这篇论文**《Weaving Context Across Images》(也就是我们上次聊到过的 VISC 方法)专注于解决多模态大模型在 多图推理**时遇到的困难。它提出了一种新的推理范式和一个大规模数据集,系统地提升了模型处理多张图片的能力。

具体来说,它解决的问题和解决方案是这样的:
🧩 解决的核心问题
当前的大模型处理单张图片效果很好,但面对多张图片时能力会显著下降。这背后有两个核心挑战:
- 跨图关联的复杂性:多张图片之间可能存在时间、空间、语义等多种复杂关系,模型很难整体理解。
- 视觉信息的不连续性:关键信息碎片化地分散在不同图片中,模型很难准确地将它们串联起来,形成连贯的推理链条。
简单来说,模型在处理多图任务时,就像一个学生面对一堆杂乱的资料,不知道该看哪、按什么顺序看,更不知道如何把不同资料里的信息拼凑出答案。
💡 解决方案:聚焦中心的视觉链(Focus-Centric Visual Chain)
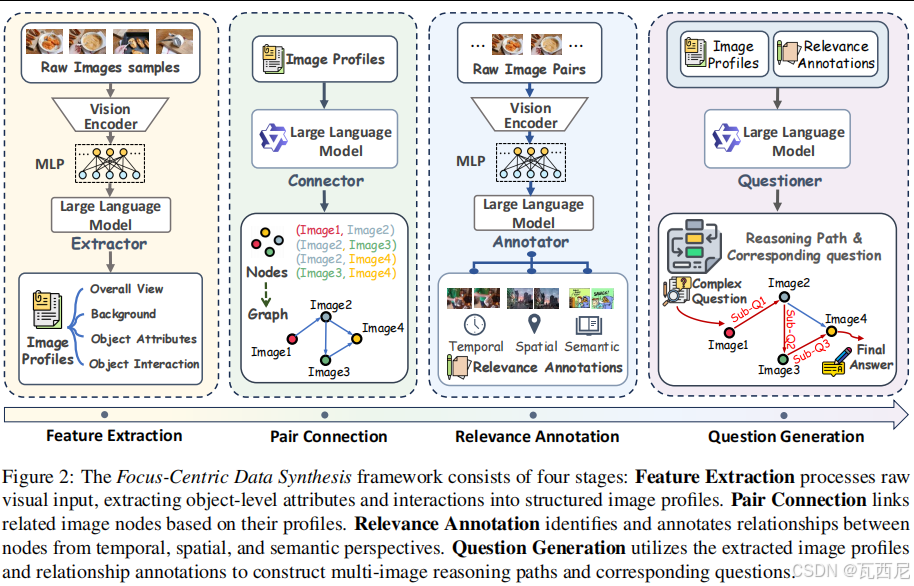
针对上述问题,论文提出了一套完整的解决方案,包括一个推理范式和一套数据合成框架。
1. 核心推理方法:分步聚焦的推理链
它让模型像人类侦探破案一样,将复杂问题分解为一系列简单的子问题,在每一步只聚焦于最相关的少数图片来寻找证据。
这是一个多步推理过程的公式化描述: q i , G i = M ( Q , G , H < i ) q_i, G_i = \mathcal{M}(Q, \mathcal{G}, \mathcal{H}_{< i}) qi,Gi=M(Q,G,H<i)
- q i q_i qi是当前步骤产生的子问题。
- G i G_i Gi是模型为回答 q i q_i qi 而"聚焦"的图片子集。
- M \mathcal{M} M 代表模型,它会结合总问题 Q Q Q、所有图片 G \mathcal{G} G和之前步骤的历史 H < i \mathcal{H}_{< i} H<i来决定当前该关注什么。
通过这种动态的"聚焦-回答问题-再聚焦"的循环,模型能逐步聚合零散的视觉证据,最终推导出复杂问题的答案。
2. 数据制造工厂:自底向上的数据合成框架
为了训练模型的这种能力,需要对应的"思考过程"数据,但这类数据非常稀缺。于是他们设计了一个完全由开源模型驱动的自动化流水线来"制造"数据,这个方法成本低且可靠。这个框架主要分四步:
- 特征提取:用视觉模型为每张图片生成一份细致的"档案",描述其中的物体、背景、动作等,将视觉信息文本化。
- 配对关联:分析所有图片的文本档案,找出存在潜在关联的图片对(Pair Connection),比如包含相同物体,或描绘了相关事件。
- 关系标注 :对上一步找到的图片对进行关系判断,并用三种标签进行注释:
- 时间关系:图片间有先后顺序。
- 空间关系:图片间存在几何或位置上的联系。
- 语义关系:图片间有主题、逻辑或因果等抽象联系。
- 问题生成:这是最关键的一步。基于前面建立起来的"图片-关联-关系"网络,先生成一系列相互关联的子问题,再将这些子问题组合成一个需要多步推理才能解决的复杂总问题,同时生成了完整的推理链条。
3. 最终产物:VISC-150K 数据集
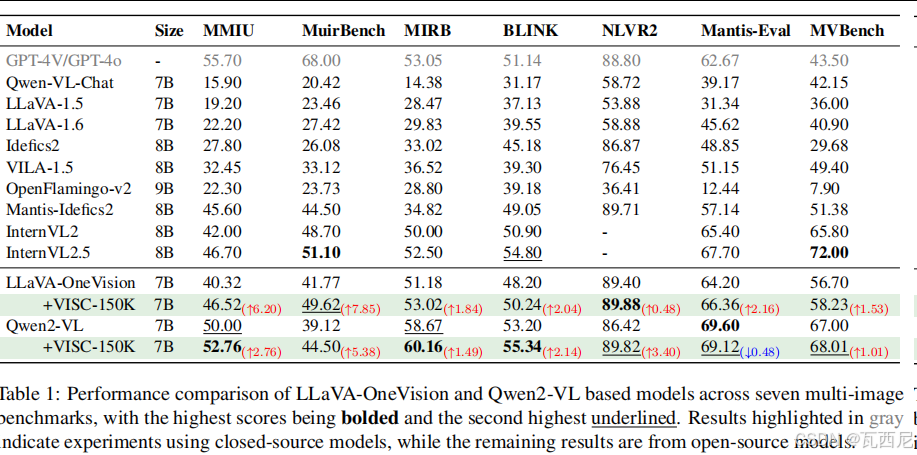
利用上述框架,他们构建了一个包含15万条高质量多图推理样本的数据集(VISC-150K)。实验证明,用这个数据集进行微调,能在各种多图任务上稳定提升不同架构模型的性能,并且没有损害模型的通用能力(如单图理解)。