i'} - \hat{x}_i \|^2) \tag{9} Lrep=i=1∑Ti′∈K(i)∑−∥x^i′−x^i∥⋅exp(−ω∥x^i′−x^i∥2)(9)
最终总损失为上述各项加权和:
Ltotal=∑i=1M(Lcls(i)+β1Lnorm(i)+β2Lcp(i)+β3Lrep(i))+β4Lco(10) \mathcal{L}{\text{total}} = \sum{i=1}^{M} \left( \mathcal{L}{\text{cls}}^{(i)} + \beta_1 \mathcal{L}{\text{norm}}^{(i)} + \beta_2 \mathcal{L}{\text{cp}}^{(i)} + \beta_3 \mathcal{L}{\text{rep}}^{(i)} \right) + \beta_4 \mathcal{L}_{\text{co}} \tag{10} Ltotal=i=1∑M(Lcls(i)+β1Lnorm(i)+β2Lcp(i)+β3Lrep(i))+β4Lco(10)
这种设计让网络从一开始就按结构进行思考,而不是盲目追逐点的位置。
4. 实验:让数据说话
4.1 实验设置
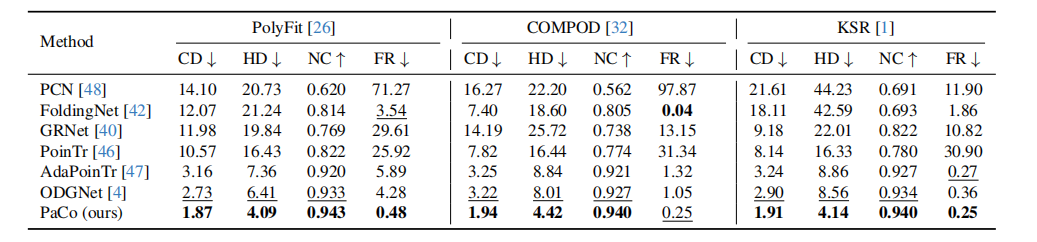
使用 ABC 数据集中 15,339 个纯平面 CAD 模型,每个模型生成 25%、50%、75% 缺失三种难度,共约 36 万帧点云。评价指标基于重建网格:Chamfer Distance (CD)、Hausdorff (HD)、法向一致性 (NC) 和失败率 (FR)。
4.2 对比点云补全 + 重建流水线
将 PCN、FoldingNet、GRNet、PoinTr、AdaPoinTr、ODGNet 与 PolyFit、KSR、COMPOD 组合,与 PaCo 直接对比(PaCo 输出的平面可直接组装)。结果如论文中所示,PaCo 在不同求解器下均全面领先,尤其在 75% 硬缺失下,CD 仅 2.43,而最强对手 ODGNet 为 4.72,失败率仅 0.48%。

4.3 对比直接重建方法
在不完整输入上直接运行 PolyFit、KSR、COMPOD 等,失败率高达 33%~64%,BSP-Net 和 SECAD-Net 也难逃结构丢失。PaCo 的完成-重建策略将失败率压至 0.48%,证明了参数化补全对结构恢复的决定性作用。
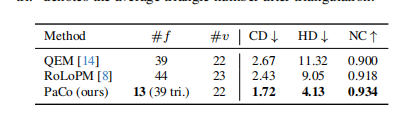
4.4 对比几何简化
与 QEM、RoLoPM 简化泊松网格相比,PaCo 用最少的三角面片(平均 39 个三角形)实现了最高的几何精度和最强的规则性。
4.5 鲁棒性分析
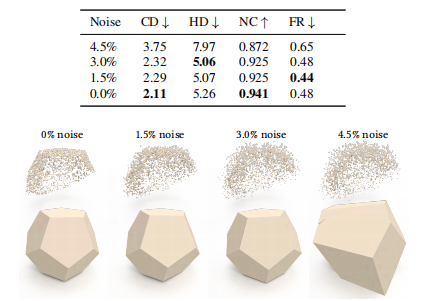
- 噪声:加入 1.5%~4.5% 高斯噪声重新训练,PaCo 直到 3% 噪声级别性能几乎不降,失败率稳定在低水平(图7)。
- 高缺失:随缺失率增加(25%→75%),其他方法性能陡降,PaCo 则下降平缓,优势持续扩大。
5. 结论:范式转换的力量
PaCo 开创了参数化补全新范式 ,将点云补全的目标从"恢复点"扭转为"恢复参数化平面基元"。通过分层编码、代理生成和参数恢复,它能在极短时间(29.8ms)内从残缺数据中恢复出完整、规整的多边形表面,即使在极高缺失和噪声下也极其稳健。
目前 PaCo 主要面向纯平面物体,未来将扩展到球面、圆柱面等更多参数化基元,有望统一形状补全与表面重建。项目页面和代码已开源,欢迎尝鲜和二次开发。