文章目录
- [Redis 从入门到精通:缓存设计与实战](#Redis 从入门到精通:缓存设计与实战)
-
- 一、引言
- [二、Redis 核心数据结构与选型策略](#二、Redis 核心数据结构与选型策略)
-
- [2.1 五种基础数据结构](#2.1 五种基础数据结构)
- [2.2 选型原则](#2.2 选型原则)
- 三、缓存设计中的三大经典问题
-
- [3.1 缓存穿透](#3.1 缓存穿透)
- [3.2 缓存击穿](#3.2 缓存击穿)
- [3.3 缓存雪崩](#3.3 缓存雪崩)
- 四、数据一致性:缓存与数据库的双写难题
-
- [4.1 问题本质](#4.1 问题本质)
- [4.2 推荐方案:Cache-Aside 模式](#4.2 推荐方案:Cache-Aside 模式)
- [4.3 最终一致性保障](#4.3 最终一致性保障)
- 五、实战案例:构建高可用的用户会话缓存
-
- [5.1 需求分析](#5.1 需求分析)
- [5.2 设计思路](#5.2 设计思路)
- [5.3 代码实现(伪代码)](#5.3 代码实现(伪代码))
- [5.4 性能优化](#5.4 性能优化)
- [六、Redis 高级特性与最佳实践](#六、Redis 高级特性与最佳实践)
-
- [6.1 持久化策略](#6.1 持久化策略)
- [6.2 内存淘汰策略](#6.2 内存淘汰策略)
- [6.3 分布式锁](#6.3 分布式锁)
- 七、总结
Redis 从入门到精通:缓存设计与实战
一、引言
在当今高并发、低延迟的互联网应用中,缓存系统已成为架构设计中不可或缺的一环。Redis 作为业界最流行的内存数据库,凭借其丰富的数据结构、高性能的读写能力以及灵活的持久化机制,成为缓存领域的首选方案。然而,许多开发者在实际使用 Redis 时,往往只停留在简单的 key-value 存取层面,对缓存穿透、缓存雪崩、数据一致性等深层次问题缺乏系统性的理解。
本文将从 Redis 的核心数据结构出发,深入剖析缓存设计中的常见陷阱与解决方案,并结合实战案例,帮助读者构建一套健壮的缓存体系。无论你是刚接触 Redis 的初学者,还是希望提升缓存设计能力的资深开发者,本文都将为你提供有价值的参考。
二、Redis 核心数据结构与选型策略
2.1 五种基础数据结构
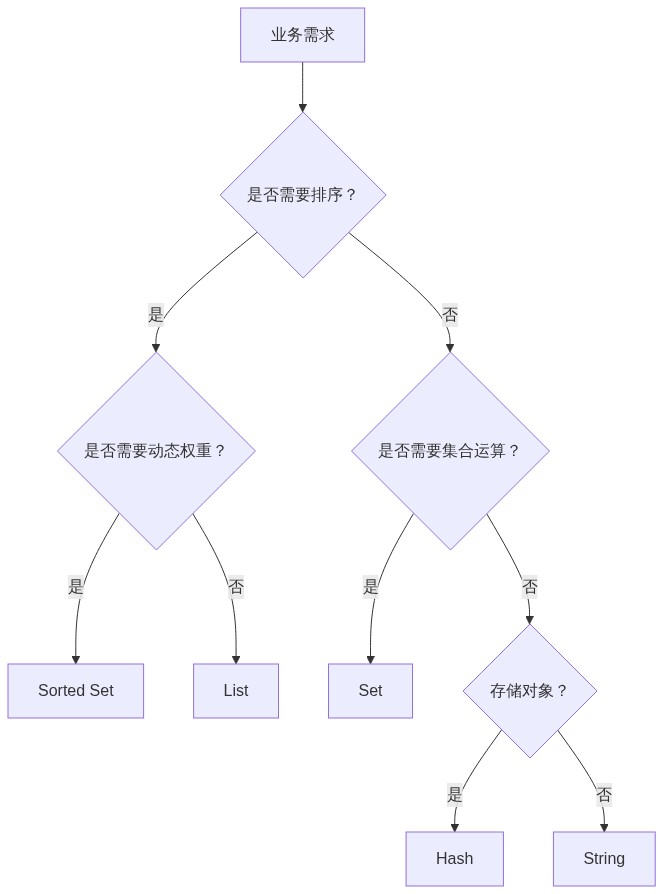
Redis 提供了五种基础数据结构,每种结构都有其独特的应用场景:
- String:最基础的键值对,适合存储简单数据(如计数器、session 信息)。
- Hash:适合存储对象(如用户信息),支持对单个字段的增删改查。
- List:双向链表,适合消息队列、最新消息列表等场景。
- Set:无序集合,适合去重、交集/并集运算(如共同好友)。
- Sorted Set:有序集合,适合排行榜、延时队列等需要排序的场景。
2.2 选型原则
在实际项目中,选择哪种数据结构取决于业务需求:
- 如果需要存储一个完整的对象,且需要频繁修改部分字段,优先选择 Hash。
- 如果需要维护一个有序列表(如最新文章),List 或 Sorted Set 是更好的选择。
- 如果需要进行集合运算(如共同关注),Set 是最佳选择。
三、缓存设计中的三大经典问题
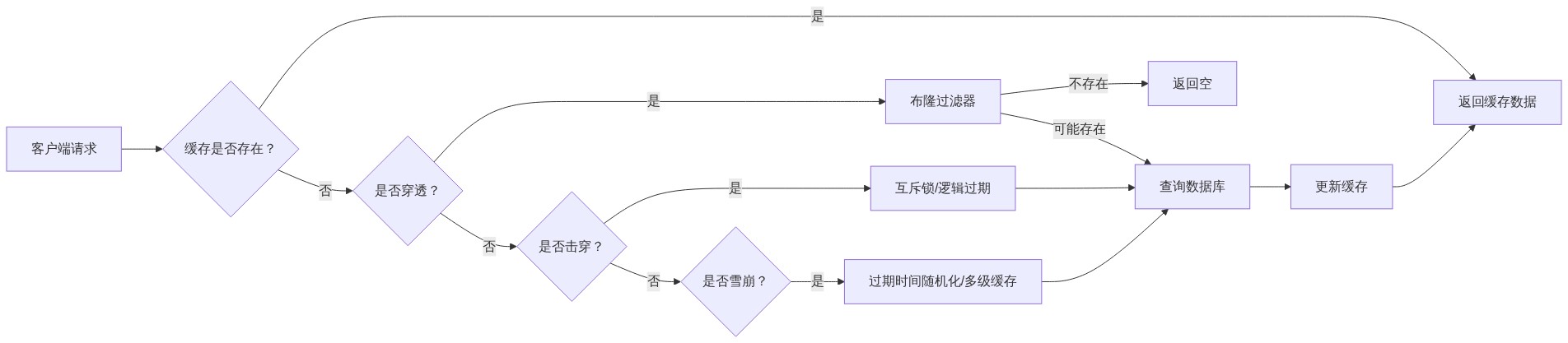
3.1 缓存穿透
问题描述:查询一个不存在的数据,由于缓存中不存在,请求直接打到数据库,导致数据库压力剧增。
解决方案:
- 布隆过滤器:在缓存层之前加一层布隆过滤器,快速判断 key 是否可能存在。
- 缓存空值:将查询结果为 null 的 key 也缓存起来,设置较短的过期时间(如 5 分钟)。
3.2 缓存击穿
问题描述:一个热点 key 在过期瞬间,大量并发请求同时访问该 key,导致数据库瞬间被压垮。
解决方案:
- 互斥锁:当缓存失效时,只允许一个线程去加载数据,其他线程等待。
- 逻辑过期:在 value 中存储过期时间,异步更新缓存。
3.3 缓存雪崩
问题描述:大量 key 在同一时间过期,或者 Redis 服务宕机,导致所有请求直接打到数据库。
解决方案:
- 过期时间随机化:在基础过期时间上增加随机值,避免大量 key 同时过期。
- 多级缓存:引入本地缓存(如 Caffeine)作为 Redis 的降级方案。
- Redis 高可用:部署主从架构或哨兵模式,避免单点故障。
四、数据一致性:缓存与数据库的双写难题
4.1 问题本质
在缓存与数据库并存的系统中,数据一致性是最棘手的挑战。常见的双写策略包括:
- 先更新数据库,再删除缓存:最常用的策略,但存在删除缓存失败的风险。
- 先删除缓存,再更新数据库:可能导致并发读请求读到旧数据。
- 延迟双删:先删除缓存,更新数据库,再延迟一段时间后再次删除缓存。
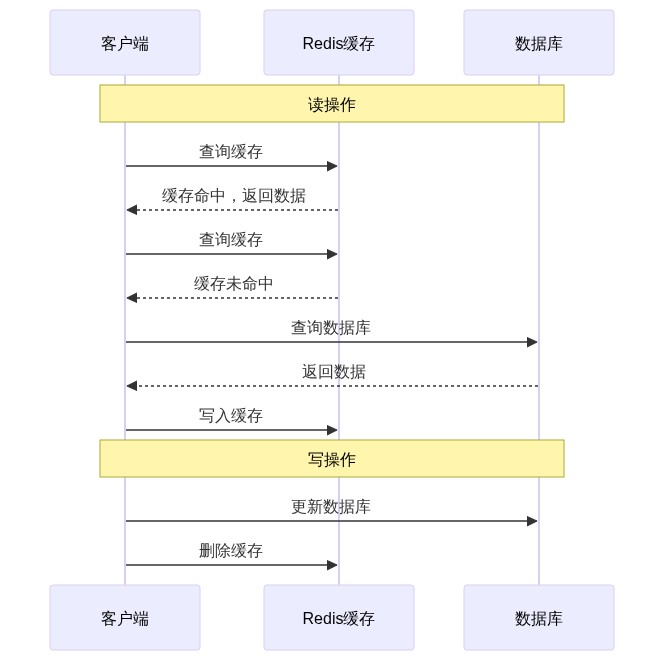
4.2 推荐方案:Cache-Aside 模式
Cache-Aside 模式是业界公认的最佳实践:
- 读操作:先读缓存,命中则返回;未命中则读数据库,然后写入缓存。
- 写操作:先更新数据库,然后删除缓存。
为什么删除缓存而不是更新缓存?
因为更新缓存需要额外的计算成本,且在高并发下容易导致数据不一致。删除缓存后,下一次读请求会重新加载最新数据。
4.3 最终一致性保障
即使采用 Cache-Aside 模式,仍可能出现短暂的不一致。可以通过以下方式增强:
- 消息队列:将删除缓存的操作发送到消息队列,确保最终执行。
- 监听 binlog:通过 Canal 等工具监听数据库变更,异步同步到缓存。
五、实战案例:构建高可用的用户会话缓存
5.1 需求分析
假设我们需要为电商平台构建用户会话缓存,要求:
- 用户登录后,session 信息存储在 Redis 中,过期时间为 30 分钟。
- 每次请求需要验证 session 是否有效。
- 防止缓存穿透和雪崩。
5.2 设计思路
- 数据结构选择:使用 Hash 存储用户信息(如 userId、nickname、role),key 为 sessionId。
- 过期时间随机化:基础过期时间 30 分钟,增加 0-5 分钟的随机值。
- 布隆过滤器:在 session 验证前,先判断 sessionId 是否可能存在。
- 本地缓存兜底:使用 Caffeine 缓存最近 1000 个活跃 session,过期时间 1 分钟。
5.3 代码实现(伪代码)
java
// 1. 初始化布隆过滤器
BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.stringFunnel(), 1000000, 0.01);
// 2. 验证 session
public UserSession getSession(String sessionId) {
// 布隆过滤器快速过滤
if (!bloomFilter.mightContain(sessionId)) {
return null;
}
// 本地缓存
UserSession localSession = localCache.getIfPresent(sessionId);
if (localSession != null) {
return localSession;
}
// Redis 缓存
String key = "session:" + sessionId;
Map<String, String> map = redis.hgetAll(key);
if (map.isEmpty()) {
return null;
}
UserSession session = convertToSession(map);
// 写入本地缓存
localCache.put(sessionId, session);
return session;
}
// 3. 创建 session
public void createSession(String sessionId, UserSession session) {
String key = "session:" + sessionId;
Map<String, String> map = convertToMap(session);
// 随机过期时间
int expire = 1800 + new Random().nextInt(300);
redis.hmset(key, map);
redis.expire(key, expire);
bloomFilter.put(sessionId);
}5.4 性能优化
- Pipeline 批量操作:在批量创建 session 时,使用 Pipeline 减少网络开销。
- 连接池配置:合理配置 Jedis 或 Lettuce 连接池,避免连接泄漏。
- 监控告警:监控缓存命中率、过期 key 数量,及时调整策略。
六、Redis 高级特性与最佳实践
6.1 持久化策略
- RDB:适合数据备份和灾难恢复,但可能丢失最后一次快照后的数据。
- AOF:数据安全性更高,但文件体积大,恢复速度慢。
- 混合持久化:Redis 4.0 引入,结合 RDB 和 AOF 的优点。
6.2 内存淘汰策略
当 Redis 内存达到上限时,需要选择合适的淘汰策略:
- allkeys-lru:淘汰最近最少使用的 key,最常用。
- volatile-lru:仅淘汰设置了过期时间的 key。
- allkeys-random:随机淘汰,适合缓存场景。
6.3 分布式锁
Redis 的分布式锁实现需要解决以下问题:
- 原子性:使用 SET NX EX 命令确保加锁和设置过期时间的原子性。
- 锁续期:使用 Redisson 的 WatchDog 机制自动续期。
- 可重入性:通过 Hash 结构记录线程 ID 和重入次数。
七、总结
Redis 缓存设计并非简单的"存数据、取数据",而是需要综合考虑数据结构选型、一致性保障、高可用架构以及性能优化等多个维度。本文从基础数据结构出发,深入剖析了缓存穿透、击穿、雪崩等经典问题的解决方案,并通过实战案例展示了如何构建一套健壮的缓存体系。
在实际项目中,建议遵循以下原则:
- 缓存是加速手段,不是数据源:永远不要将缓存作为唯一的数据存储。
- 设计时考虑最坏情况:假设缓存会失效、会宕机,提前做好降级方案。
- 监控与告警:没有监控的缓存系统是盲目的,需要实时掌握缓存状态。
最后,Redis 的学习是一个持续的过程,建议读者结合官方文档和实际项目不断实践,才能真正做到"从入门到精通"。