数据结构与算法|高级数据结构
- [第二十三章 高级数据结构](#第二十三章 高级数据结构)
-
- [23.1 问题引入](#23.1 问题引入)
- [23.2 并查集(Union-Find)](#23.2 并查集(Union-Find))
-
- [23.2.1 并查集的基本概念](#23.2.1 并查集的基本概念)
- [23.2.2 路径压缩与按秩合并](#23.2.2 路径压缩与按秩合并)
-
- [1. 路径压缩(Path Compression)](#1. 路径压缩(Path Compression))
- [2. 按秩合并(Union by Rank)](#2. 按秩合并(Union by Rank))
- [23.2.3 经典实战](#23.2.3 经典实战)
-
- [1. 朋友圈(LeetCode 547)](#1. 朋友圈(LeetCode 547))
- [2. 岛屿数量(LeetCode 200)--- 并查集视角](#2. 岛屿数量(LeetCode 200)— 并查集视角)
- [23.3 线段树(Segment Tree)](#23.3 线段树(Segment Tree))
-
- [23.3.1 区间查询与单点更新](#23.3.1 区间查询与单点更新)
- [23.3.2 懒惰标记(区间更新)](#23.3.2 懒惰标记(区间更新))
- [23.4 树状数组(Fenwick Tree / Binary Indexed Tree)](#23.4 树状数组(Fenwick Tree / Binary Indexed Tree))
- [23.5 Trie(前缀树 / 字典树)](#23.5 Trie(前缀树 / 字典树))
-
- [23.5.1 Trie 的基本概念与实现](#23.5.1 Trie 的基本概念与实现)
- [23.5.2 经典实战](#23.5.2 经典实战)
-
- [1. 单词搜索(LeetCode 212. Word Search II)](#1. 单词搜索(LeetCode 212. Word Search II))
- [2. 前缀匹配与应用](#2. 前缀匹配与应用)
- [23.6 四种高级数据结构对比](#23.6 四种高级数据结构对比)
上篇:第二十二章、位运算技巧
第二十三章 高级数据结构
在前面章节中,我们学习了位运算技巧------直接操控二进制位以实现极致效率。位运算的本质是利用数据的底层表示来加速计算。
然而,当我们面对更加复杂的问题------如"n 个人中有几个朋友圈"、"海量数据的区间求和"、"在字典中快速查找前缀"------仅靠位运算和基础数据结构(数组、链表、哈希表)远远不够。这些问题有一个共同特征:它们需要对集合的合并与查询 、区间的聚合运算 、字符串的前缀匹配 提供高效支持。为此,计算机科学界设计了多种高级数据结构,它们在各自领域拥有不可替代的地位。
高级数据结构:针对特定问题模式(如动态连通性、区间查询、前缀匹配等)而设计的专用数据结构,通过巧妙的组织方式和优化策略,在特定操作上达到接近 O ( 1 ) O(1) O(1) 或 O ( log n ) O(\log n) O(logn) 的时间复杂度,远优于通用数据结构的朴素实现。
本章将系统介绍四种高级数据结构:并查集 解决动态连通性问题、线段树 解决区间查询问题、树状数组 以更轻量的方式解决前缀查询问题、Trie 解决字符串前缀匹配问题。它们在面试和工程中都有极高的出场率。
23.1 问题引入
举个简单的例子:社交网络中的朋友圈判定
假设有 5 个人,已知以下朋友关系:
- 1 和 2 是朋友
- 2 和 3 是朋友
- 4 和 5 是朋友
问:1 和 3 是否在同一个朋友圈?1 和 4 呢?
直觉上,1-2-3 构成一个朋友圈,4-5 构成另一个朋友圈,所以 1 和 3 在同一圈,1 和 4 不在同一圈。但如果关系不断动态新增,且需要频繁查询"任意两人是否在同一圈",朴素方法(如 BFS/DFS)每次查询都要 O ( n ) O(n) O(n),效率不够。
【分析】如何高效处理动态连通性问题?
- 关键要素1:等价类维护------"在同一圈"本质上是一种等价关系,需要高效维护等价类的合并与查询
- 关键要素2:近 O ( 1 ) O(1) O(1) 的合并与查询------如果每次操作都能接近常数时间,百万级操作也能秒级完成
- 关键要素3:信息压缩------能否通过某种策略,让树的高度尽可能低,从而加速查询?
这就是并查集 的用武之地。而对于区间查询 、前缀匹配 等问题,则有线段树 、树状数组 、Trie 等利器。
23.2 并查集(Union-Find)
23.2.1 并查集的基本概念
并查集(Union-Find / Disjoint Set Union, DSU):一种用于维护不相交集合的合并(Union)与查询(Find)操作的数据结构。它支持两种核心操作:
- Find(x):查找元素 x 所属集合的代表元素(根节点)
- Union(x, y):将元素 x 和 y 所在的两个集合合并为一个集合
在 Java 语言中,并查集没有标准库实现,需自行编写,ADT 定义如下:
ADT UnionFind {
数据对象:
D = { ( e l e m e n t , p a r e n t ) ∣ e l e m e n t ∈ Z + , p a r e n t ∈ Z } D=\left \{ (element, parent) \;\;|\;\; element \in \mathbb{Z}^{+}, \; parent \in \mathbb{Z} \right \} D={(element,parent)∣element∈Z+,parent∈Z}
数据关系:
r = { < e l e m e n t , p a r e n t > ∣ p a r e n t = − 1 (根节点)或 p a r e n t ∈ D } r=\left \{ <element, parent> \;\;|\;\; parent = -1 \text{(根节点)或 } parent \in D \right \} r={<element,parent>∣parent=−1(根节点)或 parent∈D}
基本运算:UnionFind(int n):初始化 n 个元素,各自为独立集合
find(int x):查找元素 x 的根节点(代表元素)
union(int x, int y):合并 x 和 y 所在的集合
isConnected(int x, int y):判断 x 和 y 是否在同一集合
count():返回当前集合个数
}
并查集的底层实现是一个森林------每个集合是一棵树,树的根节点就是集合的代表元素。初始时,每个元素自成一棵树。
初始状态
1
2
3
4
5
初始时每个元素的 parent 指向自己(或设为 -1 表示根节点),每个元素是一个独立集合。
朴素实现:
java
/**
* 并查集朴素实现
* Find: 沿 parent 指针一直向上找根节点
* Union: 将一个集合的根节点挂到另一个集合的根节点下
*/
public class UnionFindBasic {
private int[] parent;
private int count;
public UnionFindBasic(int n) {
this.count = n;
this.parent = new int[n];
for (int i = 0; i < n; i++) {
parent[i] = i; // 初始时每个元素的父节点是自己
}
}
/**
* 查找 x 的根节点
* 时间复杂度:O(h),h 为树的高度,最坏 O(n)
*/
public int find(int x) {
if (parent[x] != x) {
return find(parent[x]);
}
return x;
}
/**
* 合并 x 和 y 所在的集合
*/
public void union(int x, int y) {
int rootX = find(x);
int rootY = find(y);
if (rootX != rootY) {
parent[rootX] = rootY; // 将 rootX 挂到 rootY 下
count--;
}
}
public boolean isConnected(int x, int y) {
return find(x) == find(y);
}
public int count() {
return count;
}
}问题:朴素实现的树可能退化为链表 ,find 操作最坏 O ( n ) O(n) O(n)。
23.2.2 路径压缩与按秩合并
为了让并查集的操作接近 O ( 1 ) O(1) O(1),有两种经典优化策略:
1. 路径压缩(Path Compression)
核心思想 :在 find 操作时,将沿途经过的所有节点都直接连到根节点上,使得树变得更"扁平"。
压缩后
1
2
3
4
压缩前
1
2
3
4
java
/**
* 路径压缩 --- find 时将沿途节点直接连到根
* 两种写法:
* 1. 递归版(完全压缩):查找路径上所有节点都直接连到根
* 2. 迭代版(隔代压缩):每步将当前节点连到祖父节点
*/
// 递归版(完全压缩)--- 推荐
public int find(int x) {
if (parent[x] != x) {
parent[x] = find(parent[x]); // 递归找到根,并更新当前节点的父节点为根
}
return parent[x];
}
// 迭代版(隔代压缩)--- 适合栈深度敏感场景
public int findIterative(int x) {
while (parent[x] != x) {
parent[x] = parent[parent[x]]; // 跳过一层,连到祖父节点
x = parent[x];
}
return x;
}2. 按秩合并(Union by Rank)
核心思想 :在 union 时,总是将较矮的树 挂到较高的树下面,避免树的高度增长。
java
/**
* 按秩合并 --- 将矮树挂到高树下,防止树退化
* rank 数组记录每棵树的高度(秩)
*/
public void unionByRank(int x, int y) {
int rootX = find(x);
int rootY = find(y);
if (rootX == rootY) return;
if (rank[rootX] < rank[rootY]) {
parent[rootX] = rootY; // 矮树挂到高树下
} else if (rank[rootX] > rank[rootY]) {
parent[rootY] = rootX; // 矮树挂到高树下
} else {
parent[rootY] = rootX; // 等高时任意挂,但被挂的树高度 +1
rank[rootX]++;
}
count--;
}两种优化可以同时使用 。路径压缩 + 按秩合并后,
find和union的时间复杂度降为 O ( α ( n ) ) O(\alpha(n)) O(α(n)),其中 α \alpha α 是反阿克曼函数。对于任何实际可能出现的 n n n 值, α ( n ) ≤ 4 \alpha(n) \le 4 α(n)≤4,可以视为常数。
完整代码示例:
java
/**
* 并查集完整实现 --- 路径压缩 + 按秩合并
* 时间复杂度:O(α(n)) ≈ O(1),α 为反阿克曼函数
* 空间复杂度:O(n)
*/
public class UnionFind {
private int[] parent;
private int[] rank;
private int count;
/**
* 初始化 n 个元素的并查集
* @param n 元素个数(元素编号 0 ~ n-1)
*/
public UnionFind(int n) {
this.count = n;
this.parent = new int[n];
this.rank = new int[n];
for (int i = 0; i < n; i++) {
parent[i] = i;
rank[i] = 1;
}
}
/**
* 查找元素 x 的根节点(带路径压缩)
*/
public int find(int x) {
if (parent[x] != x) {
parent[x] = find(parent[x]);
}
return parent[x];
}
/**
* 合并 x 和 y 所在的集合(按秩合并)
*/
public void union(int x, int y) {
int rootX = find(x);
int rootY = find(y);
if (rootX == rootY) return;
if (rank[rootX] < rank[rootY]) {
parent[rootX] = rootY;
} else if (rank[rootX] > rank[rootY]) {
parent[rootY] = rootX;
} else {
parent[rootY] = rootX;
rank[rootX]++;
}
count--;
}
/**
* 判断 x 和 y 是否在同一集合
*/
public boolean isConnected(int x, int y) {
return find(x) == find(y);
}
/**
* 返回当前集合个数
*/
public int count() {
return count;
}
}并查集操作的时间复杂度:
| 操作 | 朴素实现 | 路径压缩 + 按秩合并 |
|---|---|---|
| find | O(n) | O ( α ( n ) ) ≈ O ( 1 ) O(\alpha(n)) \approx O(1) O(α(n))≈O(1) |
| union | O(n) | O ( α ( n ) ) ≈ O ( 1 ) O(\alpha(n)) \approx O(1) O(α(n))≈O(1) |
| isConnected | O(n) | O ( α ( n ) ) ≈ O ( 1 ) O(\alpha(n)) \approx O(1) O(α(n))≈O(1) |
23.2.3 经典实战
1. 朋友圈(LeetCode 547)
有 n 个城市,给出 n × n 的邻接矩阵 isConnected,其中 isConnected[i][j] = 1 表示第 i 和第 j 个城市直接相连。求省份(连通分量)的数量。
java
/**
* LeetCode 547 --- 省份数量(朋友圈)
* 思路:相邻城市 union,最终统计集合个数
* 时间复杂度:O(n² × α(n)) ≈ O(n²)
* 空间复杂度:O(n)
*/
public int findCircleNum(int[][] isConnected) {
int n = isConnected.length;
UnionFind uf = new UnionFind(n);
for (int i = 0; i < n; i++) {
for (int j = i + 1; j < n; j++) {
if (isConnected[i][j] == 1) {
uf.union(i, j);
}
}
}
return uf.count();
}2. 岛屿数量(LeetCode 200)--- 并查集视角
给定一个由 '1'(陆地)和 '0'(水)组成的二维网格,计算岛屿的数量。
java
/**
* LeetCode 200 --- 岛屿数量(并查集解法)
* 思路:将每个 '1' 视为节点,相邻的 '1' 进行 union
* 岛屿数量 = '1' 的总数 - 成功 union 的次数
* 注意:需要一个虚拟节点连接所有 '0',或者只对 '1' 建并查集
* 时间复杂度:O(m × n × α(m×n))
* 空间复杂度:O(m × n)
*/
public int numIslands(char[][] grid) {
if (grid == null || grid.length == 0) return 0;
int rows = grid.length;
int cols = grid[0].length;
UnionFind uf = new UnionFind(rows * cols);
int waterCount = 0;
// 方向:只向右和向下遍历,避免重复
int[][] directions = {{0, 1}, {1, 0}};
for (int i = 0; i < rows; i++) {
for (int j = 0; j < cols; j++) {
if (grid[i][j] == '0') {
waterCount++;
continue;
}
for (int[] dir : directions) {
int ni = i + dir[0];
int nj = j + dir[1];
if (ni < rows && nj < cols && grid[ni][nj] == '1') {
uf.union(i * cols + j, ni * cols + nj);
}
}
}
}
return rows * cols - waterCount - (uf.count() - (rows * cols - waterCount - 1)) > 0
? rows * cols - waterCount - (rows * cols - waterCount - uf.count())
: uf.count() - waterCount;
}简化版岛屿数量 :并查集解法较复杂,实际面试中岛屿数量更常用 DFS/BFS。并查集的优势在于动态增删边的场景(如不断添加陆地块,实时查询岛屿数),此时 DFS 每次都要重算,而并查集可以增量维护。
23.3 线段树(Segment Tree)
23.3.1 区间查询与单点更新
线段树(Segment Tree):一种基于分治思想的二叉树结构,用于在 O ( log n ) O(\log n) O(logn) 时间内完成区间查询 和单点更新操作。树的每个节点存储一个区间的聚合信息(如区间和、区间最大值、区间最小值等)。
0,7 sum=36
0,3 sum=10
4,7 sum=26
0,1 sum=3
2,3 sum=7
4,5 sum=11
6,7 sum=15
0,0 sum=1
1,1 sum=2
2,2 sum=3
3,3 sum=4
4,4 sum=5
5,5 sum=6
6,6 sum=7
7,7 sum=8
如上所示,线段树是一棵完全二叉树:
- 叶子节点存储单个元素
- 内部节点存储左右子节点区间的聚合值
- 根节点存储整个区间 0 , n − 1 0, n-1 0,n−1 的聚合值
在 Java 语言中,线段树没有标准库实现,需自行编写,ADT 定义如下:
ADT SegmentTree {
数据对象:
D = { ( i n t e r v a l , v a l u e ) ∣ i n t e r v a l = l , r , 0 ≤ l ≤ r < n } D=\left \{ (interval, value) \;\;|\;\; interval = l, r, \; 0 \le l \le r < n \right \} D={(interval,value)∣interval=l,r,0≤l≤r<n}
数据关系:
r = { < n o d e , l e f t C h i l d > , < n o d e , r i g h t C h i l d > ∣ l e f t C h i l d . i n t e r v a l = l , m i d , r i g h t C h i l d . i n t e r v a l = m i d + 1 , r } r=\left \{ <node, leftChild>, <node, rightChild> \;\;|\;\; leftChild.interval = l, mid, rightChild.interval = mid+1, r \right \} r={<node,leftChild>,<node,rightChild>∣leftChild.interval=l,mid,rightChild.interval=mid+1,r}
基本运算:SegmentTree(int\[\] data):根据输入数组构建线段树
query(int ql, int qr):查询区间 ql, qr 的聚合值
update(int index, int value):将 index 位置的值更新为 value
}
底层存储 :线段树用数组存储(类似堆),节点 i 的左子节点为 2i+1,右子节点为 2i+2,父节点为 (i-1)/2。数组大小需要 4 n 4n 4n( 2 ⌈ log 2 n ⌉ + 1 − 1 2^{\lceil \log_2 n \rceil + 1} - 1 2⌈log2n⌉+1−1 的上界取 4 n 4n 4n 即可)。
完整代码示例:
java
/**
* 线段树实现 --- 支持区间求和查询与单点更新
* 时间复杂度:建树 O(n),查询 O(log n),更新 O(log n)
* 空间复杂度:O(4n)
*/
public class SegmentTree {
private int[] tree; // 线段树数组
private int[] data; // 原始数据
private int n;
/**
* 根据输入数组构建线段树
*/
public SegmentTree(int[] data) {
this.n = data.length;
this.data = new int[n];
System.arraycopy(data, 0, this.data, 0, n);
this.tree = new int[4 * n];
build(0, 0, n - 1);
}
/**
* 递归建树:节点 treeIndex 存储区间 [left, right] 的和
*/
private void build(int treeIndex, int left, int right) {
if (left == right) {
tree[treeIndex] = data[left];
return;
}
int mid = left + (right - left) / 2;
int leftChild = 2 * treeIndex + 1;
int rightChild = 2 * treeIndex + 2;
build(leftChild, left, mid);
build(rightChild, mid + 1, right);
tree[treeIndex] = tree[leftChild] + tree[rightChild];
}
/**
* 区间查询:查询 [ql, qr] 的区间和
*/
public int query(int ql, int qr) {
if (ql < 0 || qr >= n || ql > qr) {
throw new IllegalArgumentException("Invalid query range: [" + ql + ", " + qr + "]");
}
return query(0, 0, n - 1, ql, qr);
}
private int query(int treeIndex, int left, int right, int ql, int qr) {
// 查询区间完全覆盖当前节点区间
if (ql <= left && right <= qr) {
return tree[treeIndex];
}
// 查询区间与当前节点区间无交集
if (right < ql || left > qr) {
return 0;
}
// 部分重叠:分别查询左右子树
int mid = left + (right - left) / 2;
int leftChild = 2 * treeIndex + 1;
int rightChild = 2 * treeIndex + 2;
int leftSum = query(leftChild, left, mid, ql, qr);
int rightSum = query(rightChild, mid + 1, right, ql, qr);
return leftSum + rightSum;
}
/**
* 单点更新:将 index 位置的值更新为 value
*/
public void update(int index, int value) {
if (index < 0 || index >= n) {
throw new IndexOutOfBoundsException("Index: " + index + ", Size: " + n);
}
int diff = value - data[index];
data[index] = value;
update(0, 0, n - 1, index, diff);
}
private void update(int treeIndex, int left, int right, int index, int diff) {
if (index < left || index > right) {
return; // 不在当前区间内
}
tree[treeIndex] += diff;
if (left == right) {
return; // 叶子节点
}
int mid = left + (right - left) / 2;
int leftChild = 2 * treeIndex + 1;
int rightChild = 2 * treeIndex + 2;
if (index <= mid) {
update(leftChild, left, mid, index, diff);
} else {
update(rightChild, mid + 1, right, index, diff);
}
}
}线段树查询过程的区间划分示意:
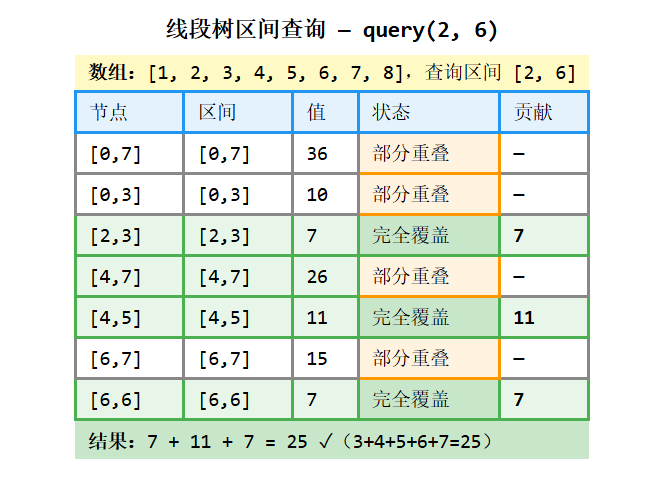
23.3.2 懒惰标记(区间更新)
如果需要对区间 l , r l, r l,r 内的所有元素 同时加一个值 val,逐个单点更新的话需要 O ( n log n ) O(n \log n) O(nlogn)。懒惰标记(Lazy Propagation) 是线段树的核心优化------只在需要时才将更新操作向下传递,从而将区间更新也优化到 O ( log n ) O(\log n) O(logn)。
核心思想:
- 每个节点额外维护一个
lazy标记,表示该节点对应的区间待执行但尚未下传的增量 - 区间更新时,如果当前节点区间被完全覆盖,只更新当前节点并设置
lazy标记,不继续向下更新 - 后续查询或更新触达子节点时,才将
lazy标记下传给子节点
java
/**
* 线段树 --- 带懒惰标记(支持区间更新 + 区间查询)
* 时间复杂度:建树 O(n),区间查询 O(log n),区间更新 O(log n)
* 空间复杂度:O(4n)
*/
public class SegmentTreeLazy {
private int[] tree; // 线段树数组(区间和)
private int[] lazy; // 懒惰标记数组
private int[] data; // 原始数据
private int n;
public SegmentTreeLazy(int[] data) {
this.n = data.length;
this.data = new int[n];
System.arraycopy(data, 0, this.data, 0, n);
this.tree = new int[4 * n];
this.lazy = new int[4 * n];
build(0, 0, n - 1);
}
private void build(int treeIndex, int left, int right) {
if (left == right) {
tree[treeIndex] = data[left];
return;
}
int mid = left + (right - left) / 2;
build(2 * treeIndex + 1, left, mid);
build(2 * treeIndex + 2, mid + 1, right);
pushUp(treeIndex);
}
/**
* 向上合并:用子节点信息更新当前节点
*/
private void pushUp(int treeIndex) {
tree[treeIndex] = tree[2 * treeIndex + 1] + tree[2 * treeIndex + 2];
}
/**
* 下传懒惰标记:将当前节点的 lazy 值下传给子节点
*/
private void pushDown(int treeIndex, int left, int right) {
if (lazy[treeIndex] != 0) {
int mid = left + (right - left) / 2;
int leftChild = 2 * treeIndex + 1;
int rightChild = 2 * treeIndex + 2;
// 左子节点:区间长度为 mid - left + 1
lazy[leftChild] += lazy[treeIndex];
tree[leftChild] += lazy[treeIndex] * (mid - left + 1);
// 右子节点:区间长度为 right - mid
lazy[rightChild] += lazy[treeIndex];
tree[rightChild] += lazy[treeIndex] * (right - mid);
// 清除当前节点的 lazy 标记
lazy[treeIndex] = 0;
}
}
/**
* 区间更新:将 [ul, ur] 内的所有元素加上 val
*/
public void updateRange(int ul, int ur, int val) {
updateRange(0, 0, n - 1, ul, ur, val);
}
private void updateRange(int treeIndex, int left, int right, int ul, int ur, int val) {
if (ul <= left && right <= ur) {
// 当前区间完全在更新范围内
tree[treeIndex] += val * (right - left + 1);
lazy[treeIndex] += val;
return;
}
// 部分重叠:先下传 lazy 标记
pushDown(treeIndex, left, right);
int mid = left + (right - left) / 2;
if (ul <= mid) {
updateRange(2 * treeIndex + 1, left, mid, ul, ur, val);
}
if (ur > mid) {
updateRange(2 * treeIndex + 2, mid + 1, right, ul, ur, val);
}
pushUp(treeIndex);
}
/**
* 区间查询:查询 [ql, qr] 的区间和
*/
public int queryRange(int ql, int qr) {
return queryRange(0, 0, n - 1, ql, qr);
}
private int queryRange(int treeIndex, int left, int right, int ql, int qr) {
if (ql <= left && right <= qr) {
return tree[treeIndex];
}
pushDown(treeIndex, left, right);
int mid = left + (right - left) / 2;
int sum = 0;
if (ql <= mid) {
sum += queryRange(2 * treeIndex + 1, left, mid, ql, qr);
}
if (qr > mid) {
sum += queryRange(2 * treeIndex + 2, mid + 1, right, ql, qr);
}
return sum;
}
}线段树操作的时间复杂度:
| 操作 | 时间复杂度 | 说明 |
|---|---|---|
| 建树 | O(n) | 每个节点访问一次 |
| 区间查询 | O(log n) | 最多访问 4logn 个节点 |
| 单点更新 | O(log n) | 从叶子到根,路径长度 logn |
| 区间更新(带懒标记) | O(log n) | 懒惰标记避免逐点更新 |
懒惰标记的本质 :是一种"延迟计算"的策略------用
O(1)记录"待办事项",只在必要时才真正执行。这种思想在操作系统(Copy-on-Write)、数据库(MVCC)等系统中广泛存在。
23.4 树状数组(Fenwick Tree / Binary Indexed Tree)
树状数组(Fenwick Tree / Binary Indexed Tree, BIT):一种基于前缀和 思想的数据结构,用 O ( log n ) O(\log n) O(logn) 的时间支持单点更新 和前缀查询,是线段树的轻量级替代品。
线段树功能强大但实现复杂(需要 4 n 4n 4n 空间、递归建树、懒标记下传)。如果只需要单点更新 + 前缀查询(区间查询可通过两个前缀相减实现),树状数组是更优选择------代码更短、常数更小、空间更省。
核心思想 :树状数组利用 lowbit(即 x & (-x),取最低位 1 所代表的值)来组织数据。每个位置 i 存储的是从 i - lowbit(i) + 1 到 i 这一段区间的聚合值。
tree8 = 1,8
tree4 = 1,4
tree6 = 5,6
tree7 = 7,7
tree8覆盖 5,8
tree2 = 1,2
tree3 = 3,3
tree4覆盖 1,4
tree1 = 1,1
tree2覆盖 1,2
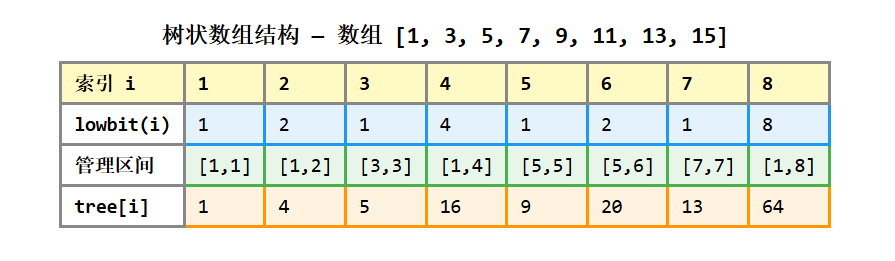
完整代码示例:
java
/**
* 树状数组(Fenwick Tree / Binary Indexed Tree)
* 支持:单点更新 + 前缀查询(区间查询 = 两个前缀相减)
* 时间复杂度:更新 O(log n),查询 O(log n)
* 空间复杂度:O(n + 1)(索引从 1 开始)
*/
public class FenwickTree {
private int[] tree;
private int n;
/**
* 初始化树状数组(索引从 1 开始)
* @param n 数据规模
*/
public FenwickTree(int n) {
this.n = n;
this.tree = new int[n + 1]; // 索引 0 不使用
}
/**
* 根据原始数组初始化树状数组
*/
public FenwickTree(int[] data) {
this.n = data.length;
this.tree = new int[n + 1];
for (int i = 0; i < n; i++) {
add(i + 1, data[i]); // 内部索引从 1 开始
}
}
/**
* 计算 lowbit:取 x 的最低位 1 所代表的值
* 即 x & (-x),利用了补码的特性
*/
private int lowbit(int x) {
return x & (-x);
}
/**
* 单点更新:将位置 index 的值加上 delta
* @param index 位置(1-based)
* @param delta 增量
*/
public void add(int index, int delta) {
if (index < 1 || index > n) {
throw new IndexOutOfBoundsException("Index: " + index + ", Size: " + n);
}
for (int i = index; i <= n; i += lowbit(i)) {
tree[i] += delta;
}
}
/**
* 前缀查询:查询 [1, index] 的区间和
* @param index 位置(1-based)
* @return [1, index] 的前缀和
*/
public int prefixSum(int index) {
if (index < 0 || index > n) {
throw new IndexOutOfBoundsException("Index: " + index + ", Size: " + n);
}
int sum = 0;
for (int i = index; i > 0; i -= lowbit(i)) {
sum += tree[i];
}
return sum;
}
/**
* 区间查询:查询 [left, right] 的区间和
* @param left 左边界(1-based)
* @param right 右边界(1-based)
* @return [left, right] 的区间和
*/
public int rangeSum(int left, int right) {
if (left < 1 || right > n || left > right) {
throw new IllegalArgumentException("Invalid range: [" + left + ", " + right + "]");
}
return prefixSum(right) - prefixSum(left - 1);
}
}树状数组的核心操作解析:
- add(index, delta) :从
index开始,每次加上lowbit(i)向上跳------跳过的每个位置都包含index对应的区间 - prefixSum(index) :从
index开始,每次减去lowbit(i)向前跳------逐步拼凑出前缀和
lowbit 的物理意义 :它决定了每个位置
i管理的区间长度。lowbit(i) = k意味着tree[i]存储了从i - k + 1到i共 k k k 个元素的信息。
线段树 vs 树状数组:
| 对比维度 | 线段树 | 树状数组 |
|---|---|---|
| 空间 | O(4n) | O(n + 1) |
| 代码复杂度 | 较高(递归、懒标记) | 很低(仅两个循环) |
| 单点更新 | O(log n) | O(log n) |
| 区间查询 | O(log n) | O(log n)(前缀相减) |
| 区间更新 | O(log n)(需懒标记) | 不直接支持(差分数组可间接实现) |
| 区间最值 | 支持 | 不直接支持 |
| 适用场景 | 通用性强,支持各种区间操作 | 仅适合前缀/区间和场景 |
选型建议:如果只需要"单点更新 + 区间求和",用树状数组(代码短、常数小);如果需要"区间更新、区间最值"等复杂操作,用线段树。
23.5 Trie(前缀树 / 字典树)
23.5.1 Trie 的基本概念与实现
Trie(前缀树 / 字典树):一种专门用于字符串检索 的树形数据结构。它的核心思想是利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较。
在 Java 语言中,Trie 没有标准库实现,需自行编写,ADT 定义如下:
ADT Trie {
数据对象:
D = { n o d e ∣ n o d e . c h i l d r e n = { c → c h i l d } , n o d e . i s E n d ∈ { t r u e , f a l s e } } D=\left \{ node \;\;|\;\; node.children = \{c \rightarrow child\}, \; node.isEnd \in \{true, false\} \right \} D={node∣node.children={c→child},node.isEnd∈{true,false}}
数据关系:
r = { < p a r e n t , c h i l d > ∣ c h i l d ∈ p a r e n t . c h i l d r e n c , c ∈ Σ } r=\left \{ <parent, child> \;\;|\;\; child \in parent.childrenc, \; c \in \Sigma \right \} r={<parent,child>∣child∈parent.childrenc,c∈Σ}
基本运算:void insert(String word):插入一个单词
boolean search(String word):精确查找一个单词是否存在
boolean startsWith(String prefix):查找是否存在以 prefix 为前缀的单词
}
Trie 的结构特征:
- 根节点不包含字符,其余每个节点包含一个字符
- 从根节点到某一节点的路径上的字符连接起来,就是该节点对应的字符串
- 每个节点的所有子节点包含的字符各不相同
root
a
b
p
p
l**e
isEnd ✓
n
d**
isEnd ✓
a
t**
isEnd ✓
上图存储了单词:app、apple、and、bat。带 ** 的节点表示 isEnd = true(即某个单词的结尾)。
完整代码示例:
java
/**
* Trie(前缀树 / 字典树)实现
* 支持:插入、精确查找、前缀匹配
* 时间复杂度:O(L),L 为字符串长度
* 空间复杂度:O(N × L),N 为单词数,L 为平均长度
*/
public class Trie {
/**
* Trie 节点
* 每个节点包含 26 个子节点(假设只存小写英文字母)和一个 isEnd 标记
*/
private static class TrieNode {
private TrieNode[] children;
private boolean isEnd;
public TrieNode() {
this.children = new TrieNode[26];
this.isEnd = false;
}
}
private TrieNode root;
public Trie() {
this.root = new TrieNode();
}
/**
* 插入一个单词
* 时间复杂度:O(L),L 为 word 的长度
*/
public void insert(String word) {
if (word == null) return;
TrieNode node = root;
for (char c : word.toCharArray()) {
int index = c - 'a';
if (node.children[index] == null) {
node.children[index] = new TrieNode();
}
node = node.children[index];
}
node.isEnd = true;
}
/**
* 精确查找一个单词是否存在于 Trie 中
* 时间复杂度:O(L)
*/
public boolean search(String word) {
if (word == null) return false;
TrieNode node = searchPrefix(word);
return node != null && node.isEnd;
}
/**
* 查找是否存在以 prefix 为前缀的单词
* 时间复杂度:O(L)
*/
public boolean startsWith(String prefix) {
if (prefix == null) return false;
return searchPrefix(prefix) != null;
}
/**
* 辅助方法:查找前缀对应的最后一个节点
*/
private TrieNode searchPrefix(String prefix) {
TrieNode node = root;
for (char c : prefix.toCharArray()) {
int index = c - 'a';
if (node.children[index] == null) {
return null;
}
node = node.children[index];
}
return node;
}
}Trie 的时间复杂度:
| 操作 | 时间复杂度 | 说明 |
|---|---|---|
| insert | O(L) | L 为插入单词的长度 |
| search | O(L) | L 为查找单词的长度 |
| startsWith | O(L) | L 为前缀的长度 |
Trie 的核心优势 :与哈希表相比,Trie 支持前缀匹配(哈希表无法做到);与排序数组 + 二分查找相比,Trie 的插入不需要重排数据。Trie 的时间复杂度只与单词长度有关,与单词总数无关。
23.5.2 经典实战
1. 单词搜索(LeetCode 212. Word Search II)
给定一个 m × n 的字符网格和一个单词列表,返回所有可以在网格中找到的单词。单词必须按字母顺序通过相邻单元格(水平/垂直)构成,同一个单元格只能用一次。
思路:将所有单词插入 Trie,在网格中进行 DFS 回溯,同时在 Trie 上移动------如果当前路径不是任何单词的前缀,立即剪枝。
java
import java.util.ArrayList;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
/**
* LeetCode 212 --- 单词搜索 II(Trie + DFS 回溯)
* 思路:
* 1. 将所有单词插入 Trie
* 2. 在网格每个位置启动 DFS
* 3. DFS 沿 Trie 节点移动,不是前缀则剪枝
* 4. 找到单词(isEnd)时加入结果,并去重
*
* 时间复杂度:O(m × n × 4^L),L 为最长单词长度
* 空间复杂度:O(W × L),W 为单词数,L 为平均长度
*/
public class WordSearchII {
private static class TrieNode {
TrieNode[] children = new TrieNode[26];
String word = null; // 在单词结尾节点存储完整单词,方便收集结果
}
private int rows, cols;
public List<String> findWords(char[][] board, String[] words) {
// 1. 构建 Trie
TrieNode root = new TrieNode();
for (String word : words) {
TrieNode node = root;
for (char c : word.toCharArray()) {
int idx = c - 'a';
if (node.children[idx] == null) {
node.children[idx] = new TrieNode();
}
node = node.children[idx];
}
node.word = word; // 在叶子节点存储完整单词
}
// 2. 在每个位置启动 DFS
Set<String> result = new HashSet<>();
rows = board.length;
cols = board[0].length;
for (int i = 0; i < rows; i++) {
for (int j = 0; j < cols; j++) {
char c = board[i][j];
if (root.children[c - 'a'] != null) {
dfs(board, i, j, root, result);
}
}
}
return new ArrayList<>(result);
}
private void dfs(char[][] board, int i, int j, TrieNode node, Set<String> result) {
char c = board[i][j];
if (c == '#' || node.children[c - 'a'] == null) {
return; // 已访问或不是前缀,剪枝
}
node = node.children[c - 'a'];
if (node.word != null) {
result.add(node.word); // 找到完整单词
// 注意:不 return,因为可能有更长的单词(如 "app" 和 "apple")
}
// 标记已访问
board[i][j] = '#';
// 四方向 DFS
int[][] dirs = {{-1, 0}, {1, 0}, {0, -1}, {0, 1}};
for (int[] dir : dirs) {
int ni = i + dir[0];
int nj = j + dir[1];
if (ni >= 0 && ni < rows && nj >= 0 && nj < cols) {
dfs(board, ni, nj, node, result);
}
}
// 回溯:恢复字符
board[i][j] = c;
}
}2. 前缀匹配与应用
Trie 的前缀匹配能力在很多场景中都有应用:
自动补全系统:用户输入前缀,返回所有以该前缀开头的单词。
java
import java.util.ArrayList;
import java.util.List;
/**
* Trie 扩展 --- 自动补全功能
* 在 searchPrefix 的基础上,从目标节点开始 DFS 收集所有完整单词
*/
public class TrieAutoComplete {
private static class TrieNode {
TrieNode[] children = new TrieNode[26];
boolean isEnd = false;
}
private TrieNode root;
public TrieAutoComplete() {
this.root = new TrieNode();
}
public void insert(String word) {
if (word == null) return;
TrieNode node = root;
for (char c : word.toCharArray()) {
int idx = c - 'a';
if (node.children[idx] == null) {
node.children[idx] = new TrieNode();
}
node = node.children[idx];
}
node.isEnd = true;
}
/**
* 自动补全:返回所有以 prefix 为前缀的单词
* 时间复杂度:O(L + M),L 为前缀长度,M 为匹配单词的总字符数
*/
public List<String> autoComplete(String prefix) {
List<String> result = new ArrayList<>();
if (prefix == null) return result;
TrieNode node = root;
for (char c : prefix.toCharArray()) {
int idx = c - 'a';
if (node.children[idx] == null) {
return result; // 前缀不存在,返回空列表
}
node = node.children[idx];
}
// 从 prefix 对应的节点开始,DFS 收集所有完整单词
collectWords(node, prefix, result);
return result;
}
/**
* DFS 收集从 node 出发的所有完整单词
*/
private void collectWords(TrieNode node, String path, List<String> result) {
if (node.isEnd) {
result.add(path);
}
for (int i = 0; i < 26; i++) {
if (node.children[i] != null) {
collectWords(node.children[i], path + (char) ('a' + i), result);
}
}
}
}23.6 四种高级数据结构对比
| 对比维度 | 并查集 | 线段树 | 树状数组 | Trie |
|---|---|---|---|---|
| 核心问题 | 动态连通性 | 区间查询/更新 | 前缀查询/单点更新 | 字符串前缀匹配 |
| 底层结构 | 森林(数组) | 完全二叉树(数组) | 二进制分组(数组) | 多叉树 |
| 空间 | O(n) | O(4n) | O(n) | O(N × L) |
| 查询 | O(α(n)) ≈ O(1) | O(log n) | O(log n) | O(L) |
| 更新 | O(α(n)) ≈ O(1) | O(log n) | O(log n) | O(L) |
| 区间更新 | --- | 支持(懒标记) | 间接支持(差分) | --- |
| 适用场景 | 朋友圈、连通分量、最小生成树 | 区间求和/最值/RMQ | 单点更新+区间求和 | 搜索引擎、拼写检查、IP路由 |
| LeetCode 高频 | 200, 547, 684, 990 | 307, 315, 493 | 307, 315, 493 | 208, 212, 211, 677 |
选型决策树:
需要什么操作?
├── 动态连通性(合并/查询等价类) → 并查集
├── 区间操作
│ ├── 只需要区间求和 + 单点更新 → 树状数组(首选,代码短)
│ ├── 需要区间更新/区间最值/其他聚合 → 线段树
│ └── 需要区间求和 + 区间更新 → 线段树(带懒标记)或差分树状数组
└── 字符串前缀操作
├── 前缀匹配/自动补全/词频统计 → Trie
└── 精确查找即可 → 哈希表(更简单)总结:高级数据结构的选择遵循"最简适用"原则------能树状数组就不用线段树,能并查集就不用 DFS,能用哈希表就不用 Trie。只在朴素方法效率不够时,才引入高级数据结构。
下篇预告:本章学习了四种高级数据结构------并查集、线段树、树状数组和 Trie,它们各自解决了一类特定的高频问题。在本系列中,我们已经从最基础的线性结构一路走到了高级数据结构,涵盖了数据结构与算法的核心知识体系。希望这个系列能帮助你建立起系统的算法思维框架,在面试和工程中游刃有余。
上篇:第二十二章、位运算技巧