为什么要做这件事?
在文档理解领域,大模型方案(如 GPT-4V、Qwen-VL)固然强大,但它们有几个绕不开的问题:
部署成本高 --- 动辄 7B、13B 参数,GPU 显存起步就是十几 GB
依赖链重 --- Python + PyTorch + Transformers + 一堆 C++ 扩展,生产环境部署麻烦
延迟不可控 --- 云端 API 调用有网络波动,私有化部署又有硬件门槛
那如果告诉你,有一个 0.1B 参数的超轻量级模型,配合 ONNX Runtime,能在 纯 CPU 上完成文档的版面检测 + 文本识别 + 公式识别 + 表格解析,整个系统打包成一个 Java JAR 文件就能跑------你会不会感兴趣?这是复旦大学开源的端到端OCR模型,我利用java重新实现了推理识别。面向java研发者,开箱即用。
这就是本文要介绍的项目:OpenOCR4J。
项目地址: openocr4j:https://www.wexopen.com下的工具中心
UniRec-0.1B 是什么?
UniRec(Unified Recognition)是一个统一识别模型,核心设计理念是「一个模型搞定所有」:
┌──────────────────────────────────────────────────┐
│ UniRec-0.1B │
│ │
│ ┌─────────┐ ┌─────────┐ ┌─────────────────┐ │
│ │ 纯文本 │ │ 数学公式 │ │ 文本+公式混排 │ │
│ │ 识别 │ │ 识别 │ │ 混合识别 │ │
│ └────┬────┘ └────┬────┘ └────────┬────────┘ │
│ └────────────┼────────────────┘ │
│ ▼ │
│ 编码器-解码器 + KV Cache │
│ 参数量:仅 0.1B │
└──────────────────────────────────────────────────┘与传统 OCR 方案不同,UniRec 不是一个「检测 + 识别」的两阶段流水线,而是一个端到端的 VLM(Vision-Language Model):
输入:一张文档区域图片
输出:直接生成结构化文本(纯文字、LaTeX 公式、Markdown 等)
这意味着它天然支持混合内容场景------图片里既有文字又有公式时,不需要先「判断区域类型」再「分别处理」,模型自己就能搞定。
0.1B 有多大?
模型 参数量 编码器大小 解码器大小
Qwen-VL-7B 7B --- ---
InternVL-2B 2B --- ---
UniRec 0.1B ~700MB ~700MB
ONNX 格式下,编码器和解码器各约 700MB,分词器映射仅 5MB,总计不到 1.5GB。这个体积放到任何一台普通服务器甚至开发机上都不成问题。
系统架构
完整的文档 OCR 系统由两个 ONNX 模型协同工作:
输入图片
│
▼
┌───────────────────┐
│ PP-DocLayoutV2 │ 版面检测模型
│ (25 种文档元素) │ 检测文本、标题、表格、
│ │ 公式、图片等区域位置
└───────┬───────────┘
│ 检测框列表
▼
┌─────────────────────┐
│ 按区域裁剪图片 │
│ 排除图片/印章区域 │
└───────┬─────────────┘
│ 多个图片块
▼
┌─────────────────────┐
│ UniRec-0.1B VLM │ 统一识别模型
│ (编码器-解码器) │ 每个块独立识别
│ + KV Cache 加速 │ 支持多线程并行
└───────┬─────────────┘
│ 识别文本
▼
┌─────────────────────┐
│ 后处理 │
│ - OTSL → HTML 表格 │
│ - 公式符号标准化 │
│ - Markdown 组装 │
└─────────────────────┘
│
▼
最终 Markdown
版面检测:PP-DocLayoutV2
版面检测模型负责将文档图片「切块」,支持 25 种文档元素类型:
┌─────────────────────────────────┐
│ doc_title (文档标题) │
├─────────────────────────────────┤
│ abstract │ image │
│ (摘要) │ (配图) │
├─────────────────────────────────┤
│ paragraph_title (段落标题) │
│ text text text text text text │
│ text text text text text text │
│ │
│ ┌───────────────────────────┐ │
│ │ table (表格) │ │
│ │ ┌───┬───┬───┬───┐ │ │
│ │ │ │ │ │ │ │ │
│ │ └───┴───┴───┴───┘ │ │
│ └───────────────────────────┘ │
│ │
│ display_formula (展示公式) │
│ E = mc² │
│ │
│ text text text text text text │
├─────────────────────────────────┤
│ footer (页脚) │
└─────────────────────────────────┘统一识别:UniRec-0.1B
每个裁剪出的区域送入 UniRec 模型,它像一个「会看图的打字员」,直接输出结构化文本:
输入区域类型 UniRec 输出
纯文本段落 原文文字(中英文混排)
数学公式 LaTeX 格式(如 E=mc^2)
文本 + 公式混排 Markdown 混合格式(如 当 x\>0 时)
表格 OTSL 格式(后续自动转 HTML)
标题 标题文字(按层级标记)
技术选型:为什么是 Java + ONNX?
这个项目最核心的决策是 Java + ONNX Runtime,而非 Python + PyTorch:
维度 Python + PyTorch Java + ONNX Runtime
运行时依赖 Python 3.8+、PyTorch、Transformers 仅需 JDK 11+ 和一个 JAR
模型格式 需要转换 直接使用 ONNX 格式
部署方式 conda/venv + 模型文件 单个 Fat JAR + 模型文件
生产集成 需要微服务包装 直接嵌入 Java 应用
启动速度 数秒(加载 PyTorch) 毫秒级
内存占用 1~2GB+ 500MB~1GB
GPU 依赖 必须装 CUDA CPU 即可,GPU 可选
ONNX Runtime 是微软开源的推理引擎,它做了极致的性能优化:
支持 CPU 的多线程推理(自动利用所有核心)
支持 AVX2/AVX512 等 SIMD 指令加速矩阵运算
内置图优化(算子融合、内存复用等)
提供 Java 原生绑定,零拷贝传输张量数据
KV Cache:解码效率的关键
UniRec 采用自回归解码,逐 token 生成文本。如果没有优化,每生成一个 token 都要重新处理之前所有 token,复杂度是 O(n²)。
KV Cache 的原理很简单:缓存之前已经计算过的 Key 和 Value 矩阵,每次只处理最新的 token。
Step 1: 输入 BOS → 计算完整 attention → 生成 token₁
→ 缓存 K₁, V₁
Step 2: 输入 token₁ → 用缓存的 K₁,V₁ + 新算的 K₂,V₂
→ 生成 token₂
→ 缓存 K₂, V₂
Step 3: 输入 token₂ → 用缓存的 K₁,V₁,K₂,V₂ + 新算的 K₃,V₃
→ 生成 token₃
...
每次解码步骤的复杂度从 O(n²) 降到 O(n)
在 Java 实现中,KV Cache 通过 TensorData 结构体保存原始张量的多维 shape 信息,确保每次解码时张量维度严格匹配模型期望:
// KV Cache 数据结构(保留完整 shape)
private static class TensorData {
final float[] data; // 扁平化的数据
final long[] shape; // 原始多维 shape
}
// Cross Attention KV: 5D [batch, numLayers, numHeads, seqLen, headDim]
// Self Attention KV: 4D [batch, numHeads, seqLen, headDim]
使用
// === UniRec 通用识别 ===
public static void parseOCR() throws OrtException {
OpenOCR ocr = new OpenOCR(
"unirec", // task
"false", // useGpu
null, // layoutModelPath,可以给确定模型路径;或者设置为null,程序会首次自动下载模型
null, // unirecEncoderPath,可以给确定模型路径;或者设置为null,程序会首次自动下载模型
null, // unirecDecoderPath,可以给确定模型路径;或者设置为null,程序会首次自动下载模型
null, // tokenizerMappingPath,可以给确定模型路径;或者设置为null,程序会首次自动下载模型
0.5, // layoutThreshold
false, // useLayoutDetection
true, // useChartRecognition
4, // maxParallelBlocks
2048 // maxLength
);
// 单张图片
Object result = ocr.call("test1.jpg");
if (result instanceof String[]) {
String text = ((String[]) result)[0];
System.out.println(text);
}
}
// === pdf文档 解析 完整流水线 ===
public static void parseDoc() throws OrtException {
try (OpenOCR ocr = new OpenOCR(
"doc", // task
"false", // useGpu
null, // layoutModelPath,可以给确定模型路径;或者设置为null,程序会首次自动下载模型
null, // unirecEncoderPath,可以给确定模型路径;或者设置为null,程序会首次自动下载模型
null, // unirecDecoderPath,可以给确定模型路径;或者设置为null,程序会首次自动下载模型
null, // tokenizerMappingPath,可以给确定模型路径;或者设置为null,程序会首次自动下载模型
0.5, // layoutThreshold
true, // useLayoutDetection
true, // useChartRecognition
4, // maxParallelBlocks
2048 // maxLength
)) {
// pdf文件
Object result = ocr.call("test2.pdf");
// 保存结果
ocr.saveToMarkdown(result, "./output");
ocr.saveToJson(result, "./output");
}
}
// === 文档图片 解析 完整流水线 ===
public static void parseDoc() throws OrtException {
try (OpenOCR ocr = new OpenOCR(
"doc", // task
"false", // useGpu
null, // layoutModelPath
null, // unirecEncoderPath
null, // unirecDecoderPath
null, // tokenizerMappingPath
0.5, // layoutThreshold
true, // useLayoutDetection
true, // useChartRecognition
4, // maxParallelBlocks
2048 // maxLength
)) {
// 单张图片
Object result = ocr.call("test.jpg");
// 保存结果
ocr.saveToMarkdown(result, "./output");
ocr.saveToJson(result, "./output");
ocr.saveVisualization(result, "./output");
// 针对单张获取 Markdown 字符串
String markdown = ocr.toMarkdown(result);
System.out.println(markdown);
}
}
专题四 曲线运动
241
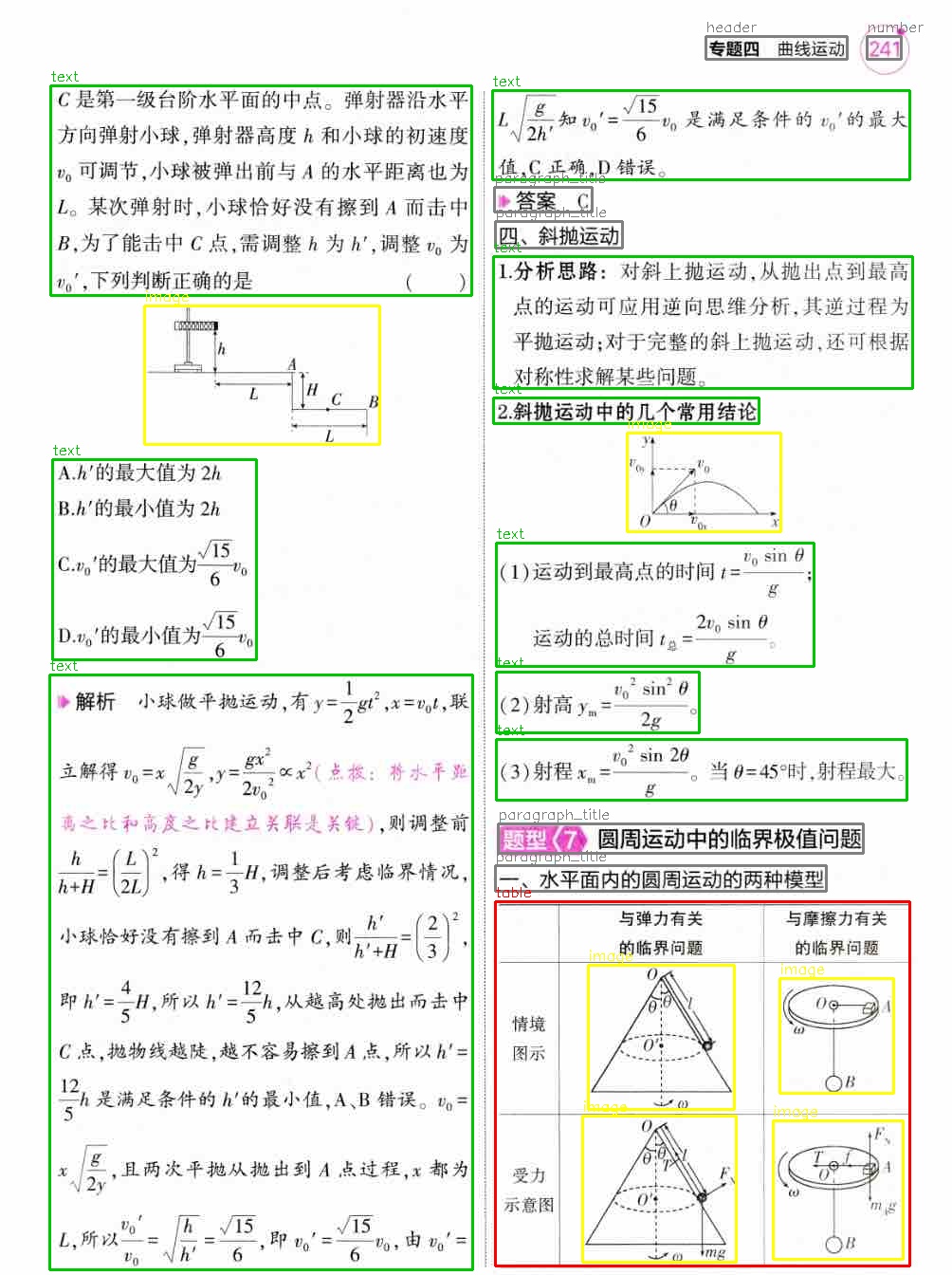
$C$ 是第一级台阶水平面的中点。弹射器沿水平方向弹射小球, 弹射器高度 $h$ 和小球的初速度 $v_{0}$ 可调节, 小球被弹出前与 $A$ 的水平距离也为 $L$。某次弹射时, 小球恰好没有擦到 $A$ 而击中 $B$, 为了能击中 $C$ 点, 需调整 $h$ 为 $h'$, 调整 $v_{0}$ 为 $v_{0}'$, 下列判断正确的是 ( )
<img src="imgs/img_in_image_box_152_322_400_468.jpg" alt="Image" width="80%" />
A. $h'$ 的最大值为 $2h$
B. $h'$ 的最小值为 $2h$
C. $v_{0}'$ 的最大值为 $\frac{\sqrt{15}}{6}v_{0}$
D. $v_{0}'$ 的最小值为 $\frac{\sqrt{15}}{6}v_{0}$
解析 小球做平抛运动, 有 $y=\frac{1}{2}gt^{2}$ , $x=v_{0}t$ , 联立解得 $v_{0}=x\sqrt{\frac{g}{2y}}$ , $y=\frac{gx^{2}}{2v_{0}^{2}}\propto x^{2}$ (点拨: 将水平距离之比和高度之比建立关联是关键), 则调整前 $\frac{h}{h+H}=\left(\frac{L}{2L}\right)^{2}$ , 得 $h=\frac{1}{3}H$ , 调整后考虑临界情况, 小球恰好没有擦到 A 而击中 C, 则 $\frac{h^{\prime}}{h^{\prime}+H}=\left(\frac{2}{3}\right)^{2}$ , 即 $h^{\prime}=\frac{4}{5}H$ , 所以 $h^{\prime}=\frac{12}{5}h$ , 从越高处抛出而击中 C 点, 抛物线越陡, 越不容易擦到 A 点, 所以 $h^{\prime}=\frac{12}{5}h$ 是满足条件的 $h^{\prime}$ 的最小值, A、B 错误。 $v_{0}=x\sqrt{\frac{g}{2y}}$ , 且两次平抛从抛出到 A 点过程, x 都为 L, 所以 $\frac{v_{0}^{\prime}}{v_{0}}=\sqrt{\frac{h}{h^{\prime}}}=\frac{\sqrt{15}}{6}$ , 即 $v_{0}^{\prime}=\frac{\sqrt{15}}{6}v_{0}$ , 由 $v_{0}^{\prime}=$
$$ L\sqrt{\frac{g}{2h^{\prime}}} 知 v_{0}^{\prime}=\frac{\sqrt{15}}{6}v_{0} 是满足条件的 v_{0}^{\prime} 的最大值 ,C 正确 ,D 错误。 $$
## 答案 C
## 四、斜抛运动
1.分析思路:对斜上抛运动,从抛出点到最高点的运动可应用逆向思维分析,其逆过程为平抛运动;对于完整的斜上抛运动,还可根据对称性求解某些问题。
2.斜抛运动中的几个常用结论
<img src="imgs/img_in_image_box_661_456_823_560.jpg" alt="Image" width="80%" />
(1)运动到最高点的时间 $t=\frac{v_{0} \sin \theta}{g}$ ;
运动的总时间 $t_{总}=\frac{2v_{0} \sin \theta}{g}$ 。
(2) 射高 $y_{m}=\frac{v_{0}^{2}\sin^{2}\theta}{2g}$
(3) 射程 $x_{\mathrm{m}}=\frac{v_{0}^{2} \sin 2\theta}{g}$。当 $\theta=45^{\circ}$ 时, 射程最大。
## 题型(7)圆周运动中的临界极值问题
## 一、水平面内的圆周运动的两种模型
<table>
<tr>
<td></td>
<td>与弹力有关 的临界问题</td>
<td>与摩擦力有关 的临界问题</td>
</tr>
<tr>
<td>情境 图示</td>
<td><img src="imgs/img_in_image_box_620_1017_774_1169.jpg" ></td>
<td><img src="imgs/img_in_image_box_822_1031_942_1152.jpg" ></td>
</tr>
<tr>
<td>受力 示意图</td>
<td><img src="imgs/img_in_image_box_614_1176_776_1330.jpg" ></td>
<td><img src="imgs/img_in_image_box_815_1181_952_1327.jpg" ></td>
</tr>
</table>性能数据
测试环境:Intel Core i7-12700H(6 大核 + 8 小核,共 14 核),32GB DDR5,纯 CPU 推理
场景 图片尺寸 耗时 说明
单块文本识别 800×200 ~5s 纯文本段落
单块公式识别 600×150 ~8s 行内公式
单块表格识别 1000×600 ~15s 含 OTSL 解析
完整文档(10 块) 1200×1600 ~30s 4 并行
PDF(10 页) A4 每页 ~8min 逐页串行
注意:以上为纯 CPU 数据。开启 GPU 后速度可提升 3~5 倍。
几个关键观察:
1.编码器只需跑一次,之后每步解码都在 CPU 上非常快
2.并行处理效果显著,4 并行比串行快约 2.5 倍
3.公式识别反而比纯文本快,因为公式 token 数通常更少
与其他方案的对比
方案 参数量 需要 GPU 部署复杂度 公式识别 表格识别 中文支持
PaddleOCR ~50M 可选 中 ✗ ✗ ✓
Tesseract ~30M ✗ 低 ✗ ✗ △
Mathpix API N/A 云端 低(但需联网) ✓ ✓ ✓
Qwen-VL-7B 7B ✓ 高 ✓ ✓ ✓
UniRec-0.1B (本项目) 0.1B ✗ 低 ✓ ✓ ✓
UniRec-0.1B 在不需要 GPU的前提下,提供了远超传统 OCR 的能力(公式、表格),同时保持了极低的部署门槛。
局限性与适用场景
优势
✅ 零 GPU 依赖 --- 普通 CPU 服务器即可部署
✅ 单 JAR 部署 --- Java 生态友好,嵌入现有系统方便
✅ 端到端识别 --- 一个模型搞定文本 + 公式 + 表格
✅ ONNX 跨平台 --- Windows/Linux/macOS 均可运行
局限
⚠️ 精度不及大模型 --- 0.1B 毕竟是小模型,复杂排版/手写体效果有限
⚠️ 速度有限 --- CPU 推理速度约 3~5 token/s,不适合实时场景
⚠️ 长文档耗时 --- 10 页 PDF 需要几分钟,大批量处理需规划任务队列
⚠️ OpenCV 原生库 --- 需要额外安装系统级的 OpenCV 动态库
适用场景
场景 推荐度 说明
发票/票据结构化 ⭐⭐⭐⭐ 版式固定,识别精度高
论文/文档转 Markdown ⭐⭐⭐⭐ 支持公式,学术文档效果好
表格数据提取 ⭐⭐⭐⭐ OTSL 转 HTML 表格,结构化输出
批量文档归档 ⭐⭐ 需配合任务队列,支持异步处理
手写体识别 ⭐⭐⭐ 模型未针对手写体训练
总结
UniRec-0.1B 证明了:文档理解不一定要靠大模型 + GPU。
对于大多数企业级文档处理场景------发票识别、合同解析、论文归档、表格提取------一个 0.1B 参数的小模型配合 ONNX Runtime 的 CPU 推理,已经完全够用。更重要的是,它以 Java 的形式交付,可以无缝嵌入现有的企业 Java 应用中,免去了 Python 微服务化的额外复杂度。
如果你的团队正在寻找一个轻量、易部署、纯 CPU 的文档 OCR 方案,不妨试试这个项目。
项目地址: openocr4j:https://www.wexopen.com下的工具中心