


专栏:Redis 修行录
个人主页:手握风云
目录
[一、Stream 类型](#一、Stream 类型)
[1.1. 核心概念与数据模型](#1.1. 核心概念与数据模型)
[1.2. 消费者组](#1.2. 消费者组)
[1.3. 核心操作命令](#1.3. 核心操作命令)
[1.4. 典型应用场景](#1.4. 典型应用场景)
[二、Geospatial 类型](#二、Geospatial 类型)
[2.1. 底层原理](#2.1. 底层原理)
[2.2. 基础命令](#2.2. 基础命令)
[2.3. 高级空间搜索](#2.3. 高级空间搜索)
[2.4. 典型应用场景](#2.4. 典型应用场景)
[三、Bitmap 类型](#三、Bitmap 类型)
[3.1. 核心概念](#3.1. 核心概念)
[3.2. 基础命令](#3.2. 基础命令)
[3.3. 高级定位与多字节域操作](#3.3. 高级定位与多字节域操作)
[3.4. 内存压缩价值](#3.4. 内存压缩价值)
[四、Bitfield 类型](#四、Bitfield 类型)
[4.1. 核心概念](#4.1. 核心概念)
[4.2. 基础读写与批量原子操作](#4.2. 基础读写与批量原子操作)
[4.3. 高级算术溢出控制机制](#4.3. 高级算术溢出控制机制)
[4.4. 内存极限压缩](#4.4. 内存极限压缩)
[5.1. 为什么需要渐进式遍历](#5.1. 为什么需要渐进式遍历)
[5.2. 工作原理](#5.2. 工作原理)
[5.3. SCAN 命令](#5.3. SCAN 命令)
一、Stream 类型
Redis 官方文档将 Stream 定义为一种类似于追加日志(Append-only Log)的数据结构,但在此基础上提供了更为强大的功能以克服传统日志的局限性。Stream 在 Redis 5.0 中被引入,它不仅填补了 Redis 传统 Pub/Sub 机制在消息持久化上的空白,还通过引入"消费者组(Consumer Groups)"的概念,使得 Redis 能够作为一个轻量级、高性能且可靠的消息队列中间件来使用。
1.1. 核心概念与数据模型
Redis Stream 基于追加日志(Append-only Log)模型构建,保证了事件严格按发生的物理顺序记录,每次写入的数据都会被追加到 Stream 尾部。Redis 会为每条存入的消息生成一个唯一的 ID(默认格式为"毫秒时间戳-序列号"),借助这些 ID 可以实现 O(1) 时间复杂度的随机访问或基于时间线范围的查询。 此外,Stream 中的每条消息并非简单的纯文本字符串,而是由一系列"字段-值"对构成的键值对结构,这种类似哈希的设计极其适合存储系统操作日志、设备传感器读数或订单流转状态等结构化事件数据。
1.2. 消费者组
消费者组(Consumer Groups)是 Redis Stream 突破传统日志局限性并实现消息队列功能的最核心机制。 它允许多个消费者实例共同监听同一个 Stream,将不同的消息分发给组内的不同工作节点,从而轻松实现微服务架构下的负载均衡与并行处理。为了保证可靠投递,Redis 服务端不仅会记录每个组的"最后投递消息 ID"以防止重复分发,还引入了消息确认(ACK)机制。任何已读取但未 ACK 的消息都会被存入待处理列表(PEL),一旦某个消费者发生宕机崩溃,其他存活的节点可以通过故障转移机制申领这些遗留消息并重新消费,从而提供"至少一次投递(At-least-once delivery)"的企业级可靠性。
1.3. 核心操作命令
Redis 官方文档提供了一整套以字母 X 开头的专属命令体系用于 Stream 的全生命周期管理。在写入与维护层面,开发者通过 XADD 追加消息,并常结合 MAXLEN 参数对超长日志进行自动修剪以保护内存,利用 XLEN 和 XTRIM 来查询长度或手动裁剪过期数据。在数据读取方面,除了支持范围检索的 XRANGE 和 XREVRANGE,还提供支持阻塞监听新数据的 XREAD 命令。而针对消费者组的高级控制,则依赖于 XGROUP 进行组的创建与销毁、XREADGROUP 以组身份消费消息、XACK 提交处理确认,以及利用 XPENDING 实时监控故障恢复过程中滞留的未处理消息。
1.4. 典型应用场景
得益于上述的结构化特性、低延迟表现以及消费者组机制,Stream 数据结构在诸多现代系统架构场景中表现尤为出色。它不仅是事件溯源(Event Sourcing)模式的理想载体,能够精准记录用户的点击流或业务的状态变更流水;还能作为轻量级的消息代理(Message Broker),在替换复杂且笨重的 Apache Kafka 的同时,为微服务间通信提供亚毫秒级的延迟保障。此外,Stream 同样被广泛应用于海量物联网(IoT)传感器时间序列数据的实时监控收集,以及在大语言模型(LLM)流式输出等需要将后端生成的序列数据实时、可靠地分发给前端客户端的高吞吐场景中。
二、Geospatial 类型
Redis 官方文档将 Geospatial(地理空间) 索引定义为一种专门用于存储和查询地理坐标(经度和纬度)的功能。虽然它在逻辑上表现为一种独立的地理空间能力,但官方文档特别指出,Geospatial 底层实际上是基于 Redis 的有序集合实现的。
2.1. 底层原理
Redis 官方文档指出,虽然地理空间(Geospatial)功能在逻辑上表现为独立的坐标处理能力,但其底层实际上是基于有序集合(Sorted Set)实现的。为了将二维的经纬度坐标映射到一维的数据结构中,Redis 巧妙地采用了 Geohash 算法,将地球表面划分为网格,并把默认的 WGS84 坐标系下的有效经纬度(经度 -180 到 180,纬度 -85.05112878 到 85.05112878)编码为一个 52 位的整数值,作为 Sorted Set 中的分数(score)进行存储。得益于这种高精度的编码机制,Redis 空间索引的距离计算误差通常不到一米,足以满足绝大多数对定位精度要求严格的商业应用场景。
2.2. 基础命令
在基础的数据录入与管理层面,Redis 提供了一套专门以 GEO 开头的精简指令集。开发者可以通过 GEOADD 命令将包含具体坐标和实体名称的成员数据写入特定的键中,这里需要特别强调的是,官方严格规定了参数传入的顺序必须是"先经度(longitude)后纬度(latitude)"。数据录入后,利用 GEOPOS 能够随时回查实体的精确坐标,而 GEODIST 则可以直接计算出两个已知实体间的球面物理距离,并支持米、千米、英里等多种常见单位的直接输出。此外,对于需要与前端地图框架或外部系统进行无缝集成的场景,还可以使用 GEOHASH 命令直接获取标准的 Geohash 字符串。
2.3. 高级空间搜索
随着 Redis 6.2 版本的更新,官方文档强烈建议开发者摒弃旧版的范围查询命令,转而使用更为强大和统一的 GEOSEARCH 与 GEOSEARCHSTORE 指令来进行高级空间搜索。新的搜索机制支持高度灵活的中心点设定,既可以基于已存在的成员位置,也能直接输入全新的经纬度作为辐射中心。在此基础上,系统不仅支持经典的 BYRADIUS 圆形辐射搜索来查找指定半径内的数据,还引入了极其契合现代移动端地图应用视角的 BYBOX 矩形边界框搜索。为了保障系统性能并提升用户体验,这些搜索结果不仅能按距离远近自动正序或逆序排列,还能通过设定 COUNT 参数严格限制返回条目数,而 GEOSEARCHSTORE 更是允许将计算结果直接缓存至全新的有序集合中,非常适合用于离线计算或结果缓存。
2.4. 典型应用场景
得益于内存级别的高极速响应和专门优化的空间查询指令,Redis Geospatial 已成为现代基于位置服务(LBS)领域不可或缺的核心组件。无论是社交软件中经典的"附近的人"功能,还是本地生活平台里检索周边商铺的推荐列表,都可以借助 GEOSEARCH 在瞬间完成海量数据的距离筛选与排序输出。在并发要求极其苛刻的网约车派单或外卖物流调度系统中,底层高效的 ZSET 结构使得系统能够毫不费力地承载高频的位置轨迹更新,并实时圈选出目标区域内的可用空闲运力进行接单广播。此外,结合矩形边界框搜索,它还能轻松实现地理围栏功能,精准监控物流包裹或运营车辆是否进入或驶出了特定的服务网格边界。
三、Bitmap 类型
3.1. 核心概念
根据 Redis 官方文档的明确定义,位图(Bitmaps)实际上并不是一种全新的、独立的数据结构,而是基于 Redis 原生的字符串(String)类型提供的一套位级(bit-level)操作机制。由于 Redis 的字符串是二进制安全的(binary-safe),并且其最大长度被限制在 512 MB,这意味着一个单独的 String 键最多可以容纳 2^32(约 42.9 亿)个独立的比特位。通过将普通的字符串在逻辑上视为一个由 0 和 1 构成的庞大比特数组,开发者能够以极限的细粒度对底层数据进行直接控制。
3.2. 基础命令
针对这种二进制数组,Redis 提供了一系列时间复杂度极低的基础读写与统计指令。最基础的操作是 SETBIT 和 GETBIT,它们能在 O(1) 的时间复杂度内,将指定偏移量上的比特位修改为 0 或 1,或者快速读取该位置的当前状态。在宏观统计层面,官方文档特别强调了 BITCOUNT 命令,它能够极速统计出整个位图或指定字节范围内值为 1 的比特总数。此外,强大的 BITOP 命令允许直接在 Redis 服务端对多个不同键的位图执行按位与、按位或、按位异或及按位非运算,将复杂的交集、并集计算下推至数据层完成。
3.3. 高级定位与多字节域操作
为了满足更复杂的业务需求,Redis 还为 Bitmap 补充了高级的定位与多字节域操作功能。通过 BITPOS 指令,开发者可以快速扫描整个数组,定位到第一个值为 0 或 1 的比特位的精确偏移量。而官方文档中极其推崇的 BITFIELD 指令,则进一步打破了单比特的限制,它允许将整个 Bitmap 视作一个包含多个任意位宽整数的连续内存块(例如将其划分为多个连续的 5 位无符号整数阵列)。借助 BITFIELD,业务可以直接对这些自定义宽度的数值区域执行批量读取、修改或原子自增操作,同时还支持自定义处理算术溢出(Overflow)的控制策略。
3.4. 内存压缩价值
Bitmap 在企业级系统中最核心的价值在于其极其惊人的内存压缩率与高并发效率。正如官方文档中的经典案例所示,如果系统需要记录高达 1 亿名用户的每日在线状态,使用 Bitmap 来存储每个用户的一个布尔状态(在线为 1,离线为 0),总共仅仅只需要消耗约 12 MB 的内存资源。因此,它在现代架构中成为了处理海量布尔型数据的首选方案,被极其广泛地应用于日活跃用户(DAU)的超高速统计、用户连续打卡与签到记录的存储、海量用户画像标签体系的布尔特征过滤,以及通过 BITOP 的 AND/OR 运算来极速得出多日用户留存率等大数据实时分析场景。
四、Bitfield 类型
4.1. 核心概念
根据 Redis 官方文档的定义,BITFIELD 并不是一种全新的独立数据结构,而是建立在 Redis 原生字符串(String)类型之上的一项极其强大的高级多字节位操作功能。如果说原生的 Bitmap 只能处理以 1 位(bit)为单比特的布尔状态(0 或 1),那么 BITFIELD 则彻底打破了这一限制。它允许开发者将一个普通的 Redis 字符串在逻辑上视作一个由多个任意位宽(最高可支持 64 位整数)的连续内存块。这意味着你可以精准地在指定的比特偏移量上,按需划分出不同长度的数字位段(例如 5 位、18 位或 50 位),并将这些连续的比特位作为标准的整数进行直接读写。
4.2. 基础读写与批量原子操作
在操作层面,BITFIELD 提供了一组高度聚合的子命令集,主要包括 GET、SET 和 INCRBY。开发者在操作时需要明确指定数据的编码类型(如表示有符号整数的 i8 或无符号整数的 u16,其中有符号最大支持 64 位,无符号最大支持 63 位)以及目标偏移量。更强大的是,官方文档特别强调 BITFIELD 具有批量执行的特性:在单条 BITFIELD 命令中,你可以自由组合调用多个子命令,对同一个键的不同偏移量区域进行混合操作(例如提取位段 A,修改位段 B,自增位段 C)。Redis 会保证这一系列动作在底层严格以原子(Atomic)的方式执行,彻底避免了高并发场景下的竞态条件问题。
4.3. 高级算术溢出控制机制
除了打破单比特位宽限制,BITFIELD 最具特色的工程设计在于其提供的底层算术溢出(Overflow)控制策略。当对特定位宽的字段执行 INCRBY 累加操作并导致数值超出该范围所能表示的极限时,开发者可以通过 OVERFLOW 子命令动态指定三种不同的应对行为:默认的 WRAP 模式会像 C 语言中的无符号整数一样发生循环折返(例如 8 位无符号整数 255 加 1 后变为 0);SAT(Saturate 饱和)模式会将数值死死锁定在极值边界(即保持在最大或最小值不再变化),这极其适合用于达到上限就不再增加的累计积分系统;而 FAIL 模式则会直接拒绝执行导致溢出的操作并返回 NULL,为业务代码提供严格的数据安全校验。
4.4. 内存极限压缩
在实际的企业级高并发架构中,BITFIELD 的核心价值在于将多维度的属性进行极限的内存压缩与"结构体打包"存储。例如,在大型网络游戏中,通常需要频繁读写玩家的高频状态,你可以利用 BITFIELD 将玩家的当前等级(占用 7 个 bit)、VIP 等级(占用 3 个 bit)、金币数量(占用 32 个 bit)无缝拼接,紧凑地存放在仅仅几个字节的单个字符串中。这不仅极大减少了使用 Hash 结构或多个独立 String 键带来的内部元数据开销,还能通过一条指令完成所有属性的原子更新。因此,它被极其广泛地应用于海量实体的复杂状态追踪、密集型实时计数器阵列以及对内存成本和网络延迟要求严苛的超大规模系统中。
五、渐进式遍历
在 Redis 中,渐进式遍历主要是通过 SCAN 系列命令来实现的。它的核心目的是为了在遍历大规模数据时,避免阻塞 Redis 服务器。
5.1. 为什么需要渐进式遍历
如果直接使用 KEYS 命令获取所有键,或者使用 SMEMBERS 获取一个巨大集合中的所有元素,可能会导致单线程的 Redis 服务器被阻塞很长时间(甚至几秒钟),从而无法处理其他客户端的请求。 为了解决这个问题,Redis 提供了渐进式遍历。每次执行遍历命令的时间复杂度仅为 O(1),它通过分批次、多次执行的方式来逐步完成对全部数据的遍历。
5.2. 工作原理
渐进式遍历是一个基于游标(cursor)的迭代器:首次调用时,将游标设置为 0。每次命令执行后,Redis 会返回两个值------一个是新的游标,另一个是本批次获取到的元素数组。你需要将这个新游标作为下一次调用的参数传给服务器。当服务器返回的新游标重新为 0 时,意味着整个集合已经被完整探索完毕,遍历结束(这被称为一次完整遍历,full iteration)。
5.3. SCAN 命令
bash
SCAN cursor [MATCH pattern] [COUNT count] [TYPE type]COUNT 选项:用于提示 Redis 每次调用大概需要扫描多少数据,默认值为 10。需要注意的是,这仅仅是一个"提示(hint)",并不意味着每次都会严格返回指定数量的元素,甚至有时可能会返回 0 个元素,只要游标不为 0 就代表遍历未结束。每次调用时也可以动态改变 COUNT 的值。
MATCH 选项:支持 glob 风格的模式匹配,只返回匹配指定模式的元素。注意: 模式匹配是在元素从集合中取出后才进行的,这意味着如果符合条件的元素很少,可能会连续几次调用都返回空数据和非零游标。
bash
SCAN 0
SCAN 0 count 3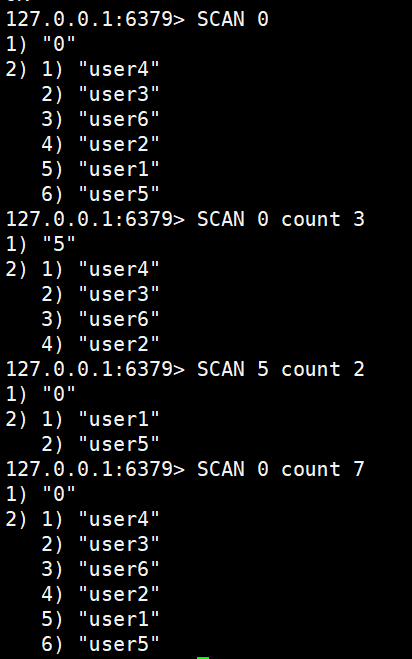
这里的渐进式遍历,在遍历过程中,不会在服务器这边存储任何的状态信息。此处的遍历是随时可以终止的,并且不会对服务器产生任何的副作用。
除了针对全局键的 scan 之外,Redis 还为特定的数据结构提供了相应的渐进式遍历命令:面向哈希的 hscan、面向集合的 sscan,以及面向有序集合的 zscan,它们的用法与 scan 基本相似。
虽然渐进式遍历有效地解决了阻塞问题,但由于遍历是分步进行的,如果在遍历期间数据库的键发生了变化(增加、修改或删除),可能会导致遍历结果中出现键的重复或遗漏 。这是在实际开发中必须考虑和应对的风险 。