1. 进程创建
1-1 fork函数初识
在linux中fork函数是非常重要的函数,它从已存在进程中创建一个新进程。新进程为子进程,而原进 程为父进程。
cpp
#include
pid_t fork(void);
返回值:子进程中返回0,父进程返回子进程id,出错返回-1进程调用fork,当控制转移到内核中的fork代码后,内核做:
• 分配新的内存块和内核数据结构给子进程
• 将父进程部分数据结构内容拷贝至子进程
• 添加子进程到系统进程列表当中
• fork返回,开始调度器调度
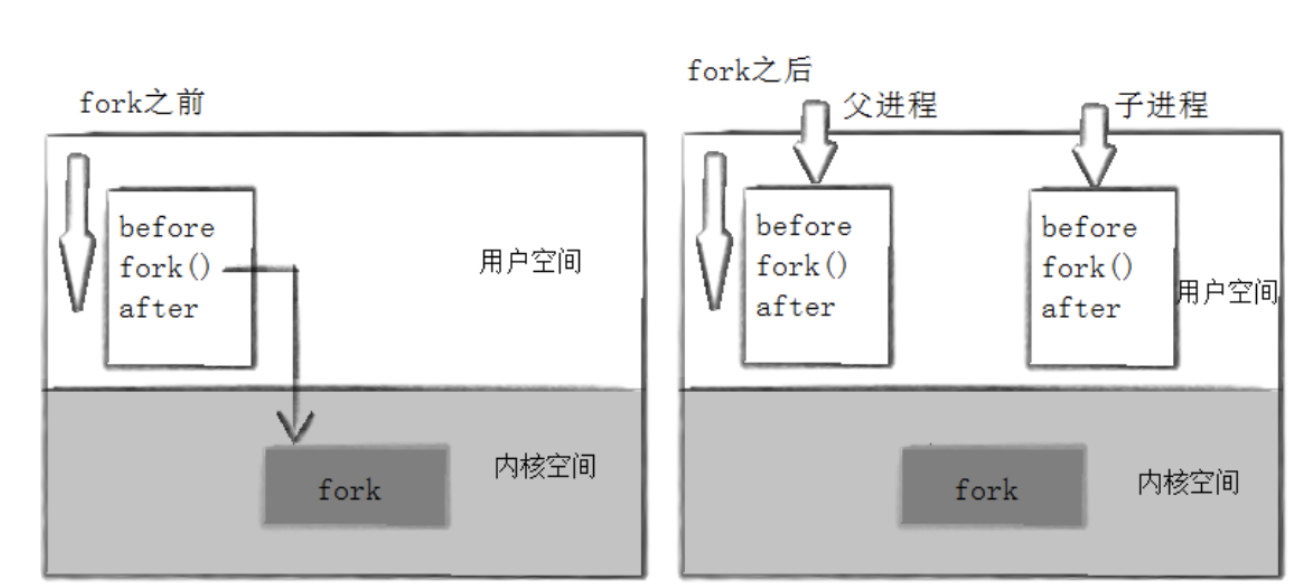
当一个进程调用fork之后,就有两个二进制代码相同的进程。而且它们都运行到相同的地方。但每个进 程都将可以开始它们自己的旅程
fork 之前:一个进程,一条执行流。fork 之后:两个进程,两条执行流,从同一行代码开始各跑各的。
1-2 fork 返回值
cpp
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main(void)
{
pid_t pid;
printf("Before: pid is %d\n", getpid());
if ((pid = fork()) == -1) perror("fork()"), exit(1);
printf("After: pid is %d, fork return %d\n", getpid(), pid);
sleep(1);
return 0;
}看刚才跑出来的结果:
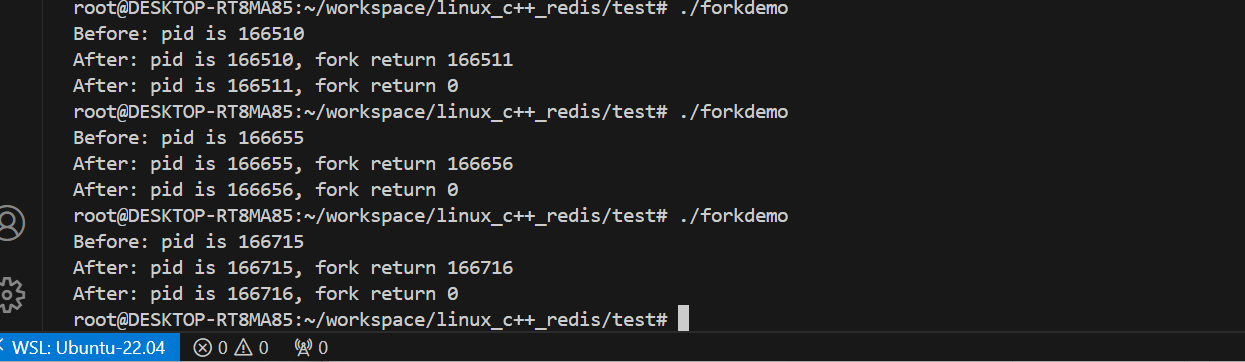
Before: pid is 165611 ← 父进程 fork 之前,只执行一次
After: pid is 165611, fork return 165612 ← 父进程:fork 返回子进程的 pid
After: pid is 165612, fork return 0 ← 子进程:fork 返回 0同一个 pid = fork() 调用,返回两次!
父进程里 fork() 返回 165612(子进程 pid)→ 父拿到孩子的身份证号
子进程里 fork() 返回 0 → 子知道自己"我是被复制出来的"用返回值区分谁是谁:
pid = fork();
if (pid == 0) // 在子进程里
...子进程干活...
else if (pid > 0) // 在父进程里
...父进程干活...执行流示意图
父进程 (pid=165611)
│
printf("Before..."); ← fork 之前,只跑一次
│
pid = fork(); ← 分裂点
│
┌──────────┴──────────┐
│ │
父进程继续 子进程开始
pid = 165612 pid = 0
│ │
printf("After..."); printf("After...");
│ │
return 0; return 0;
│ │
▼ ▼子进程不执行 fork 之前的代码,它从 fork 返回处开始跑。所以 fork 之前的 printf("Before") 子进程不会执行。
1-3 写时拷贝(COW)
通常,父子代码共享,父子在不写入时,数据也是共享的,当任意一方试图写入,便以写时拷贝的方 式各自一份副本。具体见下图:
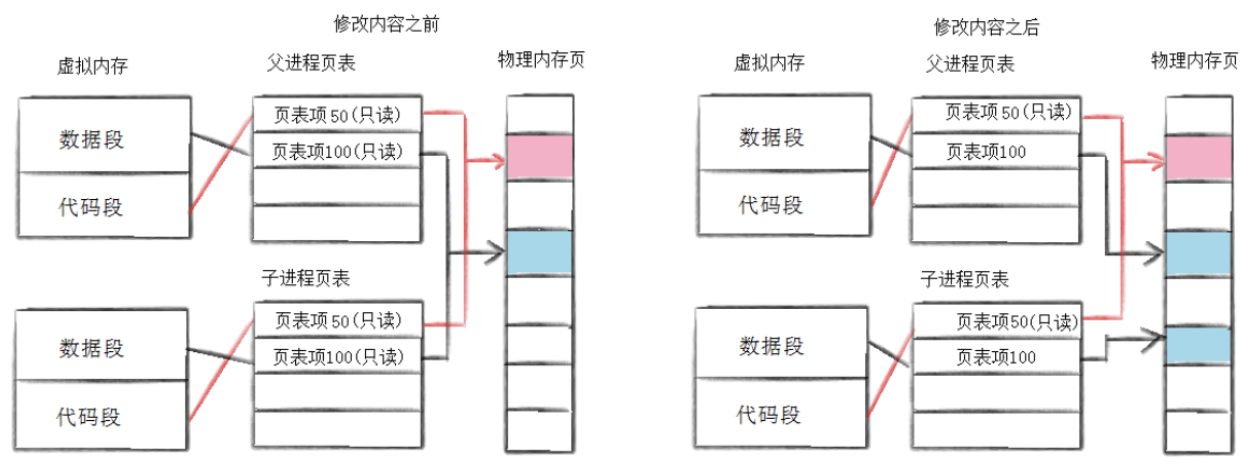
**COW 是延迟申请技术------**因为有写时拷贝技术的存在,所以父子进程得以彻底分离离!完成了进程独立性的技术保证! 写时拷贝,是一种延时申请技术,可以提高整机内存的使用率
1-4 fork 常规用法
用法一:父子各干各的
父进程:while(1) { 等客户端连接 → fork → 让子进程去处理 }
子进程:处理这个连接的业务逻辑用法二:变身(fork + exec)
pid = fork();
if (pid == 0) {
// 子进程
exec("./mycmd"); // 子进程"变脸",换成另一个程序
}
// 父进程继续做自己的事Shell 里敲 ls 就是这个流程:Bash fork 一个子进程,子进程 exec 变成 ls。
1-5 fork 调用失败的原因
| 原因 | 说明 |
|---|---|
| 系统进程数太多 | 进程表满了,新 task_struct 分配失败 |
| 用户进程数超限 | ulimit -u 限制了每个用户最大进程数 |
总结
| 概念 | 一句话 |
|---|---|
| fork 做什么 | 复制出一个一模一样的新进程,从同一行代码分道扬镳 |
| 返回值 | 父子各收到不同的返回值,通过返回值知道"我是爹还是儿" |
| 执行顺序 | fork 之后谁先跑,调度器说了算 |
| 写时拷贝 | 共享到写时才复制,延迟申请,省内存 |
| fork + exec | fork 复制身份,exec 换脸 |
2. 进程终止
2-1 进程退出场景
三大类:
| 场景 | 举例 |
|---|---|
| 代码正常跑完,逻辑正确 | mycmd 算完 1~100 累了,正常退休 |
| 代码正常跑完,逻辑错误 | 程序算完但结果不对,正常退休但留了封遗书 |
| 代码异常终止 | 段错误、除以 0、Ctrl+C 被人杀了 |
2-2 退出方法总览
正常终止(有退出码可查 echo $?)
├── main 函数 return
├── exit(status)
└── _exit(status)
异常终止(无退出码)
├── Ctrl+C (SIGINT, 退出码 130)
├── kill (SIGTERM, 退出码 143)
└── 段错误 (SIGSEGV)、除以 0 (SIGFPE) 等2-2-1 退出码
cpp
cat > exit1.c << 'EOF'
#include <stdio.h>
#include <stdlib.h>
int main()
{
printf("hello"); // 末尾没有 \n,输出留在缓冲区
exit(0); // exit 会先刷缓冲区再退出
}
EOF
cat > exit2.c << 'EOF'
#include <stdio.h>
#include <unistd.h>
int main()
{
printf("hello"); // 末尾没有 \n,输出留在缓冲区
_exit(0); // _exit 不刷缓冲区,直接退出
}
EOF刚才跑的结果:
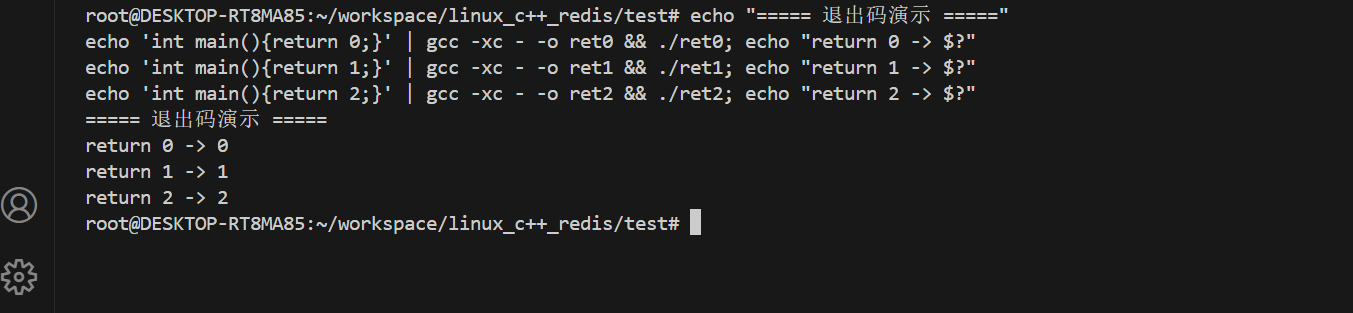
return 0 → echo $? 得到 0 ← 成功
return 1 → echo $? 得到 1 ← 失败
return 2 → echo $? 得到 2 ← 失败(另一种错误)常见退出码速查:
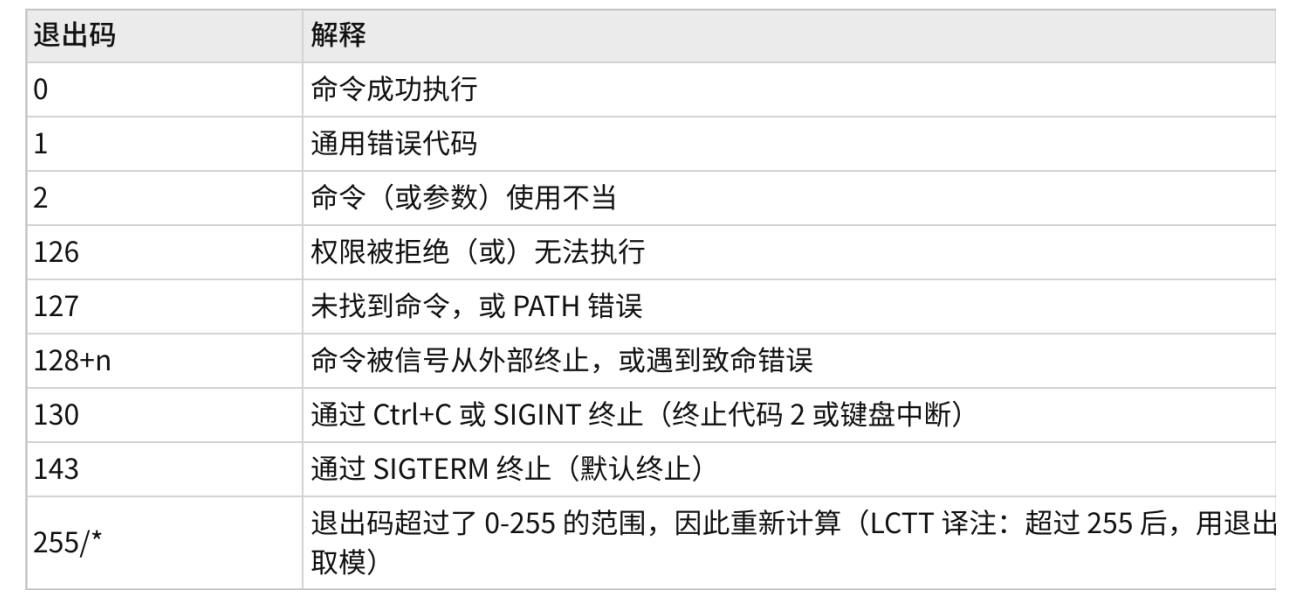
| 退出码 | 含义 |
|---|---|
0 |
成功 |
1 |
一般错误(权限不足、除以 0 等) |
2 |
参数错误 |
126 |
命令不可执行 |
127 |
命令未找到 |
128+n |
被信号 n 干掉的(130=Ctrl+C, 143=kill) |
0 = 成功,非 0 = 有事。
2-3-2 _exit 函数
#include <unistd.h>
void _exit(int status); // 只有低 8 位有效(0~255)_exit 做的事:直接退出,不做任何清理。 缓冲区的内容?不管。atexit 注册的清理函数?不调。就是立刻走人。
_exit(-1); // -1 的二进制低 8 位是 11111111 = 255
echo $? // 得到 2552-3-3 exit 函数 vs _exit
cpp
cd /root/workspace/linux_c++_redis/test && cat > exitdemo.c << 'EOF'
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main1()
{
printf("hello"); // 末尾没有 \n,输出留在缓冲区
exit(0); // exit 会先刷缓冲区再退出
}
int main2()
{
printf("hello"); // 同样没有 \n
_exit(0); // _exit 不刷缓冲区,直接退出
}
EOF刚才跑出来的关键区别:
exit(0) 版本: 输出 hello ← printf 的缓冲区被刷了
_exit(0) 版本: 啥都没输出 ← 缓冲区里的 "hello" 直接丢了原因:exit 在调用 _exit 之前多做了三步:
exit(status)
│
├── 1. 调用 atexit / on_exit 注册的清理函数 ← "临走收拾一下"
├── 2. 关闭所有打开的 FILE* 流,刷缓冲区 ← printf 没写出去的,现在写
└── 3. 调用 _exit(status) ← 真正退出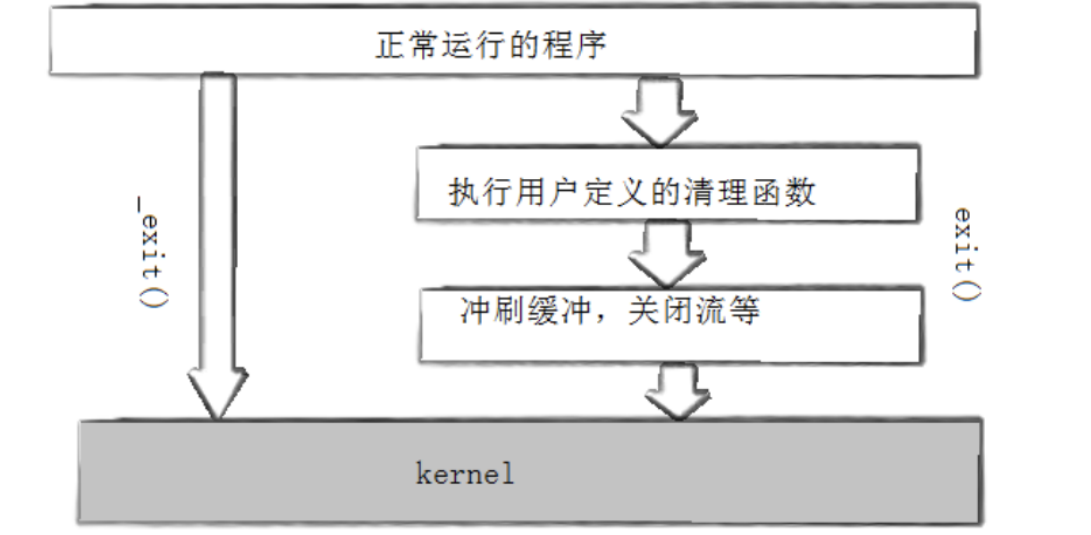
_exit 直接跳到最后一步,前面的全不做。
printf("hello"); printf("hello");
exit(0); _exit(0);
│ │
刷了 "hello" 缓冲区丢了
输出 hello (空白)2-3-4 return 退出
int main() {
return 0; // 等价于 exit(0);
}return n 就是 exit(n)。 main 函数的调用者(C 运行时 _start)会拿返回值去调 exit,(调用main的运行时函数会 将main的返回值当做 exit的参数)
_start → main() → return 0;
↓
exit(0) → _exit(0)总结:exit / _exit / return 三者的关系
return n
│
└── exit(n) ──→ atexit 清理 → 关闭流 → 刷缓冲区 → _exit(n) → 内核回收资源
↑
_exit(n) ──────────┘
(直接退出,啥也不管)_exit |
exit |
return |
|
|---|---|---|---|
| 刷缓冲区 | ✗ | ✓ | ✓ |
| 调 atexit 清理函数 | ✗ | ✓ | ✓ |
| 关闭文件流 | ✗ | ✓ | ✓ |
| 最终调 _exit | ✓ | ✓ | ✓ |
一句话:return n 就是 exit(n),exit 是带打扫的退出,_exit 是直接拔电源。