PyTorch深度学习实战(56)------在iOS上构建PyTorch应用
0. 前言
我们已经学习了如何使用 PyTorch Mobile 优化 MNIST 手写数字识别模型,并将优化后的模型部署到 Android 系统上。在本节中,我们将在 iOS 平台上重复了这一过程,开发一个 iOS 应用程序,用于对手写数字的摄像头拍摄图像进行分类识别。我们将复用Android 应用开发环节中已优化的 MNIST 手写数字识别模型。
1. 配置 iOS 开发环境
要构建 iOS 应用,需要在 MacBook 上下载 Xcode。Xcode 是 Apple 为 iOS (以及 macOS、iPadOS、watchOS 和 tvOS) 平台开发软件创建的集成开发环境 (Integrated Development Environment, IDE)。它是开发者用来创建 Apple 各个平台应用程序和软件的主要工具。作为 iOS 应用开发的官方 IDE,Xcode 必须运行于 MacBook 设备。
在打开 Xcode 之前,需通过命令行将当前工作目录切换至 iOS/HelloWorld 文件夹。在该目录下运行以下命令:
shell
pod installpod 命令指的是 CocoaPods,它是一个用于 iOS 项目的开源依赖管理工具。CocoaPods 简化了将第三方库和框架集成到 Xcode 项目的过程。与手动下载、配置和添加外部库到项目中不同,CocoaPods 自动化了这个过程。可以使用以下命令在 MacBook 上安装 CocoaPods:
shell
sudo gem install cocoapods以上命令通过解析 Podfile 文件安装依赖(原理类似 Python 的 pip install -r requirements.txt)。当前工作目录中的 Podfile 包含以下关键配置:
shell
platform :ios, '15.0'
target 'HelloWorld' do
pod 'LibTorch-Lite', '~> 1.13.0.1'
end执行 pod install 将安装 PyTorch C++ 库 (libtorch),为 iOS 应用提供 ML 预测所需的底层支持。在 Xcode 中打开当前工作目录下的 HelloWorld.xcworkspace 文件,此时 Xcode IDE 界面将呈现如下图所示的布局。
在上图最左侧,可以看到 model 文件夹,其中包含移动端优化后的 MNIST 模型文件。通过以下命令,我们将此模型从 Android 文件夹复制到 iOS 文件夹:
shell
cp ../Android/app/src/main/assets/optimized_for_mobile_traced_model.pt ./iOS/HelloWorld/HelloWorld/model/model.pt在上图最左侧,我们还可以看到一个 Info.plist 文件,这个 XML 格式的配置文件存储着 iOS 应用程序的核心元数据和配置信息,用于向操作系统和 App Store 声明应用的基本行为规范。为实现摄像头调用功能,我们在该文件中添加了如下图所示的权限配置项。
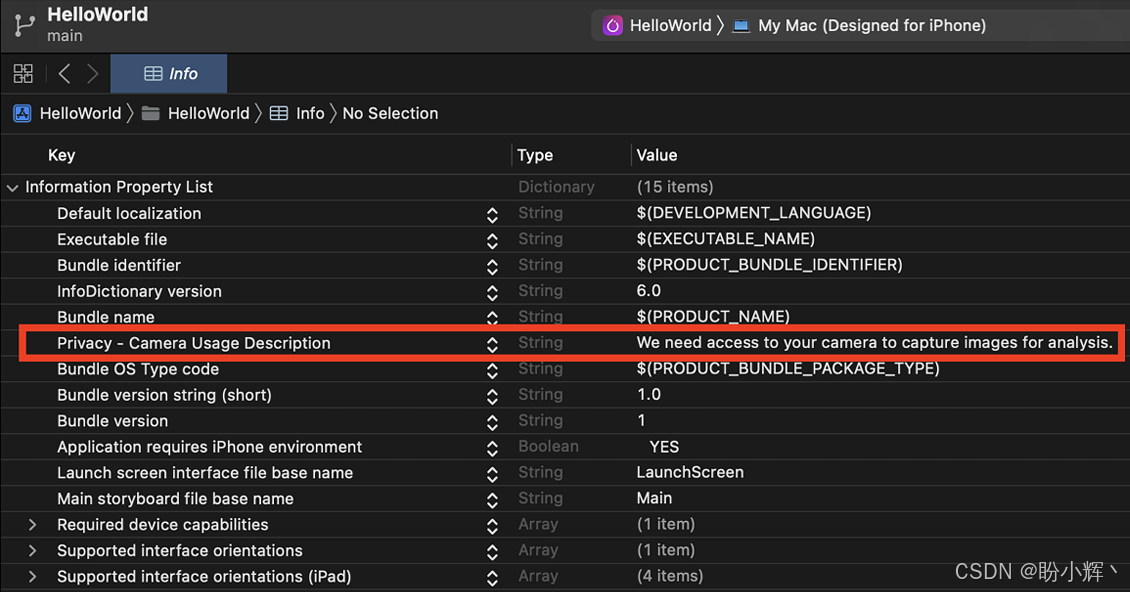
在 iOS 应用开发中,我们需要说明为什么需要访问手机摄像头,如上图高亮部分的右侧所示。
现在我们已经设置好了 Xcode 项目,并处理了手机摄像头访问的配置,接下来介绍处理图像拍摄功能的代码。
2. 在 iOS 应用中使用手机摄像头拍摄图像
观察上一小节 IDE 界面左侧区域,可见多个 Swift 语言编写的源代码文件( Swift 是 iOS 开发的主流编程语言)。其中负责处理摄像头采集功能的是 CaptureViewController.swift,该文件包含了 CaptureViewController 类,该类列出了处理摄像头拍摄流程所需的各种对象和方法:
swift
class CaptureViewController: UIViewController, AVCapturePhotoCaptureDelegate {
@IBOutlet var captureButton: UIButton!
@IBOutlet var imageView: UIImageView!
private var captureSession: AVCaptureSession!
private var photoOutput: AVCapturePhotoOutput!
private var previewLayer: AVCaptureVideoPreviewLayer!
private var capturedImage: UIImage?上述代码中包含以下核心组件:
- 首先定义
captureButton对象,关联摄像头拍摄界面上的拍摄按钮 - 然后,定义
imageView对象,关联屏幕上动态显示的摄像头输出画面 - 接下来,声明
captureSession会话对象,负责管理手机摄像头的实时图像流采集 - 定义
photoOutput对象,用于存储原始拍摄的照片数据 - 声明
previewLayer预览层对象,负责向用户渲染拍摄的画面 - 最后定义
capturedImage对象,存储经过处理的照片(原始数据来自photoOutput)。
这些对象之后声明了若干方法,首先是 viewDidLoad。该方法用于执行视图的初始设置与配置(本节中即摄像头拍摄界面):
swift
override func viewDidLoad() {
super.viewDidLoad()
setupCamera()
}因此,该方法会进一步调用 CaptureViewController 类中的另一个函数------setupCamera。setupCamera 方法首先会确认应用程序是否确实拥有手机摄像头的访问权限,接着初始化运行摄像头拍摄流程所需的 captureSession、previewLayer 和 photoOutput 对象。该函数最终会启动摄像头拍摄会话:
swift
func setupCamera() {
captureSession = AVCaptureSession()
guard let captureDevice = AVCaptureDevice.default(for: .video) else {
fatalError("Cannot access camera.")
}
do {
let input = try AVCaptureDeviceInput(device: captureDevice)
captureSession.addInput(input)
photoOutput = AVCapturePhotoOutput()
captureSession.addOutput(photoOutput)
previewLayer = AVCaptureVideoPreviewLayer(session: captureSession)
previewLayer.videoGravity = .resizeAspectFill // Maintain aspect ratio
// Calculate the square frame that fits within the screen bounds
let minSideLength = min(view.bounds.width, view.bounds.height)
let previewFrame = CGRect(
x: (view.bounds.width - minSideLength) / 2,
y: (view.bounds.height - minSideLength) / 2,
width: minSideLength,
height: minSideLength
)
previewLayer.frame = previewFrame
view.layer.addSublayer(previewLayer)
captureSession.startRunning()
} catch {
fatalError("Cannot set up camera.")
}
}以上代码定义了将传入的图像流捕获至 photoOutput 对象,并在 previewLayer 中显示摄像头拍摄画面的逻辑。接下来是 captureButtonTapped 方法,该方法将摄像头拍摄按钮的按下操作与将拍摄的照片存储至 photoOutput 变量的逻辑关联起来:
swift
@IBAction func captureButtonTapped(_ sender: UIButton) {
let settings = AVCapturePhotoSettings()
photoOutput.capturePhoto(with: settings, delegate: self)
}接下来是 photoOutput 方法,该方法将原始的 photoOutput 对象转换为最终的 capturedImage 对象,并在 previewLayer 上显示拍摄的图像:
swift
func photoOutput(_ output: AVCapturePhotoOutput, didFinishProcessingPhoto photo: AVCapturePhoto, error: Error?) {
if let imageData = photo.fileDataRepresentation(), let image = UIImage(data: imageData) {
capturedImage = cropImage(image, to: previewLayer.frame)
performSegue(withIdentifier: "showImagePreview", sender: self)
}
}以上代码的核心功能是将捕获的照片流转换为图像数据表示,并对该图像进行裁剪以适应手机屏幕的显示范围。
完成应用程序中处理摄像头拍摄逻辑所需的全部工作后。接下来,我们将学习如何使用摄像头拍摄的图像执行机器学习模型推理,并在 iOS 应用中显示模型预测结果。
3. 运行机器学习模型推理
本节的 iOS 应用最重要且最核心的源代码位于 PreviewViewController.swift 文件中。该文件包含的 PreviewViewController 类定义了多个关键对象和方法,这些是实现应用功能并在拍摄图像上显示ML模型预测结果的核心要素:
swift
class PreviewViewController: UIViewController {
@IBOutlet var imageView: UIImageView!
@IBOutlet var resultView: UITextView!
var capturedImage: UIImage?首先,定义 imageView 对象,用于在预览屏幕上显示拍摄的图像。在同一预览界面中,模型预测结果将通过 resultView 对象呈现。此处初始化的 capturedImage 对象,正是我们在拍摄界面最终存储图像时使用的同一对象。我们将使用 capturedImage 对象作为输入,传递给 ML 模型进行推理。
接下来,定义 module 变量,用于加载经过移动端优化的 MNIST 模型对象:
swift
private lazy var module: TorchModule = {
if let filePath = Bundle.main.path(forResource: "model", ofType: "pt"),
let module = TorchModule(fileAtPath: filePath) {
return module
} else {
fatalError("Can't find the model file!")
}
}()我们首先检查模型文件是否存在于目标路径,随后将其加载为 TorchModule 对象。此步骤使用 TorchModule 正是本节需要通过 pod install 安装 libtorch 的原因。TorchModule 具备多重优势:提供简化的序列化操作、支持设备无关的高效计算,并能与 PyTorch 生态系统无缝集成,从而显著简化模型部署与执行流程。
接下来,我们定义 String 类型的 Labels 变量,该变量用于将 ML 模型输出的原始数值映射到 0 至 9 这 10 个数字类别,最终以字符串形式将识别数字显示在应用界面上:
swift
private lazy var labels: [String] = {
if let filePath = Bundle.main.path(forResource: "digits", ofType: "txt"),
let labels = try? String(contentsOfFile: filePath) {
return labels.components(separatedBy: .newlines)
} else {
fatalError("Can't find the text file!")
}
}()以上代码会加载 labels.txt 文件(该文件与 model.pt 模型文件位于同一目录下),该文件简单地列出了数字 0 到 9 (每行一个数字)。最后,是 viewDidLoad 方法,在此方法中实现了运行模型推理和显示预测结果的逻辑:
swift
override func viewDidLoad() {
super.viewDidLoad()
imageView.image = capturedImage
guard let resizedImage = capturedImage?.resized(to: CGSize(width: 28, height: 28)),
var pixelBuffer = resizedImage.grayscaleNormalized() else {
return
}
// imageView.image = resizedImage
guard let outputs = module.predict(image: UnsafeMutableRawPointer(&pixelBuffer)) else {
return
}
print("Raw Predictions: \(outputs)") // Print the raw predictions array
// Find the index of the maximum value in the outputs array
if let maxIndex = outputs.indices.max(by: { outputs[$0].floatValue < outputs[$1].floatValue }) {
let predictedDigit = maxIndex // This is the predicted digit
print("Predicted Digit: \(predictedDigit)")
resultView.text = "Predicted Digit: \(predictedDigit)"
} else {
print("Unable to determine predicted digit")
resultView.text = "Unable to determine predicted digit"
}
}在此方法中,首先,通过 resized 方法将图像调整为 (28, 28) 像素,然后使用 grayscaleNormalized 方法将调整大小后的图像转换为灰度图像,并使用基于 MNIST 数据集的均值和标准差值对其像素值进行归一化。resized 和 grayscaleNormalized 方法都在 UIImage+Helper.swift 文件中定义。
随后,我们对归一化后的图像调用 module.predict 方法执行模型推理,获取 MNIST 模型输出的类别概率分布。系统会记录原始概率值用于调试,同时通过 labels 变量将最高概率对应的数字类别转换为字符串。最终该字符串将显示在预览界面的 resultView 控件下方。下图展示了多个预览界面示例,可见 ML 模型能准确识别拍摄图像中的手写数字。

如图所示,本节构建的 iOS 应用程序能够基于优化的移动端 MNIST 手写识别模型,对不同图像准确识别并输出正确结果。
该应用可通过两种方式在 iPhone 上运行:通过无线连接或使用 USB 数据线将 iPhone 与正在 Xcode 进行开发的 MacBook 相连。连接成功后,将在 Xcode 窗口顶部中央的下拉菜单中看到设备选项(显示 My Mac (Designed for iPhone) 的标签页)。选择设备并点击 Xcode 集成开发环境左上角面板的运行按钮,系统将首先构建项目,随后在 iPhone 上启动应用程序。
小结
在本节中,我们详细介绍了将 PyTorch Mobile 优化的 MNIST 手写数字识别模型部署到 iOS 平台的过程。通过配置 Xcode 开发环境,集成 LibTorch-Lite 库,并利用 Swift 编写摄像头图像采集和处理模块,实现了对手写数字图像的实时拍摄和识别。应用成功将拍摄图像预处理为模型输入格式,执行推理并显示识别结果,验证了移动端模型在 iOS 设备上的有效部署和准确识别能力。
系列链接
PyTorch深度学习实战(1)------神经网络与模型训练过程详解
PyTorch深度学习实战(2)------PyTorch基础
PyTorch深度学习实战(3)------使用PyTorch构建神经网络
PyTorch深度学习实战(4)------常用激活函数和损失函数详解
PyTorch深度学习实战(6)------神经网络性能优化技术
PyTorch深度学习实战(7)------批大小对神经网络训练的影响
PyTorch深度学习实战(10)------过拟合及其解决方法
PyTorch深度学习实战(13)------可视化神经网络中间层输出
PyTorch深度学习实战(16)------面部关键点检测
PyTorch深度学习实战(19)------从零开始实现R-CNN目标检测
PyTorch深度学习实战(20)------从零开始实现Fast R-CNN目标检测
PyTorch深度学习实战(21)------从零开始实现Faster R-CNN目标检测
PyTorch深度学习实战(22)------从零开始实现YOLO目标检测
PyTorch深度学习实战(23)------从零开始实现SSD目标检测
PyTorch深度学习实战(24)------使用U-Net架构进行图像分割
PyTorch深度学习实战(25)------从零开始实现Mask R-CNN实例分割
PyTorch深度学习实战(26)------多对象实例分割
PyTorch深度学习实战(27)------自编码器(Autoencoder)
PyTorch深度学习实战(28)------卷积自编码器(Convolutional Autoencoder)
PyTorch深度学习实战(29)------变分自编码器(Variational Autoencoder, VAE)
PyTorch深度学习实战(30)------对抗攻击(Adversarial Attack)
PyTorch深度学习实战(32)------Deepfakes
PyTorch深度学习实战(33)------生成对抗网络(Generative Adversarial Network, GAN)
PyTorch深度学习实战(34)------DCGAN详解与实现
PyTorch深度学习实战(35)------条件生成对抗网络(Conditional Generative Adversarial Network, CGAN)
PyTorch深度学习实战(36)------Pix2Pix详解与实现
PyTorch深度学习实战(37)------CycleGAN详解与实现
PyTorch深度学习实战(38)------StyleGAN详解与实现
PyTorch深度学习实战(39)------少样本学习(Few-shot Learning)
PyTorch深度学习实战(40)------零样本学习(Zero-Shot Learning)
PyTorch深度学习实战(41)------循环神经网络与长短期记忆网络
PyTorch深度学习实战(44)------基于 DETR 实现目标检测
PyTorch深度学习实战(47)------使用PyTorch构建Transformer模型
PyTorch深度学习实战(48)------基于Transformer实现机器翻译
PyTorch深度学习实战(49)------扩散模型(Diffusion Model)详解与实现
PyTorch深度学习实战(50)------PyTorch分布式训练
PyTorch深度学习实战(51)------自动混合精度训练
PyTorch深度学习实战(52)------PyTorch深度学习模型部署
PyTorch深度学习实战(53)------使用TorchServe部署PyTorch模型