一.链式二叉树的实现
节点的封装。
//链式二叉树的实现
typedef int BTDatatype;
struct BinaryTreeNode
{
BTDatatype data;
struct BinaryTreeNode* left;
//像链表的next指针一样
//指向左子树的根节点
struct BinaryTreeNode* right;
//指向右子树的根节点
};
typedef struct BinaryTreeNode BTNode;在初阶数据结构中,构建一棵完整的链式二叉树,我们就纯手搓吧。
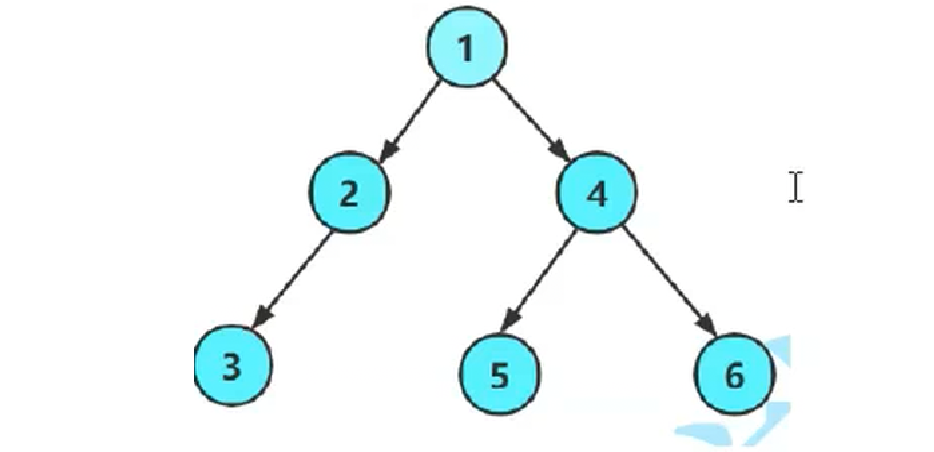
//创造链式二叉树
BTNode* CreateBTree()
{
BTNode* node1 = BuyNode(1);
BTNode* node2 = BuyNode(2);
BTNode* node3 = BuyNode(3);
BTNode* node4 = BuyNode(4);
BTNode* node5 = BuyNode(5);
BTNode* node6 = BuyNode(6);
node1->left = node2;
node1->right = node4;
node2->left = node3;
node4->left = node5;
node4->right = node6;
return node1;
}二.链式二叉树相关函数的实现
(1)深度优先遍历
①前序遍历
按照根-左子树-右子树的方式访问链式二叉树。
对着已经构建好了的树,我们来先过一遍前序遍历。
从root节点开始,再到root的左子树,访问完2后,由于1的左子树还没走完,所以还要到3,访问完3后,由于1的左子树还是没走完,所以还要到3的左子树,遇到空了,则说明3的左子树访问完了,可1的左子树还是没有访问完,按照根-左子树-右子树的顺序,接下来要访问3的右子树,遇到空,则说明3的右子树访问完了,3的根-左子树-右子树都访问完了,也就说明2的左子树访问完了,但1的左子树还没访问完,则下一步接着访问2的右子树,遇到空则说明2的右子树访问完了,2的根-左子树-右子树都访问完了。也就是说明1的左子树访问完了,下一步就要去访问1的右子树。
到了1的右子树,访问完4后,1的右子树还没访问完,那就要按照前序遍历的顺序访问4的左子树,访问完5后,1的右子树也还没访问完,那就要访问5的左子树,遇到空,则说明5的左子树访问完了,接着访问5的右子树,遇到空了,则说明5的根-左子树-右子树都访问完了,同时也说明4的左子树访问完了,但1的右子树还没访问完,紧接着要访问4的右子树,访问完6,再访问6的左子树和右子树,等到6的根-左子树-右子树都访问完了,也就是4的根-左子树-右子树都访问完了,还是1的根-左子树-右子树都访问完了,前序遍历也就完成了。
假设遇到空节点打印N,则前序遍历的顺序就为下图:

代码实现:
//前序遍历
//递归调用
void PrevOrder(BTNode* root)
{
//既是对空树的判断又是递推的结束条件
if(root == NULL)
{
printf("N");
return;
}
//访问根
printf("%d",root->data);
//访问左子树
PrevOrder(root->left);
//访问右子树
PrevOrder(root->right);
}递归展开图的理解:
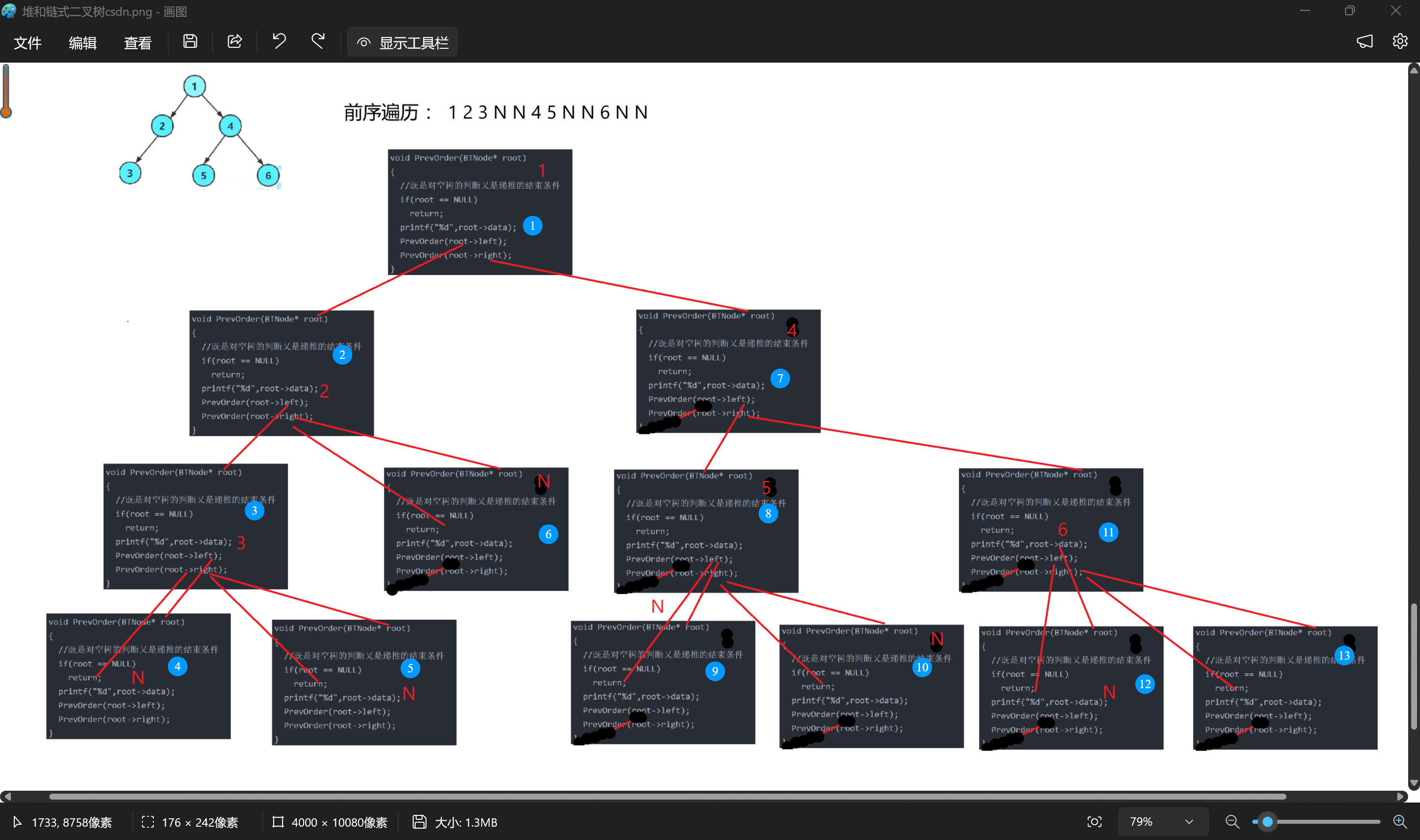
②中序遍历
按照左子树-根-右子树的顺序访问链式二叉树。

代码实现:
//中序遍历
void InOrder(BTNode* root)
{
if(root == NULL)
{
printf("N");
return;
}
//左子树
InOrder(root->left);
//根
printf("%d",root->data);
//右子树
InOrder(root->right);
}③后序遍历
按照左子树-右子树-根的顺序访问链式二叉树。

代码实现:
//后序遍历
void BackOrder()
{
if(root == NULL)
{
printf("N");
return;
}
//访问左子树
BackOrder(root->left);
//访问右子树
BackOrder(root->right);
//访问根
printf("%d",root->data);
}(2)链式二叉树相关函数
①数节点个数
求数的节点个数可以拆分成左子树节点个数+右子树节点个数+1,而左子树的节点个数又可以按一样的逻辑,拆分成左子树节点个数+右子树节点个数+1,右子树可以拆分成左子树节点个数+右子树节点个数+1,这就是递归大问题化成许多个相同解法的小问题的思想。
//数节点总个数
int BTreeSize(BTNode* root)
{
//既是处理空树情况也是递推的结束条件
if(root == NULL)
return 0;
return BTreeSize(root->left)+BTreeSize(root->right)+1;
}②数树的高度
树的高度是左右子树中更高的那棵树的高度+1,左右子树又可以拆分成更小的左右子树。
//链式二叉树的高度
int BTreeHeight(BTNode* root)
{
if(root == NULL)
return 0;
int left = BTreeHeight(root->left);
int right = BTreeHeight(root->right);
return left>right?left+1:right+1;
}细节理解:
int BTreeHeight(BTNode* root)
{
if(root == NULL)
return 0;
return BTreeHeight(root->left)>BTreeHeight(root->right)
?BTreeHeight(root->left+1:BTreeHeight(root->right)+1;
}这样的写法行吗?
其实逻辑是对的,就是如果不将BTreeHeight(root->left)和BTreeHeight(root->right)的值保存下来,那么判断大小的时候需要递归,等返回的时候又需要重新递归一次,这就白白多出许多损耗。
③数叶子节点个数
树的叶子节点个数就是左子树的叶子结点个数+右子树的叶子结点个数,而左右子树又可以继续拆分成更小的左右子树。
//数叶子节点的个数
int BTreeLeafSize(BTNode* root)
{
if(root == NULL)
return;
if(root->left == NULL && root->right == NULL)
return 1;
return BTreeLeafSize(root->left)+BTreeLeafSize(root->right);
}④数树的第k层的节点个数
树的k层节点个数就是左子树的k-1层节点个数+右子树的k-1层节点个数,继续拆分,k越来越小,等k==1时,就到了最初的第k层了,就要返回1了。
//数第k层的节点个数
int BTreeKLeverLeaf(BTNode* root,int k)
{
if(root == NULL)
return 0;
if(k == 1)
return 1;
return BTreeKLeverLeaf(root->left,k-1)+BTreeKLeverLeaf(root->right,k-1);
}⑤查找值为x的节点
和前序遍历有点像,按照根-左子树-右子树的顺序查找x,如果根找到了x,那么左子树就不用找了,如果左子树找到了,那么右子树就不用找了。
//查找值为x的节点值
BTNode* BTreeFind(BTNode* root, BTDataType x)
{
//递推的结束条件也是处理空树的语句
if(root == NULL)
return NULL;
if(root->data == x)
return root;
BTNode* left = BTreeFind(root->left,x);
if(left)
return left;
BTNode* right = BTreeFind(root->right,x);
if(right)
return right;
//当每次左右子树都没找到的时候,就要返回NULL了
return NULL;
}⑥链式二叉树的销毁
从叶子节点开始销毁,就是当root->left和root->right都为空时,就代表root需要销毁了,而销毁叶子节点的前提是深入到叶子结点的位置,所以是先递推到叶子节点,再释放叶子结点。
//链式二叉树的销毁
void BTreeDestroy(BTNode* root)
{
if(root == NULL)
return;
BTreeDestroy(root->left);
BTreeDestroy(root->right);
free(root);
root = NULL;
}(2)广度优先遍历
层序遍历:
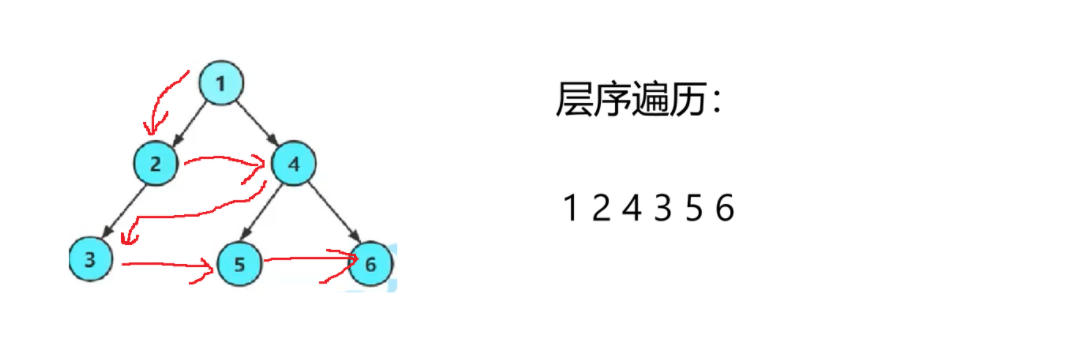
要借助栈来实现。
先把根节点1插入到栈中,然后1再出栈,当1出栈时,把1的左孩子2和右孩子4插入到栈中,2再出栈,2出栈时插入2的左孩子3(右孩子为NULL不插入),4出栈的时候插入4的左孩子5和右孩子6,3再出栈,由于3的左右孩子都为NULL,所以不用插入,5,,6出栈,和3是同样情况,不需要插入,当栈中无数据可出栈时,层序遍历就完成了。
出栈的顺序就体现了层序遍历。
在代码实现前,我们先来想一个问题:插入到栈中的是树的节点还是树的节点值?
很显然是树的节点,不然出栈的时候,我们怎么找得到它的左右孩子呢?
代码实现:
//层序遍历
//Queue.h
//只需要将栈中存储的数据改成树的节点就行
typedef struct BinaryTreeNode* QDatatype;
//前置声明
struct QueueNode
{
QDatatype val;
struct QueueNode* next;
};
typedef struct QueueNode QNode;
//BTree.c
void LevelOrder(BTNode* root)
{
Queue q;
QueueInit(&q);
//初始化
QueuePush(&q,root);
while(!QueueEmpty(&q))
{
BTNode* front = QueueFront(&q);
printf("%d ",front->data);
QueuePop(&q);
//左右孩子不为空就插入
if(front->left)
{
QueuePush(&q,front->left);
}
if(front->right)
{
QueuePush(&q,front->right);
}
}
//不要忘记销毁栈了
QueueDestroy(&q);
}细节理解:pop数据不是销毁了内存空间吗?为什么还能访问堆顶元素front?
确实,pop数据会销毁内存空间,但是销毁的是栈的节点空间,不是栈的节点里的成员变量(树的节点指针)指向的空间,原先的成员变量指针确实无法通过栈的节点指针找到了,可我们已经将成员变量指针赋给了front,通过front就能访问data和左右孩子指针。
层序遍历相关函数:判断二叉树是否为完全二叉树
完全二叉树进行层序遍历时,如果出栈的节点为NULL时,就代表树已经遍历完了,可对于非完全二叉树却不是这样,当出栈的节点为NULL之后一定会存在非空节点,所以我们的切入点就是判断当层序遍历一棵树出栈的节点为空节点后,是否会遇到非空节点。
如果在栈空之前都不能遇到,则说明该树为完全二叉树。
从判断出栈的节点是否为空这句话,我们就能知道这里的入栈和层序遍历有些不同,层序遍历中NULL是不入栈的,但在判断是否为完全二叉树的函数中,NULL节点也是要入栈的。
//判断是否为完全二叉树
int BTreeComplete(BTNode* root)
{
Queue q;
QueueInit(&q);
QueuePush(&q,root);
while(!QueueEmpty(&q))
{
BTNode* front = QueueFront(&q);
QueuePop(&q);
//出栈节点为空,就跳出循环
if(front == NULL)
break;
//不用再判断孩子节点是否为空了,无论空否都要入栈
QueuePush(&q,root->left);
QueuePush(&q,root->right);
}
//判断在遇到空节点后会不会遇到非空节点
while(!QueueEmpty(&q))
{
BTNode* front = QueueFront(&q);
QueuePop(&q);
if(front != NULL)
return 0;
}
//在栈空之后都没有遇到非空节点,则说明该树为完全二叉树
return 1;
}细节理解:
①为什么出栈出现了空节点,就可以直接break?如果此时树的节点还没有全部入栈呢?这不会影响判断吗?
先说结论,树的节点有没有完全入栈,并不会影响判断。
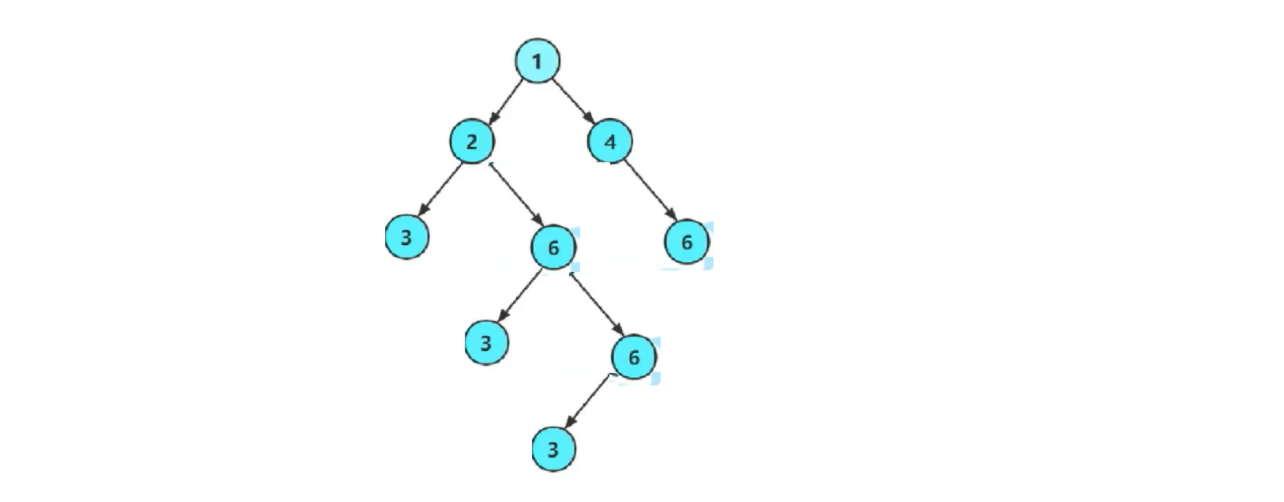
以这棵形状怪异的非完全二叉树举例:
当4的左孩子NULL出栈时,为空就会跳出第一个while循环,此时,层序遍历的前五个数据1,2,4,3,6已经出栈了,第6,7,8个元素还在栈内,最后一个元素3还未入栈。
进入第二个while循环后,就开始pop,判断是否会出现非空节点,pop的第一个元素是第6个元素6,很显然这是非空节点,所以返回0(假)。
最后一个元素3没有入栈,但也并不影响非完全二叉树的判断。
②不额外考虑空树的情况吗?
可以代入一下空树的情况,NULL入栈,栈还是空,两个while循环都不会进入,直接就返回1了。
------end------