第九章:革命性的简洁------Transformer 架构
!info
在上一章中,我们看到了注意力机制如何打破了 Seq2Seq 的信息瓶颈。巴赫达瑙(Bahdanau)等人的一个朴素想法------让解码器在每步生成时"回头查阅"编码器的所有隐状态------不仅让机器翻译的质量大幅提升,还给整个 NLP 领域留下了一个迷人的可解释性工具:对齐矩阵。注意力机制,成了那个时代 NLP 系统的"标配附件"。
然而,有一件事没有改变:RNN 还在那里。注意力机制只是改变了解码器获取信息的方式,但编码器和解码器本身仍然是 LSTM 或 GRU------仍然是一步接一步地处理输入,仍然在逐步传递隐状态,仍然受限于这个根本的顺序计算依赖。
GPU 一直在等待,却始终没有被充分利用。
!question
如果注意力机制已经能让模型直接建立任意两个词之间的关联,我们还需要 RNN 做什么?能不能把 RNN 彻底扔掉,只用注意力来做序列建模?
9.1、一篇宣战书
9.1.1 一个激进的想法
2017 年初,谷歌有一个奇特的内部文化:各个研究团队之间竞争激烈,但也彼此交叉。在谷歌大脑(Google Brain)和谷歌研究(Google Research)的走廊里,你可能在上午遇到一个在研究图像生成的人,下午又遇到一个在写翻译系统的人。这种混搭有时会产生意外的化学反应。
要理解这群人所处的时代背景,我们需要把镜头稍微拉远一点。
2016 年秋,谷歌的机器翻译系统完成了一次重大升级,正式从基于规则的统计翻译切换到深度学习系统,即"谷歌神经机器翻译"(GNMT)。这个系统在各大媒体引发轰动,翻译质量的提升被用户真实感受到了。谷歌翻译日均处理的翻译量高达 1000 亿词以上,这意味着 GNMT 在投产的那一刻,就已经成为地球上规模最大的 AI 系统之一。
但工程师们心里清楚,GNMT 有一道难以逾越的天花板。它的核心是 8 层堆叠的 LSTM,每一层都需要顺序地处理输入序列------词一个接一个地被喂进去,隐状态一步一步地更新。这意味着,即便谷歌拥有全球最强的 TPU(张量处理器)集群,这个系统也无法充分利用硬件的并行能力。训练 GNMT 一次需要数周时间,而当研究者试图把模型做大------加更多层、加更宽的隐层------时间消耗进一步以令人沮丧的速度增长。
阿希什·瓦斯瓦尼(Ashish Vaswani,谷歌大脑研究科学家)和他的同事们正是在这个背景下工作的。他们一直在做机器翻译,RNN 是核心架构,但每次试图把模型做大,训练效率就变得极其低下。不是因为算法不好,而是因为 RNN 的顺序计算结构,天然地无法被并行化。这是一个结构性的问题,不是调参能解决的。
诺姆·沙泽尔(Noam Shazeer,1977-,谷歌传奇工程师,后任 Character.AI 联合创始人)是这个团队里思维最活跃的人之一。他在谷歌工作了将近二十年,经历过搜索排序、语言模型、翻译系统等一系列大型工程项目。在谷歌的内部文化里,他是那种"大家都知道他的名字"的人------不是因为头衔,而是因为他总能提出别人没想到的技术方案。他不是那种只会写论文的学者,更像一个有强烈工程直觉的"发明家"。他后来主导提出了稀疏 Mixture of Experts 架构(与多位同事合作),并独立提出了 SwiGLU 激活函数,都成了大语言模型时代的核心技术------但那是后话。
在 2017 年初的那段时间,沙泽尔开始认真思考一个问题:注意力机制本身已经能做到"直接建立任意两个位置之间的连接"了。那我们还需要 RNN 来维持那条顺序链条吗?
这个问题,听起来像是在质疑整个 NLP 领域过去十年的基础设施。当时,全球 NLP 研究界几乎所有重要系统都建立在某种形式的 RNN 之上:机器翻译是 LSTM,语音识别是 LSTM,问答系统是 LSTM,情感分析是 LSTM。LSTM 已经不只是一个模型,更是一种思维方式------提到序列建模,人们的第一反应就是"循环"。质疑这个前提,在当时需要相当的勇气,或者说,足够强大的工程直觉做支撑。
9.1.2 论文标题即宣言
在谷歌内部,这个想法经历了相当程度的怀疑。
RNN 派的人有充分的理由抵触这个想法。循环网络的顺序计算,不只是一种计算方式,更是一种直觉------语言本来就是有顺序的,词语之间的依赖关系本来就是逐步建立的。把 RNN 扔掉,感觉就像要建一座没有地基的楼。而且,Bahdanau 注意力刚被证明好用,为什么不继续沿着这条路走,而是要做一个激进的"完全去掉 RNN"的实验?
但瓦斯瓦尼、沙泽尔,以及另外六位合作者------尼基·帕马尔 (Niki Parmar)、雅各布·乌斯科雷特 (Jakob Uszkoreit)、利昂·琼斯 (Llion Jones)、艾丹·戈麦斯 (Aidan N. Gomez,当时是多伦多大学的实习生)、乌卡斯·凯泽 (Łukasz Kaiser)、伊利亚·波洛苏欣 (Illia Polosukhin)------他们决定做一件事:先建一个完全基于注意力的系统,看看它能不能在机器翻译上打败 RNN。
实验的结果,让他们自己都有点意外。
这个没有任何循环结构的模型,不仅跑得更快,而且翻译质量更好。2017 年 6 月,他们把这篇论文提交到了 arXiv,并随后投稿 NeurIPS 2017(当时叫做 NIPS)。
他们给这篇论文起了一个名字:《Attention Is All You Need》。
翻译成中文,是"注意力就是你所需要的一切"。但这个中文翻译失去了原文的那种挑衅气息。"All You Need",暗示了 RNN 不只是"不那么必要",而是根本"不需要"。这个标题不是一个谦虚的学术表述,它更像是一份宣战书------对过去十年 RNN 统治 NLP 的整个范式,正面宣战。
值得一提的是,"XXX is all you need" 标题风由于其简约或者略带反叛的风格,被后续很多工作者所使用,然而在更多的普通论文中,这种标题往往超出了实际贡献的解释能力,将本质上多因素驱动的系统简化为单一因素,容易造成表达强度与实际内容之间的不匹配,从而削弱学术严谨性并引发审稿与读者的怀疑,这种标题党也一度引起社区的反感与抵触。
在这篇论文中,他们给自己的模型起名叫 Transformer,有意思的是,这个单词至今也并没有一个非常好的中文翻译,它的本意是变压器,变形金刚等,比较接近的翻译是"转换器"。至于为什么起了这样的一个名字,是因为主要命名者 Jakob Uszkoreit 单纯觉得 "Transformer" 这个词发音好听、有力量感,比干巴巴的 "Attention Net" 或 "Self-Attention Network" 更响亮。

图 9.1:阿希什·瓦斯瓦尼(Ashish Vaswani),Transformer 论文第一作者
9.1.3 怀疑,与第一批惊喜
论文在 NeurIPS 2017 被接受,但在最初的评审中并非没有质疑。有审稿人认为,这项工作只在机器翻译上做了实验,无法证明它是一个通用的序列建模框架。有人担心,完全去掉循环结构,模型是否能处理需要严格依赖顺序的任务。更具体的质疑是:自然语言里存在大量的长距离依赖现象,LSTM 花了多年时间才被调优到能处理这些情况------一个完全新的架构,真的能在这些方面一步到位吗?
还有一种更"哲学性"的反对意见:RNN 的循环结构,不只是计算上的选择,更是对"语言本质"的一种建模------语言是时间性的,词语的含义随着上下文的积累而逐步形成。如果完全去掉这种时间性的结构,单纯用"所有位置互相关注"来替代,真的能学到语言的深层结构吗?
最早认真读这篇论文的社区,反应是两极分化的。一部分人看到机器翻译的基准测试结果,立刻被吸引------数字说话,效果好,并行快,没有理由不用。另一部分人则持观望态度:LSTM 经历了多年打磨,机器翻译只是 NLP 的一个子领域,Transformer 能否推广还不清楚。
在工业界,反应更快。谷歌的工程师们迅速意识到,Transformer 的并行化特性意味着它可以更充分地利用 TPU/GPU 的并行计算能力------训练同样规模的模型,Transformer 所需的时间和资源可以大幅减少。这不是一个学术层面的优化,而是一个直接影响研发成本和产品迭代速度的工程优势。
但接下来发生的事,远远超出了任何人的预期------包括这篇论文的作者。
2018 年,谷歌基于 Transformer 的编码器训练出了 BERT;OpenAI 基于 Transformer 的解码器训练出了 GPT-1。两个模型几乎同时重塑了整个 NLP 领域,把此前所有的基准测试提升了几乎不可思议的幅度。再往后,Transformer 跨越了 NLP 的边界:图像领域出现了 Vision Transformer(ViT),音频领域出现了 Wav2Vec,蛋白质结构预测领域出现了 AlphaFold 2------2021年,AlphaFold 2 使用 Transformer 架构攻克了困扰生物学界五十年的蛋白质折叠问题,被《Science》杂志评为年度突破。
回头看,Vaswani 等人 2017年发表《Attention Is All You Need》的那个夏天,这个领域其实已经站在了悬崖边上------不过没有人知道这一点,包括他们自己。他们只是在解决一个具体的工程问题:怎么让机器翻译跑得更快、翻译得更好。他们没有想到,他们的解决方案会成为接下来整个 AI 时代最重要的基础设施。
人们后来常常把 Transformer 的成功归结为"这是一个天才的设计"。但参与其中的工程师们回忆,更接近真实的描述是:这是一群聪明的工程师在巨大的计算压力下,把一个看起来合理的想法推到极致,然后发现它出人意料地好用。
9.2、顺序计算的枷锁
在第八章中,我们在讨论 RNN 模型的时候,已经给大家介绍过 RNN 的"顺序计算"的枷锁。
9.2.1 GPU 的怒吼
现代 GPU 是为并行计算而生的。一块 2017 年的 NVIDIA Tesla V100 GPU,里面有 5120 个 CUDA 核心。这 5120 个核心可以同时进行计算------就像一个工厂有 5120 条流水线同时运转。
但一条流水线有个前提:每条流水线处理的任务之间,不能有前后依赖。如果任务 B 必须等待任务 A 完成之后才能开始,那不管你有多少条流水线,那两个任务都只能串行处理。
RNN 的顺序计算,恰恰就是这种情况,如果需要处理一个 100 词的句子:
- 第 1 步:处理词 x1x_1x1,计算隐状态 h1h_1h1
- 第 2 步:把 h1h_1h1 和词 x2x_2x2 一起,计算 h2h_2h2(必须等待第 1 步完成)
- 第 3 步:把 h2h_2h2 和词 x3x_3x3 一起,计算 h3h_3h3(必须等待第 2 步完成)
- ......以此类推,共 100 步
这 100 步是严格串行的。每一步都依赖上一步的输出。因此不管 GPU 里有多少个并行核心,这 100 步只能一步一步地完成。GPU 的 5119 条流水线,大部分时间都在空转等待。
这不只是"效率低"的问题,而是一个结构性的上限:随着序列变长,训练时间线性增长,与你拥有多少并行计算资源无关。2017 年的谷歌,拥有当时全球最强的 AI 计算集群,却被 RNN 的顺序计算结构卡死------这是一种非常令人沮丧的不匹配感。
9.2.2 长距离依赖的物理极限
除了并行化问题,RNN 还有另一个根本性的局限:信息在时间轴上传播的路径长度。
想象一下这个英文句子:
The cat, which had been living with my grandmother in her old farmhouse by the lake, was hungry.
"cat"(猫)和动词"was"(是)之间,隔了一个很长的定语从句------共有 16 个词。对于 RNN 来说,"cat"的信息需要经过 16 步的隐状态传递,才能到达处理"was"的那一步。每一步传递,都有信息损耗的风险------即使 LSTM 的门控机制已经大大缓解了梯度消失的问题,极长距离的依赖仍然很难被完美捕捉。
用一个更直观的类比:想象你在传一张纸条,每传给一个人,他都会在纸条上重新抄写一遍(可能有几个字稍微变了)再传给下一个人。传了 16 个人之后,纸条上的内容和最初的原件,可能已经有了不同程度的偏差。
这个问题在实际评测里有清晰的体现。研究者发现,当机器翻译系统处理越来越长的句子时,BLEU 分数会随句子长度增加而下降------哪怕使用了注意力机制的最好 RNN 系统,在超过 30 个词的长句上,翻译质量明显弱于短句。翻译界有一条经验:如果一个系统在短句上的表现和长句上的表现差距很大,那背后几乎一定有某种"记忆限制"在起作用。
在 Transformer 到来之前,"长距离依赖"一直是 NLP 的一个核心难题。研究者们发明了各种技巧------更长的上下文窗口、双向 LSTM、层次化结构------都是在 RNN 的框架内修修补补。但问题的根源没有被触动:只要用顺序传递来建立依赖,长距离就永远是负担。
RNN 的两个问题------无法充分利用 GPU 并行计算,以及长距离依赖的信息衰减------是同一个根源的两种表现:顺序计算结构。而 Transformer 一刀切断了这个根源。
9.3、核心洞察:一步直达
瓦斯瓦尼等人的核心洞察,用一句话说是这样的:
注意力机制不需要 RNN 作为"载体"------注意力本身就能建立位置之间的直接连接,而这已经足够了。
这个洞察的激进之处在于,它推翻了一个隐性假设:我们一直默认,序列建模需要某种"状态传递"机制,沿着时间轴把信息一步一步送到该去的地方。RNN 是这样的,LSTM 是这样的,带注意力的 Seq2Seq 也还是这样的------注意力只是解码器查询信息的方式,编码器本身还是在"传递状态"。
但如果每个位置都可以直接"看到"序列里的所有其他位置呢?
就像把那条"逐步传递信息的链条",换成了"一间开放式会议室":链条里,信息从头传到尾,每个人都只和旁边的人说话;而会议室里,每个人都能直接和所有其他人对话。
这个比喻揭示了两种范式的本质差异:
- RNN:信息的传播路径是线性链 ,最远的依赖需要经过 n−1n-1n−1 步才能建立
- Transformer:信息的连接是全连接图,任意两个位置之间只需 1 步
从链条到全连接图,不只是计算效率的提升,而是表达能力的根本升级。
但这里有一个微妙的地方值得细想:如果把"每个位置直接看到所有位置"这件事推到极致,它是不是会带来信息过载?人类在处理语言时,并不是同时关注所有词语------我们总是在某个时刻重点关注某些词,而相对忽视其他词。
Self-Attention 的设计,其实已经内置了这种"选择性":注意力权重经过 Softmax 之后,是一个概率分布。最相关的位置会获得高权重,不相关的位置权重接近零。这不是"平均关注所有词",而是"加权关注所有词,但权重分布反映了语义相关性"。在实践中,大多数位置的注意力权重会高度集中在少数几个真正相关的位置上------这让 Transformer 兼顾了"直接连接一切"的计算优势和"有选择地关注"的语义表达力。
另一个值得思考的问题是:为什么之前没有人想到这个设计?
答案是:想到了,但没有条件实现。纯注意力的思想并不新鲜------理论上,任何时候都可以说"让每个词关注所有词"。但在 2014-2015 年,这样做计算代价太高,而且缺乏有效的训练方法。是注意力机制本身变得成熟(高效的点积计算、可微的软注意力)、硬件条件改善(更强的 GPU 和 TPU),以及深度学习训练技巧的积累(残差连接、层归一化),这三件事共同成熟,才让"纯注意力"的想法从"理论上可行"变成了"工程上真的好用"。
Transformer 的诞生,不是一个天才灵感突然降临的时刻,而是一系列技术条件积累到临界点后的自然爆发。
9.4、拆解 Transformer
现在让我们走进 Transformer 的内部,逐层理解它的工作原理。Transformer 的结构看起来复杂,但核心其实只有几个组件------把这几个组件的逻辑理清楚,整个架构就会自然展开。
9.4.1 Self-Attention:序列的内部对话
上一章我们讨论的注意力机制,是"编码器-解码器之间的注意力":解码器的某个位置,去关注编码器的所有位置。这是一种跨序列的注意力------Query 来自一个序列(解码器),Key 和 Value 来自另一个序列(编码器)。
Self-Attention(自注意力) 是一个关键变体:Query、Key、Value 都来自同一个序列。序列里的每个位置,都去关注这同一个序列的所有其他位置------包括自己。
这就是"自注意力"的"自"字的含义:序列在与自身对话。
让我们用一个例子来感受这件事的意义。考虑这句话:
"bank 宣布他们将裁员,因为那家工厂的贷款出了问题。"
读到 "bank" 这个词时,它到底指的是什么?是金融机构?还是河岸(bank 在英文里有两者的含义)?
对于人类来说,答案显然------看后文,"贷款"、"裁员",语境明确指向金融机构。但对于机器来说,如果只看 "bank" 这一个词,没有上下文,是无法消歧义的。
Self-Attention 的作用,就是让 "bank" 这个词能够"看到"整句话中的所有其他词------"贷款"、"工厂"、"裁员"------并根据这些词的相关度,调整自己的表征。经过 Self-Attention 之后,"bank" 的表示向量,已经不再是孤立词语的表示,而是融合了整个句子上下文信息的表示。
这个能力,是 RNN 没有的。RNN 是顺序处理的,当它处理 "bank" 时,"贷款"这个词还没有出现在输入流里(假设是从左到右处理)。双向 LSTM 稍微改善了这一点,但仍然需要两次顺序扫描,而且捕捉超长距离依赖的能力依然有限。
Self-Attention 让每个词在同一时刻就能"看到"整个序列------无论依赖跨越多远的距离,代价都完全相同。
我们可以更细致地追踪这个例子。考虑句子中的"他们"这个词。在中文里,"他们"是一个指代词,它的意义取决于它所指向的名词。在这句话里,"他们"指的是"银行"(作为机构的银行的人员)。对于 RNN 来说,处理"他们"时,"银行"这个词已经在隐状态里被"消化"了------如果句子够短、LSTM 够大,它可能还在隐状态里留有"银行"的信息;但如果两者距离很远,信息就可能已经衰减。
对于 Self-Attention 来说,处理"他们"时,模型会计算"他们"这个词的 Query 向量,和句子里所有其他词(包括"银行")的 Key 向量的相似度。如果训练得当,"他们"对"银行"的注意力权重会远高于对其他词的权重------因为这两个词在语义上有强烈的指代关系。于是,"他们"的最终表示向量,会强烈地受到"银行"的 Value 向量的影响,有效地解析了指代关系。
这种直接连接,是 Self-Attention 最重要的能力之一:它可以一步完成跨越任意距离的语义联系,而不需要等待信息在 RNN 的链条里慢慢传播。
9.4.2 三重角色:每个词同时是提问者、被检索标签和实际内容
现在来解释 Self-Attention 里最核心、也最容易让人困惑的概念:Q/K/V 的三重角色。
上一章已经引入了 Q/K/V 的基本图书馆类比------Query 是我们的查询问题,Key 是书的标签,Value 是书的实际内容。在 Bahdanau 注意力里,Query 来自解码器,Key 和 Value 来自编码器。
但在 Self-Attention 里,事情有趣多了:序列里的每一个词,同时扮演三个角色。
对,是同时。不是轮流,是同时。
让我们用一个办公室会议的类比来理解这件事。
想象一间会议室里有 6 位同事(对应句子里的 6 个词)。他们正在开一个"信息整合"会议,每个人都带来了自己的知识,目的是让每个人离开时都能整合所有人的信息。
会议的规则是这样的:
- 每个人都要提出自己的查询(Query):"我需要什么信息来更好地理解当前的讨论?"
- 同时,每个人也在向所有人广播自己的标签(Key):"我能提供什么类型的信息?"
- 还有,每个人都准备了实际内容(Value):"如果有人真的需要我的信息,这是详细内容。"
会议进行时:
- 每个人都把自己的 Query("我需要什么?")和其他所有人的 Key("他们能提供什么?")做匹配,计算相关度分数
- 根据分数,决定"我应该参考哪些人的意见,各占多少比重"
- 对所有人的 Value("实际内容")做加权求和,得到自己的"整合结论"
- 这个整合结论,就是这个人"参加了这次会议"之后获得的新表示
六个人同时进行这个过程,互相不需要等待。会议结束后,每个人的"表示"都已经融合了整个房间的信息。
这就是 Self-Attention 的工作方式:序列里的每个词,同时以三种方式参与计算。
那么,这三个角色的向量是哪来的?不是直接用词的原始表示,而是通过线性变换得到的:
Qi=WQ⋅xi,Ki=WK⋅xi,Vi=WV⋅xiQ_i = W^Q \cdot x_i, \quad K_i = W^K \cdot x_i, \quad V_i = W^V \cdot x_iQi=WQ⋅xi,Ki=WK⋅xi,Vi=WV⋅xi
其中 xix_ixi 是第 iii 个词的输入表示(词嵌入或上一层的输出),WQ,WK,WVW^Q, W^K, W^VWQ,WK,WV 是三个不同的权重矩阵,通过训练学习。
为什么要三个不同的矩阵,而不是直接用同一个向量?
因为"用于被检索"(Key)和"用于提供内容"(Value)是两种不同的角色,用不同的矩阵投影,可以让模型把这两种功能分开优化。类比于图书馆:书的封面和目录(Key,用于被找到)和书的正文内容(Value,被找到后提供的信息)当然可以很不一样------用不同的矩阵投影,就是在允许这种差异存在。
9.4.3 缩放点积注意力:数学细节与一个被忽视的设计
有了 Q/K/V,计算过程如下:
第一步:计算注意力分数
对于位置 iii,计算它的 Query 向量和序列中所有 位置的 Key 向量的点积:
eij=Qi⋅Kje_{ij} = Q_i \cdot K_jeij=Qi⋅Kj
点积的结果越大,表示第 iii 个词"需要的信息"和第 jjj 个词"能提供的信息"越匹配。从数学角度而言,两个向量的点积结果大,说明两个向量的方向更具一致性,可以解释为两个向量的相似度更高。
第二步:缩放(为什么要除以 dk\sqrt{d_k}dk ?)
在 Vaswani 等人的设计里,计算完点积之后,要除以一个系数 dk\sqrt{d_k}dk ,其中 dkd_kdk 是 Key 向量的维度:
eij=Qi⋅Kjdke_{ij} = \frac{Q_i \cdot K_j}{\sqrt{d_k}}eij=dk Qi⋅Kj
这个缩放步骤,看起来像一个不起眼的技术细节,但它背后有一个真实的工程问题。
以原论文 dk=64d_k = 64dk=64(每个头的维度)为例:两个 64 维的随机向量做点积,结果的期望绝对值约为 64=8\sqrt{64} = 864 =8。如果 dkd_kdk 更大(比如某些大型模型里每个头的维度是 128 或 256),这个数值会更高。当这些数值进入 Softmax 函数时,会发生什么?
Softmax 的公式是 σ(zi)=ezi/∑jezj\sigma(z_i) = e^{z_i} / \sum_j e^{z_j}σ(zi)=ezi/∑jezj。当输入值非常大时,指数函数会让某一个维度的值远远大于其他维度,Softmax 输出会接近一个"硬分配"------几乎把全部权重分给分数最高的那一个位置,其他位置的权重趋近于零。
这个效果听起来似乎不错("把注意力集中在最相关的位置"),但它会导致一个严重的梯度问题:Softmax 在输出接近 0 或 1 的区域,梯度几乎消失。模型的参数学不到任何信息,训练陷入停滞。
除以 dk\sqrt{d_k}dk 把点积结果缩放到一个合理的量级,让 Softmax 能维持合理的梯度,训练稳定进行。
这个设计被称为缩放点积注意力(Scaled Dot-Product Attention),"缩放"两个字的由来就在这里。
第三步:Softmax 归一化
αij=Softmax(Qi⋅Kjdk)=exp(eij)∑kexp(eik)\alpha_{ij} = \text{Softmax}\left(\frac{Q_i \cdot K_j}{\sqrt{d_k}}\right) = \frac{\exp(e_{ij})}{\sum_k \exp(e_{ik})}αij=Softmax(dk Qi⋅Kj)=∑kexp(eik)exp(eij)
对每个位置 iii,其对所有位置 jjj 的注意力权重求和等于 1。
第四步:加权求和
oi=∑jαijVjo_i = \sum_j \alpha_{ij} V_joi=j∑αijVj
用注意力权重对所有位置的 Value 向量加权求和,得到位置 iii 的输出表示。
整个过程写成矩阵形式更简洁:
Attention(Q,K,V)=Softmax(QKTdk)V\text{Attention}(Q, K, V) = \text{Softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right) VAttention(Q,K,V)=Softmax(dk QKT)V
其中 Q,K,VQ, K, VQ,K,V 是把序列所有位置的 Query、Key、Value 向量堆叠成的矩阵。这个矩阵形式的好处在于,它可以被整个批量并行计算------不再需要任何循环。
(选读)深入解释 :QKTQK^TQKT 是一个 n×nn \times nn×n 的矩阵,其中 nnn 是序列长度。这就是 Transformer 计算复杂度 O(n2⋅d)O(n^2 \cdot d)O(n2⋅d) 的来源:对于长度为 nnn 的序列,需要计算 n2n^2n2 个注意力分数,每个分数的计算代价是 O(d)O(d)O(d)(ddd 为特征维度)。训练时的内存占用也是 O(n2)O(n^2)O(n2),因为需要存储整个注意力矩阵。这个二次方代价,是 Transformer 后续面临的最大瓶颈。
9.4.4 Multi-Head Attention:多角度同时观察
理解了缩放点积注意力,我们再来看 Transformer 的另一个关键设计:多头注意力(Multi-Head Attention)。
一个头(Single Head)的问题是什么?想象一下,一个注意力头负责计算词与词之间的相关度。每次计算,它只能用一套 Q/K/V 的权重矩阵,捕捉一种类型的关联。但语言里的关联类型是多种多样的:
- 句法关联:主语和谓语之间的关联("猫" → "跳")
- 语义关联:指代关联(代词"它"指向前文的"猫")
- 位置关联:修饰语与被修饰词的关联("红色的" → "苹果")
- 语义框架关联:动词和其论元之间的关联("踢" → "足球")
如果只有一个注意力头,它只能学到这些类型中"最主要"的那一种,或者学到这几种的某种混合------混合的结果,往往是把每种类型都没学好。
多头注意力的解决方案是:让多个注意力头并行运行,每个头用自己独立的 Q/K/V 权重矩阵,各自学习不同类型的关联。
这就像一个合唱团的排练。指挥(总体任务)希望合唱团的声音丰富、有层次。如果只有一个声部,无论这个声部唱得多好,都只能表达一种音色。但如果有女高音、女中音、男高音、男低音四个声部同时演唱,每个声部专注于自己的音区,合在一起才能产生丰富的和声层次。多头注意力里的每个"头",就是一个声部。
具体实现:假设用 hhh 个头,每个头用维度为 dk=dmodel/hd_k = d_{model}/hdk=dmodel/h 的 Q/K/V 矩阵(让总参数量保持不变),独立进行缩放点积注意力计算,得到 hhh 个不同的输出向量,最后把它们拼接在一起,再经过一个线性变换:
MultiHead(Q,K,V)=Concat(head1,...,headh)WO\text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \ldots, \text{head}_h) W^OMultiHead(Q,K,V)=Concat(head1,...,headh)WO
其中每个 headi=Attention(QWiQ,KWiK,VWiV)\text{head}_i = \text{Attention}(Q W_i^Q, K W_i^K, V W_i^V)headi=Attention(QWiQ,KWiK,VWiV)
Transformer 原论文使用了 h=8h=8h=8 个头,每个头的维度 dk=512/8=64d_k = 512/8 = 64dk=512/8=64。实验表明,多头注意力确实能让不同的头专注于不同类型的关系------研究者后来对注意力权重的可视化研究发现,某些头确实表现出专注于句法关系,某些头专注于指代关系,尽管这种专门化并非通过显式监督实现的。
2019 年,Clark 等人对 BERT(基于 Transformer 编码器的大型模型)的注意力头进行了系统性分析。他们发现,不同的注意力头自发地学到了不同的语言学功能:
- 某些头几乎把所有注意力集中在相邻位置(局部依赖)
- 某些头专门处理标点符号和特殊标记(SEP、CLS)
- 某些头在句法上跟踪主谓关系
- 某些头处理指代关系("他"→ "张三")
这些发现让语言学家和 AI 研究者都感到震惊:一个从未被告知过语言学理论的模型,只凭借大规模文本的端到端训练,就自发地在内部组织出了反映语言结构的功能模块。这不是设计出来的,而是"学"出来的。这意味着语言的某些结构,以一种深层的方式编码在了大规模文本的统计规律里------Transformer 有能力从中提取出这些结构。
当然,这种"自发专门化"并不是每个头都清晰可见的。事实上,大多数注意力头的行为复杂而难以解释------它们学到的关联模式,可能根本没有人类语言学的类比。但这恰恰说明,Transformer 捕捉到的信息不只是人类已知的那些语言规律,还有大量隐藏在数据里的更复杂的统计结构。
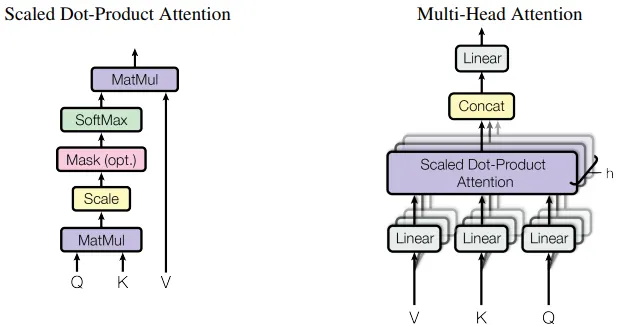
图 9.2:Multi-Head Attention 架构图 ,左图为 Scaled Dot-Product Attention 模块(Q→Linear, K→Linear, V→Linear,进入 MatMul+Scale+Softmax+MatMul 流程)。右图为 Multi-Head Attention:输入 Q, K, V 经过 h 个独立的线性投影(每个头一组),分别计算 Scaled Dot-Product Attention,得到 h 个输出,Concat 拼接后经过最终的线性投影 WOW^OWO。箭头标注各维度变化。来源:Vaswani et al.,2017,图 2。
9.4.5 位置编码:告诉模型"谁在哪里"
Self-Attention 有一个隐藏的问题,初次接触的人很容易忽略。
让我们回想一下 Self-Attention 的计算过程:对于序列里的任意两个位置 iii 和 jjj,注意力分数 eij=Qi⋅Kje_{ij} = Q_i \cdot K_jeij=Qi⋅Kj。注意,这个公式里没有任何关于位置 iii 和位置 jjj 的信息------计算只依赖于这两个词的 Q/K 向量,而 Q/K 向量是从词的表示通过线性变换得到的。
这意味着,如果你把句子里的词随机打乱顺序,对每个位置的 Self-Attention 计算没有任何影响------只要词的内容没变,计算结果就不变。
这显然是个大问题。"猫追鼠"和"鼠追猫",所有词相同,但意思完全相反。
RNN 是天然有顺序信息的------它逐步处理,第 ttt 步的隐状态 hth_tht 自然地编码了"这是第 ttt 个输入"这个事实,因为之前所有输入都已经流过这个状态。
但 Transformer 一次性看所有词,没有"先看哪个、后看哪个"的概念。它需要一种方式,人为地注入每个词的位置信息。
Vaswani 等人的方案是位置编码(Positional Encoding):在每个词的输入嵌入向量上,叠加一个携带位置信息的固定向量。
具体设计使用正弦和余弦函数:
PE(pos,2i)=sin(pos100002i/dmodel)PE_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{2i/d_{model}}}\right)PE(pos,2i)=sin(100002i/dmodelpos)
PE(pos,2i+1)=cos(pos100002i/dmodel)PE_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{2i/d_{model}}}\right)PE(pos,2i+1)=cos(100002i/dmodelpos)
其中 pospospos 是词在序列中的位置(1, 2, 3, ...),iii 是向量的维度索引,dmodeld_{model}dmodel 是模型维度。
为什么用三角函数,而不是简单地用 1, 2, 3, 4 这样的位置数字?
这里有几个设计考量:
第一,范围无关性。 如果直接用位置数字(1, 2, 3, ...)作为位置编码,当序列很长时,位置编码的数值会很大,与词的嵌入向量(通常在 -1 到 1 之间)量级不匹配,训练不稳定。三角函数的值域是 −1,1-1, 1−1,1,永远和词的嵌入向量在同一量级。
第二,相对位置可学习性。 三角函数有一个优美的性质:sin(pos+k)\sin(pos + k)sin(pos+k) 可以用 sin(pos)\sin(pos)sin(pos) 和 cos(pos)\cos(pos)cos(pos) 的线性组合表示。这意味着,位置 pos+kpos + kpos+k 的编码,可以被表示为位置 pospospos 的编码的一个线性变换。换句话说,相对位置关系 ("这个词在那个词后面 kkk 步")可以通过线性变换从绝对位置编码里推导出来,模型可以学到这种关系。
第三,外推能力(有限)。 三角函数是周期性的,不会随位置增大而溢出。在训练时见过的序列长度范围之外,理论上也能产生有意义的编码------虽然在实践中,原论文的正弦编码在超长序列上的外推能力是有限的(这个问题后来被 RoPE、ALiBi 等更先进的位置编码方案改进,见第十六章)。
实际操作:把位置编码向量 PEposPE_{pos}PEpos 直接加到词嵌入向量 EposE_{pos}Epos 上:
xpos=Epos+PEposx_{pos} = E_{pos} + PE_{pos}xpos=Epos+PEpos
加法而不是拼接。这样做,模型的输入维度保持不变,位置信息和语义信息被融合在同一个向量空间里。
有一种更直观的理解方式:把位置编码想象成一种"坐标系"。每个位置都有一个独一无二的"坐标签名",而且这个签名的设计方式,使得位置越接近的词,签名越相似;位置越远的词,签名越不同。这个特性,让模型能够通过比较签名来感知"这两个词是相邻的,还是相距很远的"。
这里其实也有一些耐人寻味的设计理念,既然我们说位置编码非常重要,而又通过这种相加的方式将位置编码与词嵌入编码进行混合,那么这是否会导致位置编码信息被淹没掉或者被弱化掉呢?实际上研究者也尝试过很多其他方案,如将两者的编码信息拼接起来,但这会导致模型参数增多,计算量骤增,他们也尝试过可学习的位置嵌入等方案,但效果整体相近,因此这里也没有理论层面的最优设计,而是一种工程上的考量。
9.4.6 前馈网络与子层设计
在每一个 Transformer 层中,Self-Attention(或 Multi-Head Attention)之后,还有一个前馈网络(Feed-Forward Network,FFN):
FFN(x)=max(0,xW1+b1)W2+b2\text{FFN}(x) = \text{max}(0, xW_1 + b_1)W_2 + b_2FFN(x)=max(0,xW1+b1)W2+b2
这是一个标准的两层全连接网络,激活函数用 ReLU(原论文)或后来常用的 GELU。注意,这个 FFN 是逐位置应用的(Position-wise):序列里的每个词,独立地经过同一个 FFN。不同位置之间,FFN 的计算不互相依赖。
FFN 的作用是什么?
Self-Attention 是一种"混合"操作------它把序列里不同位置的信息混合在一起,让每个位置的表示都融入了上下文。但混合之后的向量,需要进一步的"消化"------对这个混合信息进行非线性变换,提取更深层的特征。FFN 就承担了这个角色:它是 Transformer 里负责特征提取的组件。
我们可以把 Self-Attention 想象成"收集信息",FFN 想象成"处理信息"。两者的分工明确,交替叠加,构成了 Transformer 每一层的基本结构。
残差连接与层归一化
Transformer 的每个子层(Self-Attention 或 FFN)外面,还包裹着两个关键设计:残差连接(Residual Connection) 和层归一化(Layer Normalization,LayerNorm)。
残差连接来自第五章讲到的 ResNet 思想:子层的输出是"输入 + 子层计算结果",不只是子层计算结果。这让梯度在反向传播时有一条"直路"可走,避免了深层网络的梯度消失。
LayerNorm 在第六章已经详细介绍过:它在每个样本的特征维度上进行归一化,让深层网络的训练更稳定。与批归一化(BatchNorm)不同,LayerNorm 不依赖 batch 大小,对序列数据天然友好------这正是它成为 Transformer 标配的原因。
所以,每个子层的完整计算是:
output=LayerNorm(x+SubLayer(x))\text{output} = \text{LayerNorm}(x + \text{SubLayer}(x))output=LayerNorm(x+SubLayer(x))
这个公式看起来简单,但它是 Transformer 能堆叠到很深(6 层、12 层乃至后来的数百层)仍然稳定训练的关键。没有残差连接,深层 Transformer 的梯度会消失;没有 LayerNorm,每层输出的分布会漂移,深层网络的训练会极不稳定。这两个组件,在 ResNet(2015)和 Ba 等人(2016)分别提出时,各自解决了深度网络训练的不同问题。Transformer 把它们组合在一起,构成了一个可以稳定扩展到任意深度的架构基础------而这个扩展性,后来被证明是 Transformer 最重要的特性之一(见第十二章关于规模定律的讨论)。
其中 SubLayer 是 Self-Attention 或 FFN。
9.4.7 Encoder-Decoder:完整的翻译机器
Transformer 原论文是为机器翻译设计的,所以它的完整架构包含编码器和解码器两个部分。
编码器(Encoder)
编码器接受源语言句子,对每个词做 Self-Attention,让每个词的表示融入整个句子的上下文。编码器由 NNN 个相同的层堆叠而成(原论文 N=6N=6N=6),每层包含一个 Multi-Head Self-Attention 子层和一个 FFN 子层。
编码器的输出是一组"上下文感知的词表示":每个词的向量,不再只携带这个词本身的信息,而是携带了它在整个源语言句子中的语义角色信息。
解码器(Decoder)
解码器接受目标语言句子(训练时是已知的翻译,推理时是已经生成的部分),逐步生成翻译结果。解码器同样由 NNN 层堆叠,但每一层有三个子层:
- Masked Multi-Head Self-Attention:对已经生成的目标序列做 Self-Attention,但有一个"掩码"(mask):每个位置只能关注它之前的位置,不能"偷看"后面还没生成的词。这是为了保持自回归的生成性质------生成时,是一个词一个词产生的,不能提前知道后面的词。
- Multi-Head Cross-Attention:这就是"编码器-解码器注意力"------Query 来自解码器当前的表示,Key 和 Value 来自编码器的最终输出。这一步让解码器能"查阅"源语言句子的所有位置,决定当前时刻该关注翻译的哪个部分。
- FFN:与编码器相同的前馈网络。
每个子层同样包裹残差连接和 LayerNorm。
最后,解码器的输出经过一个线性层和 Softmax,生成目标词汇表上的概率分布,选择概率最高的词作为当前步骤的翻译输出。
值得注意的是,这个 Encoder-Decoder 架构并不是 Transformer 唯一的使用方式------恰恰相反,后来证明最有影响力的是两种"截肢版本":
- 只用编码器(Encoder-only):BERT 的架构,擅长理解和分类,每个词的表示充分融合了双向上下文
- 只用解码器(Decoder-only):GPT 系列的架构,天然适合生成,通过 Masked Self-Attention 保持自回归性质
这个分叉------BERT 路线和 GPT 路线------是 2018 年 NLP 最重要的架构抉择之一,我们将在第十一章中详细展开。而在那之前,我们需要理解一件更基础的事:不管是编码器还是解码器,要充分发挥 Transformer 的能力,仅靠机器翻译这一个任务的数据是远远不够的。
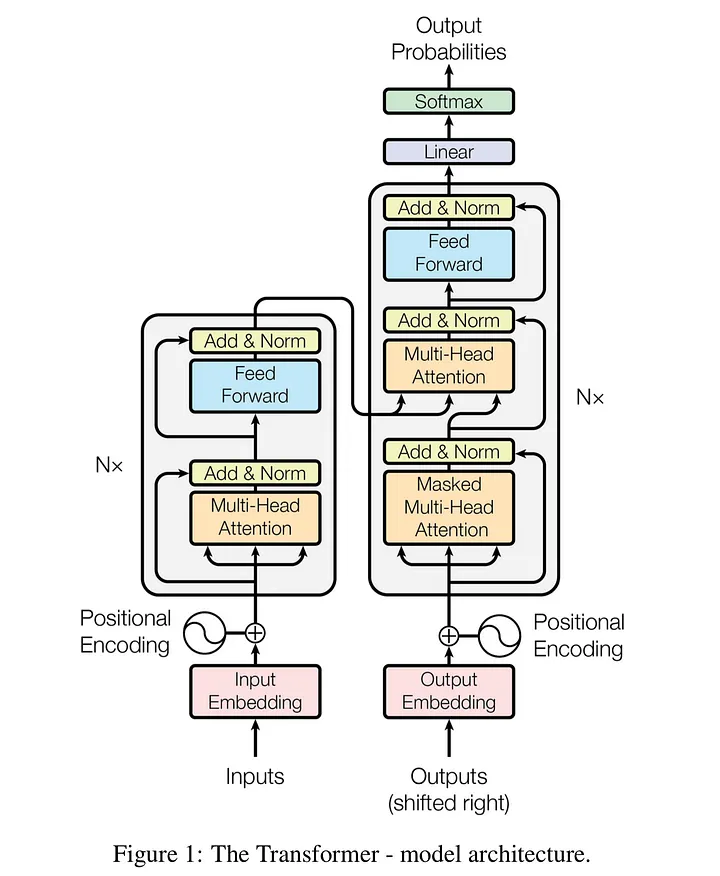
图 9.3:完整的 Transformer Encoder-Decoder 架构
9.5、为什么有效:机器翻译的基准测试
Transformer 论文的实验数据,是让怀疑者无话可说的关键。
9.5.1 英法、英德翻译:BLEU 分数的飞跃
在第六章我们提到,机器翻译的标准评测指标是 BLEU 分数,范围 0-100,分值越高越好。测试集是 WMT(Workshop on Machine Translation)竞赛的标准数据集,是 NLP 领域最权威的评测平台之一。
要理解 BLEU 分数的含义,可以想象一个简单的类比:你让不同的人翻译同一句英文,然后把他们的翻译和"标准答案"(参考译文)比较,看有多少词组(n-gram)是重叠的。重叠越多,分数越高。BLEU 不是完美的评测指标(有时会奖励字面正确但语义奇怪的翻译),但它是领域里最广泛使用的标准化评测工具,各个系统的 BLEU 分数可以相互比较。
在英语 → 德语翻译任务(WMT 2014 基准测试)上:
- 当时领先的 RNN+注意力系统(包括多种集成模型):约 24-26 BLEU
- 谷歌 GNMT(8 层 LSTM,模型集成):约 26.36 BLEU
- Transformer(大模型配置):28.4 BLEU,超越所有此前系统,提升 2 个点以上
在英语 → 法语翻译任务(WMT 2014 基准测试)上:
- 当时最好的集成系统:约 41.16 BLEU
- Transformer(大模型配置):41.8 BLEU,以单个模型超越了之前需要多个模型集成才能达到的最优水平
NLP 领域有一个非正式的说法:BLEU 分数每提升 1 个点,翻译质量的提升就足以被有经验的评估员明显感知到。2 个点的提升,在人工评估中已经是显著的差距。而 Transformer 这一次不只是在某个特定语言对或特定条件下胜出,而是在最权威的基准测试上全面碾压------这让怀疑者很难继续保持观望。
仅凭这两个数字,BLEU 分数的提升本身已经值得关注。但更让人震撼的是另一个数字。
9.5.2 训练效率:8 块 GPU vs 数百块 GPU
这才是让工业界真正沸腾的数字。
在训练 WMT 英德翻译模型时:
- 谷歌 GNMT(相当规模的 LSTM 系统):在大量 GPU/TPU 上训练了约一周以上
- Transformer(大模型配置,"Transformer Big"):8 块 NVIDIA P100 GPU,训练 3.5 天,达到更高的 BLEU 分数
这不是"同等条件下快了一点",而是数量级级别的效率提升。更少的计算资源,更短的训练时间,更好的结果------三件事同时发生。
原因在哪里?并行化。
回想一下 RNN 的训练过程:处理一个 50 词的句子,需要 50 步串行计算。每一步的矩阵运算本身可以利用 GPU 并行,但 50 步之间的依赖关系让它们只能顺序执行。如果批量处理 64 个句子,每个句子内部是串行的,不同句子之间的批量计算才能并行。
Transformer 的训练过程:处理同样一个 50 词的句子,整个编码器的 Self-Attention 可以用一次大矩阵运算完成------QQQ、KKK、VVV 矩阵的计算,和注意力分数矩阵 QKTQK^TQKT 的计算,都是现代 GPU 最擅长的纯矩阵运算,可以被高度并行化。
打个比方:RNN 训练就像让一个工人按顺序完成 50 道工序,每道工序用上所有机器;Transformer 训练就像把 50 道工序拆成若干批,每批的所有工序可以同时进行。在 GPU 这种"超多核"的架构下,后者的效率优势是压倒性的。
正是这个效率优势,让研究团队在有限的计算预算内可以做更多的实验迭代,可以训练更大的模型,可以更快地验证想法。在 AI 研究中,实验速度本身就是竞争力------能做更多实验的团队,发现更好结果的概率更高。Transformer 的出现,等于给 NLP 研究安装了一台更大的发动机。
9.5.3 注意力的可视化
研究者在论文里还做了注意力头的可视化------把 Multi-Head Attention 里不同头的注意力权重画出来,得到了一些有意思的发现。
某些头清楚地表现出了句法结构的捕捉:比如,一个头的注意力权重显示,动词位置的词高度关注其主语;另一个头显示,指代词"it"在解析时高度关注前文的名词短语。这里有一个著名的例子,句子是 "The animal didn't cross the street because it was too tired"(动物没有穿越街道,因为它太累了)------在这个句子里,"it"(它)指代的是 "animal"(动物)而不是 "street"(街道)。注意力可视化清晰地显示,某个注意力头在处理 "it" 时,注意力权重高度集中在 "animal" 上,而几乎忽略了 "street"------尽管 "street" 在位置上离 "it" 更近。
图 9.4:多头注意力机制下的句法结构捕捉示意图
这些模式,没有经过任何句法标注的显式监督。完全是从大规模翻译数据里,通过端到端训练自动浮现出来的。
这一发现的重要性不只在于"模型学到了语言学结构",更在于它提供了一种前所未有的可解释性。深度学习模型长期以来被批评为"黑盒"------给它输入,它给你输出,但中间发生了什么,没人能看见。正如我们在上一章说所言,Attention 的设计改变了这一点:每一步的注意力权重,都是可以计算和可视化的。当模型翻译错了,或者生成了奇怪的输出,研究者可以检查哪些位置的注意力权重分布异常------这比盲目调参要有效得多。
这一特性,让语言学背景的研究者们格外感兴趣------一个纯数据驱动的模型,自发地学到了人类语言学家描述过的某些结构,这究竟意味着什么?是语言的这些结构本身就深深编码在大规模文本的统计规律里?还是 Transformer 只是恰好找到了一种计算上高效的近似,在表面上看起来和语言学结构一致?这个问题,在今天仍然是 AI 可解释性领域最活跃的研究方向之一。
9.6、边界与局限:一个美丽新世界的隐患
Transformer 是 2017 年 NLP 领域最重要的突破,但它绝不是没有代价的。而这些局限的每一个,都直接催生了后续的技术进步。
9.6.1 O(n2)O(n²)O(n2) 的计算代价:规模的诅咒
Transformer 最核心的局限,也是它最大的工程挑战,就是注意力机制的计算复杂度。
对于长度为 nnn 的序列,Self-Attention 需要计算 n×n=n2n \times n = n^2n×n=n2 个注意力分数(每个位置对每个位置)。这意味着:
- 序列长度翻倍 → 计算量翻四倍
- 序列长度增加 10 倍 → 计算量增加 100 倍
- 内存占用也是 O(n2)O(n^2)O(n2),因为需要存储整个 n×nn \times nn×n 的注意力矩阵
在处理短句子(几十个词)时,这个代价是可以接受的。Transformer 原论文处理的句子平均长度不超过 50 个词,502=250050^2 = 2500502=2500 个注意力分数,完全没问题。但当你试图把 Transformer 扩展到处理更长的文本时,这个二次方增长就变成了一道难以跨越的墙:
- 处理 512 词的文档:注意力矩阵约有 26 万个元素(这是 BERT 的默认配置)
- 处理 1,024 词的文档:注意力矩阵约有 100 万个元素(GPT-2 的最大配置)
- 处理 4,096 词的长文档:注意力矩阵约有 1600 万个元素,显存开始紧张
- 处理整本书(10 万词):注意力矩阵有 100 亿个元素------单这一个矩阵就需要数百 GB 的内存,任何现实的 GPU 都无法承受
这就是为什么 2017-2022 年间,基于 Transformer 的语言模型通常有"上下文窗口"的限制------不是设计者不想处理更长的文本,而是超出这个长度,内存和计算代价都会变得无法承受。BERT 的上下文窗口是 512 个词(token),早期的 GPT-2 是 1024,GPT-3 是 2048------每一代提升都是在算力极限上挣扎的结果。
这个问题在实际应用中带来了真实的痛苦。假设你想用 BERT 来分析一份法律合同,合同有 1 万字。BERT 每次只能处理 512 个词,你需要把合同切成若干段分别处理,然后手动整合结果------但整合时,BERT 看不到全文的跨段依赖,分析质量会有损失。对于需要理解长篇文档的任务(法律、医疗报告、学术论文),上下文窗口的限制是一个绕不开的工程障碍。
后来,围绕这个问题衍生出了一系列重要技术方向:
- FlashAttention(2022,Dao 等人):通过重新组织内存访问模式,在不改变数学结果的情况下大幅减少 GPU 显存使用,使实际可用的序列长度翻倍
- Sparse Attention(稀疏注意力) :不计算所有 n2n^2n2 个注意力分数,只计算"重要的"位置对,把复杂度降低到 O(nn)O(n\sqrt{n})O(nn ) 或 O(nlogn)O(n\log n)O(nlogn)
- Linear Attention(线性注意力) :通过数学变换把复杂度从 O(n2)O(n^2)O(n2) 降到 O(n)O(n)O(n),但通常以牺牲一些表达能力为代价
- 位置编码升级(RoPE、ALiBi):让模型在训练序列长度之外仍能工作,间接扩展了"有效上下文"
这场围绕长上下文的技术竞赛,是 2022-2024 年间 AI 工程领域最热门的话题之一------从 4K 上下文到 8K、32K、128K,再到 2024 年某些模型宣称支持 100 万个 token 的超长上下文。这些故事,我们会留在第十四章深入探讨。
9.6.2 位置编码的外推问题
Transformer 的正弦位置编码,在处理"训练时没见过的长度"的序列时表现糟糕。
具体来说:如果训练时最长序列是 512 词,那么模型在测试时处理 1000 词的序列,就需要使用"训练时从未见过的"位置编码值(pos > 512 的部分)。虽然正弦函数可以延伸到任意位置,但模型的其他参数没有见过这些编码模式,外推性能会显著下降------就像你从来没有见过大于 100 的数字,突然被要求处理 300 的运算,直觉上感到陌生。
这个问题导致了后来一系列改进工作:相对位置编码(Relative Position Encoding)、旋转位置编码(RoPE,Rotary Position Embedding)、线性偏置注意力(ALiBi)等。这些方案的共同目标,是让模型在训练长度之外也能保持合理的性能。其中 RoPE 目前已成为绝大多数主流大语言模型(LLaMA、Qwen、DeepSeek 等)的标配位置编码方案,将在第十四章详细讨论。
9.6.3 数据饥渴:归纳偏置的代价
Transformer 的强大能力,需要大量数据来支撑------而这背后有一个深层原因。
RNN 有较强的归纳偏置(Inductive Bias):它的循环结构天然假定"时间上相邻的词更可能相关",这是对序列数据的一种合理先验。在数据量有限时,这种内置先验往往是有帮助的。Transformer 的 Self-Attention 则没有这种偏置------每个位置对每个位置的权重都从数据中学习,没有内置的"近邻偏好"。这种灵活性是优势(可以学到任意类型的依赖),但也意味着模型需要更多样本才能学到稳定的注意力模式。
具体数字:在 WMT 英法翻译任务上,Transformer 使用了约 3600 万对平行句对训练。这是当时 NLP 领域最大规模的监督数据集之一。如果换一个低资源语言的翻译任务,从零训练一个 Transformer 很可能不如精心调优的小型 LSTM。
这产生了一个重要的历史规律:Transformer 在大规模数据上的表现远超 RNN,但在小数据集上,精心调优的 LSTM 往往仍有竞争力。"Transformer 永远比 RNN 好"是一个常见的误解;正确的说法是"在有足够数据的情况下,Transformer 展现出更强的扩展能力"。
更深的问题是:Transformer 在机器翻译上的成功,依赖大量有标注的平行语料。但 NLP 的许多任务根本没有这么多标注数据------如何让 Transformer 的能力迁移到这些任务?这个问题,在 2017 年还没有清晰的答案。但恰恰是这个问题,催生了整个"预训练-微调"的范式------而这,正是第十一章的故事。
9.6.4 原生架构对序列生成的顺序依赖
一个常常被忽视的点:Transformer 在训练 时可以并行处理整个序列(解码器用 Masking 确保训练时不"偷看"),但在推理(实际使用)时,生成任务仍然是自回归的------一个词一个词地生成,每次生成都依赖之前生成的所有词。
这意味着,在生成文本时,Transformer 和 RNN 一样无法并行。生成 100 个词,仍然需要 100 步。训练时的并行优势,在推理时无法直接享受。
更让工程师头疼的是,每次生成一个新词,模型都要重新计算整个 Key 和 Value 矩阵------尽管之前所有步骤的 K/V 都已经计算过了。这是一种明显的浪费。后来的工程优化引入了 KV Cache(键值缓存):把每一步已经计算过的 K/V 向量缓存起来,下一步直接复用,只计算新增词语的 K/V。KV Cache 在实际部署中极大提升了推理速度,现在已经是所有基于 Transformer 的大语言模型服务的标配优化。但 KV Cache 本身也带来了新的内存压力------对于上下文很长的对话,缓存的 K/V 矩阵可能占据大量显存,限制了系统能同时服务的用户数量。
后来的推测解码(Speculative Decoding,2022年)是另一个方向:用一个小型草稿模型快速生成候选词,再用大模型验证------实现了类似并行的效果,将推理速度提升了 2-3 倍。这是 2023 年之后大规模 LLM 推理优化的重要方向之一。
9.7、Transformer 走出 NLP
2020 年 10 月的某个早晨,当计算机视觉领域的研究者们打开 arXiv,看到了一篇标题奇特的论文:
An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale
(一张图像等于 16×16 个词:用 Transformer 进行大规模图像识别)
作者是谷歌大脑的阿列克谢·多索维茨基(Alexei Dosovitskiy,谷歌大脑高级研究科学家,ViT 论文通讯作者)和他的合作者。论文标题刻意向 2017 年那篇《Attention Is All You Need》致敬------不只是一种学术礼貌,更是一种宣告:同样的逻辑,即将在图像领域重演一次。
他们的做法简单到有些"粗暴":把图像切成一块块 16×1616×1616×16 像素的小方块(patch),把每个 patch 展平成一个向量,当成一个"词",然后把这个"词的序列"直接喂给标准的 Transformer 编码器。没有卷积层,没有任何图像专用的设计,完全就是 NLP 里用的那套架构。他们把这个模型命名为 ViT(Vision Transformer)。
这件事之所以令人震惊,需要理解图像识别领域的背景。自从 AlexNet 在 2012 年引爆深度学习革命,CNN 便以绝对统治者的姿态主宰了计算机视觉整整八年。CNN 的设计有两个核心的"归纳偏置"(Inductive Bias,即模型对数据结构的先验假设):局部性 (图像中相邻像素之间的关联比远距离像素更强),以及平移不变性(一只猫无论出现在画面的哪个角落,都应该被识别为猫)。这两个假设被认为是"理解图像的前提"------卷积操作的整个逻辑,就建立在这两条先验知识上。
Transformer 的 Self-Attention 没有这种偏置。它对所有位置一视同仁------从原则上说,一张图像左上角的像素块和右下角的像素块,对 Transformer 来说是"等距"的。在 ViT 出现之前,研究者们普遍认为,把 Transformer 直接用于图像将会因为"缺乏局部先验"而表现不如 CNN,尤其是在训练数据有限的情况下。
结果让人目瞪口呆:当训练数据足够大(谷歌使用了私有的 JFT-300M 数据集,约 3 亿张图片),ViT 的图像识别准确率全面超越了当时最强的 CNN 模型------不是"稍微好一点",而是以明显差距取胜。
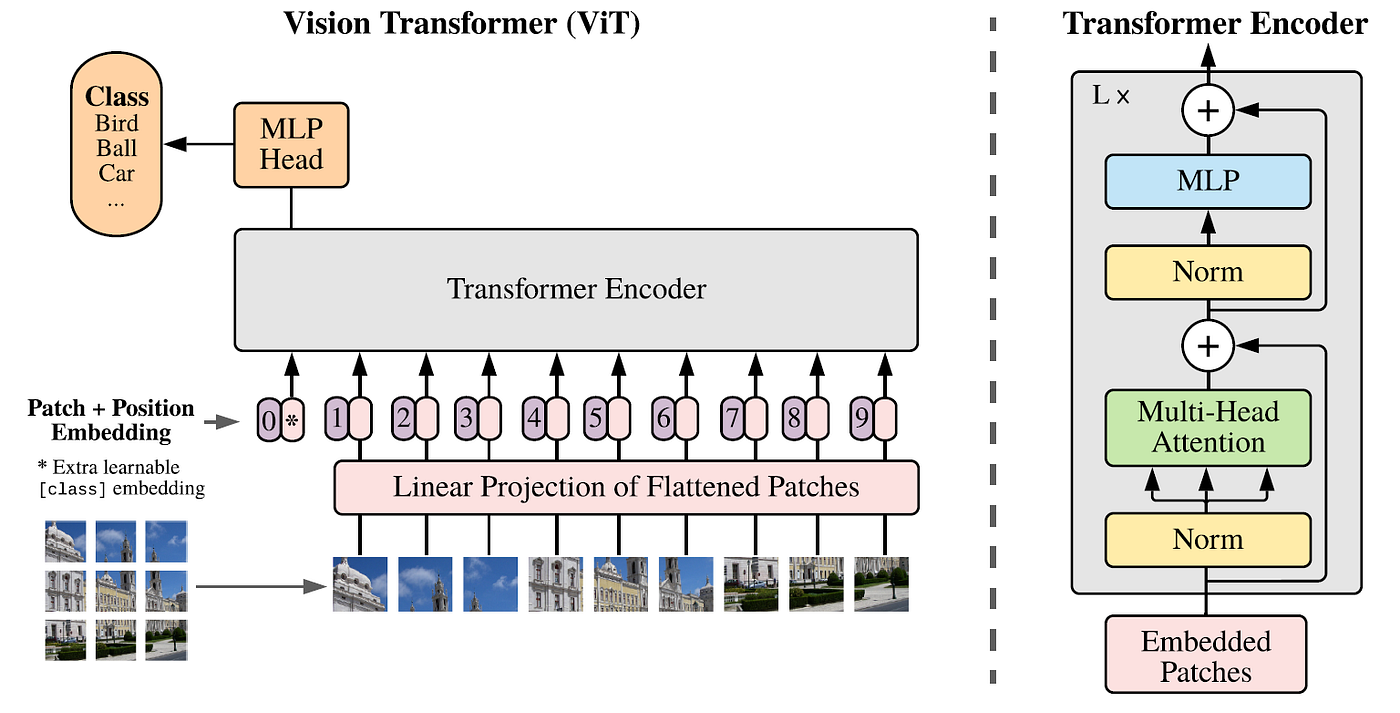
图 9.5:Vision Transformer(ViT)的基本架构------图像被切成 patch 序列,直接送入标准 Transformer 编码器。
这个结果揭示了一条规律,它在 NLP 里已经被 Transformer 演示过一次,现在在视觉领域再次得到验证:当数据和计算资源足够充沛,通用架构的学习能力会超过内置了专用先验的专用架构。
换句话说,归纳偏置不是"必要的知识",而是"在数据不足时的补偿手段"。当数据足够多,模型可以直接从数据里学到局部性、平移不变性,以及 CNN 从未能学到的更复杂的图像结构。
就在 ViT 挑战图像领域的同时,Facebook AI 实验室的研究者们正在把 Transformer 应用于语音。他们的 Wav2Vec 2.0 (2020)证明,用 Transformer 做自监督预训练,只需要极少量的标注语音数据,就能超越当时需要大量标注数据的全监督系统。语音识别领域,也出现了它自己的"BERT 时刻"。OpenAI 随后在 2022 年发布了 Whisper,用 68 万小时的弱标注音频数据训练了一个多语言语音识别系统,其跨噪声环境的鲁棒性远超任何之前的专用方案。
然后是整个科学界的震撼。
2021 年,DeepMind 公告说它解决了困扰生物学家半个世纪的蛋白质折叠问题------根据氨基酸序列预测蛋白质三维结构。AlphaFold 2 在 CASP14 竞赛上的预测精度达到了接近实验室测定的水平,将这个领域的技术水平一步推进了数十年。《Science》杂志将其评为 2021 年年度突破。
AlphaFold 2 的核心组件叫做 Evoformer------一个专为蛋白质数据设计的 Transformer 变体。它的基本直觉是:氨基酸序列,就是一种"语言";蛋白质折叠,就是理解这门"语言"的"语法结构"。Transformer 理解人类语言的能力,经过针对性改造,同样能理解生命的语言。
三件事,三个不同的领域,三年时间。
2017 年的 Transformer 是一个为翻译而生的工具。2021 年,它成了一种通用的智能框架------在图像里,它学会了看;在语音里,它学会了听;在蛋白质里,它开始理解生命。
每一次移植,都在问同一个问题:领域专用的归纳偏置,真的是必要的吗?
每一次,答案都是:在足够规模面前,不是。
这个规律------规模使通用架构战胜专用架构------是接下来整个 AI 发展最重要的主线之一。Transformer 走出 NLP 的详细故事,我们将在下一章更加全面的展开介绍。
9.8、知识自检
读完本章,你应该能做到:
- 用 3 句话向非技术朋友解释 Transformer 解决了 RNN 的什么根本问题,以及它是如何解决的
- 在白板上画出 Transformer 单层编码器的结构草图(包括 Multi-Head Self-Attention、Add&Norm、FFN、Add&Norm 四个模块)
- 解释 Self-Attention 中 Query、Key、Value 三种角色的含义,以及为什么每个词需要同时扮演这三个角色
- 解释为什么计算注意力分数时需要除以 dk\sqrt{d_k}dk (不除会发生什么)
- 解释位置编码的必要性:为什么 Transformer 需要人为注入位置信息,而 RNN 不需要
- 说出 Transformer 的至少 2 个局限,以及这些局限在后来如何推动了新技术的出现
9.9、常见误解
❌ "Transformer 就是在 RNN 上加了注意力机制"
✅ 实际上:Transformer 完全去掉了 RNN,没有任何循环结构。它的核心是 Self-Attention,让序列中任意两个位置直接建立连接,绕开了顺序传递。带注意力的 Seq2Seq(第八章内容)才是"RNN + 注意力",而 Transformer 和 RNN 没有任何关系。
❌ "Self-Attention 就是每个词只关注最重要的一两个词"✅ 实际上:Self-Attention 是"软注意力"------它对序列中的所有位置都计算注意力权重,只是权重有大有小。没有任何位置被完全忽略(权重可以极小,但不等于零)。"只关注最重要的几个词"是硬注意力的做法,Transformer 不这样做。
❌ "多头注意力就是多跑几遍注意力,增加了计算量但没有本质区别"✅ 实际上:多头注意力的每个"头"使用独立的权重矩阵,因此每个头可以学到不同类型的关联模式------一个头关注句法,另一个头关注指代,等等。这不是"重复计算",而是"从多个角度同时观察"。原论文把总维度均分给各个头,所以总计算量与单头大模型相当,但表达能力更强。
❌ "Transformer 处理序列比 RNN 快,所以生成文本也快"✅ 实际上:Transformer 的并行化优势体现在训练 阶段(整个序列可以同时处理)。在推理 (生成文本)阶段,Transformer 仍然是自回归的------生成第 kkk 个词时必须等待前 k−1k-1k−1 个词已经生成。推理阶段的每步都要重新计算所有注意力,实际上在长序列生成时未必比 RNN 快(后来的 KV Cache 优化改善了这一点)。
❌ "位置编码是可训练的参数,会随训练更新"✅ 实际上:Transformer 原论文用的是固定的正弦/余弦位置编码,不是可训练参数,不会随训练更新------它们是按公式计算出来的固定值。后来有些工作(如 BERT)改用了可训练的位置嵌入,但这是原论文之后的设计变体,不是 Vaswani 等人最初的设计。
❌ "Transformer 一次能读无限长的文本"✅ 实际上:由于注意力复杂度是 O(n2)O(n^2)O(n2),序列越长计算量越大、内存消耗越高。早期模型通常有 512 或 1024 词的上下文窗口限制。突破这个限制是近年来(2022-2024)的重要研究方向,通过 FlashAttention、稀疏注意力、RoPE 等技术实现------但即便如此,也仍然有上限。
本章关键词
| 词汇 | 简明定义 |
|---|---|
| Transformer | 2017 年 Vaswani 等人提出的序列建模架构,完全基于注意力机制,去掉循环结构,支持全并行训练 |
| Self-Attention(自注意力) | 序列内部的注意力:每个位置同时作为 Query、Key、Value 参与者,与所有其他位置直接建立连接 |
| Scaled Dot-Product Attention(缩放点积注意力) | Transformer 的基础注意力计算单元:Q·K 点积后除以 dk\sqrt{d_k}dk 再 Softmax,最后对 V 加权求和 |
| Multi-Head Attention(多头注意力) | 同时运行多个独立的注意力头,每个头用独立的 Q/K/V 权重矩阵捕捉不同类型的关联,最后拼接 |
| Positional Encoding(位置编码) | 注入序列位置信息的方式,原论文用正弦/余弦函数,将位置编码向量叠加到词嵌入上 |
| Feed-Forward Network(FFN,前馈网络) | Transformer 每层中逐位置应用的两层全连接网络,负责特征提取和非线性变换 |
| Residual Connection(残差连接) | 每个子层的输出是"输入 + 子层计算结果",提供梯度直路,使深层网络可训练 |
| Layer Normalization(层归一化) | 在每个样本的特征维度上做归一化,Transformer 的稳定训练关键组件 |
| Encoder(编码器) | Transformer 中处理输入序列的部分,由 N 层堆叠的 Self-Attention + FFN 组成 |
| Decoder(解码器) | Transformer 中生成输出序列的部分,包含 Masked Self-Attention + Cross-Attention + FFN |
| Masked Attention(掩码注意力) | 解码器的 Self-Attention 变体,用掩码确保每个位置只能关注之前的位置,保持自回归性质 |
| Cross-Attention(交叉注意力) | 解码器中的编码器-解码器注意力:Query 来自解码器,Key/Value 来自编码器输出 |
| O(n2)O(n^2)O(n2) 复杂度 | Transformer 注意力计算的理论复杂度,序列长度翻倍计算量翻四倍,是长文本处理的核心瓶颈 |
| BLEU 分数 | 机器翻译的标准评测指标,通过比较机器翻译和参考译文的 n-gram 重合度计算,范围 0-100 |
延伸阅读
-
必读 :Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention Is All You Need. NeurIPS 2017.(arXiv:1706.03762)------原始论文,架构图(图 1、图 2)和实验结果是必看内容,代码实现见配套的 Tensor2Tensor 仓库
-
必读 :Alammar, J. (2018). The Illustrated Transformer. jalammar.github.io.------目前网络上最清晰的 Transformer 可视化解读,几乎每个图都对应论文的一个关键组件,用于建立视觉直觉无可取代
-
推荐:Attention is All You Need(论文作者自述),Google AI Blog, 2017.------作者对论文工作的非技术介绍,包含一些设计决策背后的思考
-
推荐 :Rush, A. M. (2018). The Annotated Transformer. harvardnlp.github.io.------用 Python 代码逐行注释论文,工程师理解 Transformer 实现细节的最佳资料之一
-
深入 :Elhage, N., et al. (2021). A Mathematical Framework for Transformer Circuits. Transformer Circuits Thread.------从数学角度分析 Transformer 的内部机制,解释注意力头如何组合实现算法功能,可解释性研究的里程碑
!tip
下一章预告:2017 年的那篇宣言只是开始。三年后,当一批视觉研究者决定"把图片当作词序列",当 DeepMind 用 Transformer 变体破解了五十年的蛋白质折叠难题,整个 AI 领域都在问同一个问题:这究竟是一个好用的 NLP 模型,还是一种通用的智能架构?下一章,我们追溯 Transformer 如何在短短三年内跨越语言、图像、音频与生命科学的边界,颠覆了整个 AI 领域对"领域专用设计"的基本预设------以及这场征服背后,那个让归纳偏置失去意义的更深层逻辑。