文章目录
- [pgvector:PostgreSQL 原生向量搜索扩展](#pgvector:PostgreSQL 原生向量搜索扩展)
pgvector:PostgreSQL 原生向量搜索扩展
pgvector 在 GitHub 上已经拿到 21.2K Star 了。
这个开源工具专门给 PostgreSQL 加了向量相似性搜索能力,向量可以跟业务数据存在同一个库,不需要额外搭向量数据库。
1、这玩意儿是干嘛的
就是在 PostgreSQL 里加向量存储和搜索的能力,不需要单独部署额外的数据库组件。
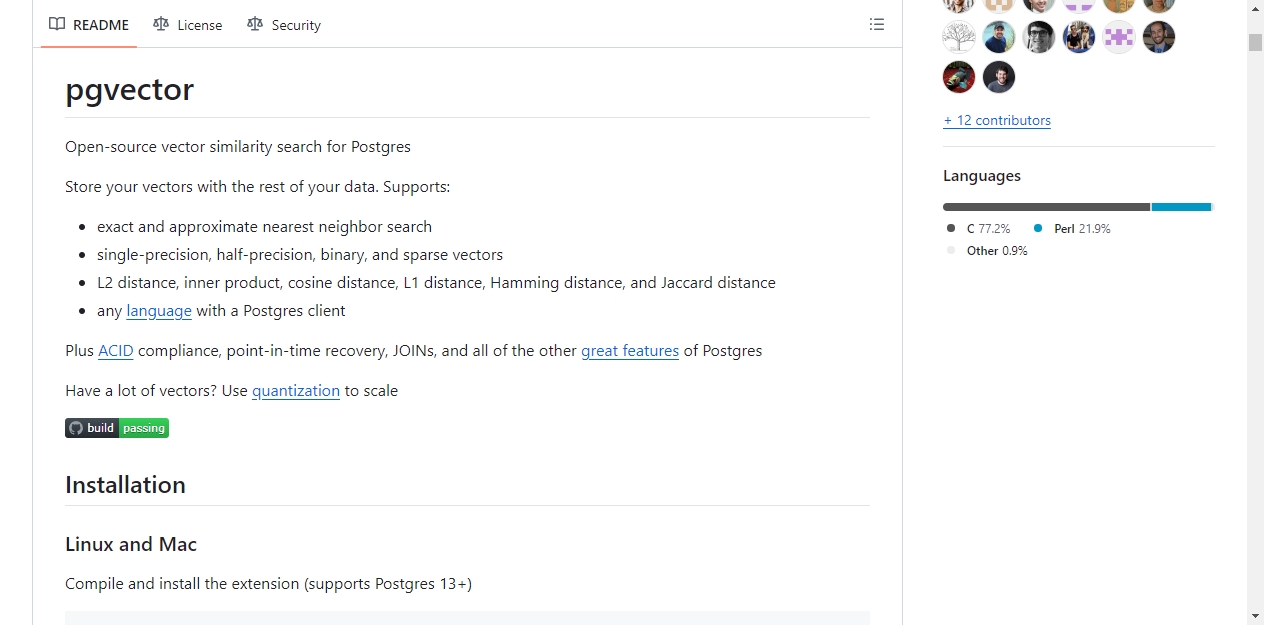
支持精确和近似最近邻搜索,覆盖单精度、半精度、二进制、稀疏四种向量类型,内置L2距离、内积、余弦距离、L1距离、汉明距离、Jaccard距离六种算法。
所有带PostgreSQL客户端的语言都能直接用,还继承PostgreSQL本身的ACID合规、时间点恢复、联表查询等所有特性。向量规模大的场景可以用量化功能做水平扩展。
2、为什么要用它
做过RAG或者向量检索的人都知道,单独搭向量数据库的麻烦:业务数据存在关系库,向量存在向量库,两边要做数据同步,一致性很难保证,查询的时候还要跨库做关联,性能损耗大。
pgvector把向量存储和检索直接集成在PostgreSQL里,向量跟业务表存在同一个库,不需要做数据同步,支持直接跟业务表做联表查询,不用额外维护一套数据库组件,运维成本低很多。
支持HNSW和IVFFlat两种近似索引,内存占用可控,查询性能满足绝大多数生产场景需求。
3、怎么安装使用
Linux和Mac环境直接编译安装:
sh
cd /tmp
git clone --branch v0.8.2 https://github.com/pgvector/pgvector.git
cd pgvector
make
make install也可以用Docker、Homebrew、APT、Yum等方式一键安装,Windows环境可以用nmake编译或者Docker部署。
启用扩展:
sql
CREATE EXTENSION vector;建表存向量:
sql
CREATE TABLE items (id bigserial PRIMARY KEY, embedding vector(3));插入向量:
sql
INSERT INTO items (embedding) VALUES ('[1,2,3]'), ('[4,5,6]');查询最近邻:
sql
SELECT * FROM items ORDER BY embedding <-> '[3,1,2]' LIMIT 5;4、适合哪些场景
- 做RAG系统、需要存向量同时关联业务数据的开发者
- 不想单独维护向量数据库、希望降低架构复杂度的团队
- 已经在用PostgreSQL、需要加向量检索能力的业务场景
开源地址:https://github.com/pgvector/pgvector
L、需要加向量检索能力的业务场景