文章目录
CompVis/stable-diffusion
CompVis团队开源的文本生成图像模型Stable Diffusion,目前在GitHub累计获得72984个Star。
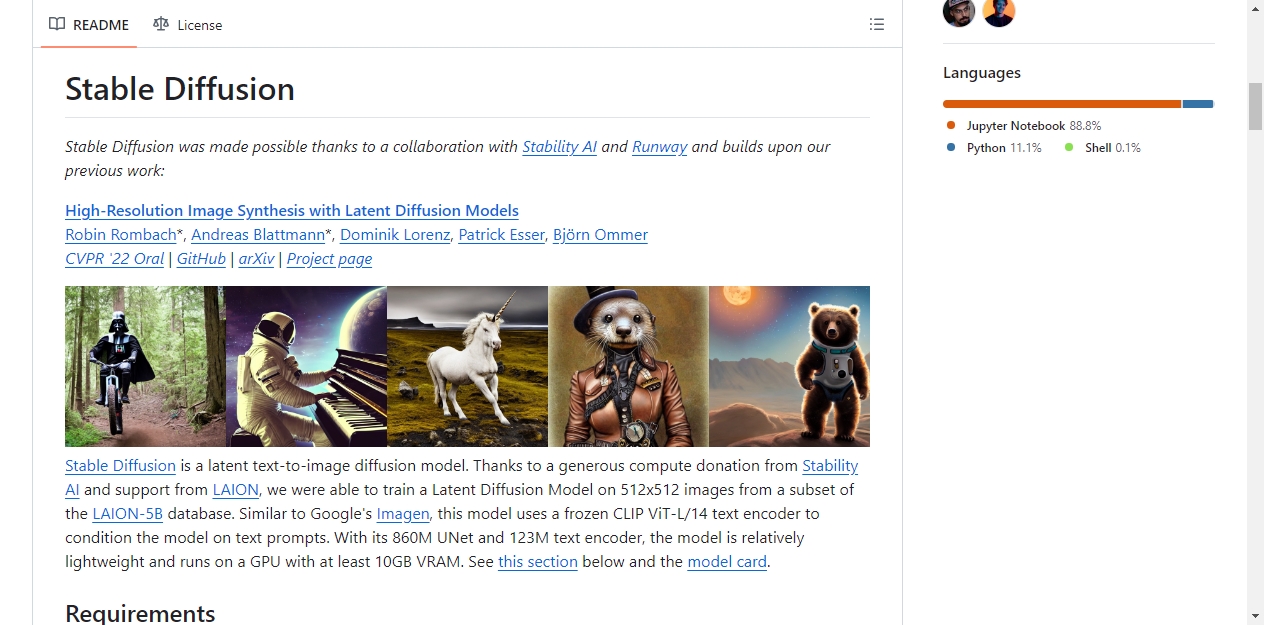
Stable Diffusion由CompVis联合Stability AI、Runway共同开发,基于此前发表的CVPR 2022论文《High-Resolution Image Synthesis with Latent Diffusion Models》构建。模型训练得到Stability AI的算力捐赠和LAION的支持,使用LAION-5B数据集的子集在512x512分辨率图像上完成训练。
该模型属于潜在扩散模型,使用冻结的CLIP ViT-L/14文本编码器处理文本提示。整体参数包含860M的UNet和123M的文本编码器,对硬件要求较低,可在显存不低于10GB的GPU上运行。
Stable Diffusion v1采用下采样因子为8的自编码器架构,先在256x256图像上预训练,再在512x512图像上微调。目前已发布四个版本的权重,分别经过不同规模和筛选标准的数据集训练,可适应不同的生成需求。模型权重采用CreativeML OpenRAIL M许可协议,可通过Hugging Face的CompVis组织页面获取,协议允许商业使用,但建议使用时添加安全机制。
该模型支持三类核心功能:
- 文本生成图像:根据输入的文本提示生成对应内容的512x512分辨率图像,支持调整采样步数、引导系数等参数
- 文本引导图像修改:基于输入图像和文本提示,调整图像内容,支持控制修改幅度
- 图像超分辨率:放大低分辨率图像,提升画面清晰度
用户可通过两种方式使用该模型。第一种是直接运行项目提供的参考脚本,首先创建conda环境:
conda env create -f environment.yaml
conda activate ldm获取权重后,运行文本生成图像脚本:
python scripts/txt2img.py --prompt "a photograph of an astronaut riding a horse" --plms 第二种是通过diffusers库调用,代码示例如下:
py
from torch import autocast
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
use_auth_token=True
).to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
with autocast("cuda"):
image = pipe(prompt)["sample"][0]
image.save("astronaut_rides_horse.png")项目代码基于OpenAI的ADM代码库和lucidrains的扩散模型实现开发,支持自定义扩展。