文章目录
-
- 前言
- [一、 为什么用ConcurrentHashMap](#一、 为什么用ConcurrentHashMap)
-
- [1.1 什么是 ConcurrentHashMap](#1.1 什么是 ConcurrentHashMap)
- [1.2 为什么用ConcurrentHashMap](#1.2 为什么用ConcurrentHashMap)
- [二、 并发和锁的基础知识](#二、 并发和锁的基础知识)
-
- [2.1 缘起:硬件的"木桶效应"与 JMM 的诞生](#2.1 缘起:硬件的“木桶效应”与 JMM 的诞生)
- [2.2 并发编程的三大核心危机](#2.2 并发编程的三大核心危机)
-
- [2.2.1 可见性问题:CPU 缓存引发的"盲区"](#2.2.1 可见性问题:CPU 缓存引发的“盲区”)
- [2.2.2 原子性问题:线程切换带来的"半途而废"](#2.2.2 原子性问题:线程切换带来的“半途而废”)
- [2.2.3 有序性问题:编译优化的"移花接木"](#2.2.3 有序性问题:编译优化的“移花接木”)
- [2.3 破局:Java 提供的底层利器](#2.3 破局:Java 提供的底层利器)
-
- [2.3.1 synchronized(宏观锁)](#2.3.1 synchronized(宏观锁))
- [2.3.2 volatile 与 Happens-Before 原则](#2.3.2 volatile 与 Happens-Before 原则)
- [2.3.3 CAS (Compare And Swap - 无锁化原子操作)](#2.3.3 CAS (Compare And Swap - 无锁化原子操作))
- [三、 数据结构进化历程](#三、 数据结构进化历程)
-
- [3.1 史前时代:数组与链表的"极限拉扯"](#3.1 史前时代:数组与链表的“极限拉扯”)
- [3.2 第一次进化:哈希表(数组 + 链表)的诞生](#3.2 第一次进化:哈希表(数组 + 链表)的诞生)
- [3.3 第二次终极进化(JDK8):红黑树的破局](#3.3 第二次终极进化(JDK8):红黑树的破局)
- [四、 常见面试问题](#四、 常见面试问题)
- [五、 实战使用场景](#五、 实战使用场景)
-
- [5.1 场景一:本地高并发缓存 (Local Cache)](#5.1 场景一:本地高并发缓存 (Local Cache))
- [5.2 场景二:实时数据统计汇总](#5.2 场景二:实时数据统计汇总)
- 总结
前言
一、 为什么用ConcurrentHashMap
1.1 什么是 ConcurrentHashMap
简单来说,ConcurrentHashMap 是 Java 并发包(java.util.concurrent)中提供的一个线程安全的高效哈希表。
它的核心功能和 HashMap 一样,都是用来存储键值对(Key-Value)数据的,但它允许多个线程同时对它进行读写操作而不会把数据搞乱。
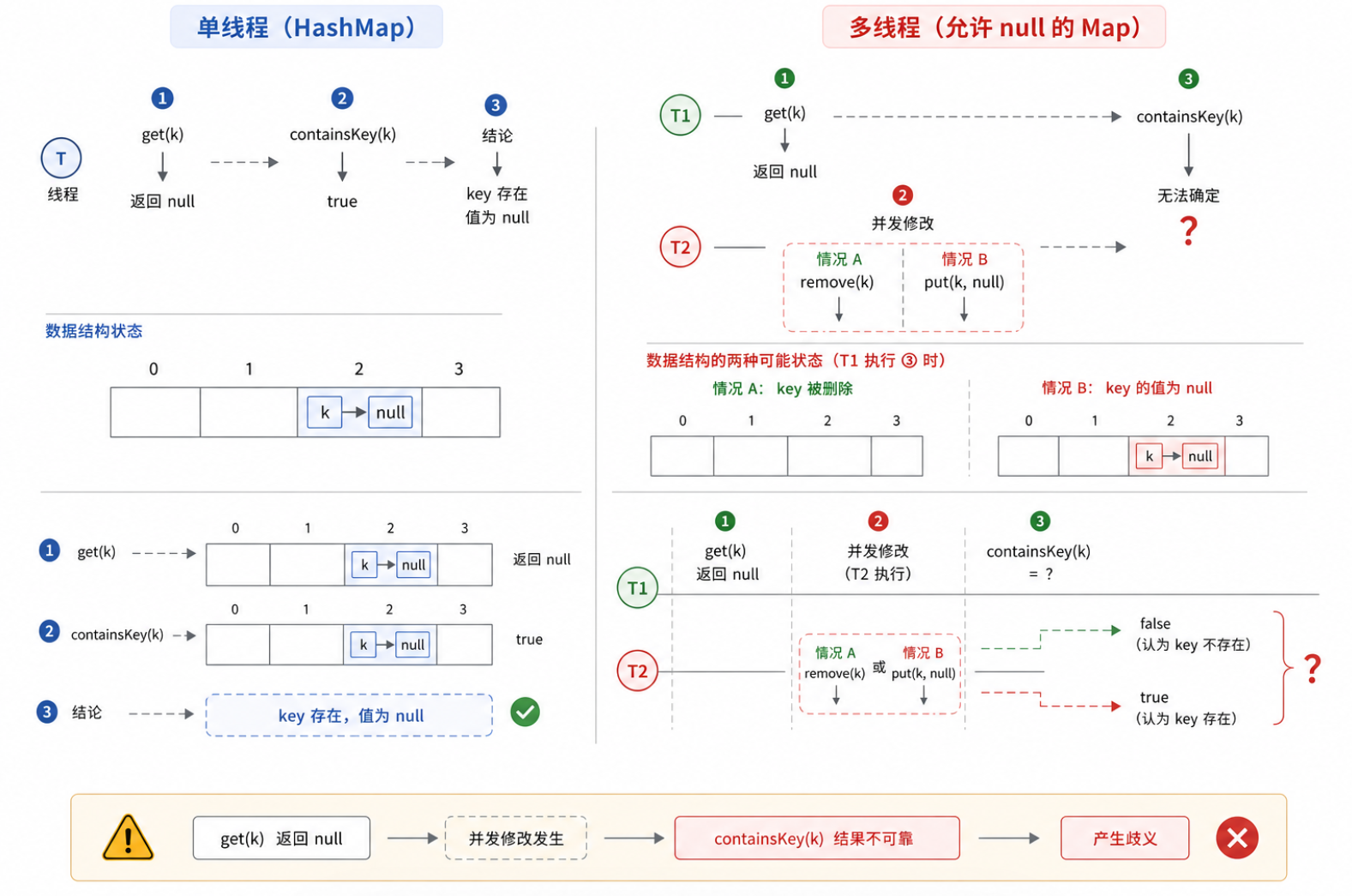
在单线程的 HashMap 中,key 和 value 都允许为 null。但在ConcurrentHashMap中,key 和 value 绝对不能为 null。
- 原因: 这是为了防范并发环境下的"二义性(歧义)"问题。如果
get(key)返回了 null,你根本无法确认是"这个 key 不存在",还是"这个 key 的 value 被设置成了 null"。在单线程中,你可以通过containsKey(key)去验证;但在多线程中,你验证的瞬间数据可能已经被其他线程篡改了。
1.2 为什么用ConcurrentHashMap
单线程时,HashMap 跑得飞快。但一旦在多线程情况下,就会暴露出数据不一致问题。
归根结底,这种不一致是由 Java 内存模型(JMM) 导致的,在宏观上主要表现为两类冲突:
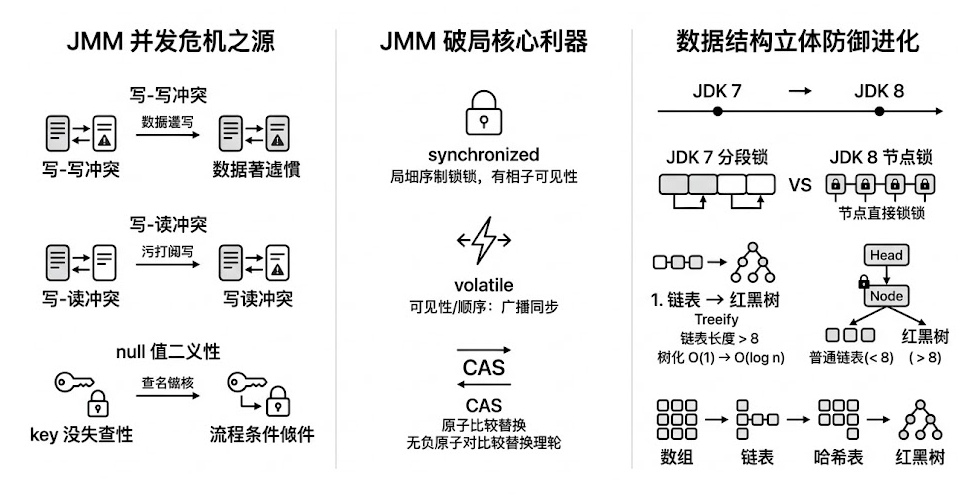
- 写-写冲突: 两个线程同时对同一个位置进行修改,导致其中一个线程的数据被无情覆盖(数据丢失)。
- 写-读冲突: 一个线程刚刚修改了数据,但由于工作内存未及时刷入主内存,另一个线程去读的时候,拿到的依然是旧数据(读到脏数据)。
为了解决数据不一致问题,最直观的解法就是加锁 ,这也是 HashMap 向 ConcurrentHashMap 演进的核心推手。
然而,粗暴的加锁会极大拖累系统性能。因此,提升高并发容器性能的关键思路在于:尽量减小锁的粒度,并尽可能找出可以"无锁化"的操作。
在设计时,需要对读写操作"分而治之":
- 写操作: 只要涉及数据的改动,必然需要加锁兜底,此时架构设计的核心考量就是尽力缩小锁的粒度(例如从锁整个 Map 缩小到只锁一个节点)。
- 读操作: 在写操作保证不出错的前提下,读操作相对好办。核心在于取舍"是否需要实时读到最新数据":
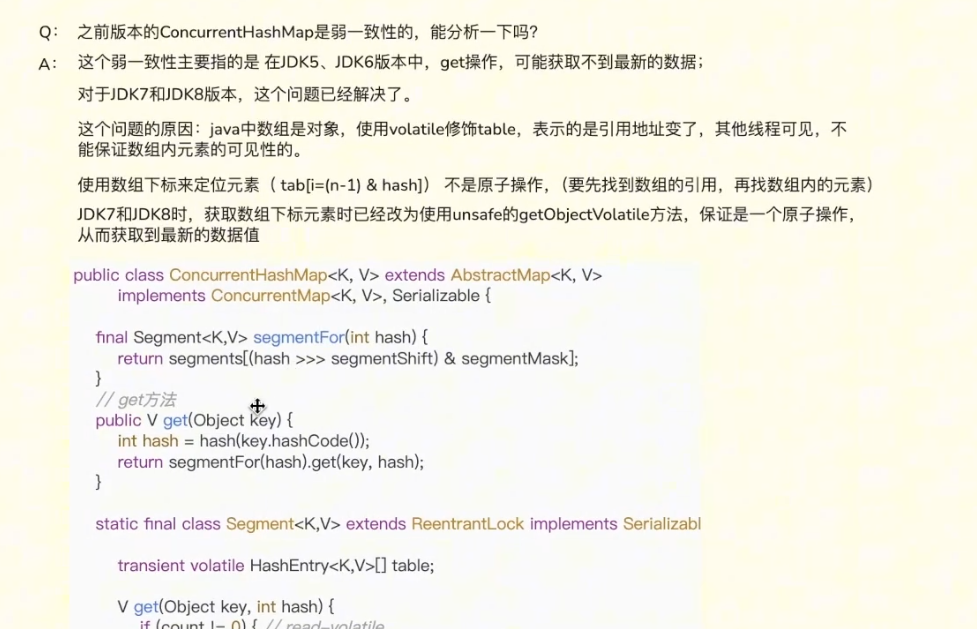
- 强一致性: 读写双重加锁,绝对安全但性能最差(如
HashTable)。 - 顺序一致性: 使用
volatile关键字,不加锁但能保证数据的可见性。 - 弱一致性: 读完全不加锁,容忍极端情况下的微小延迟,追求极致性能
- 强一致性: 读写双重加锁,绝对安全但性能最差(如
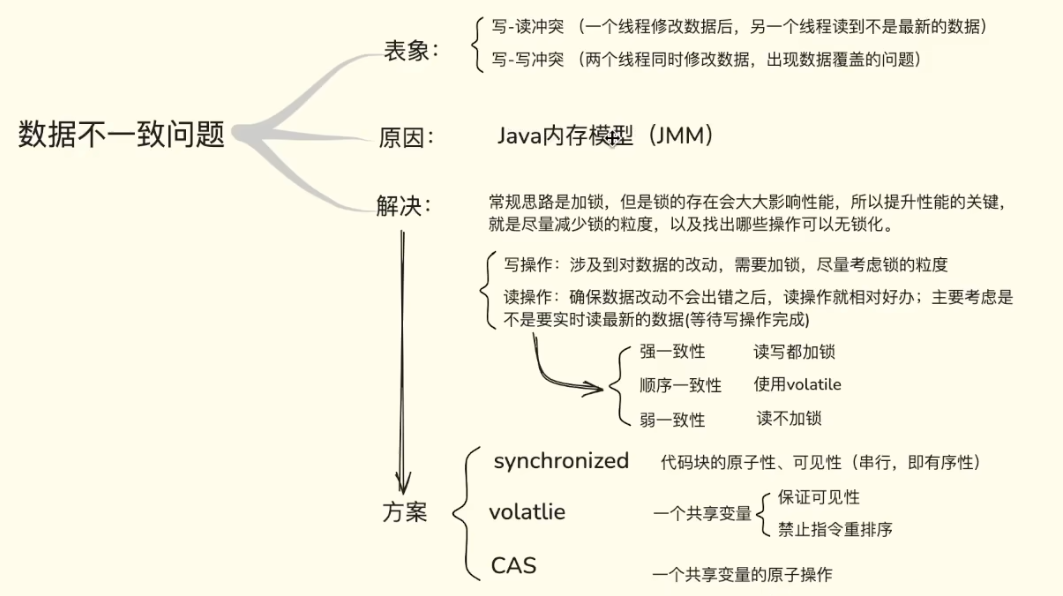
为了在"安全"与"性能"之间平衡,ConcurrentHashMap 并没有采用单一的加锁手段,而是综合运用了以下三种核心底层方案:
- synchronized: 用于保证特定代码块的原子性 和可见性(使操作局部串行化,保证有序)。
- volatile: 轻量级同步机制,作用于单个共享变量。它像是一个全网广播,既能保证数据的可见性 ,又能禁止指令重排序。
- CAS (Compare-And-Swap): 乐观锁机制,利用底层硬件指令实现针对单个共享变量的无锁原子操作。
简而言之,ConcurrentHashMap 正是巧妙地运用这三点,解决了 HashMap 的多线程问题。
二、 并发和锁的基础知识
2.1 缘起:硬件的"木桶效应"与 JMM 的诞生
计算机的核心硬件在发展过程中存在巨大的速度鸿沟:CPU 最快,内存次之,I/O 设备(硬盘)最慢。为了不让 CPU 闲着等数据,计算机体系结构、操作系统和编译器分别做出了妥协与优化,但这恰恰是并发问题的根源:
- CPU 增加了高速缓存(Cache),以均衡与内存的速度差异。
- 操作系统增加了进程/线程,以分时复用 CPU(任务切换),均衡 CPU 与 I/O 的差异。
- 编译器优化指令执行次序,使得缓存能够得到更合理的利用。
为了屏蔽各种硬件和操作系统的内存访问差异,让 Java 程序在各平台下都能达到一致的效果,Java 内存模型(JMM,Java Memory Model) 应运而生。 JMM 规定:
- 所有的共享变量 都存储在主内存中。
- 每个线程都有自己的工作内存,里面保存了被该线程使用的共享变量的副本。
- 线程对共享变量的所有操作(读、写)都必须在工作内存中进行,绝对不能直接读写主内存。不同线程之间也无法直接访问对方工作内存中的变量。
这种架构虽然高效,但在多线程下直接引爆了并发编程的"三大底层危机"。
2.2 并发编程的三大核心危机
2.2.1 可见性问题:CPU 缓存引发的"盲区"
定义: 一个线程对共享变量的修改,另一个线程能够立刻看到,这就叫可见性。 危机成因: 在多核心架构下,线程 A 运行在 CPU-1 上,线程 B 运行在 CPU-2 上。线程 A 修改了工作内存(对应 CPU-1 缓存)中的变量 val,但还没来得及同步到主内存;此时线程 B 去读 val,读到的依然是 CPU-2 缓存或主内存中的旧值。这就是 CPU 缓存导致的可见性盲区。
2.2.2 原子性问题:线程切换带来的"半途而废"
定义: 我们把一个或者多个操作在 CPU 执行的过程中不被中断的特性称为原子性。 危机成因: 高级语言里看似简单的一条语句,往往需要多条 CPU 指令才能完成。这就是违背我们直觉的地方。
- 经典场景:
count += 1。在 CPU 层面,它分为三步:- Load: 把变量
count从内存加载到 CPU 寄存器。 - Add: 在寄存器中执行
+1操作。 - Store: 将结果写入内存(缓存)。
- Load: 把变量
- 操作系统的任务切换可以发生在任何一条 CPU 指令 执行完之后。如果线程 A 刚做完"加法"还没写回内存,就被切换到了线程 B,线程 B 拿到的还是旧的
count值进行操作。最终两个线程各加了一次,结果却只增加了 1。
2.2.3 有序性问题:编译优化的"移花接木"
定义: 程序执行的顺序按照代码的先后顺序执行。 危机成因: 编译器和处理器为了优化性能,会对没有数据依赖性的指令进行重排序。
- 经典场景: 双重检查锁(DCL)实现单例模式。
instance = new Singleton();这行代码底层分为三步:- 分配一块内存空间 M。
- 在内存 M 上初始化 Singleton 对象。
- 将 M 的地址赋值给
instance变量。
- 重排序灾难: 编译器可能将执行顺序优化为
1 -> 3 -> 2。当线程 A 执行完 1 和 3 时,instance已经不是 null 了,但对象还没初始化。此时如果线程 B 进来判断instance == null为 false,直接拿走这个半成品对象去使用,就会触发空指针异常。
2.3 破局:Java 提供的底层利器
为了解决上述的可见性、原子性和有序性问题,JMM 定义了 8 种底层操作(lock, unlock, read, load, assign, use, store, write),并提供了以下并发控制工具:
2.3.1 synchronized(宏观锁)
提供了更大范围的原子性保证。在底层,它通过字节码指令 monitorenter 和 monitorexit 隐式地使用了 lock 和 unlock 操作。
- 它不仅保证了被锁定代码块的原子性 (单线程串行执行),同时在解锁前会将变量刷新回主内存,从而也保证了可见性。当遇到数组元素为空等无法加锁的场景时,它无能为力,必须依赖其他手段。
2.3.2 volatile 与 Happens-Before 原则
volatile 是一把轻量级的神兵利器,专门针对可见性和有序性:
- 可见性: 强制将修改后的值立刻刷入主存,并让其他线程的工作内存缓存失效。(注意避坑:Java 中数组是对象,
volatile修饰数组时,只能保证数组引用地址的可见性,如果数组内部元素发生改变,是无法保证可见性的!这也是为什么 ConcurrentHashMap 底层需要用 Unsafe 来操作数组元素。) - 有序性(禁止重排): 利用内存屏障防止指令重排。
- 底层约束: JMM 定义了 8 条
Happens-Before(先行发生)规则。其中"volatile 变量规则"明确指出:对一个 volatile 变量的写操作,先行发生于后面对这个变量的读操作。
2.3.3 CAS (Compare And Swap - 无锁化原子操作)
高级语言中,除了基本数据类型的直接读写(long 和 double 除外),其他操作(比如 new 一个对象)绝大多数都不是原子操作。
CAS是直接调用 CPU 底层硬件提供的一条原子指令(cmpxchg)。- Java 中通过
Unsafe类提供的方法(如compareAndSwapInt)来暴露 CAS 能力。它通过"比较并替换"的机制,在不加锁、不阻塞线程(仅自旋等待)的情况下,硬生生地保证了单个共享变量修改的原子性。这也是ConcurrentHashMap在空桶插入时能够实现无锁高并发的核心底气。
三、 数据结构进化历程
3.1 史前时代:数组与链表的"极限拉扯"
在最基础的数据结构世界里,数组和链表是两个性格迥异的极端:
- 数组(Array): 内存中连续分配。优势: 拥有绝对的寻址霸权,根据下标查询的时间复杂度是绝对的
O(1)。劣势: 增删元素时需要大面积挪动数据,极其低效。 - 链表(Linked List): 内存中分散存储,通过指针相连。优势: 增删元素只需改变指针指向,时间复杂度
O(1)。劣势: 查找数据只能从头节点顺藤摸瓜,时间复杂度高达O(n)。
痛点: 在高并发、大数据的业务场景中,我们既想要数组的"秒查",又想要链表的"秒插",这能做到吗?
3.2 第一次进化:哈希表(数组 + 链表)的诞生
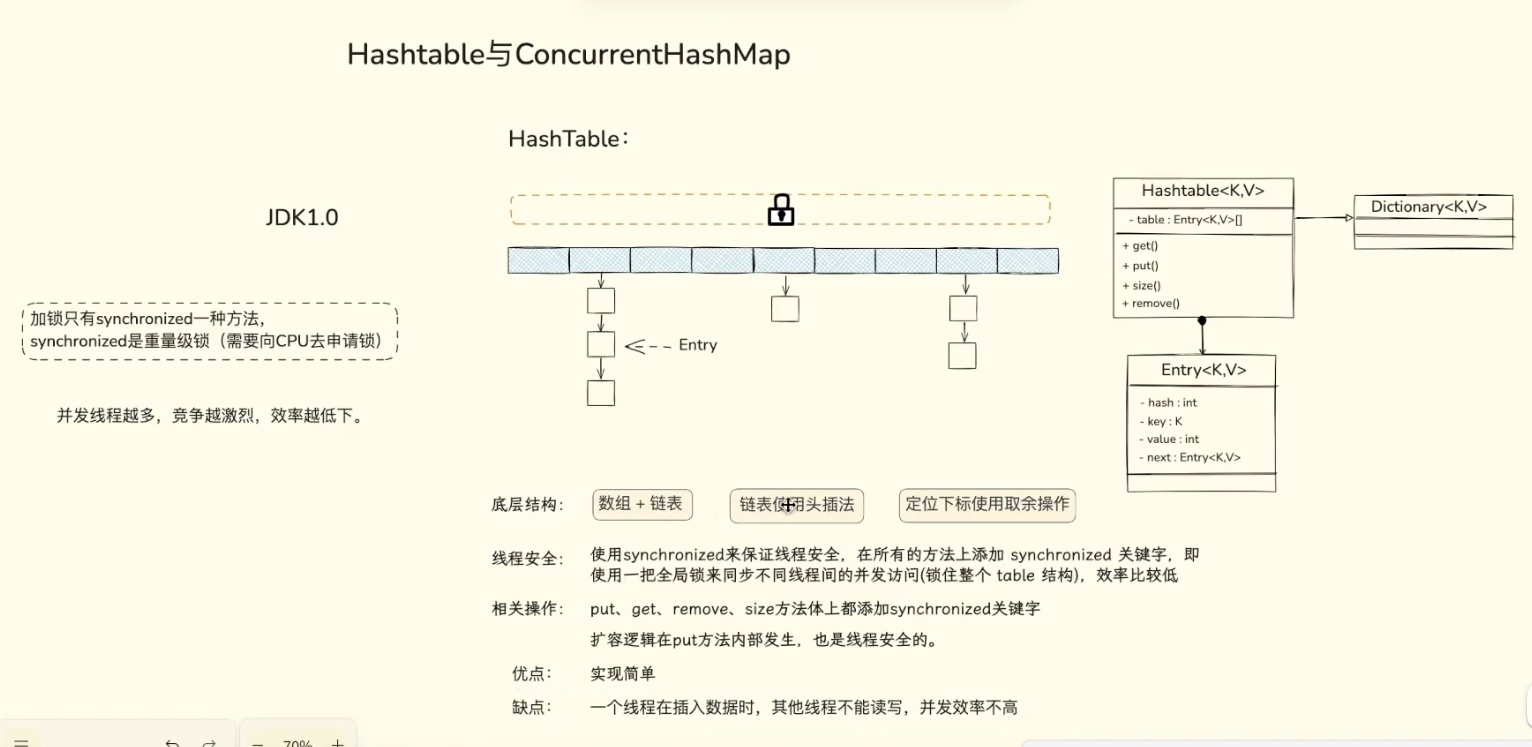
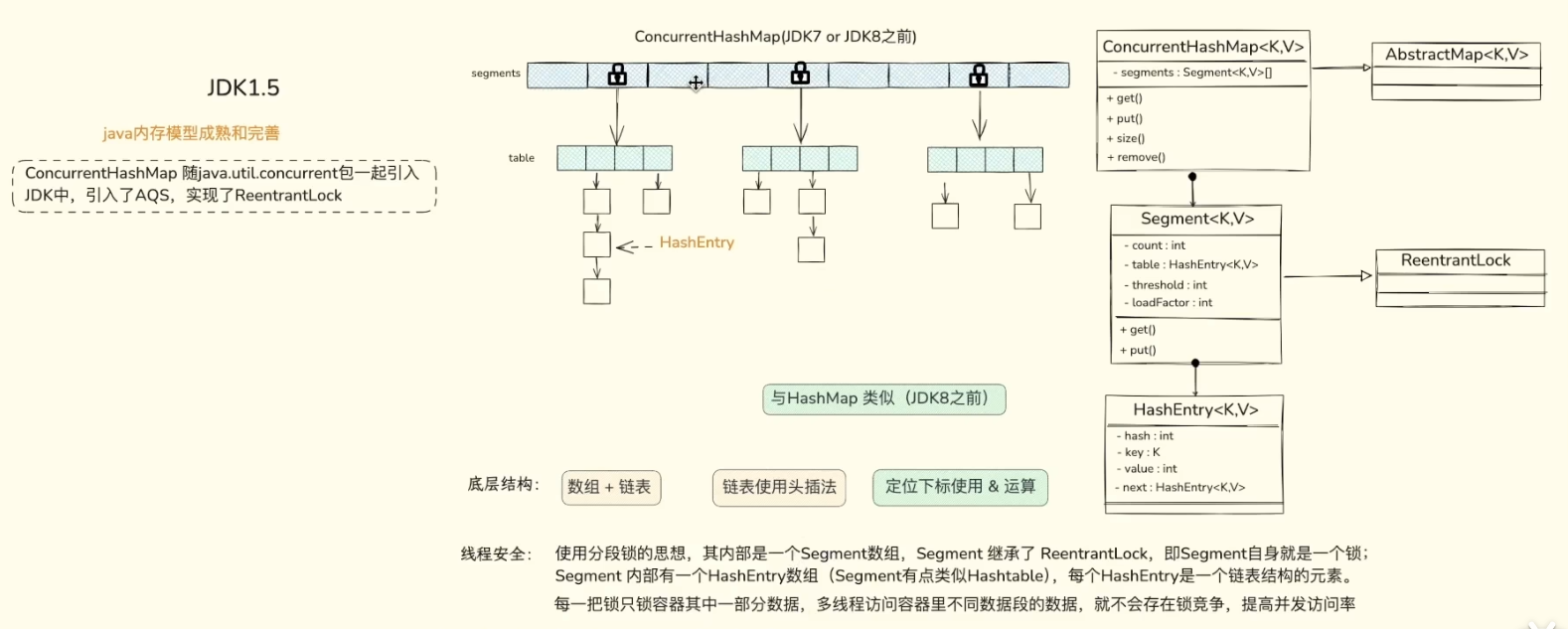
为了融合两者的优点,哈希表(Hash Table) 诞生了。它采用了拉链法(Separate Chaining) ,这也是 JDK7 及之前版本 HashMap 和 ConcurrentHashMap 的底层基石。
- 结构解析: 主体是一个数组。当你插入一个 Key 时,通过哈希函数计算出一个哈希值,然后对数组长度取模,定位到具体的数组下标(也就是哈希桶
Bucket)。 - 解决冲突: 如果两个不同的 Key 算出了相同的下标(哈希冲突),怎么办?就把它们串成一个链表,挂在这个数组节点下面。
- 比喻: 数组就像是酒店的各个楼层,哈希函数是电梯。你瞬间到达指定楼层(O(1)),如果这层住了多个人(冲突),你再挨个敲门寻找(遍历链表)。
随着数据量激增,或者遇到恶意攻击(如 Hash DoS 攻击,故意构造大量哈希值相同的 Key),哈希表的脆弱一面暴露无遗。
- 灾难再现: 当大量的元素全部堆积在同一个哈希桶时,这个桶下面的链表会变得无限长。
- 性能崩塌: 此时,哈希表的查询效率从神坛跌落,由
O(1)极速退化成了单链表的O(n)。如果你去查一个在链表末尾的元素,每一次查询都要经历漫长的遍历,系统甚至会被直接拖垮。

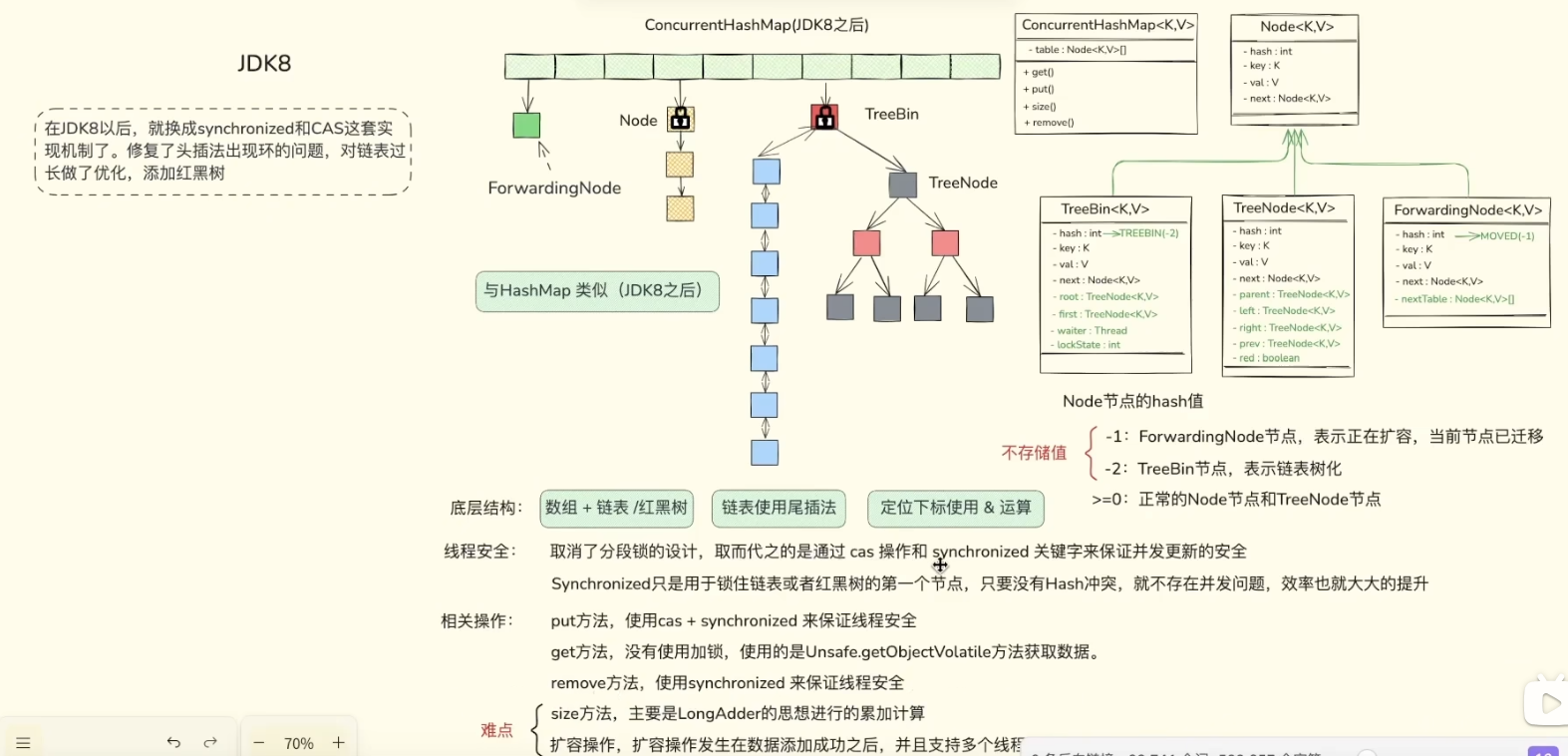
3.3 第二次终极进化(JDK8):红黑树的破局
为了彻底封死链表过长导致的性能退化,JDK8 对 ConcurrentHashMap 和 HashMap 的数据结构进行了史诗级大换血,进化成了数组 + 链表 + 红黑树的终极形态。
当发生哈希冲突时,元素依然先追加到链表上,但加入了严苛的"变异机制":
- 树化触发(Treeify): 当某一个哈希桶的链表长度达到 8 ,并且整个数组的总容量达到 64 时,这条慵懒的单向链表就会瞬间变身为一棵结构严密的红黑树(Red-Black Tree)。
- 退化触发(Untreeify): 当进行扩容或删除节点操作后,如果树中的节点数降到 6,红黑树又会退化回普通链表(利用 6 和 8 之间的差值,防止在 7 这个临界点发生频繁的"树化-退化"抖动)。
为什么是红黑树? 红黑树是一种自平衡的二叉查找树。
- 它的最大威力在于:无论数据怎么插入,它都能通过自身的左旋、右旋和变色,保持树的相对平衡。
- 这样一来,即使发生最极端的哈希冲突,在同一个桶里堆积了成千上万的数据,红黑树也能将最坏情况下的查询时间复杂度死死钉在
O(log n)(例如,100万条数据,最多只需查询 20 次左右),彻底杜绝了性能雪崩。
并发控制视角的升华: 在 JDK8 的 ConcurrentHashMap 源码中,当链表转为红黑树后,桶的头节点会被替换为一个特殊的包装类 TreeBin。此时,如果其他线程来修改数据,锁住的就是这个 TreeBin 节点。这不仅保证了读写的极高效率,还在红黑树复杂的平衡调整(左旋右旋)过程中,完美地维护了并发安全性。
四、 常见面试问题








五、 实战使用场景
理解了底层原理,我们来看看在实际编码中,ConcurrentHashMap 到底能干什么:
5.1 场景一:本地高并发缓存 (Local Cache)
在一些无需动用庞大 Redis 集群的轻量级场景下,它可以作为服务本地的热点数据缓存,抗住极高的并发读取。
Java
// 存储复杂的配置对象或数据字典,避免高并发下反复查库
private static final ConcurrentHashMap<String, ConfigObject> configCache = new ConcurrentHashMap<>();
public ConfigObject getConfig(String key) {
// 利用 computeIfAbsent 保证高并发下,即使缓存击穿,也只有一个线程去执行数据库查询
return configCache.computeIfAbsent(key, k -> loadConfigFromDatabase(k));
}5.2 场景二:实时数据统计汇总
非常适合用作多线程环境下的计数器,例如统计 API 接口的实时访问次数、视频的实时弹幕数等。通常需要配合 AtomicInteger 或更加高效的 LongAdder 一起使用。
Java
private static final ConcurrentHashMap<String, LongAdder> apiRequestCounter = new ConcurrentHashMap<>();
public void recordApiAccess(String apiName) {
// 线程安全的复合操作:如果 apiName 不存在则初始化一个 LongAdder,随后进行原子的递增操作
apiRequestCounter.computeIfAbsent(apiName, k -> new LongAdder()).increment();
}总结
ConcurrentHashMap 的本质,是 Java 在"线程安全"与"高并发性能"之间做出的工程化平衡。
它并不像 Hashtable 那样对整个 Map 粗暴加锁,而是通过:
CAS实现无锁化竞争volatile保证可见性与有序性synchronized只锁局部桶节点数组 + 链表 + 红黑树的复合结构优化查询效率
从而实现:
- 高并发下的数据安全
- 尽可能低的锁竞争
- 极端哈希冲突下依然稳定的性能表现
其底层设计思想,本质上就是一句话:
能无锁就无锁,必须加锁时就尽量缩小锁粒度。
同时,ConcurrentHashMap 也是 Java 并发编程思想的一个缩影,它几乎串联起了:
- JMM(Java 内存模型)
- 可见性 / 原子性 / 有序性
- Happens-Before 原则
- synchronized / volatile / CAS
- 红黑树
- CPU 缓存一致性
等整个 Java 并发体系中的核心知识点。
因此,学习 ConcurrentHashMap,不只是学习一个"线程安全容器",更是在真正理解 Java 高并发底层设计哲学。