这几年,大家已经很熟悉"文生图":输入一句话,AI 就能生成一张图片。但在医学影像里,事情远没有这么简单。普通图片大多是二维的,比如一张猫、一张风景照;而 CT、MRI 往往是三维体数据。它不是一张图,而是一叠图,像一本由几百页切片组成的"人体影像书"。模型不仅要生成每一页,还要保证前后切片连贯、器官结构合理、细节不能乱。这篇论文 3D MedDiffusion: A 3D Medical Latent Diffusion Model for Controllable and High-quality Medical Image Generation ,就是在解决这个问题:能不能训练一个 AI,生成高质量、可控的 3D 医学影像?
论文提出的答案叫 3D MedDiffusion。它可以生成 CT 和 MRI,覆盖头颈、胸腹、下肢、脑、膝关节等多个部位,并能用于稀疏角 CT 重建、快速 MRI 重建,以及分割和分类任务的数据增强。论文摘要中明确写到,该模型能生成最高 512×512×512 的高分辨率 3D 医学图像,并在多个下游任务中展示了泛化能力。
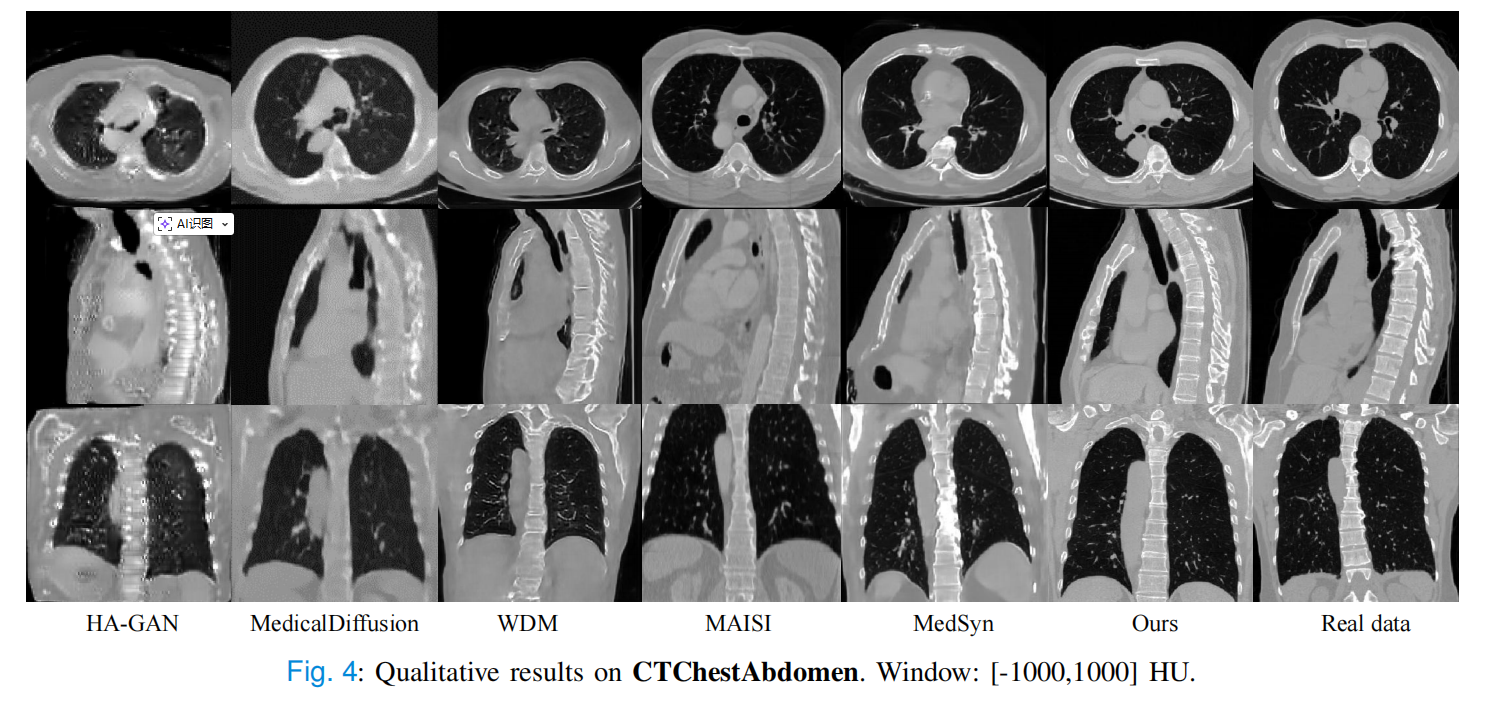
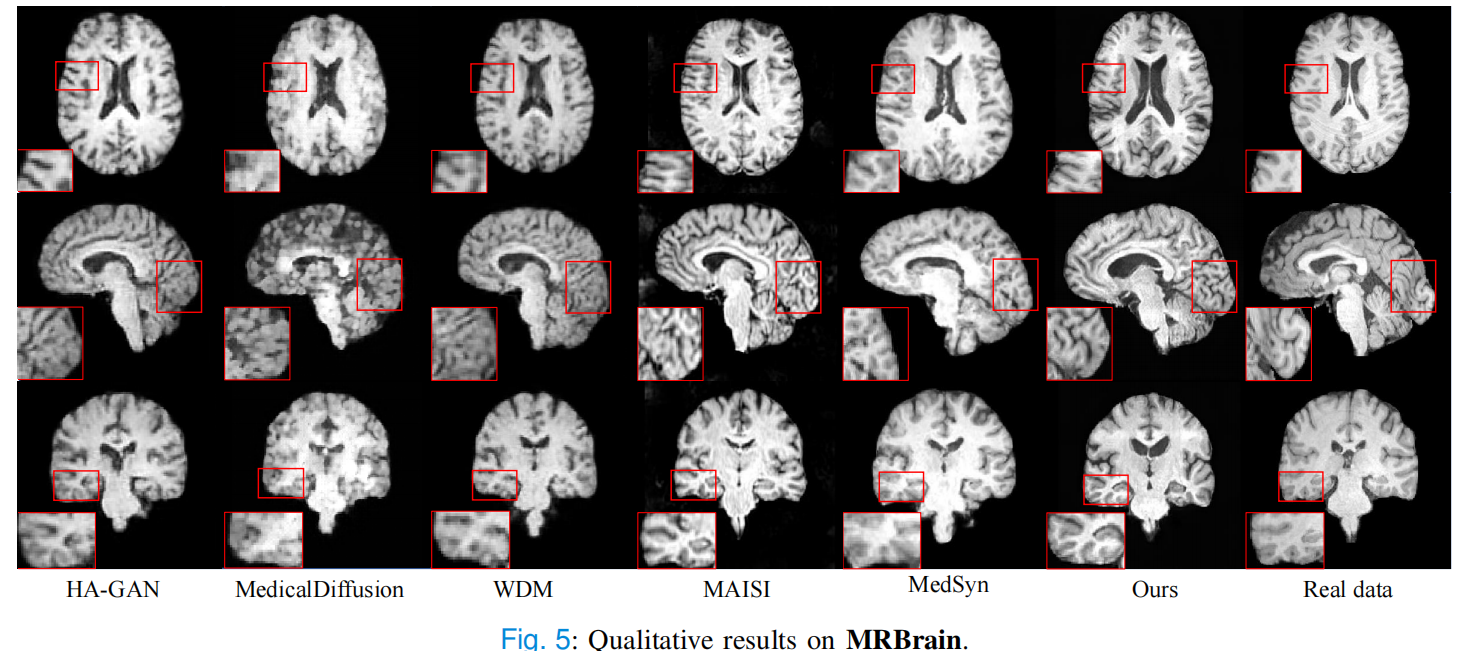
论文Fig4展示不同方法生成的胸腹部 CT 对比,3D MedDiffusion 在细节和结构连续性上更接近真实数据。
不同方法生成的胸腹部 CT 对比,3D MedDiffusion 在细节和结构连续性上更接近真实数据。
一、为什么医学影像生成这么难?
生成医学影像,难点主要有三个。
第一,医学影像是 3D 的,数据量巨大。
普通图片是一个平面,医学 CT 是一个体。模型要理解的不只是"这一张切片长什么样",还要理解上下左右前后的空间关系。比如脊柱要连续,肺部不能断裂,器官位置不能乱跑。
第二,医学影像对细节非常敏感。
自然图像里,猫毛少几根问题不大;医学图像里,一个小病灶、一个边界、一段血管,都可能影响诊断和模型训练。
第三,医学数据很难获得。
真实医学数据涉及隐私,标注也非常贵。一个高质量 3D 分割标注,往往需要专业医生花大量时间完成。正因为如此,合成医学影像有潜在价值:它可以扩充训练数据,缓解小样本问题。
3D MedDiffusion 的核心目标,就是在这些限制下,生成既清晰、又连贯、还能用于下游任务的 3D 医学图像。
二、它的核心思路:先压缩,再生成
如果直接在原始 3D CT 上做扩散生成,计算量会非常恐怖。
所以 3D MedDiffusion 采用了和 Stable Diffusion 类似的思路:不要直接在原图空间生成,而是先把图像压缩到 latent space,再在压缩空间里生成。
可以把这个过程理解成:
原始 CT / MRI
↓
压缩成更小的"医学影像编码"
↓
AI 在编码空间里生成
↓
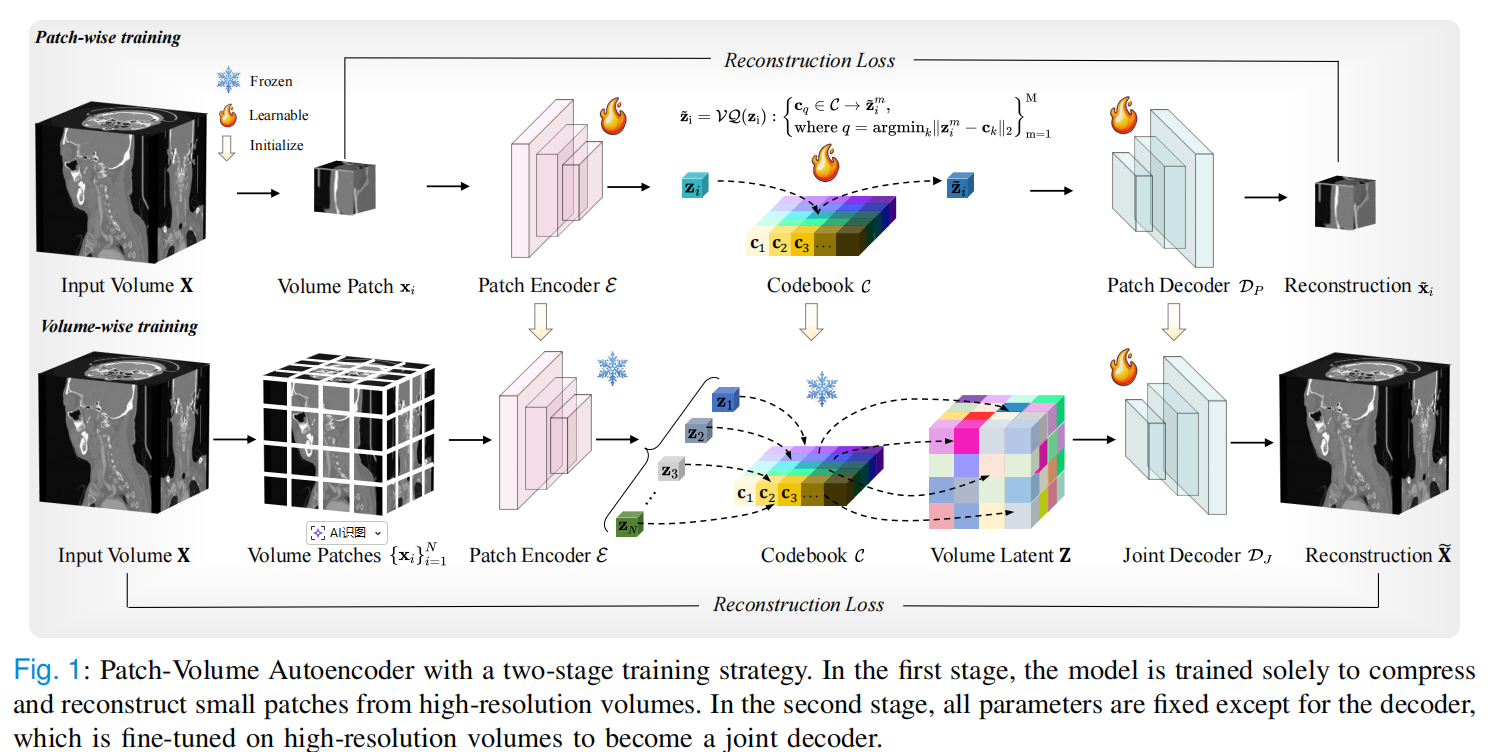
再解码回完整 3D 医学图像这就像我们不直接搬一整栋楼,而是先把楼的设计图压缩成结构图,再根据结构图重建。论文里这个压缩模块叫 Patch-Volume Autoencoder 。它的特殊之处在于:编码时切成小块,解码时恢复成整体。
为什么要这么做?
因为整张 3D 医学影像太大,直接编码非常吃显存;但如果只切小块处理,又容易在拼接处出现边界伪影。于是作者设计了两阶段训练:第一阶段让模型学会压缩和重建小块;第二阶段冻结大部分模块,只训练一个整体解码器,让它学会把小块编码自然地拼成完整影像。论文 Fig. 1 就展示了这个 patch-wise training 到 volume-wise training 的过程。3D MedDiffusion 先把大体积医学影像切成小块压缩,再用整体解码器恢复完整图像,从而兼顾显存效率和整体连贯性。
三、真正的关键:既要看局部,也要看全局
压缩只是第一步。接下来,模型要在 latent space 里生成新影像。传统 diffusion model 常用 U-Net 来预测噪声、逐步去噪。但作者认为,3D 医学影像不能只靠一个普通 U-Net。因为医学图像同时需要两种能力:
一是看清局部细节,比如骨骼边缘、脑沟、器官边界;
二是维持全局结构,比如身体区域、器官位置、上下切片连续性。
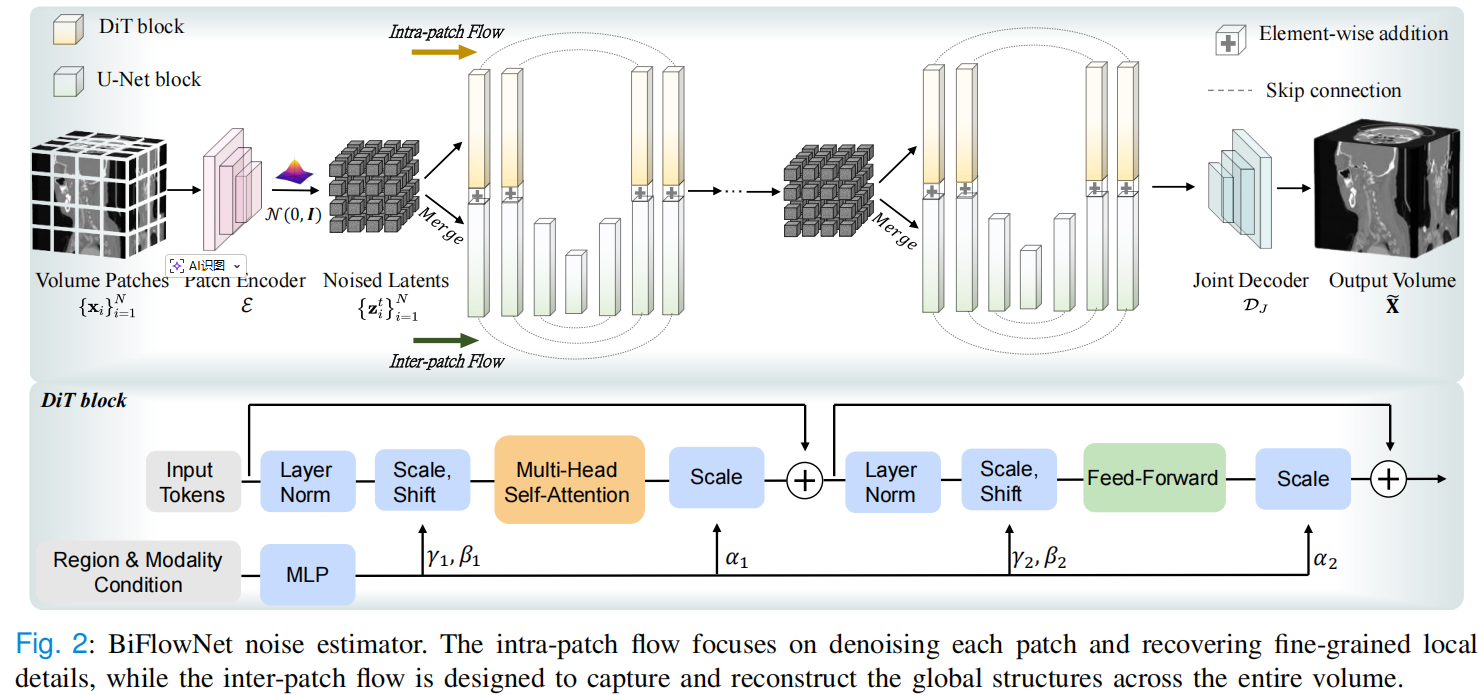
于是论文设计了一个新的噪声估计器:BiFlowNet 。这个名字可以理解成"双流网络"。第一条流叫 intra-patch flow ,主要负责小块内部的细节,用的是 DiT,也就是 Diffusion Transformer。第二条流叫 inter-patch flow,主要负责大范围结构,用的是 3D U-Net。 最后,两条流的信息融合起来,一起完成去噪生成。
说得通俗一点:DiT 像"显微镜",负责看局部细节; U-Net 像"全景地图",负责看整体结构;BiFlowNet 就是把显微镜和全景地图结合起来。论文 Fig. 2 展示了这个双流结构:intra-patch flow 负责局部细节,inter-patch flow 负责整体体积结构。
四、它不只是"会生成",还可以接任务
医学 AI 里,生成图像本身不是终点。更重要的是:生成出来的图像能不能帮助真实任务?
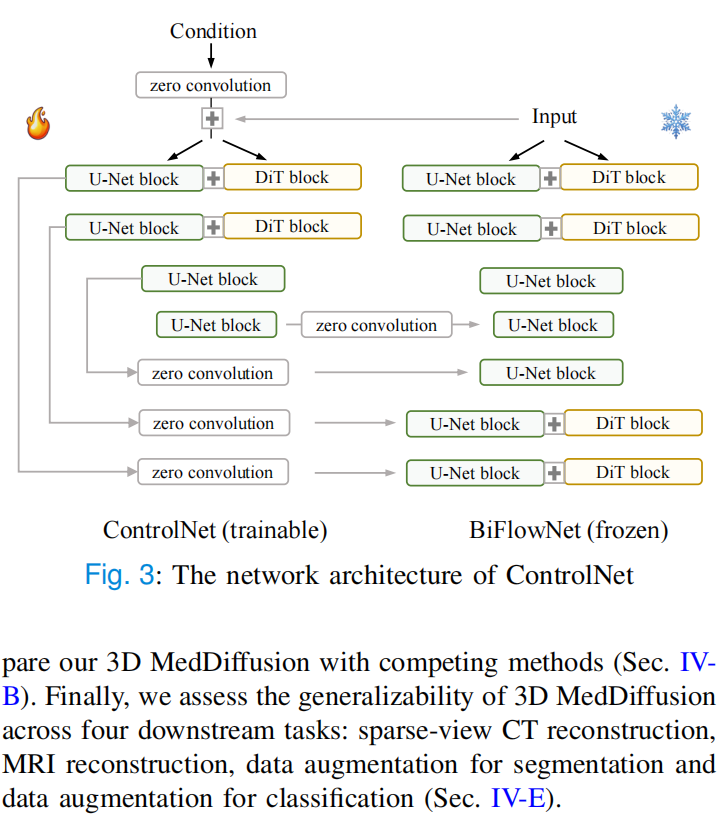
3D MedDiffusion 接入了 ControlNet。熟悉图像生成的读者可能知道,ControlNet 常用于让扩散模型听从额外条件,比如边缘图、姿态图、深度图。这里的思路类似:预训练好的 3D MedDiffusion 作为基础模型,任务来了以后,再用 ControlNet 加入特定条件。
论文把它用于四类下游任务:
- 稀疏角 CT 重建;
- 快速 MRI 重建;
- 分割任务的数据增强;
- 分类任务的数据增强。
论文 Fig. 3 展示了 ControlNet 和冻结的 BiFlowNet 如何连接:原来的生成模型被冻结,另一个可训练分支学习任务条件,再通过 zero convolution 把条件信息注入模型。ControlNet 让预训练好的 3D MedDiffusion 可以适配不同医学任务,而不是每个任务都从零训练一个大模型。
五、实验结果:它比哪些方法更好?
论文和 HA-GAN、MedicalDiffusion、WDM、MAISI、MedSyn 等方法做了比较。
在 CTChestAbdomen 数据集上,3D MedDiffusion 的 Ours(CT) 版本取得了最低 FID 和 MMD。FID 可以粗略理解为"生成图像分布和真实图像分布的距离",越低越好;MMD 也是分布差异指标,越低越好。论文 Table III 中,Ours(CT) 的 FID 为 0.0055,低于 MAISI 的 0.0135 和 MedSyn 的 0.0174。Wang 等 - 2025 - 3D MedDiffusion...
在 MRBrain 数据集上,Ours(MR) 同样取得最优指标。Table IV 显示,Ours(MR) 的 FID 为 0.0044,低于 WDM、MAISI 和 MedSyn 等方法。Wang 等 - 2025 - 3D MedDiffusion...
更直观的是论文 Fig. 4 和 Fig. 5。图中能看到,部分方法生成结果会模糊、噪声较重,而 3D MedDiffusion 在 CT 的椎骨细节、MRI 的脑表面边缘上更清晰。
六、最有意思的部分:生成模型还能帮重建 CT 和 MRI
3D MedDiffusion 不只是生成"看起来像"的图像,还能参与医学图像重建。比如在稀疏角 CT 重建中,扫描角度减少后,图像会有伪影和模糊。3D MedDiffusion 用预训练生成模型作为先验,再通过 ControlNet 接收低质量重建结果,输出更接近完整扫描的 CT。
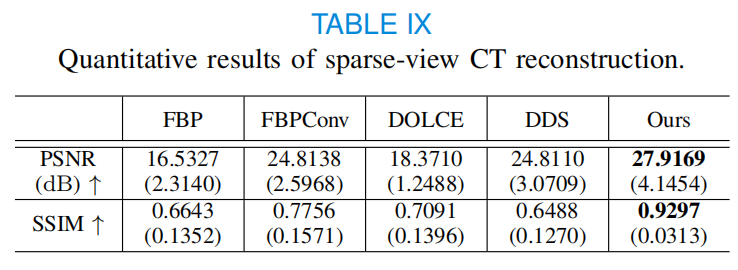
论文在 KiTS19 肾脏 CT 数据集上做实验。Table IX 显示,3D MedDiffusion 在 sparse-view CT reconstruction 中取得最高 PSNR 和 SSIM,其中 PSNR 达到 27.9169 dB,SSIM 达到 0.9297,优于 FBPConv、DOLCE、DDS 等方法。Wang 等 - 2025 - 3D MedDiffusion...
MRI 重建也类似。论文在 MRKnee 数据集上做 8× 欠采样重建,Table X 显示,3D MedDiffusion 的 PSNR 为 34.5374 dB,SSIM 为 0.9130,也高于 zero-filling、U-Net 和 DDS。
七、它能不能真的帮助训练医学 AI?
论文还做了数据增强实验。
在分割任务中,作者使用 KiTS19 数据集,目标是分割肾脏和肿瘤。他们比较了纯真实数据、纯合成数据、真实+合成数据等不同训练设置。结果显示,加入合成数据后,分割性能进一步提升;当使用 100% 真实数据再加入 100% 合成数据时,肿瘤 Dice 从 84.79% 提升到 86.32%,肾脏 Dice 从 95.01% 提升到 96.36%。
在分类任务中,论文使用 MosMedData 做 COVID-19 相关影像分类。加入合成图像后,分类准确率从 75.00% 提升到 79.17%,F1 从 0.7368 提升到 0.7863。
这说明合成医学影像不是只能"展示",它确实可能帮助下游模型训练。不过也要注意:这里的合成数据增强,很多时候仍然依赖已有标签或已有 mask。也就是说,它更像是"在已有标注基础上扩展图像外观多样性",还不能完全替代医生标注。
八、这篇论文最值得肯定的地方
3D MedDiffusion 最大的价值,不是简单地说"我也能生成 CT/MRI"。它真正有意思的地方在于,作者认真处理了 3D 医学影像生成里的两个矛盾。
第一个矛盾是:图像太大,模型跑不动。
所以他们设计 Patch-Volume Autoencoder,用小块编码降低显存压力,再用整体解码减少边界伪影。
第二个矛盾是:局部细节和全局结构都重要。
所以他们设计 BiFlowNet,用 DiT 看局部,用 U-Net 看整体。
这两个设计结合起来,使 3D MedDiffusion 不只是一个"3D 版扩散模型",而是一个更贴近医学影像特点的生成框架。
九、但它也不是万能答案
这篇论文很强,但不能被过度解读。
首先,FID、MMD、SSIM 这类指标不能完全代表临床真实性。 医学图像是否可信,不只看纹理像不像,还要看器官结构、病灶形态、HU 分布、解剖拓扑、医生诊断一致性。
其次,它的可控性仍有限。 论文强调 controllable generation,但从开源仓库的训练和推理方式看,目前更主要是类别、模态、区域和分辨率层面的控制,还不是那种"任意器官、任意病灶、任意扫描参数都能精确控制"的临床级生成系统。
再次,合成数据不能直接等于真实数据。 合成图像可以帮助训练模型,但如果生成模型本身有偏差,合成数据也会把偏差带到下游任务里。
最后,计算资源门槛依然很高。 论文中比较实验使用 A100 80GB GPU,开源 README 也提示推理至少需要 40GB 显存。 这说明它更适合科研机构和有算力条件的团队,而不是普通用户随手可用的工具
结语:医学影像生成正在进入 3D 时代
3D MedDiffusion 给我们的启发是:医学影像生成不能照搬自然图像生成。
医学影像有自己的规则:
-
它是三维的,结构要连续;
-
它是临床相关的,细节不能乱;
-
它的数据昂贵,生成结果最好能服务真实任务。
这篇论文的价值,正在于它没有只追求"生成一张好看的图",而是把高质量 3D 生成、可控适配、图像重建和数据增强放进了一个统一框架里。当然,它距离真正临床可用还有距离。未来还需要更强的临床验证、更细粒度的条件控制、更低的算力门槛,以及更严格的隐私与安全评估。
但至少可以确定一点: 医学影像 AI 的生成模型,正在从 2D 图片生成,走向真正的 3D 体数据生成。3D MedDiffusion,就是这个方向里非常值得关注的一步。