目录
[一. HTTP](#一. HTTP)
[1.1 请求报文](#1.1 请求报文)
[1.2 响应报文](#1.2 响应报文)
[1.3 最常见的 HTTP 请求方法](#1.3 最常见的 HTTP 请求方法)
[1.4 最常见的 HTTP 响应状态码](#1.4 最常见的 HTTP 响应状态码)
[1.5 HTTP是无状态协议](#1.5 HTTP是无状态协议)
[二. HTTPS](#二. HTTPS)
[三. DNS](#三. DNS)
HTTP,HTTPS,DNS是互联网应用层最核心的三个协议,前两者都是基于传输层的TCP协议实现的。而DNS是基于TCP+UDP实现的。
有关TCP的介绍可以看我的这篇博客:一篇讲清TCP的三次握手&四次挥手-CSDN博客
作为一名开发者,这里可以主要关注常见的请求方法 和常见的状态响应码。
一. HTTP
HTTP(超文本传输协议),其工作就是在浏览器客户端和服务器之间,按照事前约定好的规则,可靠的传输网页,图片等你一系列的能看到的内容。
他在客户端和服务端之间的通话模式是基于请求---响应模型实现的,客户端向服务器发送请求报文 ,服务器向客户端发送响应报文,想要请求的资源就被封装在报文中。所以说要想了解清楚HTTP的工作原理,就得先弄清楚请求报文和响应报文的格式。
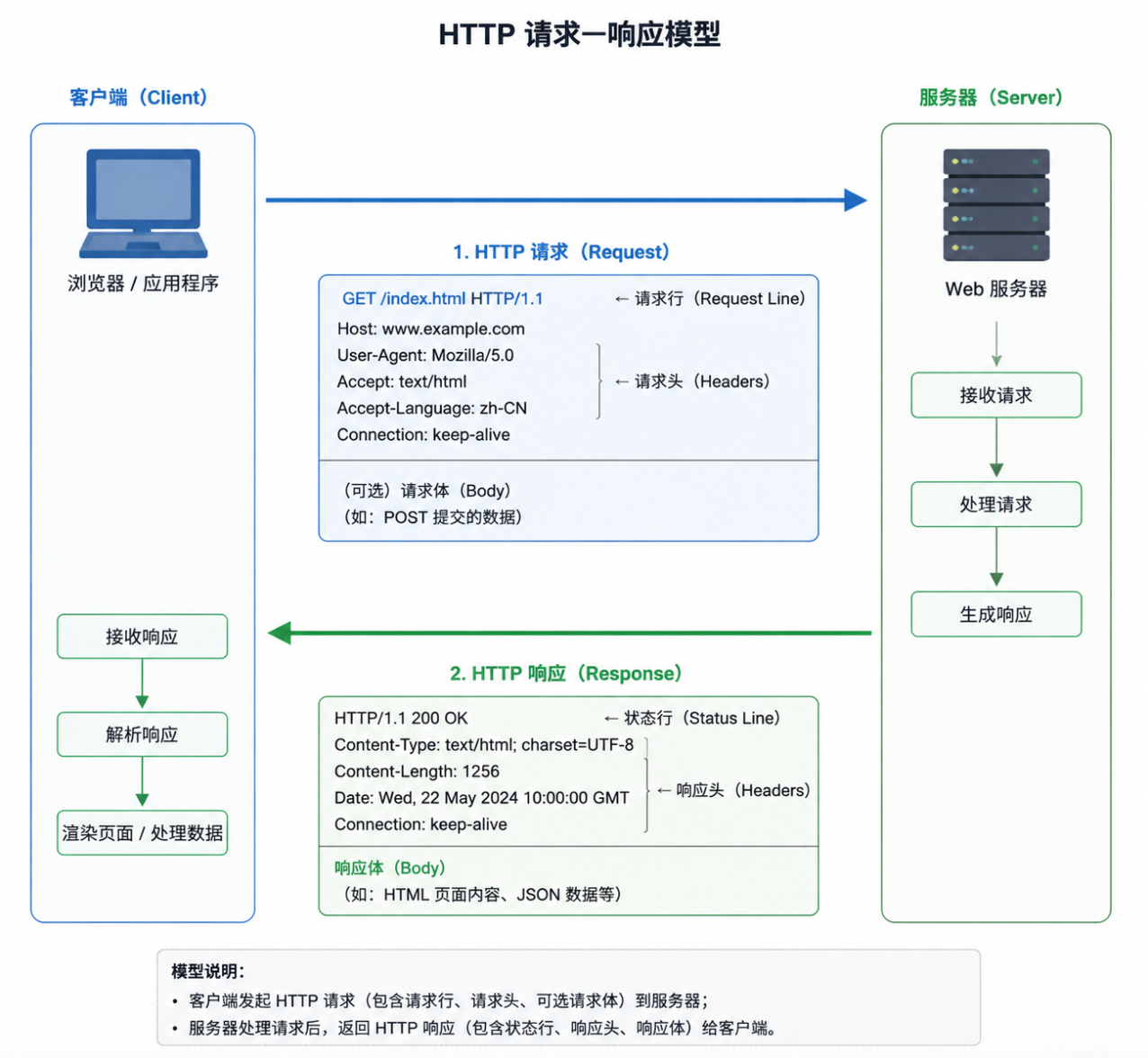
1.1 请求报文
根据上面请求响应模型的图片我们可以看出请求报文分为三部分:请求行,请求头,请求体
**请求行:**报文第一行,核心信息
固定格式:请求方法 / 请求URL HTTP版本号
图中示例:GET /index.html HTTP/1.1
- 请求方法:
GET(告诉服务器要做什么,具体的请求方法在下文讲解) - 请求 URL:
/index.html(要访问的资源路径) - HTTP 版本:
HTTP/1.1(通信使用的协议版本)
这个请求行告诉服务器我要获取(GET)/index.html 这个资源
**请求头:**键值对格式,传递附加信息
紧跟请求行,每行一个键值对,用冒号分隔,告诉服务器客户端的能力、偏好等。图中常见的请求头。
这里没什么需要特别关注的,只需要记住这里是放Cookie的地方。(权限认证)
**请求体:**可选,传递业务数据
只有POST/PUT等提交数据的请求才有,GET请求没有请求体
示例:表单提交的用户名密码、JSON 格式的接口参数
1.2 响应报文
对应图中绿色框,由状态行、响应头、响应体三部分组成。

状态行(Status Line)**:**报文第一行,核心结果
固定格式:HTTP版本号 状态码 状态描述
图中示例:HTTP/1.1 200 OK
- HTTP 版本:
HTTP/1.1 - 状态码:
200(数字,代表请求结果,对于几种状态码的讲解在下文) - 状态描述:
OK(文字,对状态码的解释)
响应头(Headers):键值对格式,服务器的附加信息
紧跟状态行,告诉客户端响应的属性、服务器信息等。这里存Cookie
还要记住Content-Type:响应体的类型和编码(HTML/JSON/ 图片等)
响应体(Body):实际返回的业务内容
- 客户端最终要获取的数据,是报文的核心
- 示例:HTML 页面内容、JSON 接口数据、图片 / 视频二进制流
1.3 最常见的 HTTP 请求方法
|------------|--------------|-----------------------------|-----------------|
| 请求方法 | 核心用途 | 特点 | 典型场景 |
| GET | 获取资源 | 无请求体;参数拼在 URL 后;可被缓存;有长度限制 | 打开网页、查询列表、获取图片 |
| POST | 提交资源 / 创建资源 | 有请求体;参数在 Body 中;不可被缓存;无长度限制 | 登录、注册、提交表单、上传文件 |
| PUT | 全量更新资源 | 有请求体;幂等(多次调用结果相同) | 修改用户全部信息、覆盖文件 |
| DELETE | 删除资源 | 一般无请求体;幂等 | 删除用户、删除文件 |
| HEAD | 仅获取资源的响应头 | 和 GET 完全一致,但服务器不返回响应体 | 检查文件是否存在、获取文件大小 |
| OPTIONS | 查询服务器支持的请求方法 | 服务器返回允许的方法列表 | 跨域预检请求(CORS) |
这里有一个非常经典的面试题:POST和GET的区别
- 本质区别:语义不同(GET 是获取,POST 是提交)
- 其他区别:参数位置、缓存、长度限制、安全性(都不绝对,POST 只是不显示在 URL)
1.4 最常见的 HTTP 响应状态码
状态码是 3 位数字,分为 5 大类,快速标识请求的结果,是状态行的核心。下面标红就是最常见的,需要记住。
1xx:信息性状态码(临时响应,很少直接见到)
100 Continue:客户端可以继续发送请求体(用于大文件上传)
2xx:成功状态码(请求正常处理)
200 OK:最常见,请求完全成功,返回对应资源201 Created:资源创建成功(POST/PUT 创建后返回)204 No Content:请求成功,但无响应体(DELETE 成功后常用)
3xx:重定向状态码(需要客户端进一步操作)
301 Moved Permanently:永久重定向,资源已永久迁移到新 URL,浏览器会缓存302 Found:临时重定向,资源临时在新 URL,浏览器不缓存304 Not Modified:缓存命中,资源未修改,客户端直接使用本地缓存(性能优化核心)
4xx:客户端错误状态码(请求有问题,服务器无法处理)
400 Bad Request:请求参数错误、格式错误(比如 JSON 语法错)401 Unauthorized:未认证(未登录,需要先登录)403 Forbidden:禁止访问(已登录,但没有权限)404 Not Found:最常见,请求的资源不存在(URL 写错、资源已删除)405 Method Not Allowed:请求方法不允许(比如接口只支持 POST,你用了 GET)
5xx:服务器错误状态码(服务器处理出错)
500 Internal Server Error:最常见,服务器内部错误(代码 bug、数据库崩溃)502 Bad Gateway:网关错误(反向代理服务器没收到后端的有效响应)503 Service Unavailable:服务不可用(服务器过载、停机维护)
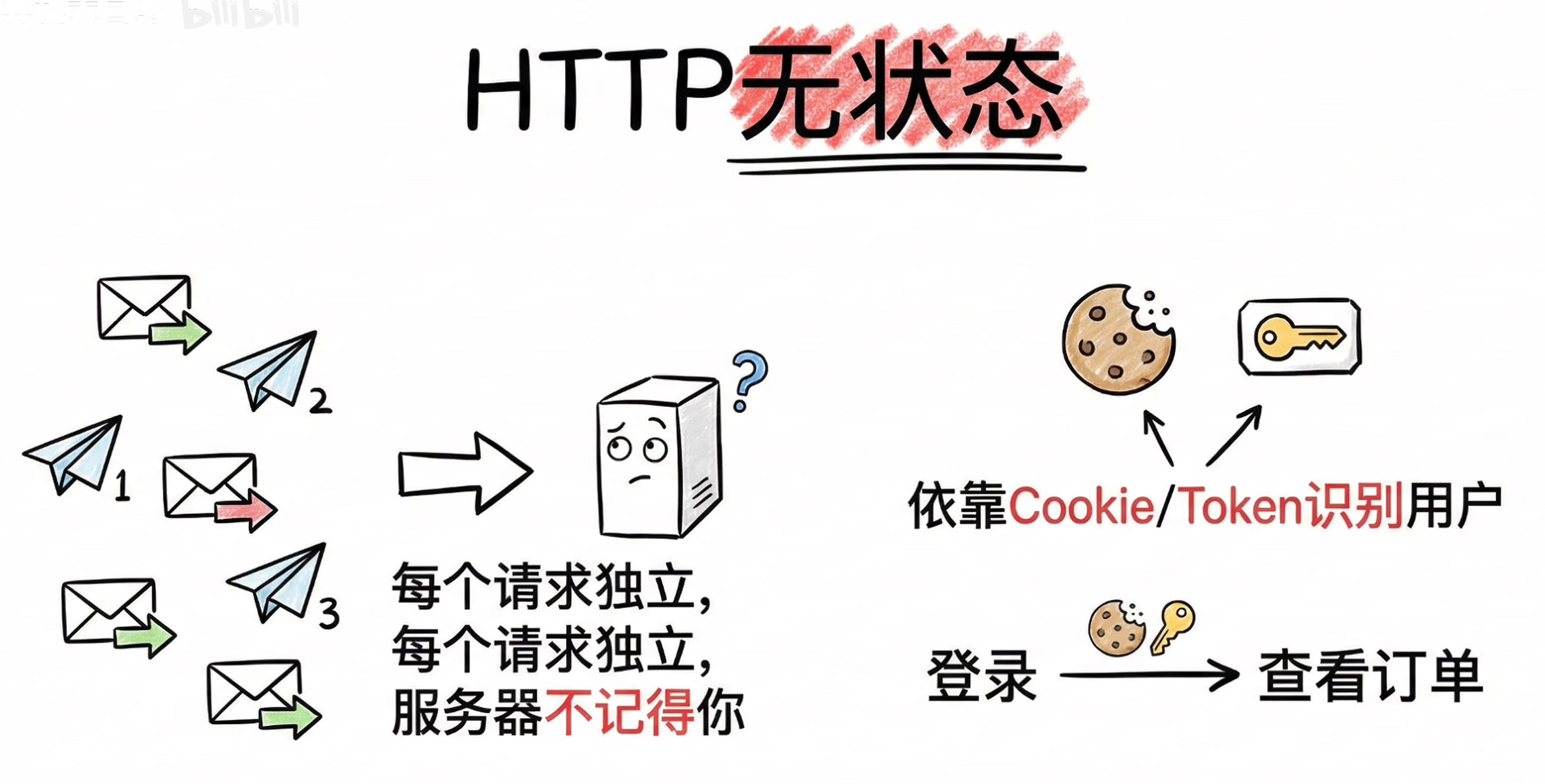
1.5 HTTP是无状态协议
每个请求都是独立的,服务器不会记得你是谁。浏览器必须依靠Cookie或Token,让服务器在每一次请求中知道你是同一个用户
二. HTTPS
HTTPS 不是新的应用层协议,而是 HTTP + SSL/TLS 的组合:在 HTTP 和 TCP 之间加了一层安全套接层(SSL/TLS) ,解决了 HTTP 明文传输的三大致命安全问题:窃听、篡改、冒充 。
HTTP 所有数据都是明文传输,在网络传输的每一个节点(路由器、运营商、WiFi 热点)都能被拦截、读取、修改,没有任何安全性:
- 窃听风险:黑客可以直接获取你的账号密码、银行卡信息、聊天内容
- 篡改风险:黑客可以修改网页内容(比如植入广告、钓鱼链接)
- 冒充风险:黑客可以伪装成你要访问的网站(比如假银行网站)
HTTPS 的核心目标就是解决这三个问题,实现:
- ✅ 保密性:数据加密传输,黑客无法窃听
- ✅ 完整性:数据传输过程中无法被篡改
- ✅ 身份认证:确认你访问的是真实的目标网站,不是黑客伪造的
至于具体实现这里不做具体讲解。不过开发者知道这些也就够了。
三. DNS
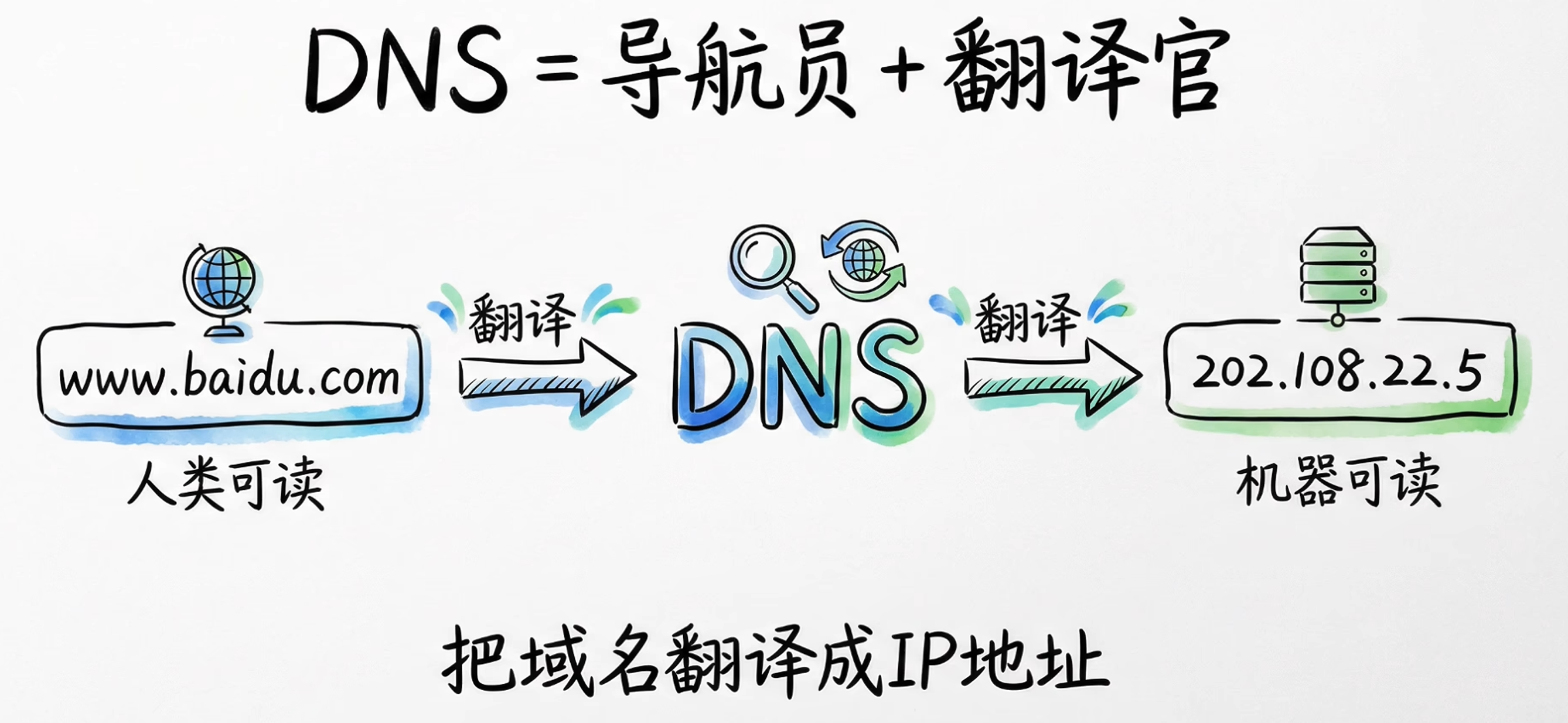
他就是把人类能读懂和能记住的域名(www.baidu.com),翻译成机器能读懂的IP地址
翻译过程:
- 先到本地缓存中找:如果之前访问过这个网站,那就会直接找到这个域名对应的IP地址。这是最快的
- 访问本地DNS服务器:这个主要由你的运营商提供(联通,移动等)
- 如果本地DNS找不到,会继续问根服务器(全球有13个),他不会告诉你最终答案,他会告诉你你的域名属于那个顶级域(.com ,.cn等)。
- 本地DNS会根据根服务器的指引先问顶级域名服务器,然后问权威DNS服务器(存储着真正的域名---IP地址映射关系),查到结果后本地DNS会把查到的结果返还给电脑,然后缓存一段时间。
这么设计为了分权和抗压。