目录
1.服务注册与发现
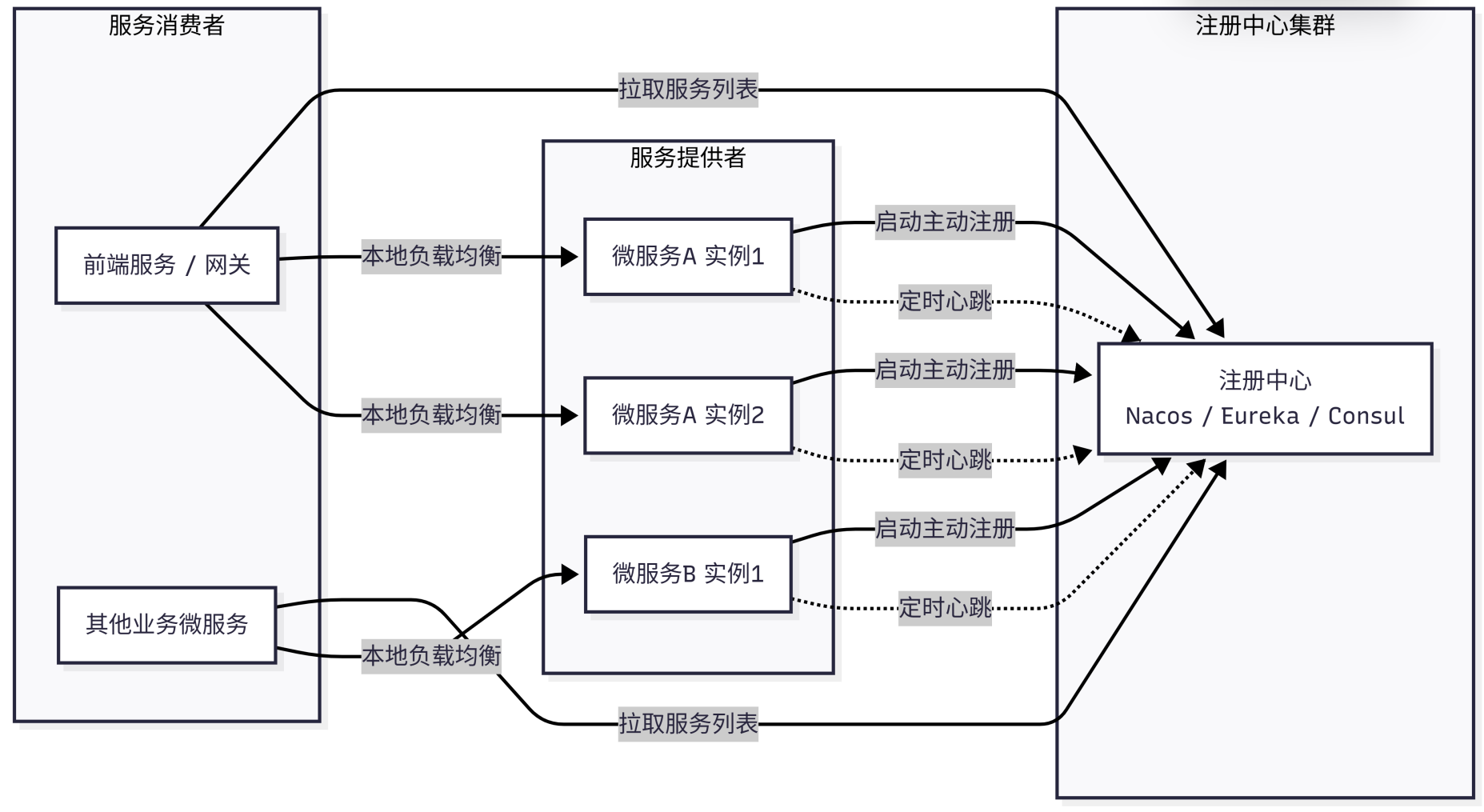
服务注册与发现
传统服务:
核心依赖:服务注册中心(Nacos/Eureka/Consul)
流程:
每个微服务启动 → 主动向注册中心注册自己的 IP、端口、服务名
消费者调用前 → 先从注册中心拉取服务列表
本地负载均衡(Ribbon/LoadBalancer)→ 选一个节点调用
扩容:多启几个实例,都去注册中心注册,消费者自动感知
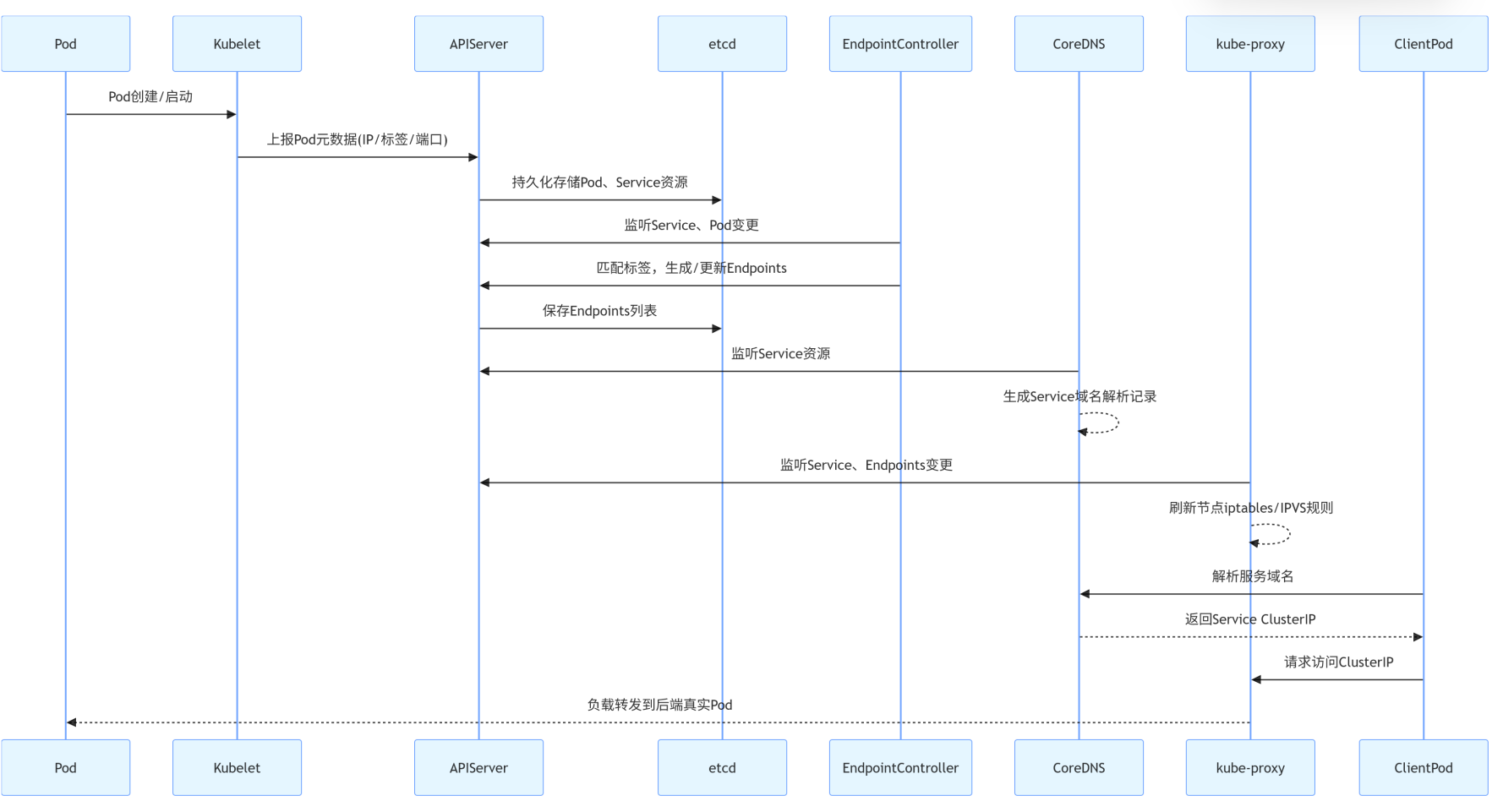
K8S
全部下沉到基础设施,K8S的几个组件就完成了注册发现的工作
- API Server
所有资源(Pod、Service、Endpoint)的统一入口
接收控制器、kubelet 的注册写入请求,存储到 etcd
是服务注册数据的总入口 - etcd
K8S 集群分布式存储
持久化存储:Service、Endpoint、Pod 地址、标签等注册元数据
相当于服务注册中心的配置存储层 - Endpoint Controller(端点控制器)
最关键的服务注册核心:
监听 Service 和 Pod 变化
自动把匹配 Service 标签的 Pod IP + 端口 维护到 Endpoints 资源中
完成:Pod 自动注册到 Service 的核心逻辑 - kube-proxy
服务发现 & 流量转发核心
监听 Service、Endpoints 变更
在每个节点上生成 iptables/ipvs 路由规则
实现集群内通过 Service 虚拟 IP 访问后端 Pod,完成服务发现与负载均衡 - CoreDNS / kube-dns
域名方式的服务发现
监听 Service 资源,自动生成域名解析记录
集群内 Pod 通过 服务名.命名空间.svc.cluster.local 域名访问服务
提供DNS 解析式服务发现 - Kubelet
上报本节点 Pod 状态与 IP 信息到 API Server
间接参与服务注册的数据上报
流程:
Pod 创建 → Kubelet 上报信息到 APIServer → 存入 etcd
EndpointController 匹配 Service 标签 → 把 Pod 写入 Endpoints(服务注册完成)
kube-proxy 感知 Endpoints/Service 变化 → 更新节点路由规则
CoreDNS 解析 Service 域名 → Pod 可用域名 / ClusterIP访问(服务发现完成)
传统微服务的痛点
- Eureka 时代
每个微服务实例主动直连注册中心,大家都要主动上报心跳、拉服务列表。
实例越多,注册中心连接压力、心跳压力、同步压力越大,集群规模一大就扛不住。 - Nacos 进阶一步
Nacos 用长连接替代短连接,服务上下线感知更快、推送更及时。
但本质没变:
还是每个业务实例都要跟 Nacos 建立长连接。
机器、实例越多,Nacos 接入层、连接管理、推送压力越大,规模上限依然有瓶颈。
K8S的解决思路
所有节点 Kubelet 只统一跟 APIServer 交互
业务 Pod 不用连任何注册中心、不用发心跳、不用建长连接
集群扩机器、扩 Pod,对业务完全无感
服务发现、健康检查、实例列表维护,全部下沉到 K8S 平台层
整个架构不再随着业务实例暴涨而压垮注册中心
完美解决了:实例越多,注册中心压力越大、架构越难横向扩展的痛点。
问题
你也许会问K8S不也是要跟APIService交互吗,它们之间也有长连接,怎么就比Nacos 要好?
以下就是答案:
- 传统注册中心致命短板
Eureka / Nacos:
每一个业务实例长连接常驻(每一台机器)
一旦服务列表变化,要全量推送给所有客户端
实例越多、服务越多,推送风暴、连接风暴直接压垮中心 - K8S 做了三个架构级优化,完美避开这个坑
① 只有 Kubelet / 控制器 跟 APIServer 通信
业务 Pod 根本不连 APIServer
普通微服务实例根本不用上报心跳、不用注册、不用拉服务列表。
只有节点上的 Kubelet、内部控制器在和 APIServer 交互,连接数直接砍掉几个量级。
② 用 Watch 订阅机制,不是轮询拉全量
不是每次都全量查一遍 etcd 数据。
组件(控制器、kubelet)跟 APIServer 建立 Watch 长连接:
没变化就静静挂着,只有资源发生变化,APIServer 才下发增量事件
只推增量,不推全量,流量极小。
③ 不用把服务列表下发给每一个业务 Pod
传统:每个微服务都要完整拉一份全服务列表。
K8S:
业务 Pod 根本不需要知道任何实例列表
只靠 CoreDNS + Service 访问,底层负载均衡完全下沉到集群层面。
不需要给客户端推送任何实例变更,直接省掉最大的广播压力。