很多人一听"神经网络训练",脑子里马上冒出一堆词:损失函数、反向传播、梯度下降、过拟合、早停法、GPU训练、参数量......
但真到了面试现场,最容易翻车的,不是不会背名词,而是讲不清它们之间到底是什么关系。
这篇文章不堆高深公式,而是把神经网络训练拆成一条完整链路:
数据进来 -> 前向传播 -> 算损失 -> 反向传播 -> 优化器更新参数 -> 不断循环,直到模型在验证集上表现最好。
只要这条主线讲清楚,很多面试题其实都能顺着回答出来。
|----------------------------------------------------------------------|
| 先记一句最核心的话:神经网络训练,本质上就是"用损失函数衡量预测错多少,再通过反向传播和梯度下降去改参数",直到模型在验证集上表现最好。 |
1. 神经网络训练,到底在训练什么?
1.1 训练不是"记答案",而是不断修正参数
很多人第一次接触神经网络,会误以为训练就是把数据塞进去,让模型把答案背下来。这个理解只对了一半。真正被训练的,不是样本本身,而是网络内部一层层的参数,也就是权重和偏置。
每当一个样本进入网络,模型都会先给出一个预测。这个预测通常不会一开始就很准,于是我们就用损失函数给它打分:错得多,就扣分更多。然后系统根据这个扣分结果,去微调各层参数,让下一次预测更接近真实答案。
1.2 一条线看懂训练主流程
从业务视角看,训练流程可以概括为五步:准备数据、前向传播、计算损失、反向传播、优化更新。这个循环会重复很多轮,直到验证集效果不再提升,或者达到预设训练轮次。
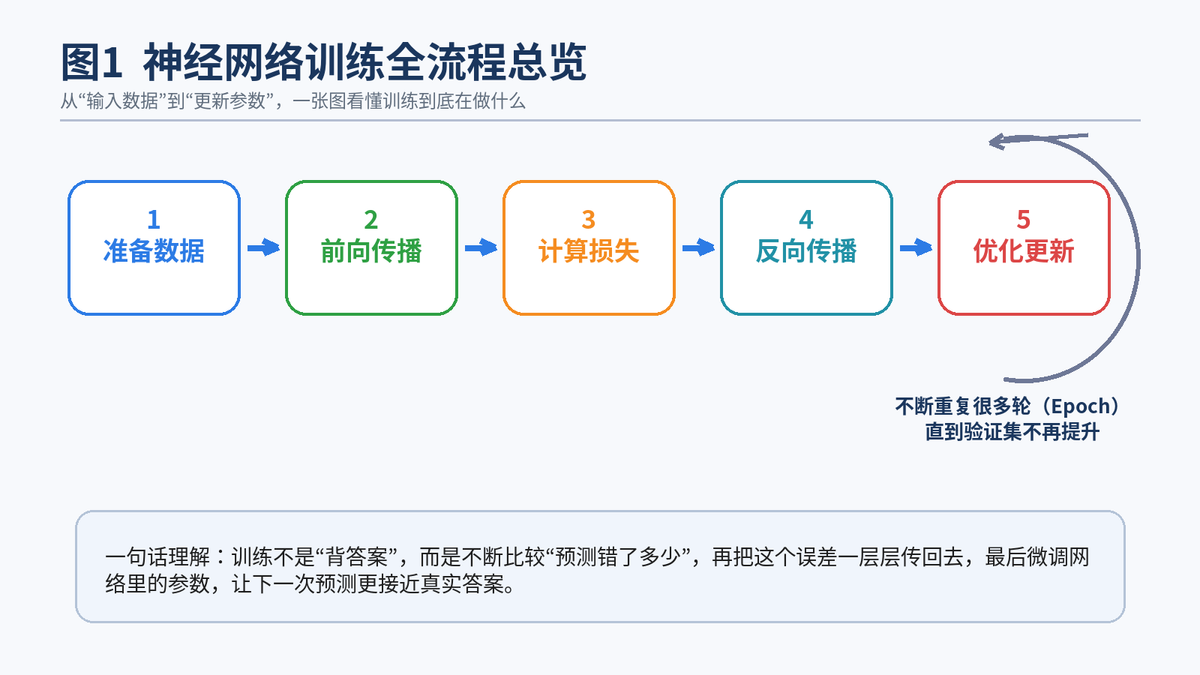
2. 损失函数的作用是什么?分类和回归常用哪些?
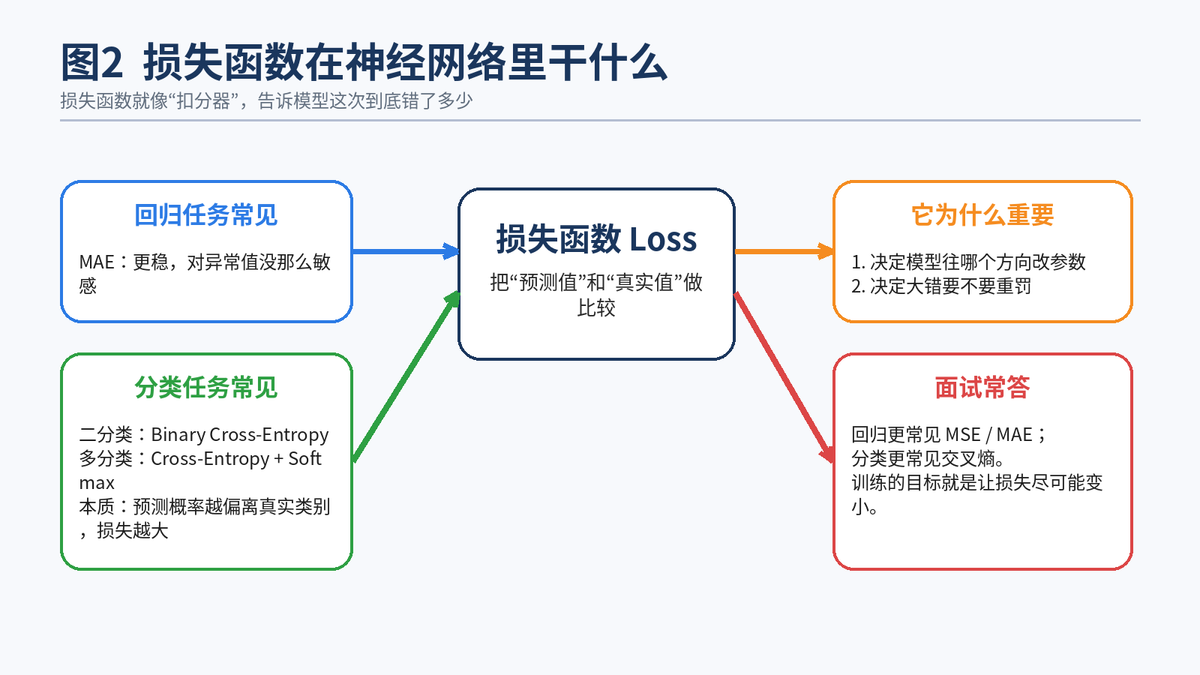
2.1 损失函数就是模型的"扣分器"
损失函数的作用非常直接:把"模型预测"和"真实答案"之间的差距,压缩成一个可以优化的数字。这个数字越大,说明模型错得越离谱;这个数字越小,说明模型离正确答案越近。
训练的目标,不是让某一层神经元看起来很高级,而是让整体损失尽可能降低。谁能让损失更快、更稳地降下去,谁就更适合当前任务。
2.2 回归任务里常见的损失函数
如果任务是预测一个连续值,比如房价、销量、温度,那通常是回归问题。回归里常见的损失包括 MAE 和 MSE。MAE 更稳健,对异常值没那么敏感;MSE 会把"大错"放大,所以训练中很常见。Google 的机器学习课程也把 MAE 和 MSE列为常见损失,并指出 MSE 会对异常值更敏感。
2.3 分类任务里常见的损失函数
如果任务是判断类别,比如垃圾邮件识别、图片分类、用户是否流失,那通常是分类问题。分类神经网络更常见的是交叉熵损失。scikit-learn 的 MLPClassifier 文档也明确写到,它优化的是 log-loss,也就是交叉熵损失。
为什么分类里更喜欢交叉熵?因为分类模型往往输出的是概率。交叉熵会直接惩罚"把正确类别概率压得太低"的情况,所以特别适合概率预测。
3. 反向传播算法的原理是什么?
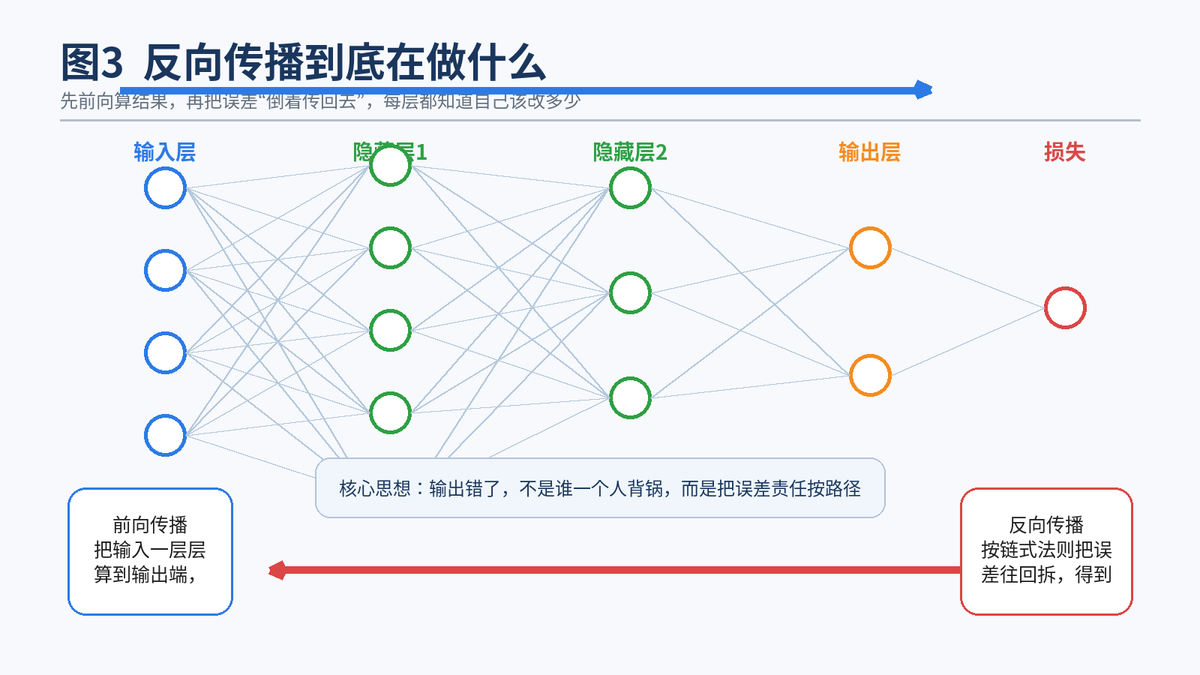
3.1 前向传播先算结果,反向传播再分责任
神经网络训练可以看成两个方向的过程。第一步叫前向传播:输入从第一层流到最后一层,得到一个预测值。第二步叫反向传播:根据损失函数的结果,把误差一层层往回传,计算每个参数对最终错误到底"负了多少责任"。
Google for Developers 把 backpropagation 描述为多层神经网络最常见的训练算法,它让梯度下降能够在多层网络中真正落地。
3.2 为什么反向传播很重要
如果没有反向传播,我们当然也可以知道模型错了,但不知道该改哪里、该改多少。反向传播的价值就在于:它能高效算出每个参数的梯度。梯度可以理解为"如果把这个参数朝某个方向动一点,损失会变大还是变小,变化有多快"。
正因为有了这一步,优化器才知道该把哪些权重调大、哪些权重调小。
3.3 反向传播并不是单独工作
要注意,反向传播本身不是优化器。它更像一个"梯度计算引擎"。真正拿着梯度去更新参数的,是 SGD、Momentum、RMSProp、Adam 这些优化方法。也就是说:反向传播负责算方向,优化器负责走步骤。
4. 神经网络为什么常用梯度下降,而不是精确解、牛顿法或共轭梯度?
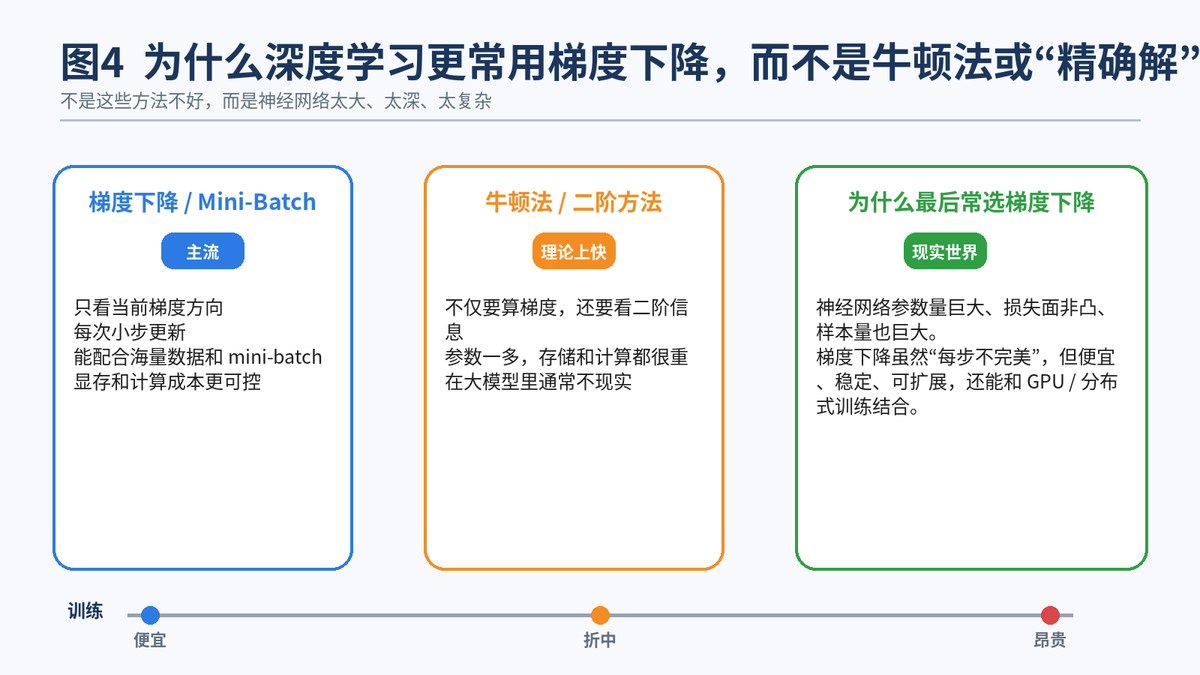
4.1 先说结论:不是别的方法没用,而是神经网络太大了
在线性回归这种相对简单的模型里,我们有时能写出解析解;在一些较小的神经网络里,也可能尝试 L-BFGS 之类的方法。scikit-learn 的 MLP 文档就提到,MLP 可以用 L-BFGS 或随机梯度下降类方法优化。
但在深度学习里,参数量动辄百万、千万甚至更多,损失面又通常是非凸的。这个时候,指望一步算出"精确最优解",基本不现实。
4.2 为什么牛顿法不常做深度学习主力
牛顿法的思路并不差,它利用的不只是梯度,还会考虑二阶信息,所以在一些小规模问题上收敛很快。问题在于:神经网络参数太多时,二阶信息的存储和计算都非常昂贵。模型越大,这个成本越夸张。
所以在真实深度学习项目里,大家更愿意选择每一步都便宜、能重复很多次、能在 GPU 和分布式环境里跑起来的方法。梯度下降虽然不是每一步都最聪明,但它足够实用。
5. 为什么训练时常用 Mini-Batch,而不是整批或单样本?
5.1 三种更新方式的本质区别
如果每次都拿全量样本算一次梯度再更新,那叫批量梯度下降。优点是方向稳,缺点是太慢。
如果每次只看一个样本就更新,那叫随机梯度下降。优点是更新频繁,缺点是噪声很大,训练曲线容易抖。Google 的 ML Crash Course 也指出,batch size 为 1 的 SGD 虽然能工作,但噪声很强。
现实里最常见的是 Mini-Batch:每次取一个小批样本,比如 32、64、128,一起算梯度,再做一次更新。这样既比 BGD 快,又比纯 SGD 稳,还天然适合 GPU 并行。
5.2 为什么 Mini-Batch 成了深度学习默认选择
因为深度学习不是只看数学优雅,更看工程效率。Mini-Batch 在训练速度、显存占用、梯度稳定性之间取得了很好的平衡。批次太小,梯度抖得厉害;批次太大,更新变慢、显存压力上来,还可能让泛化变差。

6. 如何判断神经网络是否过拟合?怎么评估模型性能?
6.1 不能只看训练集
训练集表现越来越好,这件事本身没有太大意义。真正关键的是:模型对没见过的数据表现如何。这就是为什么训练神经网络时,通常至少会划分训练集和验证集,有时还会额外准备测试集。
如果训练损失一直下降,但验证损失开始反弹,通常就说明模型开始过拟合了。它学到的已经不只是规律,还包括噪声。
6.2 性能评估要看任务类型
回归任务常看 MAE、MSE、RMSE;分类任务常看准确率、精确率、召回率、F1、AUC。不要把"损失函数"和"评估指标"混为一谈:损失函数是训练时拿来优化的,评估指标是拿来判断业务效果的。
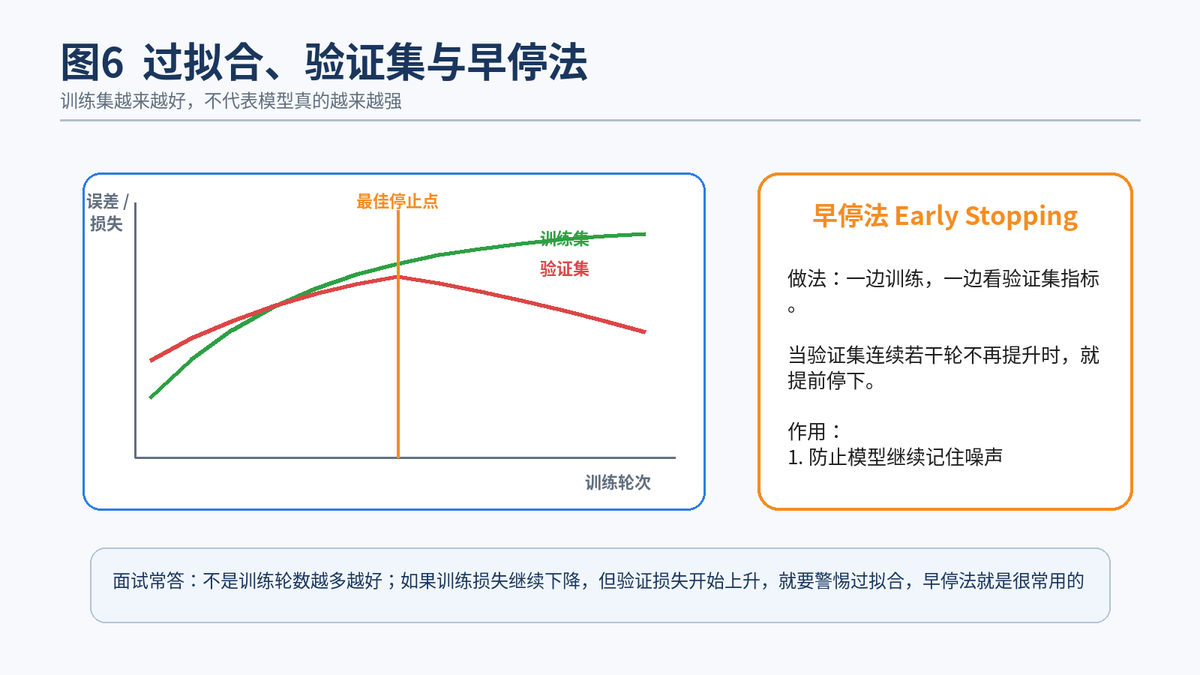
6.3 什么是早停法 Early Stopping?作用是什么?
Early Stopping 的逻辑非常朴素:如果验证集指标连续若干轮都不再改善,就提前停止训练。TensorFlow 的 EarlyStopping 文档明确写到,它会在被监控的指标不再提升时停止训练;TensorFlow 的过拟合教程也把它用作避免无效长时间训练的常见做法。
所以,早停法一举三得:防止继续记噪声、节省训练时间、常常还能拿到更好的泛化性能。
7. 深度学习中为什么常用 GPU 训练?
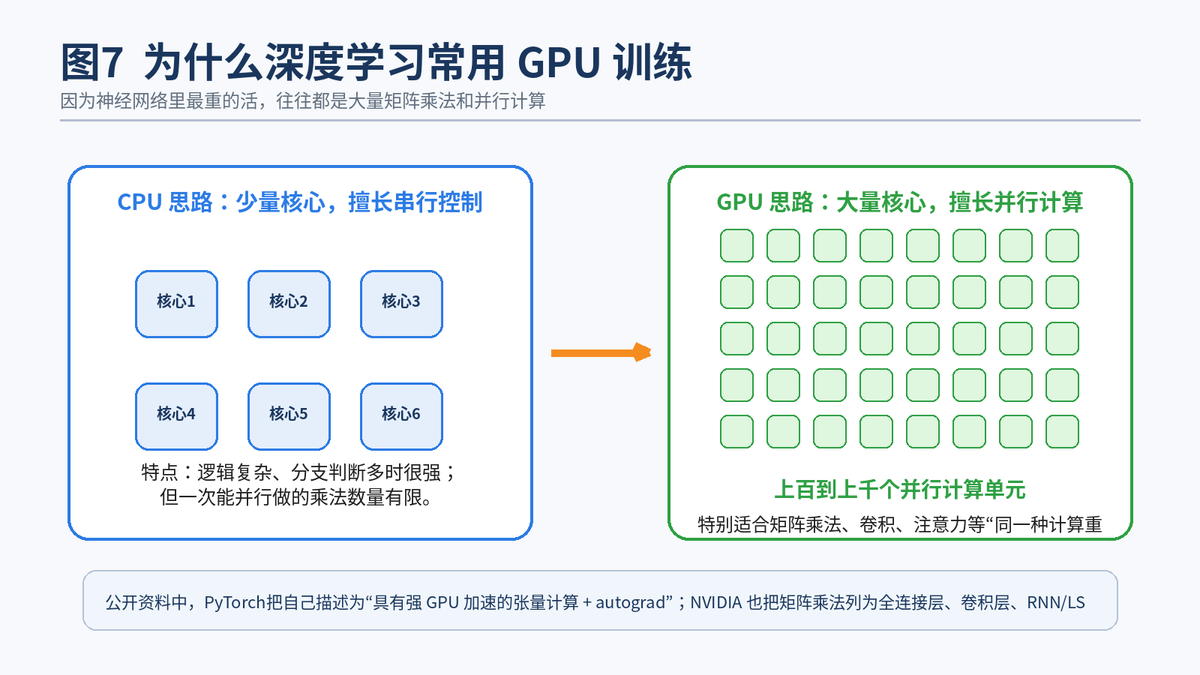
7.1 神经网络的大头工作,本来就适合 GPU
深度学习里最耗时的操作,往往不是 if-else 判断,而是海量矩阵乘法。NVIDIA 的性能文档把矩阵乘法列为全连接层、卷积层、RNN/LSTM/GRU 等神经网络层的重要基础计算。
GPU 最擅长的,就是把同一种数值运算并行地做很多份。所以当训练要反复做大规模矩阵乘法时,GPU 往往比 CPU 更合适。
7.2 从框架文档也能看出这一点
PyTorch 的公开说明把自己概括为"具有强 GPU 加速的张量计算"和"基于 autograd 的深度神经网络"。这说明 GPU 加速不是深度学习框架的附属能力,而是核心能力之一。
7.3 CPU 就完全没用了吗
也不是。小模型、数据预处理、特征工程、线上轻量推理,CPU 仍然很重要。但一旦进入中大型神经网络训练,尤其是卷积网络、Transformer 一类模型,GPU 的并行能力通常会带来明显收益。
8. 模型的参数量指的是什么,怎么计算?
8.1 参数量,就是模型里需要被训练的数字个数
在全连接网络里,参数主要由两部分组成:权重和偏置。只要一层神经元和下一层神经元有连接,就会产生权重;下一层每个神经元通常还会带一个偏置。
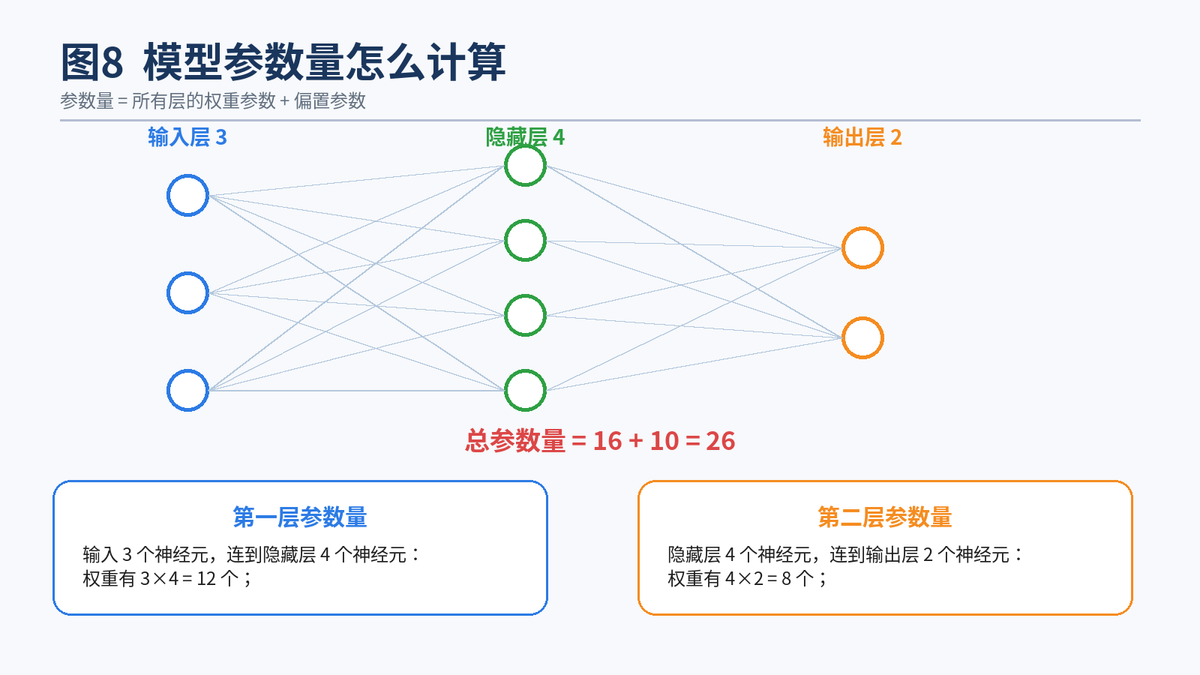
8.2 全连接层参数量的通俗算法
一层的参数量可以直接这样记:上一层神经元个数 × 下一层神经元个数,再加上下一层神经元个数。前一部分是权重,后一部分是偏置。
比如一个 3-4-2 的小网络:输入层 3 个神经元,隐藏层 4 个,输出层 2 个。第一层参数量是 3×4+4=16,第二层参数量是 4×2+2=10,总参数量就是 26。scikit-learn 的 MLP 文档也提供了各层权重矩阵形状的示例,本质上就是按这个思路在数参数。
8.3 卷积层参数量怎么理解
卷积层的算法和全连接层不一样,但思路一样:就是数需要被学习的卷积核权重,再加偏置。只不过卷积核会在空间位置上共享参数,所以卷积网络参数量通常比同规模全连接网络小得多。
9. 面试时,这道题怎么答更像高手?
如果面试官问"神经网络是怎么训练的",你不要一上来就背术语。更好的答法,是按一条主线把关系讲顺:
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 面试高分回答模板: 神经网络训练的核心,就是先做前向传播得到预测,再用损失函数衡量预测和真实标签之间的差距;然后通过反向传播高效计算各层参数的梯度,最后用梯度下降类优化器去更新参数。训练中通常使用 mini-batch 而不是全量数据,因为这样在速度、稳定性和 GPU 并行之间更平衡。为了避免过拟合,会用验证集监控效果,并结合 Early Stopping、正则化、Dropout 等方法。参数量本质上就是模型里需要学习的权重和偏置个数。 |
这样的回答有几个好处:第一,主线完整;第二,术语之间有因果关系;第三,能自然接住后续追问,比如为什么用 GPU、为什么用 mini-batch、为什么会过拟合。
10. 面试常见追问速答
10.1 为什么分类常用交叉熵,而不是 MSE?
因为分类网络输出的通常是概率,交叉熵对"正确类别概率太低"更敏感,优化目标和分类任务更一致。
10.2 反向传播和梯度下降是什么关系?
反向传播负责算梯度,梯度下降负责用梯度更新参数。前者像算导航,后者像真的开车。
10.3 为什么不用牛顿法?
不是绝对不用,而是在大规模深度网络里,二阶信息太贵,梯度下降类方法更可扩展。
10.4 为什么 mini-batch 最常见?
它兼顾了 BGD 的稳定性和 SGD 的速度,还更适合 GPU 并行。
10.5 早停法是在训练集还是验证集上判断?
通常看验证集,不看训练集。因为训练集只会越来越好,不能反映泛化能力。
10.6 参数量越大就一定越强吗?
不一定。参数多说明表达能力更强,但也更容易过拟合,对数据、算力和优化都提出更高要求。
11. 总结
把神经网络训练真正讲透,其实并不需要一上来推公式。你只要牢牢记住一条主线:模型先预测,损失函数负责扣分,反向传播负责算梯度,优化器负责改参数;为了训练得更快更稳,会用 mini-batch 和 GPU;为了别把训练集记得太死,还要靠验证集、早停法和正则化来控制过拟合。
当你能把这条链路从头到尾讲顺时,面试官听到的就不是碎片化术语,而是一整套清晰、可落地的训练逻辑。