大家好!今天用一篇超详细、超通俗、从硬件原理到实战优化的博客,带你彻底搞懂 MySQL 索引。不管是面试、工作还是考试,看完这篇直接拿捏~
全文结构:
- 什么是索引?为什么要用索引?索引的功能是什么?
- 无索引有多惨?海量数据实测
- 磁盘到底怎么存数据?(看懂索引的根基)
- MySQL 与磁盘交互:Page 是什么?
- 索引本质:从目录 → B+ 树彻底讲透
- 聚簇索引 vs 非聚簇索引
- 主键索引、唯一索引、普通索引、全文索引
- 索引创建 / 查看 / 删除实战
- 索引最佳实践与创建原则
一、 什么是索引?为什么要用索引?索引的功能是什么?
1.1 什么是索引?(一句话秒懂)
索引就是 MySQL 数据表的 "目录"。
- 书没有目录:想找内容要一页一页翻
- 书有目录:看目录直接跳到对应页码
MySQL 索引同理:
- 没有索引 → 全表扫描(一行一行找)
- 有索引 → 按目录快速定位(少查很多行)
1.2 为什么要用索引?(核心原因)
因为 MySQL 数据存在磁盘上,磁盘很慢!
- 不使用索引 查询要一行一行读数据,IO 次数多 → 巨慢数据越多越慢,百万 / 千万级数据直接卡死。
- 使用索引 先查索引目录 → 只加载少量数据页 → 极快 查询速度能提升 几十、几百、上千倍。
1.3 索引的功能是什么?(3 大核心功能)
- **加速查询(最主要功能)**把无序数据变成有序结构(B + 树),避免全表扫描,快速定位数据。
- 约束数据(保证正确性)
- 主键索引:非空、唯一
- 唯一索引:值不能重复帮数据库保证数据不重复、不乱。
- 优化排序与分组 索引本身有序,
order by / group by可以直接用索引顺序,不用重新排序。
二、没有索引,MySQL 会慢到你怀疑人生
索引是数据库提升查询速度最猛、成本最低 的手段:不用加内存、不用改代码、不用调复杂参数,一条 create index,查询速度能快成百上千倍。
但天下没有免费午餐:
- 查询变快
- 插入 / 更新 / 删除变慢(因为要维护索引结构)
所以索引的价值,体现在海量数据的查询场景。
2.1 无索引查询 800 万条数据有多慢?
我们先构造 800 万条数据的表:
sql
-- 生成随机字符串
delimiter $$
create function rand_string(n INT)
returns varchar(255)
begin
declare chars_str varchar(100) default 'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
declare return_str varchar(255) default '';
declare i int default 0;
while i < n do
set return_str = concat(return_str, substring(chars_str,floor(1+rand()*52),1));
set i = i + 1;
end while;
return return_str;
end $$
delimiter ;
-- 生成随机数字
delimiter $$
create function rand_num()
returns int(5)
begin
declare i int default 0;
set i = floor(10+rand()*500);
return i;
end $$
delimiter ;
-- 插入海量数据存储过程
delimiter $$
create procedure insert_emp(in start int(10),in max_num int(10))
begin
declare i int default 0;
set autocommit = 0;
repeat
set i = i + 1;
insert into EMP values ((start+i)
,rand_string(6),'SALESMAN',0001,curdate(),2000,400,rand_num());
until i = max_num
end repeat;
commit;
end $$
delimiter ;
-- 插入 800 万条
call insert_emp(100001, 8000000);无索引查询:
sql
select * from EMP where empno=998877;耗时 4.93s!如果是公网、1000 人并发,直接卡死。
加索引再查:
sql
alter table EMP add index(empno);
select * from EMP where empno=123456;毫秒级出结果!
三、磁盘原理:看懂索引,先懂硬件
MySQL 存数据最终落在磁盘 上。磁盘是机械设备 ,比电子元件慢很多,所以减少 IO 次数 = 提升速度。
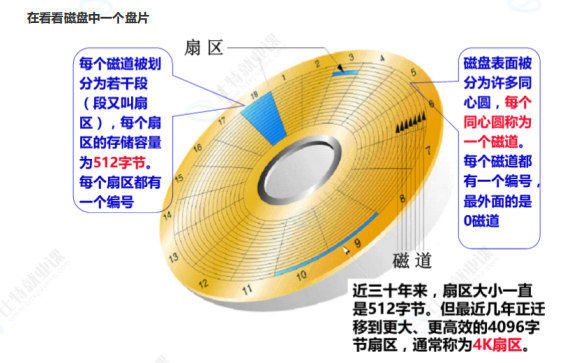
3.1 磁盘结构
- 磁道(Track):同心圆
- 扇区(Sector) :磁道切分的段,512 字节(现在 4K)
- 柱面(Cylinder):多盘片同半径磁道组成
- 磁头(Head):读写数据
定位数据用:
- CHS:磁头 + 柱面 + 扇区
- LBA:线性地址(系统用)
3.2 随机访问 vs 连续访问
- 随机访问 :地址不连续 → 磁头大幅移动 → 慢
- 连续访问 :地址连续 → 磁头几乎不动 → 快
核心结论:数据库优化 = 尽可能减少随机 IO!
四、MySQL 与磁盘交互基本单位:Page(16KB)

MySQL InnoDB 不和磁盘以 512 字节交互,而是以 16KB = 1 Page 为单位。
查看:
sql
SHOW GLOBAL STATUS LIKE 'innodb_page_size';
-- 16384 = 16KB4.1 为什么用 Page?
- 局部性原理:大概率下次访问的数据就在附近
- 一次 IO 加载一整页,后续查询直接在内存做
- IO 次数越少,速度越快
4.2 Page 内部结构
- 数据按主键有序存储
- 双向链表串起多个 Page
- 页内用目录加速查找
五、索引本质:从目录 → B+ 树(超通俗图解)
你查书不会一页页翻,而是看目录 。索引 = MySQL 的目录,空间换时间。
5.1 单页数据 + 目录
一页里数据有序,加目录后:
- 不用从头到尾遍历
- 直接跳到目标位置
5.2 多页数据 + 页目录
数据太多 → 多页页之间也需要目录 → 目录页 目录页再套目录 → B+ 树
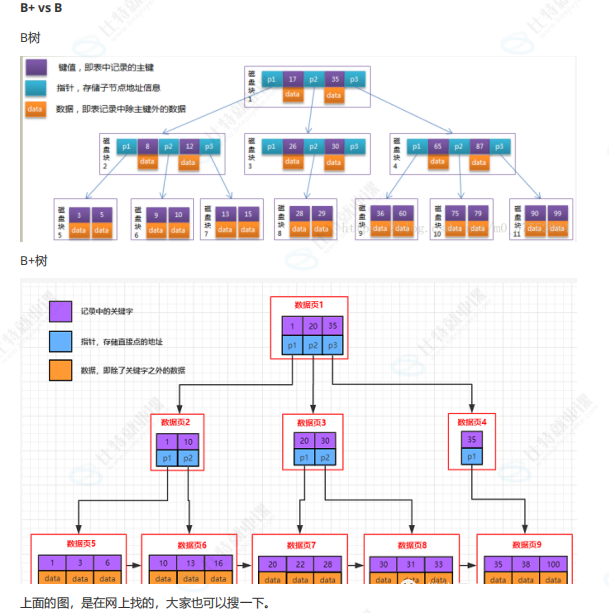
5.3 B+ 树核心特点
- 只有叶子节点存真实数据
- 非叶子只存键值 + 指针 → 一页能存更多 key → 树更矮
- 叶子节点用链表相连 → 范围查询极快
- 查找从根到叶子,高度固定 → IO 次数极少
5.4 为什么不用别的结构?
- 链表:全表扫描,慢死
- 二叉树:容易退化,树太高
- 红黑树:还是二叉,IO 多
- Hash:快,但不支持范围查询
- B 树:节点存数据,页能存的 key 少,树更高
InnoDB 唯一选择:B+ 树
六、聚簇索引 vs 非聚簇索引(面试必考)
6.1 InnoDB:聚簇索引
- 索引和数据存在一起
- 主键索引的叶子节点就是完整数据行
- 文件:
.ibd(数据 + 索引)
6.2 MyISAM:非聚簇索引
- 索引和数据分开
- 索引叶子存数据地址
- 文件:
.frm:结构.MYD:数据.MYI:索引
6.3 回表查询(InnoDB 重点)
- 主键索引:直接拿数据
- 普通 / 辅助索引:叶子只存主键
- 先查普通索引拿到主键 → 再查主键索引拿数据 → 回表
七、4 种索引:创建 + 特点 + 实战
7.1 主键索引(PRIMARY KEY)
- 一个表只能一个
- 列非空、唯一
- 默认生成 B+ 树
sql
-- 建表时
create table user1(id int primary key, name varchar(30));
-- 建表后
alter table user3 add primary key(id);7.2 唯一索引(UNIQUE)
- 列值不重复
- 一个表可多个
- 允许 NULL(除非加 NOT NULL)
sql
create table user4(id int primary key, name varchar(30) unique);
alter table user6 add unique(name);7.3 普通索引(INDEX)
- 最常用
- 允许重复
- 只为加速查询
sql
create index idx_name on user10(name);
alter table user9 add index(name);7.4 全文索引(FULLTEXT)
- 用于文章、长文本
- MyISAM 支持(InnoDB 新版也支持)
- 比
like %xx%快很多
sql
CREATE TABLE articles (
id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,
title VARCHAR(200),
body TEXT,
FULLTEXT (title,body)
)engine=MyISAM;
SELECT * FROM articles
WHERE MATCH (title,body) AGAINST ('database');八、索引管理:查看、删除
8.1 查看索引
sql
show index from 表名;
show keys from 表名;
desc 表名;8.2 删除索引
sql
-- 删主键
alter table 表 drop primary key;
-- 删普通/唯一索引
alter table 表 drop index 索引名;
drop index 索引名 on 表;九、索引创建原则(背会直接用)
- 经常出现在 WHERE 条件的字段建索引
- 唯一性太差(如性别、状态)不建单独索引
- 更新极频繁的字段不建索引
- 不在 WHERE 里的字段绝不建索引
- 优先用复合索引 ,遵循最左匹配
- 尽量使用索引覆盖避免回表
十、总结(一句话串起来)
- 索引 = 数据库的目录,用来快速定位数据
- 不用索引:全表扫描,慢到爆
- 用索引:快速定位,少 IO,速度飞
- 索引三大功能:加速查询、数据约束、优化排序
- InnoDB 是聚簇索引,数据跟主键索引放一起
- 普通索引需要回表
- 只给高频查询、高区分度字段建索引,少建、精建,不要滥用