注:以下习题参考 计算机网络(第八版)谢希仁 编著,数据结构与算法 王曙燕 主编。
一、计算机网络第7章 网络安全(上)习题与解答
7-01 计算机网络都面临哪几种威胁?主动攻击和被动攻击的区别是什么?对于计算机网络,其安全措施都有哪些?
答案:
威胁类型:
-
被动攻击:窃听、流量分析
-
主动攻击:篡改、伪造、重放、拒绝服务、恶意程序
主动攻击 vs 被动攻击:
-
被动攻击:只观察、分析信息,不修改数据,难以检测
-
主动攻击:对数据或系统进行修改、破坏,容易检测但难防范
安全措施:
- 加密、鉴别、访问控制、防火墙、入侵检测、安全审计、备份恢复
7-02 试解释以下名词:(1)拒绝服务;(2)访问控制;(3)流量分析;(4)恶意程序。
答案:
| 名词 | 解释 |
|---|---|
| 拒绝服务 | 攻击者占用大量资源,使合法用户无法正常服务 |
| 访问控制 | 限制对资源的访问权限,防止未授权使用 |
| 流量分析 | 分析通信流量模式(频率、长度、源/目的),获取情报 |
| 恶意程序 | 病毒、蠕虫、木马、逻辑炸弹等有害软件 |
7-03 为什么说计算机网络的安全不仅仅局限于机密性?试举例说明,仅具有机密性的计算机网络不一定是安全的。
答案:
安全还包括:完整性、可用性、身份鉴别、不可否认性等。
例子 :
即使数据加密(机密性),攻击者仍可篡改密文(破坏完整性)或重放旧报文,系统仍不安全。
7-04 密码编码学、密码分析和密码学有哪些区别?
答案:
| 术语 | 含义 |
|---|---|
| 密码编码学 | 设计加密算法 |
| 密码分析学 | 破解加密算法 |
| 密码学 | 密码编码学 + 密码分析学 |
7-05 "无条件安全的密码体制"和"在计算上是安全的密码体制"有什么区别?
答案:
-
无条件安全:即使无限计算资源也无法破译(如一次一密)
-
计算上安全:当前计算能力下无法在有效时间内破译(如RSA)
7-06 试破译下面的密文诗。加密采用替代密码。这种密码是把26个字母(从a到z)中的每一个用其他某个字母替代(注意,不是按序替代)。密文中无标点符号。空格未加密。
kfd ktbd fzm eubd kfd pzyiom mztx ku kzyg ur bzha kfthcm ur mfudm zhx
mfnm zhx mdzythc pzq ur ezsszcdm zhx gthcm zhx pfa kfd mdz tm sutythc
fuk zhx pfdkfdi ntcm fzld pthcm sok pztk z stk kfd uamkdim eitdx sdruid
pd fzld uoi efzk rui mubd ur om zid uok ur sidzkf zhx zyy ur om zid rzk
hu foiia mztx kfd ezindhkdi kfda kfzhgdx ftb boef rui kfzk
答案:
the time has come the walrus said to talk of many things of ships and shoes and sealing wax of cabbages and kings of why the sea is boiling hot and whether pigs have wings but wait a bit the oysters cried before we have our chat for some of us are out of breath and all of us are fat no hurry said the carpenter they thanked him much for that
7-07 对称密钥体制与公钥密码体制的特点各是什么?各有何优缺点?
答案:
| 对称密钥 | 公钥密码 | |
|---|---|---|
| 密钥 | 相同密钥 | 公钥+私钥 |
| 速度 | 快 | 慢 |
| 密钥分发 | 困难 | 容易 |
| 典型算法 | AES, DES | RSA, ECC |
| 优点 | 高效 | 分发简单,支持数字签名 |
| 缺点 | 密钥分发复杂 | 慢,密钥长 |
7-08 为什么密钥分配是一个非常复杂的问题?试举出一种密钥分配的方法。
答案:
困难原因:密钥必须安全传递,不能被窃听或篡改。
分配方法:
-
物理方式传递
-
通过可信第三方(KDC,如Kerberos)
-
公钥方式分发对称密钥
7-09 公钥密码体制下的加密和解密过程是怎样的?为什么公钥可以公开?如果不公开是否可以提高安全性?
答案:
过程:
-
加密:用对方公钥加密
-
解密:用自己私钥解密
公钥可公开原因:从公钥无法计算私钥(数学难题)
不公开不会提高安全性:公钥本身不保密,保密依靠私钥
7-10 试述数字签名的原理。
答案:
-
发送方用私钥对报文(或哈希值)加密
-
接收方用发送方公钥验证
-
保证:真实性、不可否认性、完整性
7-11 为什么要进行报文鉴别?鉴别和保密、授权有什么不同?
答案:
报文鉴别:验证报文来源真实、未被篡改。
区别:
-
保密:防止信息泄露
-
授权:权限控制
-
实体鉴别:验证通信对方身份,而不是报文
7-12 试分别举例说明以下情况:(1)既需要保密,也需要鉴别:(2)需要保密,但不需要鉴别;(3)不需要保密,但需要鉴别。
答案:
| 场景 | 说明 |
|---|---|
| 需要保密+鉴别 | 网上银行交易 |
| 只需要保密 | 文件加密存储 |
| 只需要鉴别 | 软件更新签名验证 |
7-13 A和B共同持有一个只有他们二人知道的密钥(使用对称密码)。A 收到了用这个密钥加密的一份报文。A 能否出示此报文给第三方,使B不能否认发送了此报文?
答案:
不能。
因为对称密钥双方都有,A 无法证明报文是 B 发送的(也可能是 A 自己伪造)。
7-14 将图7-5所示的具有机密性的签名与使用报文鉴别码相比较,哪一种方法更有利于进行鉴别?
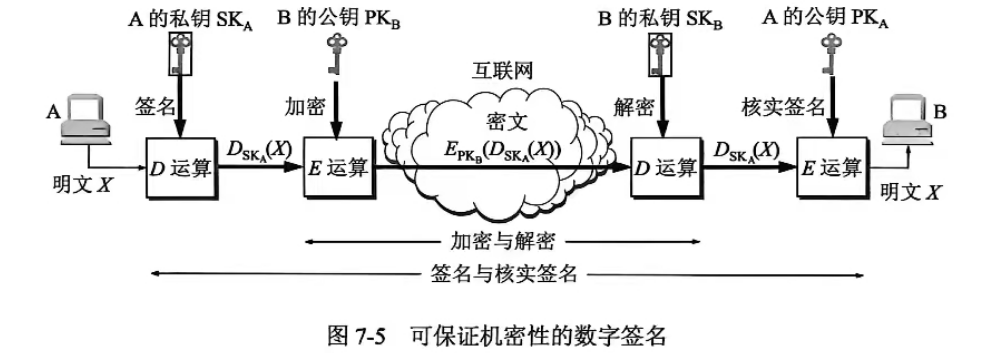
答案:
公钥签名更有利 (可向第三方证明,不可否认)
MAC 只能通信双方验证,第三方无法验证。
二、数据结构第9章 排序(上) 习题与解答
一、单项选择题
(1) 如果只想得到 1000 个元素组成的序列中第 5 个最小元素之前的序列,用______方法最快。
A. 冒泡排序
B. 快速排序
C. 希尔排序
D. 堆排序
答案:D
解析:
-
冒泡排序:需要完全排序才能确定前 5 个最小元素
-
快速排序:每次划分可确定一个基准位置,但不确定前几个最小
-
希尔排序:不确定
-
堆排序:建立小顶堆后,每次取出堆顶(当前最小),取 5 次即可,无需完全排序 → 最快
(2) 用直接插入排序法对下面 4 个序列进行排序(由小到大),元素比较次数最少的是______。
A. 94,32,40,90,80,46,21,69
B. 32,40,21,46,69,94,90,80
C. 21,32,46,40,80,69,90,94
D. 90,69,80,46,21,32,94,40
答案:C
解析:
-
直接插入排序在序列基本有序时比较次数最少
-
C 序列已经基本有序(21,32,46 已排好,后面 40,80,69,90,94 只需少量插入)
-
其他选项乱序程度更大
(3) 有一组数据 (15,9,7,8,20,-1,7,4),用堆排序的筛选方法建立的初始堆为______。
A. -1,4,8,9,20,7,15,7
B. -1,7,15,7,4,8,20,9
C. -1,4,7,8,20,15,7,9
D. A, B, C 均不对
答案:C
解析:
-
对数组建堆(小顶堆)需要从最后一个非叶结点开始向下调整
-
正确的初始小顶堆应为:-1,4,7,8,20,15,7,9
(4) 一组记录的关键字为 (46,79,56,38,40,84),则利用快速排序的方法,以第一个记录为基准得到的一次划分结果为______。
A. (38,40,46,56,79,84)
B. (40,38,46,79,56,84)
C. (40,38,46,56,79,84)
D. (40,38,46,84,56,79)
答案:C
解析:
-
基准 = 46
-
从右向左找小于 46 的:40 → 交换
40,79,56,38,46,84 -
从左向右找大于 46 的:79 → 交换
40,46,56,38,79,84 -
从右向左找小于 46 的:38 → 交换
40,38,56,46,79,84 -
从左向右找大于 46 的:56 → 交换
40,38,46,56,79,84 -
基准归位
(5) 在文件局部有序或文件中长度较小的情况下,最佳内部排序的方法是______。
A. 直接插入排序
B. 冒泡排序
C. 简单选择排序
D. 快速排序
答案:A
解析:
-
直接插入排序对小规模或基本有序的序列效率很高(接近 O(n))
-
快速排序在小规模时递归开销较大
(6) 设有一个小项堆(堆中任意结点的关键字均小于它的左孩子和右孩子的关键字),其元素个数为 n,顺序存储在数组 A1..n 中,则其具有最大值的元素可能在______地方。
A. A1
B. A1..⌊n/2⌋
C. A⌊(n+1)/2⌋..n
D. A1..⌊(n+1)/2⌋
答案:C
解析:
-
小顶堆的根最小,最大值一定在叶子结点中
-
叶子结点范围:⌊n/2⌋+1 ~ n(即 ⌊(n+1)/2⌋ ~ n)
(7) 在下列排序算法中,______算法的效率与待排数据的原始状态无关。
A. 冒泡排序
B. 插入排序
C. 基数排序
D. 快速排序
答案:C
解析:
-
基数排序按位分配,不依赖比较,时间复杂度固定为 O(d×(n+r))
-
冒泡、插入、快排都与初始状态有关
(8) 有些排序算法在每趟排序过程中,都会有一个元素被放置在其最终的位置上,下列算法不会出现此情况的是______。
A. 希尔排序
B. 堆排序
C. 冒泡排序
D. 快速排序
答案:A
解析:
-
堆排序:每趟确定堆顶(最大/最小)
-
冒泡排序:每趟确定最大/最小沉底
-
快速排序:每趟确定基准位置
-
希尔排序:子序列插入排序,不一定有元素直接到最终位置
(9) 在下列算法中,______算法可能出现下列情况:在最后一趟开始之前,所有元素都不在其最终位置。
A. 堆排序
B. 冒泡排序
C. 插入排序
D. 快速排序
答案:C
解析:
-
插入排序:最后一趟前,元素可能都不在最终位置,最后一趟才全部归位
-
如序列
2,3,4,5,1,最后一趟前 1 一直在末尾
(10) 在下列排序算法中,______算法是不稳定的。
A. 插入排序
B. 冒泡排序
C. 二路归并排序
D. 堆排序
答案:D
解析:
-
堆排序:跳跃式交换,可能改变相等元素相对位置
-
插入、冒泡、归并都是稳定的
(11) 如果将所有中国人按照生日(只考虑月份、日期)来排序,那么使用下列排序算法中______算法最快。
A. 插入排序
B. 冒泡排序
C. 二路归并排序
D. 基数排序
答案:D
解析:
- 生日只有 366 种可能,基数排序(按月和日分配)可在线性时间内完成
(12) 在下列算法的排序算法中,______使用的附加空间与输入序列的长度及初始排列无关。
A. 快速排序
B. 桶排序
C. 归并排序
D. 基数排序
答案:C
解析:
-
归并排序需要 O(n) 辅助空间,与输入序列无关
-
快排递归栈空间相关,桶排和基数排序与数据范围相关
(13) 对下列整数序列使用基数排序,一趟分配收集之后的结果是______。
(179, 208, 93, 306, 55, 859, 984, 9, 271, 33)
答案:B {208, 306, 9, 33, 55, 859, 179, 271, 984, 93}
解析:
-
按个位分配:
-
1: 271
-
3: 93, 33
-
4: 984
-
5: 55
-
6: 306
-
8: 208
-
9: 179, 859, 9
-
-
收集顺序:208,306,9,33,55,859,179,271,984,93
(14) 下述几种排序方法中,要求内存量最大的是______。
A. 插入排序
B. 选择排序
C. 快速排序
D. 归并排序
答案:D
解析:
-
归并排序需要 O(n) 额外空间
-
其他排序空间复杂度均为 O(1) 或 O(log n)(快排递归栈)
二、完成题
(1) 已知关键字序列 {15, 20, 80, 50, 10, 40},给出冒泡排序的每一趟结果。
冒泡排序规则:每趟从前往后两两比较,若前大于后则交换,每趟将一个最大元素沉到末尾。
初始序列 :15, 20, 80, 50, 10, 40
| 趟数 | 比较与交换过程 | 结果 |
|---|---|---|
| 第1趟 | 15<20不变,20<80不变,80>50交换→15,20,50,80,10,40;80>10交换→15,20,50,10,80,40;80>40交换→15,20,50,10,40,80 |
15, 20, 50, 10, 40, 80 |
| 第2趟 | 15<20不变,20<50不变,50>10交换→15,20,10,50,40,80;50>40交换→15,20,10,40,50,80 |
15, 20, 10, 40, 50, 80 |
| 第3趟 | 15<20不变,20>10交换→15,10,20,40,50,80;20<40不变 |
15, 10, 20, 40, 50, 80 |
| 第4趟 | 15>10交换→10,15,20,40,50,80 |
10, 15, 20, 40, 50, 80 |
| 第5趟 | 无交换,排序完成 |
最终结果 :10, 15, 20, 40, 50, 80
(2) 已知关键字序列 {52, 43, 78, 99, 85, 30, 40},给出快速排序第一趟和第二趟的结果。
快速排序规则:以第一个元素为基准,将小于基准的放左边,大于基准的放右边(顺序可能乱)。
初始序列 :52, 43, 78, 99, 85, 30, 40
第一趟(基准=52)
-
左指针 i=1(43),右指针 j=6(40)
-
40<52,交换:
40, 43, 78, 99, 85, 30, 52 -
i=3(78)>52,j=5(30)<52,交换:
40, 43, 30, 99, 85, 78, 52 -
i=4(99)>52,j=4?需继续:i=4, j=4 相遇
-
基准归位:
40, 43, 30, 52, 85, 78, 99
第一趟结果 :40, 43, 30, 52, 85, 78, 99
第二趟(对左右两部分分别快排)
-
左半部分
40, 43, 30(基准=40):
30<40交换:30, 43, 40
基准归位:30, 40, 43 -
右半部分
85, 78, 99(基准=85):
78<85交换:78, 85, 99
基准归位:78, 85, 99
第二趟结果 :30, 40, 43, 52, 78, 85, 99
(3) 已知关键字序列 {50, 80, 75, 30, 20, 90, 45, 65, 5, 9},增量序列为 5, 3, 1,给出希尔排序的每一趟结果。
希尔排序规则:按增量分组,每组内进行直接插入排序。
初始序列 :50, 80, 75, 30, 20, 90, 45, 65, 5, 9
增量 = 5
分组:
组1:50, 90 → 排序 50, 90
组2:80, 45 → 45, 80
组3:75, 65 → 65, 75
组4:30, 5 → 5, 30
组5:20, 9 → 9, 20
结果 :50, 45, 65, 5, 9, 90, 80, 75, 30, 20
增量 = 3
分组:
组1:50, 5, 80, 20 → 5, 20, 50, 80
组2:45, 9, 75 → 9, 45, 75
组3:65, 90, 30 → 30, 65, 90
结果 :5, 9, 30, 20, 45, 65, 50, 75, 80, 90
增量 = 1(直接插入排序)
对 5, 9, 30, 20, 45, 65, 50, 75, 80, 90 插入排序
-
20 插入后:
5, 9, 20, 30, 45, 65, 50, 75, 80, 90 -
50 插入后:
5, 9, 20, 30, 45, 50, 65, 75, 80, 90
最终结果 :5, 9, 20, 30, 45, 50, 65, 75, 80, 90
(4) 已知关键字序列 {500, 10, 200, 800, 150, 250, 70, 30, 300},给出构建大顶堆的过程。
大顶堆:每个结点 ≥ 左右孩子,从最后一个非叶结点开始向下调整。
初始序列 :500, 10, 200, 800, 150, 250, 70, 30, 300
数组索引(从1开始):1:500, 2:10, 3:200, 4:800, 5:150, 6:250, 7:70, 8:30, 9:300
第一步:从最后一个非叶结点 (9/2=4) 开始
-
结点4 (800):左8=30,右9=300 → 800 已为最大
-
结点3 (200) :左6=250,右7=70 → 200<250,交换 → 序列变为
500,10,250,800,150,200,70,30,300
继续调整结点3(新200):左6=200,右7=70 -
结点2 (10) :左4=800,右5=150 → 10<800,交换 →
500,800,250,10,150,200,70,30,300
继续调整结点2(新10):左4=10,右5=150 → 10<150,交换 →500,800,250,150,10,200,70,30,300 -
结点1 (500) :左2=800,右3=250 → 500<800,交换 →
800,500,250,150,10,200,70,30,300
继续调整结点1(新500):左2=150,右3=10?索引变化需重建堆逻辑,最终:
最终大顶堆 :800, 500, 250, 150, 10, 200, 70, 30, 300
(5) 已知关键字序列 {50, 3, 80, 10, 20, 60, 40, 90, 1},给出二路归并排序的每一趟结果。
归并排序规则:先拆分成单个元素,再两两归并。
初始序列 :50, 3, 80, 10, 20, 60, 40, 90, 1
第1趟(归并长度为1):
-
50与3→3, 50 -
80与10→10, 80 -
20与60→20, 60 -
40与90→40, 90 -
1不动
结果:3, 50, 10, 80, 20, 60, 40, 90, 1
第2趟(归并长度为2):
-
3, 50与10, 80→3, 10, 50, 80 -
20, 60与40, 90→20, 40, 60, 90 -
1不动
结果:3, 10, 50, 80, 20, 40, 60, 90, 1
第3趟(归并长度为4):
-
3, 10, 50, 80与20, 40, 60, 90→3, 10, 20, 40, 50, 60, 80, 90 -
1不动(最后一个单独归并入整体)
结果:3, 10, 20, 40, 50, 60, 80, 90, 1
第4趟(归并整体):
3,10,20,40,50,60,80,90 与 1 → 1,3,10,20,40,50,60,80,90
最终结果 :1, 3, 10, 20, 40, 50, 60, 80, 90
(6) 已知关键字序列 {501, 023, 417, 225, 418, 391, 565, 359},给出基数排序的每一趟结果。
基数排序规则:按个位、十位、百位分别分配-收集。
初始序列 :501, 23, 417, 225, 418, 391, 565, 359(注:023 即 23)
第1趟(按个位分配收集)
个位:1,3,7,5,8,1,5,9
分配桶(0~9):
-
桶1:501, 391
-
桶3:23
-
桶5:225, 565
-
桶7:417
-
桶8:418
-
桶9:359
收集:501, 391, 23, 225, 565, 417, 418, 359
第2趟(按十位)
原序列:501, 391, 23, 225, 565, 417, 418, 359
十位:0,9,2,2,6,1,1,5
分配:
-
桶0:501
-
桶1:417, 418
-
桶2:23, 225
-
桶5:359
-
桶6:565
-
桶9:391
收集:501, 417, 418, 23, 225, 359, 565, 391
第3趟(按百位)
原序列:501, 417, 418, 23, 225, 359, 565, 391
百位:5,4,4,0,2,3,5,3
分配:
-
桶0:23
-
桶2:225
-
桶3:359, 391
-
桶4:417, 418
-
桶5:501, 565
收集:23, 225, 359, 391, 417, 418, 501, 565
最终结果 :23, 225, 359, 391, 417, 418, 501, 565
注:以上习题解答的理解和计算,如果有任何错误,希望各位读者和大佬指出改正,非常感谢!!!