不知道如何使用 Claude Code?本篇 Claude Code 教程带你从零配置 AI 编程环境。学习如何编写 CLAUDE.md 建立项目记忆、管理上下文 Token、以及使用 Plan Mode(计划模式)安全地重构代码,提升 10 倍开发效率。
现在机器人都满地跑了,你不会还是只把AI当聊天工具那样用吧?遇到问题,把代码复制进去,提问,再把生成的代码贴回来,这是不是你?但是这种方法有个问题,你的每次提问都是在开启全新的对话,AI 根本不了解项目的整体目录结构、团队的代码规范,更不知道某个模块已经重构了三天。
想要真正发挥 AI 的生产力,需要将其视为一个可以无缝接入本地工程的开发环境。当然,对于程序员来说,首选当然是 Anthropic 推出的 Claude Code 啦,AKA GitHub Copilot 替代品。
本文是完整指南的第一部分。我们将给新手深入拆解如何配置和使用 Claude Code CLI,让它成为一个真正懂业务的本地 Claude 编程助手。(如果你是个高手高手高高手,就不用看了。)
一、 基础准备与环境接入
要让 AI 接入本地工作流,第一步是在终端中叫醒它,就像你的闹钟叫醒你去上班一样。
Claude Code 安装步骤
运行该工具的前提是本地已具备 Node.js 环境。对于不想折腾 nvm 或环境变量的开发者,推荐直接使用 ServBay 来部署。
作为一款集成化的本地开发环境管理工具,ServBay 提供的图形界面能支持一键安装各个开发语言的运行环境。只需在软件中点选所需的 Node.js 版本,即可完成秒级部署,彻底免去手动配置环境变量的烦恼。
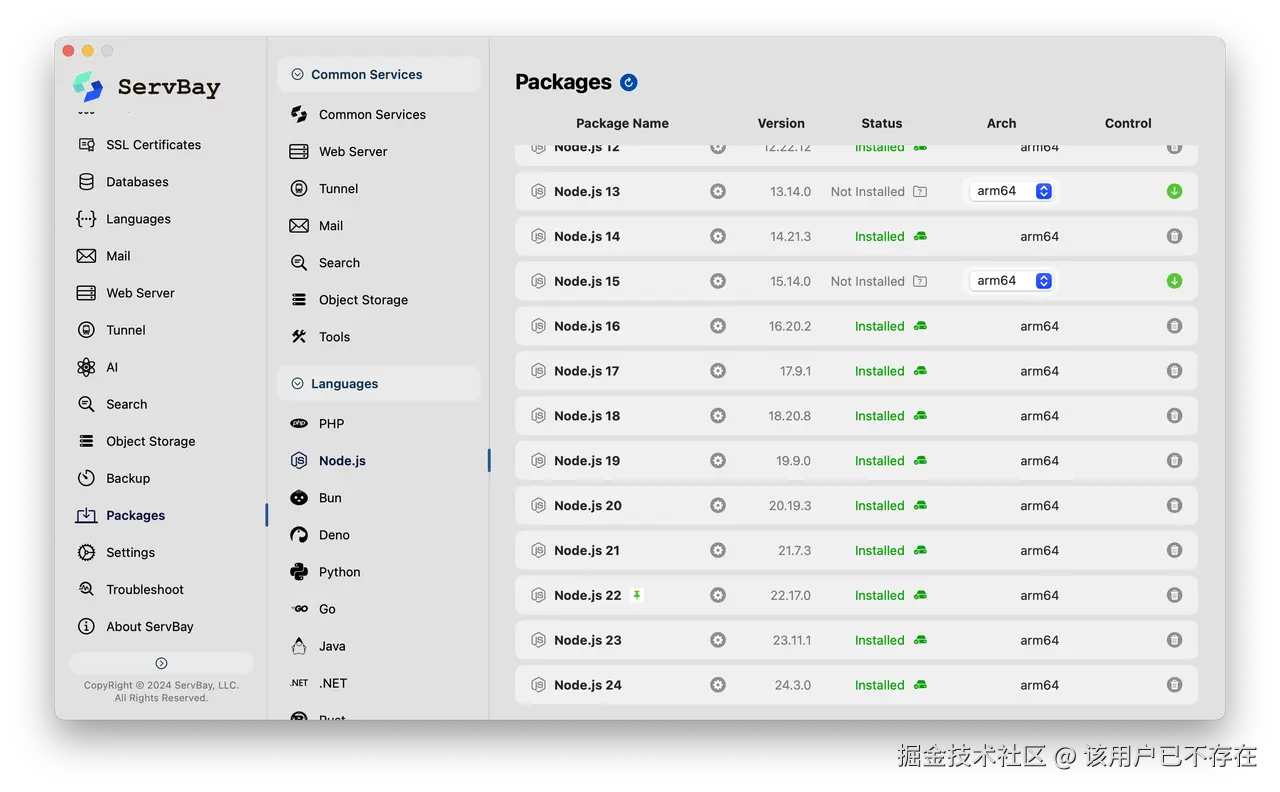
通过 ServBay 准备好环境后,打开终端执行以下命令进行全局安装。
bash
npm i -g @anthropic-ai/claude-code安装完成后,输入 claude --version 验证是否成功。首次运行会自动弹窗请求 Anthropic API 密钥或 Claude Pro 订阅授权。
环境初始化后,当前项目和全局目录下会生成特定的配置文件。理解这些文件的层级分布有助于后续的团队协作与个性化设置。
项目根目录的 .claude/ 文件夹内存放着 settings.json(可提交到 Git 供团队共享)和 settings.local.json(本地忽略,用于个人偏好覆盖)。
系统用户目录 ~/.claude/ 下则存放着全局通用的配置偏好。
这种分离机制保证了团队在代码规范上保持一致,同时开发者又能保留个人的终端操作习惯。
二、 建立项目全局上下文
AI 写代码如何记住项目上下文是一个普遍痛点。如果每次都要重复解释业务逻辑,效率就会大大降低,就像你天天要跟你的同事重复一遍业务一样。Claude Code 解决这个问题的方案是建立项目记忆。
在终端进入项目根目录,输入 claude 启动界面,随后输入 /init 命令。
此时程序会自动扫描本地代码库,分析 package.json 中的依赖项、目录架构以及现有的技术栈特征,最终在根目录生成一个 CLAUDE.md 文件。
CLAUDE.md 怎么写
这个文件是整个工作流的大脑。每次启动对话前,程序都会优先读取其中的指令。一份结构清晰的配置可以大幅降低沟通成本。以下是一个针对全栈项目的编写示例。
Markdown
# 项目名称 SaaS 仪表盘
## 技术架构
- 前端 React 18 + Vite
- 状态管理 Zustand
- 后端 NestJS + TypeScript
- 数据库 MySQL + TypeORM
## 目录规范
- `/frontend/src/views` 存放页面级组件
- `/frontend/src/shared` 存放公共纯函数与 Hooks
- `/backend/src/modules` 按业务模块划分后端逻辑
## 编码约束
- 前端组件统一使用箭头函数和解构赋值
- 接口响应格式必须遵循 { code, data, message } 结构
- 严禁在 TypeScript 中使用 any 类型,遇到复杂类型需定义 interface
- 所有的日期处理统一调用 dayjs 库,不要使用原生 Date
## 常用脚本
- `npm run dev:all` 启动前后端本地服务
- `npm run lint` 执行代码规范检查把这些规则写清楚后,下一次安排新增一个数据展示接口时,程序会自动按照规范的格式返回数据,并把文件存放到指定的 /backend/src/modules 目录下。
需要防范的是,绝对不要把数据库密码或 API 密钥写进这个文件,因为它会跟随代码提交到版本控制系统中。
三、 内存管理与拒绝上下文臃肿
终端界面中有一个上下文指示器,它反映了当前对话的内存占用情况。
随着对话的深入,引用的文件越来越多,上下文窗口会被逐渐填满。当占用率超过 75% 时,响应速度会明显下降,甚至会出现遗忘早期指令的现象。也能理解,毕竟人都不一定能记住那么多事情。所以,盲目扩充上下文并不是长久之计,精细化管理才是正解。
精准引入文件
最大的误区是一次性把整个 src 目录扔给程序。正确的做法是按需加载。使用 @ 符号加上文件名,可以精准挂载目标文件。
例如提示词可以这样写,检查 @frontend/src/views/Login.tsx 中的表单校验逻辑,修复密码长度验证报错的问题。这种按需读取的方式能极大节省 Token 消耗。
对话状态压缩
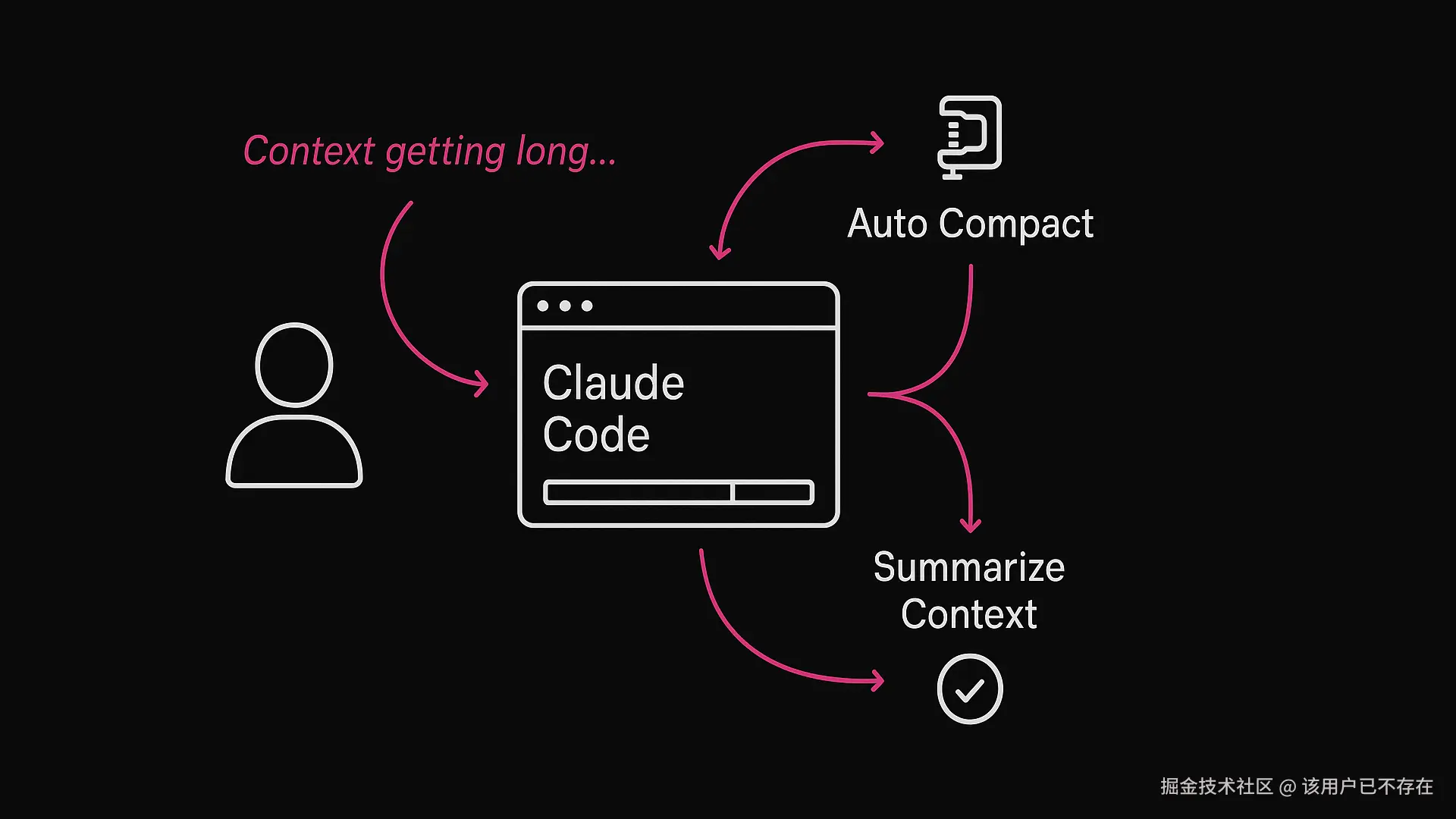
当一个功能模块开发到一半,上下文指示器已经标红时,可以使用 /compact 命令。
执行该命令后,程序会将冗长的历史对话压缩成摘要,保留关键的技术决策、当前的任务进度和文件修改状态,同时丢弃那些试错过程中的废话。
如果是开启一项与之前完全无关的新任务,则直接使用 /clear 命令清空对话历史。此时 CLAUDE.md 中的项目记忆依然生效,只是重置了当前的沟通记录。
四、 掌控执行权,防止代码被改坏
在实际开发场景中,你要注意,小心 AI 乱改你的代码,尤其是在处理涉及多个文件的重构任务时,如果直接下手修改,很容易引发连锁报错。
Claude Code 提供了不同的交互模式来应对不同复杂度的任务。
计划模式 (Plan Mode)
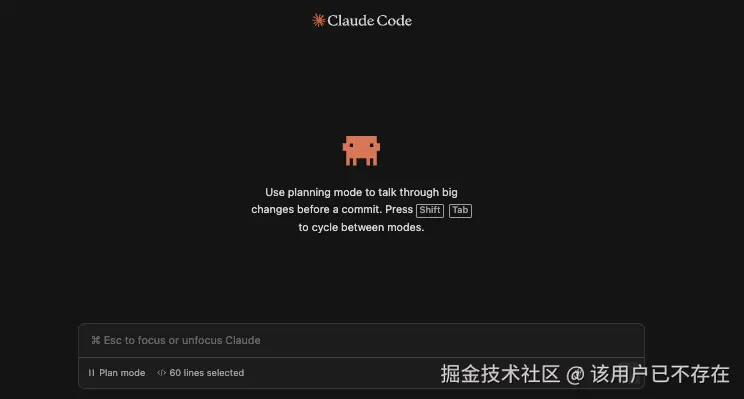
按下 Shift+Tab 键可以切换到计划模式。这是进行复杂开发时极具价值的特性。
在该模式下输入需求后,程序不会立刻动手写代码,而是先输出一份详细的执行步骤。
例如要求把原有的 Session 登录重构为 JWT 登录。程序会列出如下计划。
-
安装相关的 jsonwebtoken 依赖包
-
在工具类目录下创建 token 生成与解析方法
-
修改后端的登录接口,用 JWT 替换原有的 Session 逻辑
-
更新前端的拦截器,在请求头中携带 Token
开发者可以先审核这份计划,确认无误或提出修改意见后,再批准其执行。这相当于在动手前先进行了一次方案评审,从根本上杜绝了代码库被大面积破坏的风险。
扩展思考模式 (Extended Thinking)
遇到偶发性的深层 Bug 或需要权衡利弊的架构设计时,可以开启扩展思考模式。这会消耗更多的计算资源,让程序在给出最终答案前进行更深度的内部推理。通常用于排查疑难杂症,不建议在日常简单的增删改查任务中开启。
五、 权限与安全边界
作为一个本地化运行的命令行工具,它具备读取文件、修改代码甚至执行 Shell 脚本的能力。基于最小权限原则,程序在执行敏感操作前都会弹窗请求授权。
开发者可以根据项目的信任级别,在配置文件中自定义权限边界。修改本地的 settings.json 文件即可实现管控。
json
{
"permissions": {
"allowedTools": ["Read", "Write", "Glob", "Bash(npm run dev)"],
"blockedTools": ["Bash(rm *)", "Bash(git push -f)"],
"autoApprove": ["Write(frontend/src/views/*)"]
}
}上述配置中,allowedTools 划定了白名单,blockedTools 锁死了危险操作,而 autoApprove 则允许程序在特定目录下修改代码时免除弹窗打扰。永远不要把宽泛的终端执行权限加入自动批准列表。
第一部分总结与下期预告
在第一部分中,我们完成了基础环境的搭建。通过 ServBay 部署 Node.js 环境,生成了规范的 CLAUDE.md 项目记忆,掌握了精细化的上下文管理技巧,并学会了使用计划模式和权限控制来保护代码安全。
这套体系搭建完成后,命令行 AI 编程工具才算真正融入了本地研发工作流。
在即将发布的第二部分中,我们将探讨更高级的进阶能力,包括如何配置 MCP(模型上下文协议)连接外部数据库与文档,以及如何为 Claude 编写自定义技能,进一步解放生产力。