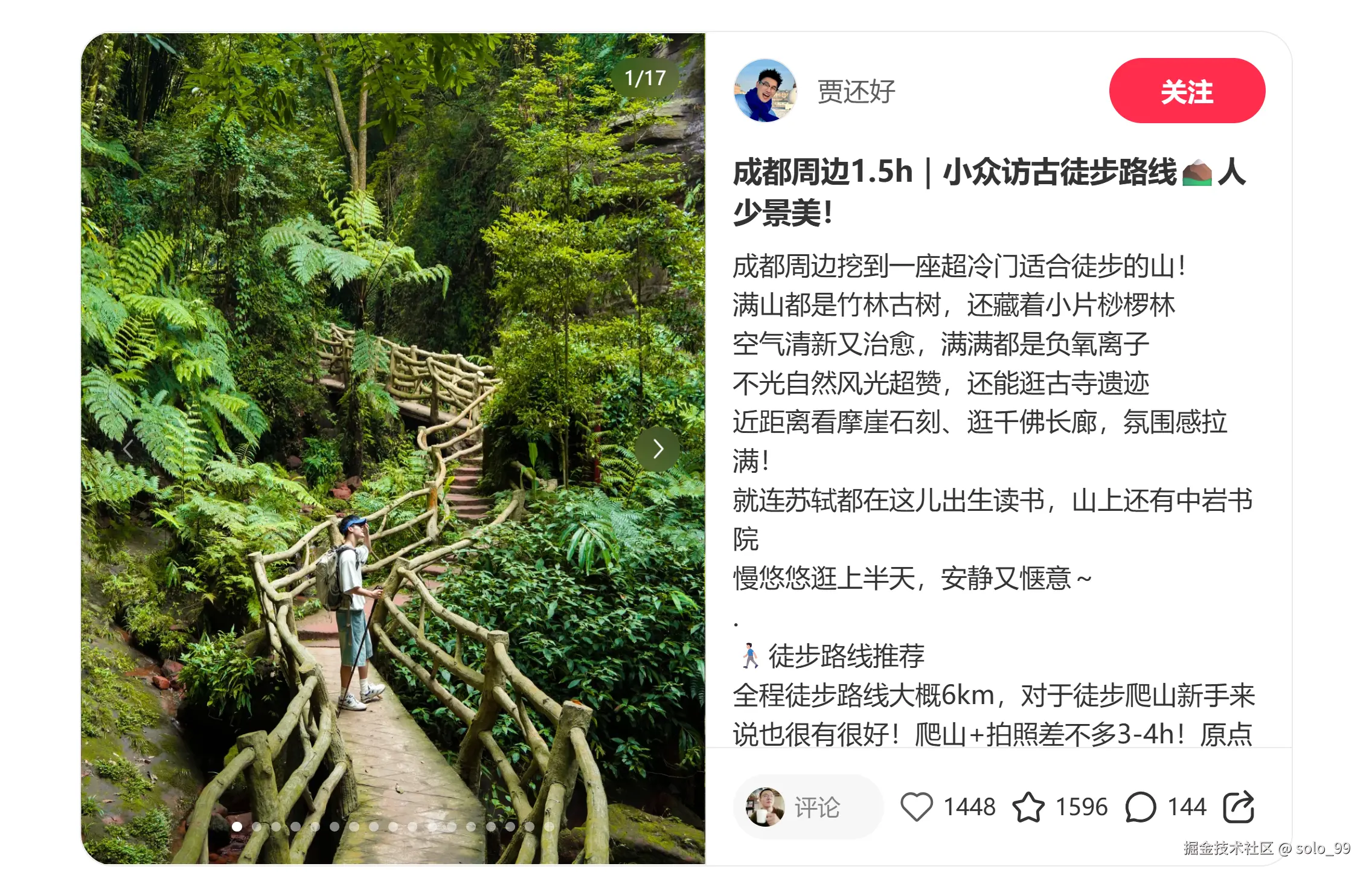
序言
最近在研究python爬虫,拿小红书实验了一下。供大家学习和借鉴。
研究数据的位置
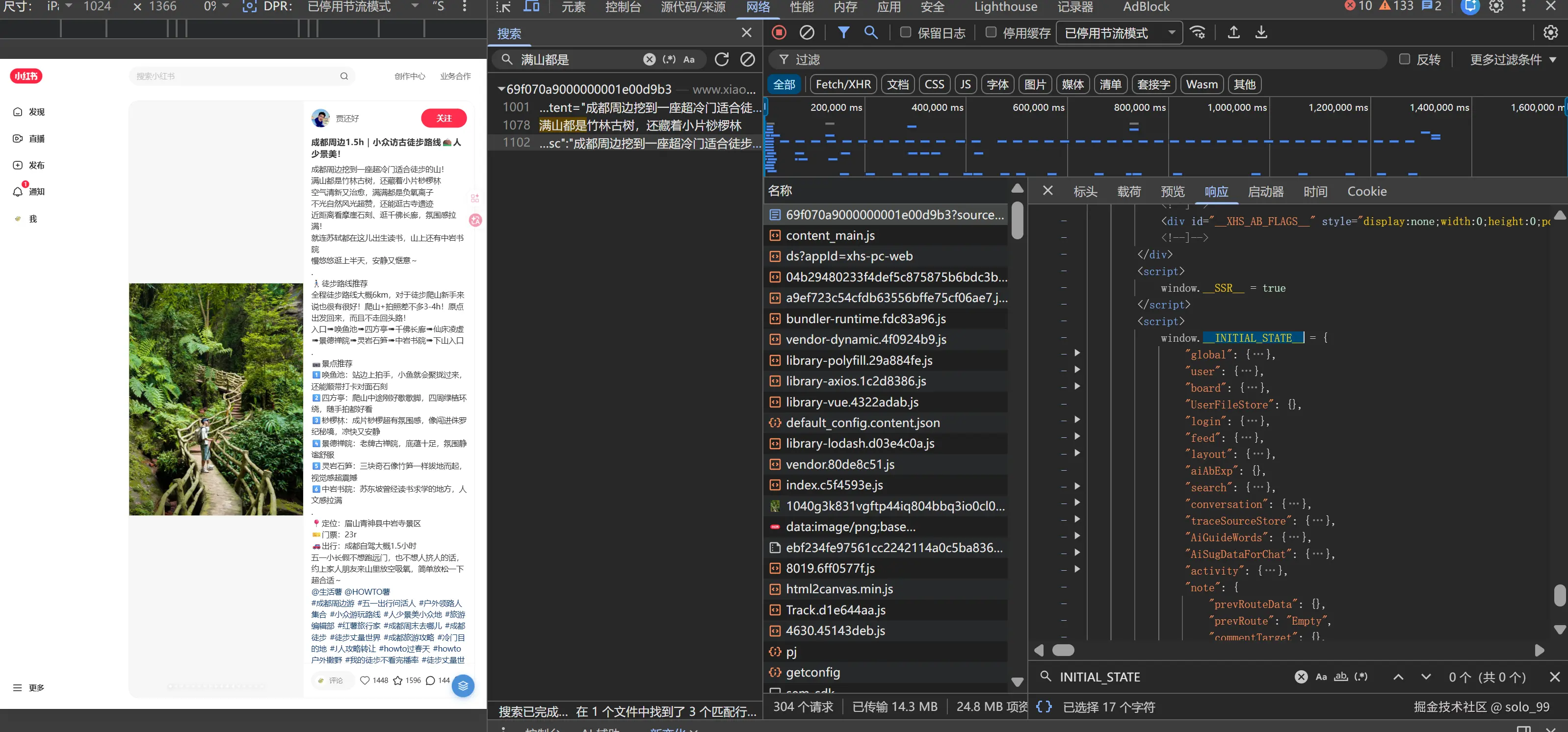
编写脚本
python
from DrissionPage import ChromiumPage
import time
page = ChromiumPage()
# 如果你的 DrissionPage 版本支持,可以指定用户数据目录:
# page = ChromiumPage(user_data_path=r"C:\Users\zgh\AppData\Local\Google\Chrome\User Data")
# 访问页面
url = "https://www.xiaohongshu.com/explore/69f070a9000000001e00d9b3?source=webshare&xhsshare=pc_web&xsec_token=ABJlJI3WKKswIkDhUIvq9Yld9fsbEcqdmAmg5afcsX7K0=&xsec_source=pc_share"
page.get(url)
# 等待页面完全加载
page.wait.doc_loaded()
# 提取数据
note_data = page.run_js('''
return window.__INITIAL_STATE__.note.noteDetailMap[Object.keys(window.__INITIAL_STATE__.note.noteDetailMap)[0]].note
''')
if note_data:
print(f"标题: {note_data.get('title')}")
print(f"描述: {note_data.get('desc')}")
else:
print("提取失败")效果
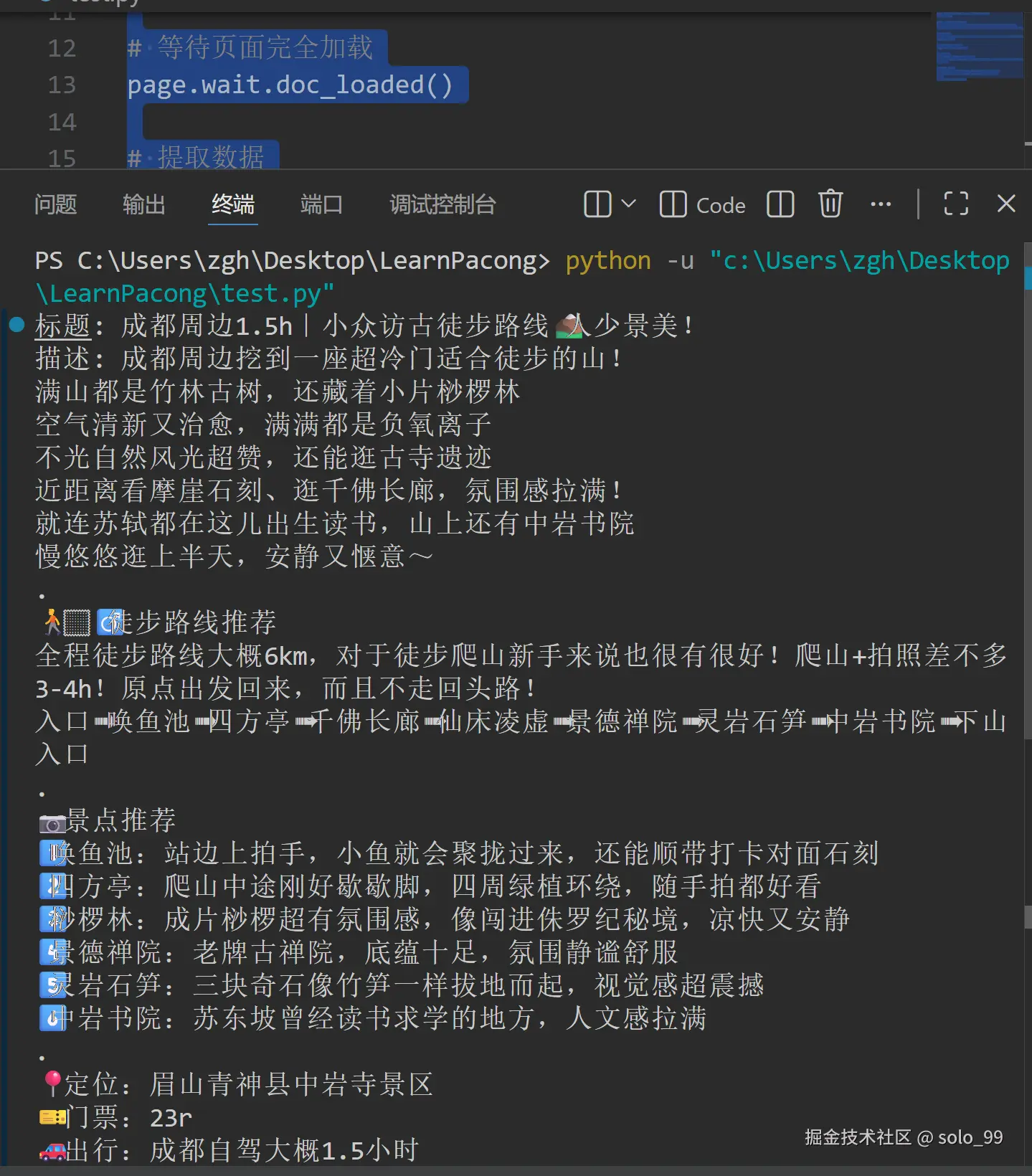
原贴