目录
- [Differentiable Semantic ID for Generative Recommendation](#Differentiable Semantic ID for Generative Recommendation)
-
- 论文元信息
- 核心创新点
-
- [1. 问题识别:生成式推荐中的目标不匹配(Objective Mismatch)](#1. 问题识别:生成式推荐中的目标不匹配(Objective Mismatch))
- [2. 核心方法:DIGER框架](#2. 核心方法:DIGER框架)
-
- 组件1:DRIL(可微分语义ID探索式学习)
-
- [1.1 Gumbel-Softmax采样](#1.1 Gumbel-Softmax采样)
- [1.2 前向传播(硬选择)](#1.2 前向传播(硬选择))
- [1.3 反向传播(软更新)](#1.3 反向传播(软更新))
- [组件2:Uncertainty Decay(不确定性衰减)](#组件2:Uncertainty Decay(不确定性衰减))
-
- [策略1:Standard Deviation Uncertainty Decay (SDUD)](#策略1:Standard Deviation Uncertainty Decay (SDUD))
- [策略2:Frequency-based Uncertainty Decay (FrqUD)](#策略2:Frequency-based Uncertainty Decay (FrqUD))
- [3. 训练目标](#3. 训练目标)
- 实验设置
- 实验结果
-
- [RQ1:可微分SID vs 传统两阶段方法](#RQ1:可微分SID vs 传统两阶段方法)
- RQ2:与SOTA方法对比
- RQ3:消融实验(组件重要性分析)
- RQ4:超参数敏感性分析
- RQ5:Codebook容量和SID长度影响
- RQ6:语义ID动态分析
-
- [6.1 SID漂移分析](#6.1 SID漂移分析)
- [6.2 训练-推理一致性(Train-Inference Agreement)](#6.2 训练-推理一致性(Train-Inference Agreement))
- [6.3 代码利用率分布](#6.3 代码利用率分布)
- 作者方法/思想的详细分析
-
- 核心思想:从Two-Stage到End-to-End
- 技术深度分析
-
- [1. 为什么Gumbel-Softmax有效?](#1. 为什么Gumbel-Softmax有效?)
- [2. 不确定性衰减的设计哲学](#2. 不确定性衰减的设计哲学)
- [3. 码本崩溃(Codebook Collapse)的根源分析](#3. 码本崩溃(Codebook Collapse)的根源分析)
- 论文局限性
- 未来工作方向
- 总结
Differentiable Semantic ID for Generative Recommendation
论文元信息
- 标题: Differentiable Semantic ID for Generative Recommendation (DIGER)
- 作者: Junchen Fu, Xuri Ge, Alexandros Karatzoglou, Ioannis Arapakis, Suzan Verberne, Joemon M. Jose, Zhaochun Ren
- 作者单位 :
- Junchen Fu, Joemon M. Jose: University of Glasgow(格拉斯哥大学),英国
- Xuri Ge: Shandong University(山东大学),中国济南
- Alexandros Karatzoglou: Amazon,西班牙巴塞罗那
- Ioannis Arapakis: Telefónica Scientific Research,西班牙巴塞罗那
- Suzan Verberne, Zhaochun Ren(通讯作者): Leiden University(莱顿大学),荷兰莱顿
- 发表时间: 2026年1月27日首次提交arXiv,2026年4月14日最后更新(v3)
- 论文链接: https://arxiv.org/abs/2601.19711
- 会议/期刊 : 2026 SIGIR (Full Paper)
- 源代码: https://github.com/junchen-fu/DIGER
核心创新点
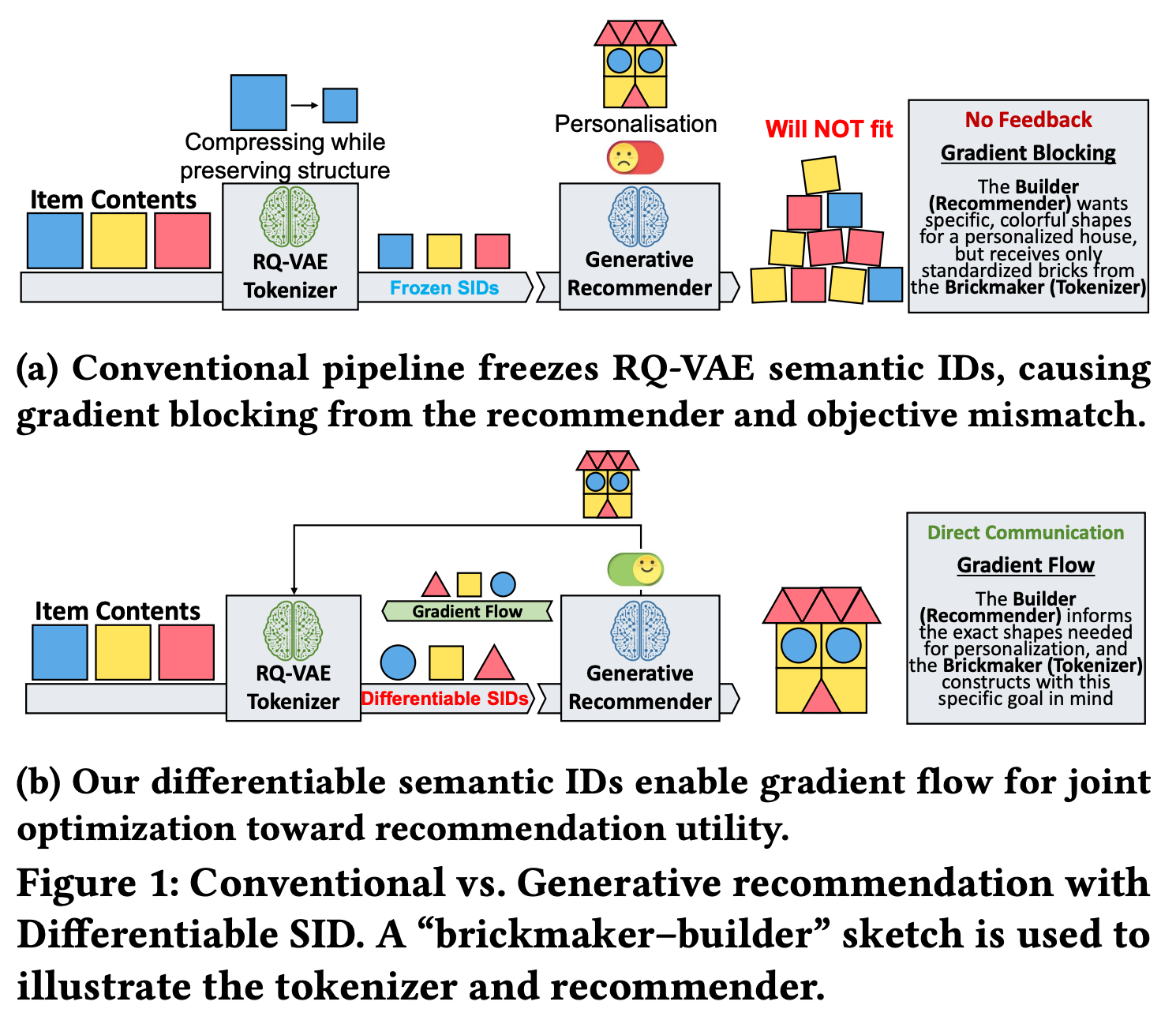
1. 问题识别:生成式推荐中的目标不匹配(Objective Mismatch)
现有方法的局限(两阶段训练范式):
-
第一阶段:使用RQ-VAE为每个物品学习离散语义ID(Semantic ID, SID)
- 优化目标:内容重建损失
- 训练后冻结SID,作为固定索引
-
第二阶段:训练生成式推荐器预测下一个SID
- 优化目标:推荐损失(预测用户下一个感兴趣的物品)
核心问题:
- 推荐损失的梯度无法反向传播到SID学习过程
- SID是为重建任务 优化的,而非为推荐任务优化
- 导致目标不匹配,限制了个性化和偏好感知的表示学习
理论支撑(论文附录A):
- 定理A.1:两阶段方法在受限参数空间Φ ⊆ A上优化,端到端方法在完整空间Φ上优化,因此端到端性能理论上不劣于两阶段
- 定理A.2 :在目标不匹配情况下,两阶段方法的次优性可以任意大
2. 核心方法:DIGER框架
DIGER(Di fferentiable Semantic ID for Ge nerative Recommendation)包含两大核心组件:
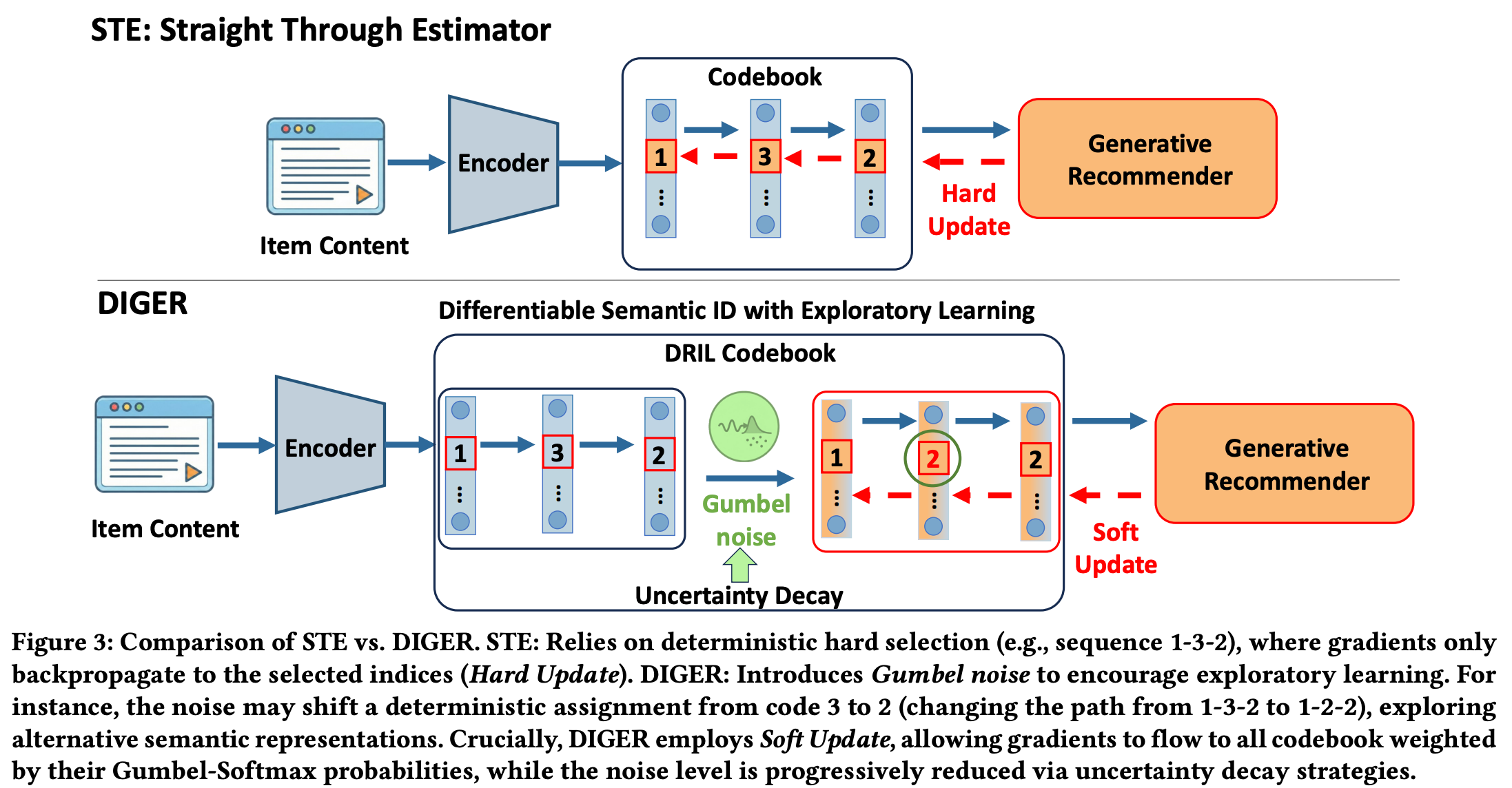
组件1:DRIL(可微分语义ID探索式学习)
目标:通过注入Gumbel噪声实现可微分的SID学习,避免代码崩溃(codebook collapse)
关键技术:
1.1 Gumbel-Softmax采样
对于物品v的第j个量化位置,计算其残差表示r_v,j与codebook中所有代码e_i的相似度:
ℓ_v,j,i = sim(r_v,j, e_i)添加Gumbel噪声并计算软概率分布:
ỹ_v,j,i = exp((ℓ_v,j,i + g_v,j,i)/τ) / Σ_k exp((ℓ_v,j,k + g_v,j,k)/τ)
其中:g_v,j,i ~ Gumbel(0,1) 是Gumbel噪声
τ 是温度参数(控制分布尖锐度)1.2 前向传播(硬选择)
c_v,j = argmax_i(ℓ_v,j,i + g_v,j,i)- 用于生成离散SID索引
- 保持与推理时的一致性
1.3 反向传播(软更新)
ē_v,j = Σ_i ỹ_v,j,i * e_i- 梯度通过软概率分布更新codebook
- 所有代码都能接收梯度信号
- 关键创新:避免了Straight-Through Estimator (STE)的梯度阻断问题
为什么选择Gumbel噪声?
- 更符合分类采样的概率特性(Gumbel分布是极值分布)
- 指数加权机制使高相似度代码自然获得更高采样概率
- 实验验证:Gumbel噪声(R@10=0.0683)显著优于高斯噪声(R@10=0.0620)
熵正则化的理论依据(定理A.3):
- 有效代码数 Eff(q) = exp(H(q)),其中H(q)是分配分布的熵
- 最大化熵H(q)可最大化有效代码利用率
- Gumbel噪声注入增加分配熵,提高代码覆盖率
组件2:Uncertainty Decay(不确定性衰减)
动机:平衡探索(exploration)与利用(exploitation)
- 训练早期:需要探索多样代码,防止过早收敛到局部最优
- 训练后期:需要减少噪声,使训练时SID与推理时保持一致
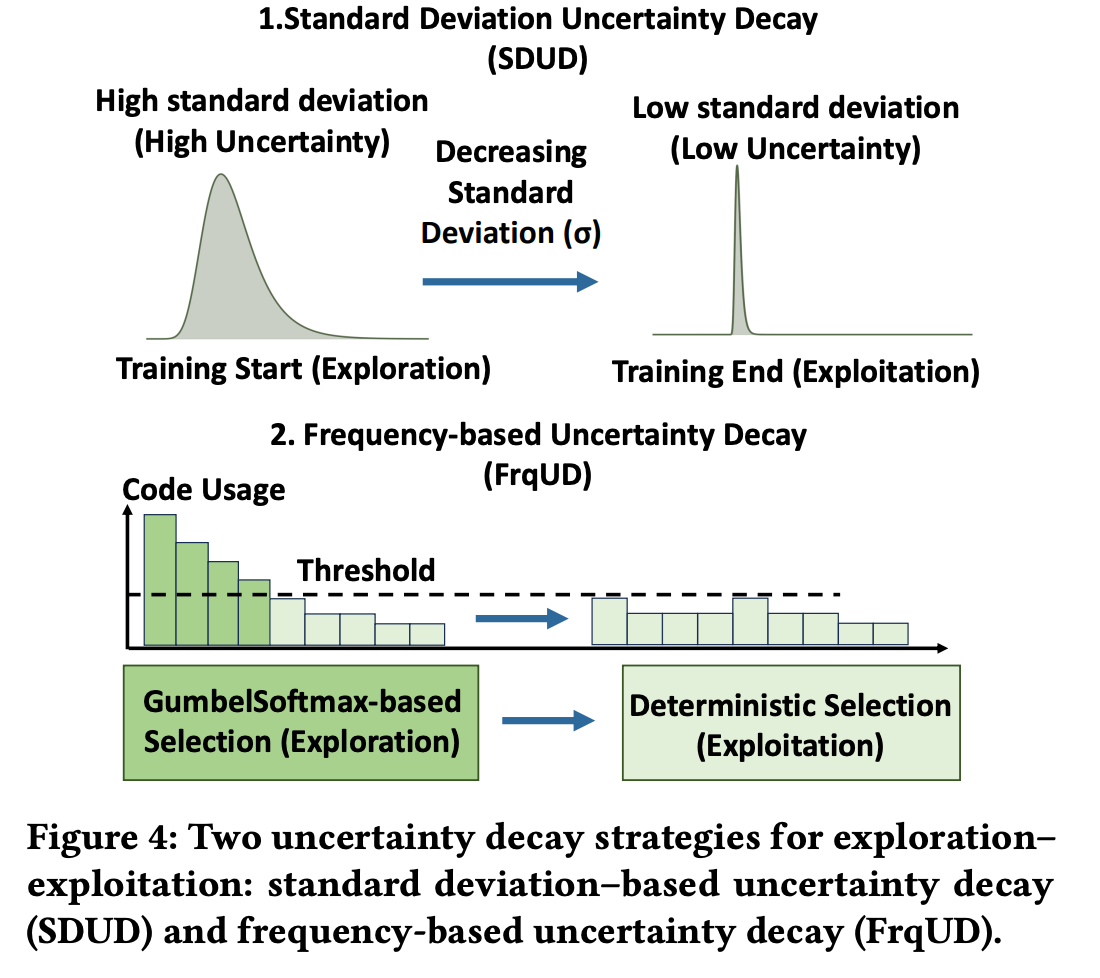
策略1:Standard Deviation Uncertainty Decay (SDUD)
核心设计:
引入辅助优化目标:
L_σ = L_gen / (2(σ+λ)²) + log(σ+λ)其中:
- L_gen:生成式推荐损失
- σ:可学习的噪声标准差参数
- λ:超参数,控制噪声归零的时机
闭式最优解(附录B推导):
∂L_σ/∂σ = 0 ⇒ σ* = max{0, √L_gen - λ}关键机制:
- 随着训练进行,L_gen下降 ⇒ σ*自动减小
- 当√L_gen ≈ λ时,σ* → 0,噪声自然归零
- 实现从探索到利用的自动平滑过渡
- 无需手动设计退火schedule
策略2:Frequency-based Uncertainty Decay (FrqUD)
核心思想:基于代码使用频率选择性应用噪声
实现步骤:
-
计算代码使用频率(使用指数移动平均EMA平滑):
f^(e)_i ← β·f^(e-1)_i + (1-β)·f̂^(e)_i 其中:f̂^(e)_i 是当前epoch代码i的使用频率 β 是平滑系数(如0.9) -
定义热代码阈值:
γ = r/K 其中:r 是阈值比例(如1.5) K 是codebook大小 -
识别过度使用的代码:
I_high = {i | f^(e)_i > γ} (热代码集合) I_low = {1,...,K} \ I_high (冷代码集合) -
差异化处理:
- 对于i ∈ I_high(过度使用的代码):应用Gumbel噪声,促进探索其他代码
- 对于i ∈ I_low(使用不足的代码):使用确定性分配,保持稳定性
设计优势:
- 针对性解决代码不平衡问题
- 从训练开始就保持高训练-推理一致性(仅对热代码应用噪声)
- 实验结果 :FrqUD通常效果最好,初期一致性85%,后期95%
3. 训练目标
联合优化损失:
L = L_gen + L_vq + L_recon其中:
-
L_gen:下一个SID的自回归生成损失(主导项)
L_gen = -Σ log P(SID_next | user_history) -
L_vq:向量量化损失(稳定优化)
L_vq = ||sg[z] - e||² + β||z - sg[e]||² 其中:sg[·] 表示stop-gradient z 是编码器输出 e 是量化后的codebook向量 -
L_recon:重建损失(防止表示偏移)
L_recon = ||x - decoder(e)||²
关键差异:
- DIGER省略了RQ-VAE的完整解码器
- 直接在量化表示上评估重建损失
- 减少计算开销,聚焦推荐任务
实验设置
数据集
| 数据集 | 用户数 | 物品数 | 交互数 | 平均序列长度 | 稀疏度 |
|---|---|---|---|---|---|
| B-Shop | 22,363 | 12,101 | 198,502 | 8.88 | 99.93% |
| I-Shop | 24,772 | 9,922 | 206,153 | 8.32 | 99.92% |
| Yelp | 30,431 | 20,033 | 304,524 | 10.01 | 99.95% |
数据处理:
- 使用LLaMA-7B生成物品的文本内容表示
- 过滤交互少于5次的用户和物品
- 采用Leave-one-out评估协议:最后一个交互作为测试集,倒数第二个作为验证集
- 全库排序(非采样负例),更贴近真实应用场景
评估指标
- Recall@10:前10个推荐中命中真实物品的比例
- NDCG@10:归一化折扣累积增益(考虑排序位置的质量)
Baseline方法
-
传统协同过滤:
- MF (Matrix Factorization)
- LightGCN(图神经网络)
-
序列推荐:
- SASRec(Self-Attention)
- BERT4Rec(双向Transformer)
-
生成式推荐:
- P5-CID(LLM-based生成式推荐)
- LETTER(引入协同信号的生成式推荐)
- TIGER(两阶段SID + 生成式推荐,论文baseline)
- ETEGRec(端到端生成式推荐,但需2倍训练时间)
-
朴素可微分方法:
- STE(Straight-Through Estimator,硬阈值 + 直通梯度)
实验结果
RQ1:可微分SID vs 传统两阶段方法
B-Shop数据集:
| 方法 | Recall@10 | NDCG@10 | 相对提升 |
|---|---|---|---|
| Two-Stage (TIGER) | 0.0610 | 0.0331 | - |
| STE(朴素可微) | 0.0134 ❌ | 0.0067 ❌ | -78.0% / -79.8% |
| DIGER (FrqUD) | 0.0683 ✅ | 0.0372 ✅ | +11.9% / +12.4% |
| DIGER (SDUD) | 0.0657 | 0.0361 | +7.7% / +9.1% |
I-Shop数据集:
| 方法 | Recall@10 | NDCG@10 | 相对提升 |
|---|---|---|---|
| Two-Stage | 0.1058 | 0.0797 | - |
| STE | 0.0554 ❌ | 0.0360 ❌ | -47.6% / -54.8% |
| DIGER (FrqUD) | 0.1138 ✅ | 0.0844 ✅ | +7.6% / +5.9% |
| DIGER (SDUD) | 0.1099 | 0.0828 | +3.9% / +3.9% |
Yelp数据集:
| 方法 | Recall@10 | NDCG@10 | 相对提升 |
|---|---|---|---|
| Two-Stage | 0.0398 | 0.0209 | - |
| STE | 0.0084 ❌ | 0.0041 ❌ | -78.9% / -80.4% |
| DIGER (FrqUD) | 0.0432 ✅ | 0.0227 ✅ | +8.5% / +8.6% |
关键发现:
- STE严重失败:在所有数据集上性能暴跌50-80%,验证了代码崩溃问题的严重性
- DIGER显著优于两阶段方法:R@10提升7.6%-11.9%,N@10提升5.9%-12.4%
- 不确定性衰减是必要的:FrqUD和SDUD都能带来稳定提升
- FrqUD通常优于SDUD:在B-Shop和I-Shop上FrqUD最优
RQ2:与SOTA方法对比
B-Shop数据集完整对比:
| 类别 | 方法 | Recall@10 | NDCG@10 |
|---|---|---|---|
| 传统CF | MF | 0.0474 | 0.0191 |
| LightGCN | 0.0511 | 0.0260 | |
| 序列推荐 | SASRec | 0.0588 | 0.0313 |
| BERT4Rec | 0.0347 | 0.0170 | |
| 生成式 | P5-CID | 0.0597 | 0.0347 |
| LETTER | 0.0672 | 0.0364 | |
| TIGER | 0.0610 | 0.0331 | |
| ETEGRec | 0.0615 | 0.0335 | |
| DIGER(本文) | 0.0683* | 0.0372* |
统计显著性:* 表示p<0.05(t-test)
I-Shop数据集对比:
| 方法 | Recall@10 | NDCG@10 |
|---|---|---|
| LETTER(最强baseline) | 0.1122 | 0.0831 |
| DIGER | 0.1138 (+1.4%) | 0.0844 (+1.6%) |
Yelp数据集对比:
| 方法 | Recall@10 | NDCG@10 |
|---|---|---|
| LETTER | 0.0426 | 0.0231 |
| DIGER | 0.0432 (+1.4%) | 0.0227 |
关键观察:
- DIGER在B-Shop和I-Shop上达到SOTA
- 在Yelp上R@10最佳,N@10与LETTER相当(0.0227 vs 0.0231)
- 显著优于ETEGRec(另一种端到端对齐方法),且ETEGRec需要2倍训练时间
- LETTER通过引入协同信号(SASRec嵌入)在Yelp的N@10上略优,但DIGER是纯基于内容的方法
RQ3:消融实验(组件重要性分析)
B-Shop数据集上的消融实验:
| 变体 | Recall@10 | NDCG@10 | 相对变化 | 关键洞察 |
|---|---|---|---|---|
| Two-Stage | 0.0610 | 0.0331 | baseline | 传统方法 |
| DIGER (FrqUD) | 0.0683 | 0.0372 | - | 完整模型 |
| DIGER (SDUD) | 0.0679 | 0.0365 | -0.6% / -1.9% | FrqUD略优 |
| -w/o UD | 0.0679 | 0.0365 | -0.6% / -1.9% | UD带来稳定提升 |
| -w/o Gumbel Noise | 0.0283 ❌ | 0.0141 ❌ | -58.6% / -62.1% | Gumbel噪声至关重要 |
| -w/o Soft Update | 0.0650 | 0.0354 | -4.8% / -4.8% | 软更新优于STE |
| -w Gumbel Tau Annealing | 0.0654 | 0.0348 | -4.2% / -6.5% | 温度退火不如不确定性衰减 |
| -w Gaussian Noise | 0.0620 | 0.0327 | -9.2% / -12.1% | Gumbel优于高斯 |
核心发现:
- Gumbel噪声是DIGER的核心:移除后性能暴跌58-62%
- 软更新显著优于硬阈值(STE):DIGER不带噪声(0.0650)仍远超STE(0.0134)
- 高斯噪声不如Gumbel噪声:验证了分类采样特性的重要性
- 不确定性衰减带来1-2%的稳定提升
- 温度退火(Tau Annealing)不如不确定性衰减:说明动态调整噪声强度比调整分布形状更有效
RQ4:超参数敏感性分析
SDUD的λ参数影响(B-Shop数据集):
| λ | Recall@10 | NDCG@10 |
|---|---|---|
| 1.0 | 0.0671 | 0.0362 |
| 1.2 | 0.0676 | 0.0367 |
| 1.4 | 0.0679 | 0.0365 |
| 1.8 | 0.0673 | 0.0361 |
| 2.0 | 0.0668 | 0.0359 |
FrqUD的r参数影响(B-Shop数据集):
| r | Recall@10 | NDCG@10 |
|---|---|---|
| 1.0 | 0.0675 | 0.0366 |
| 1.5 | 0.0683 | 0.0372 |
| 2.0 | 0.0680 | 0.0370 |
| 2.5 | 0.0677 | 0.0368 |
| 3.0 | 0.0672 | 0.0365 |
关键观察:
- 性能对λ和r变化鲁棒:在合理范围内性能波动<2%
- 极端值有轻微负面影响 :
- λ过小:后期仍有过多探索,影响收敛
- λ过大:早期探索不足,陷入局部最优
- r过小/过大:削弱探索-利用平衡
- 实践建议:λ ∈ 1.2, 1.8,r ∈ 1.5, 2.5
RQ5:Codebook容量和SID长度影响
Codebook大小K的影响(B-Shop数据集):
| K | Recall@10 | NDCG@10 |
|---|---|---|
| 128 | 0.0655 | 0.0352 |
| 256 | 0.0683 | 0.0372 |
| 512 | 0.0660 | 0.0359 |
SID长度m的影响(B-Shop数据集):
| m | Recall@10 | NDCG@10 |
|---|---|---|
| 2 | 0.0566 | 0.0301 |
| 3 | 0.0683 | 0.0372 |
| 4 | 0.0673 | 0.0373 |
发现:
- K=256, m=3是最优配置
- 过小的K或m限制表达能力:K=128时R@10下降4.1%,m=2时下降17.1%
- 过大的K或m增加优化难度但提升有限:K=512时反而下降3.4%,m=4时仅提升0.3%
RQ6:语义ID动态分析
6.1 SID漂移分析
增量漂移(Incremental SID Drift) - 单个epoch内改变SID的物品比例:
| 方法 | 初期漂移 | 中期漂移 | 后期漂移 | 特征 |
|---|---|---|---|---|
| STE | >40% ❌ | 崩溃 | 崩溃 | 早期剧烈漂移导致不稳定 |
| DIGER (w/o UD) | <5% | <5% | <5% | 漂移过小,优化不足 |
| DIGER (SDUD) | ~15% | ~12% | ~8% | 渐进式衰减 |
| DIGER (FrqUD) | ~12% | ~10% | ~8% | 平衡稳定性和适应性 |
累积漂移(Cumulative SID Drift) - 从初始SID改变的物品累积比例:
| 方法 | 累积漂移 | 评价 |
|---|---|---|
| DIGER (FrqUD) | ~35% | 允许必要的SID优化,达到最佳性能 |
| DIGER (w/o UD) | <15% | 优化不足 |
| STE | 不可用 | 早期崩溃 |
6.2 训练-推理一致性(Train-Inference Agreement)
| 方法 | 初期一致性 | 后期一致性 | 趋势 |
|---|---|---|---|
| STE | 100% | 100% | 始终确定性(但性能差) |
| DIGER (w/o UD) | ~60% | ~60% | 持续不匹配 |
| DIGER (SDUD) | ~60% | ~95% | 逐步提升 |
| DIGER (FrqUD) | ~85% | ~95% | 始终高一致性 |
关键洞察:
- FrqUD从一开始就保持高一致性(~85%),因为仅对热代码应用噪声
- SDUD通过逐步减小σ实现一致性提升(从60%到95%)
- 高一致性对应更好的推荐性能
6.3 代码利用率分布
16×16热图分析(256个代码的使用概率可视化):
第1层量化(所有方法):
- 相对均匀的分布
- 表明第一层量化较为稳定
第2-3层量化:
-
STE:严重不平衡 ❌
- 大量白色区域(未使用代码)
- 深色聚集(少数代码被过度使用)
- Code Balance ~0.40(早期)
-
DIGER (w/o UD):轻度不平衡
- Code Balance ~0.75
-
DIGER (FrqUD/SDUD):最均衡分布 ✅
- 几乎所有代码都被使用
- Code Balance ~0.92
量化指标:
- Code Balance = 有效使用的代码数 / 总代码数
- 有效使用定义:使用频率 > 阈值(如1/K)
作者方法/思想的详细分析
核心思想:从Two-Stage到End-to-End
传统Two-Stage范式的问题:
阶段1: 学习语义ID(SID)
输入:物品内容特征
输出:离散SID(固定索引)
优化目标:重建损失 L_recon
阶段2: 训练推荐器
输入:用户历史SID序列
输出:下一个SID预测
优化目标:推荐损失 L_gen
问题:∂L_gen/∂SID = 0(梯度阻断)DIGER的端到端范式:
联合优化:
L = L_gen + L_vq + L_recon
关键创新:
1. 使L_gen的梯度能够反向传播到SID学习
2. 通过Gumbel-Softmax实现离散到连续的松弛
3. 通过不确定性衰减平衡探索与利用技术深度分析
1. 为什么Gumbel-Softmax有效?
数学原理:
Gumbel-Max技巧用于从分类分布中采样:
c = argmax_i (log π_i + g_i) 其中 g_i ~ Gumbel(0,1)Gumbel-Softmax是其可微分近似:
p_i = exp((log π_i + g_i)/τ) / Σ_j exp((log π_j + g_j)/τ)为什么用于生成式推荐?
- 保持离散性:前向传播使用argmax,得到离散SID
- 提供梯度:反向传播使用softmax,所有代码接收梯度
- 探索机制:Gumbel噪声引入随机性,防止过早收敛
- 理论保证:当τ→0时,Gumbel-Softmax收敛到离散分布
2. 不确定性衰减的设计哲学
SDUD的自适应机制:
L_σ = L_gen / (2(σ+λ)²) + log(σ+λ)这是贝叶斯视角下的不确定性估计:
- 第一项:数据拟合项(σ越小,L_gen权重越大)
- 第二项:正则化项(防止σ→0过快)
闭式解的推导:
∂L_σ/∂σ = -L_gen / (σ+λ)³ + 1/(σ+λ) = 0
⇒ L_gen = (σ+λ)²
⇒ σ* = √L_gen - λ物理意义:
- 训练初期:L_gen大 ⇒ σ*大 ⇒ 强探索
- 训练后期:L_gen小 ⇒ σ*小 ⇒ 弱探索
- 收敛时:√L_gen ≈ λ ⇒ σ* ≈ 0 ⇒ 确定性分配
FrqUD的频率感知机制:
对于代码i:
if f_i > γ (过度使用):
应用Gumbel噪声 → 促进探索其他代码
else:
确定性分配 → 保持稳定性设计优势:
- 针对性:仅对热代码应用噪声,冷代码保持稳定
- 高效性:从训练开始就高一致性(~85%)
- 理论支撑:熵最大化(定理A.3)
3. 码本崩溃(Codebook Collapse)的根源分析
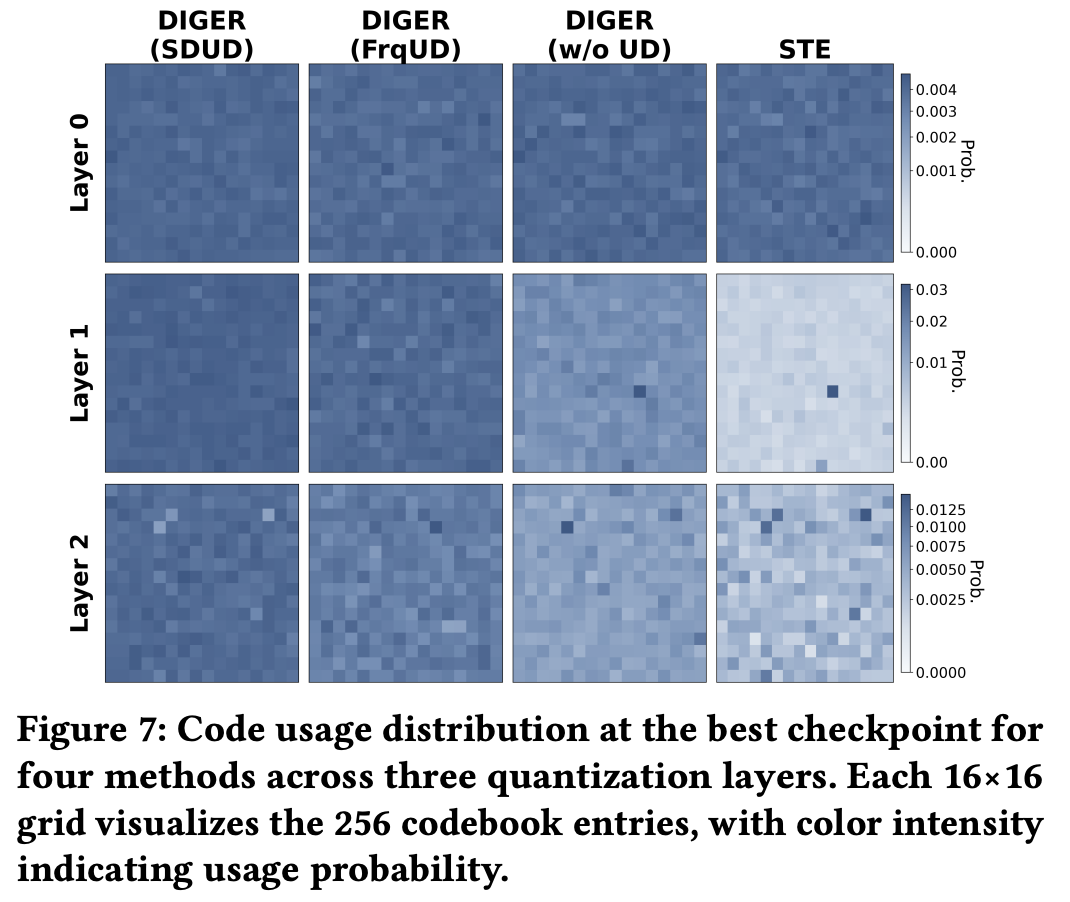
现象:
- 大量代码从未被使用(白色区域)
- 少数代码被过度使用(深色聚集)
- 训练不稳定,性能严重下降
根本原因:
-
早期确定性分配:
STE: c = argmax_i(ℓ_i) (硬阈值,无梯度)- 一旦某个代码被选中,由于无梯度,其他代码难以竞争
- 导致"富者愈富"效应
-
梯度阻断:
∂L/∂codebook = 0 (STE的梯度为0)- codebook无法根据推荐损失更新
- 限制了表示学习能力
-
缺乏探索机制:
- 确定性分配缺乏随机性
- 无法跳出局部最优
DIGER的解决方案:
-
Gumbel噪声引入随机性:
c = argmax_i(ℓ_i + g_i) 其中 g_i ~ Gumbel(0,1)- 即使ℓ_i不是最大,仍有机会被选中(通过噪声)
- 增加代码探索
-
软更新提供梯度:
ē = Σ_i p_i·e_i 其中 p_i = softmax((ℓ_i+g_i)/τ)- 所有代码接收梯度
- 实现端到端优化
-
不确定性衰减平衡探索与利用:
- 早期:强探索(高噪声)
- 后期:强利用(低噪声)
论文局限性
论文中明确提到的局限性
-
仅使用文本内容表示:
- DIGER采用纯文本方式(LLaMA-7B生成的嵌入)
- LETTER通过引入协同信号(SASRec嵌入)在Yelp的N@10上略优
- 未来方向:探索混合协同信号与可微分SID的方法
-
仅关注物品侧表示:
- 当前工作聚焦于物品的语义ID学习
- 未来方向:扩展到用户侧或交互级别的离散结构学习
-
未集成代码多样性损失:
- 为隔离可微分SID的效果,本文未使用显式的代码多样性正则化
- 未来方向:结合多样性损失可能进一步提升代码利用率
从实验结果推断的潜在局限
-
计算开销:
- 论文未详细报告训练时间
- Gumbel采样和软更新会增加计算成本
- 与ETEGRec的2倍训练时间对比表明效率是需要考虑的因素
-
超参数调优复杂度:
- 尽管声称对λ和r鲁棒,但仍需网格搜索
- 不同数据集可能需要不同的最优配置
- 新用户需要一定的调参经验
-
在极度稀疏数据上的表现:
- 在Yelp(稀疏度99.95%)的N@10上略逊于LETTER(0.0227 vs 0.0231)
- 可能表明在某些数据特性下,纯语义方法有天花板
- 协同信号在极度稀疏场景下仍有独特价值
-
代码长度和容量的限制:
- m=3, K=256是固定配置
- 对于更大规模数据集(百万级物品),可扩展性未验证
- 可能需要层次化或自适应的SID结构
-
冷启动问题未明确讨论:
- 新物品如何快速获得高质量的可微分SID?
- 是否需要额外的快速适应机制?
未来工作方向
短期改进方向(1-2年)
-
优化效率:
- 研究更高效的Gumbel采样实现(如低秩近似)
- 探索混合精度训练(FP16/BF16)
- 分析FrqUD的计算瓶颈(EMA更新的并行化)
-
自适应不确定性衰减:
- 当前SDUD和FrqUD需要手动调参(λ和r)
- 开发自适应衰减策略(如基于验证集性能动态调整)
- 研究元学习方法快速确定最优超参数
-
多模态扩展:
- 除文本外整合图像、视频、音频等模态
- 探索多模态融合的可微分SID学习
- 设计模态特定的Gumbel噪声策略
中期研究方向(2-3年)
-
用户侧可微分ID:
- 学习用户的离散表示(类似物品的SID)
- 实现用户-物品联合离散空间建模
- 探索用户SID与物品SID的对齐机制
-
层次化语义ID:
- 当前RQ-VAE是平面结构(m层独立量化)
- 探索树状或图状的层次化SID
- 研究层次化结构对可微分优化的影响
-
可解释性增强:
- 分析学到的SID的语义含义
- 可视化不同代码对应的物品特征
- 设计用户可理解的推荐解释
-
与LLM的深度集成:
- 探索可微分SID作为LLM输入的prompt(离散token)
- 研究LLM反馈对SID学习的影响
- 设计LLM指导的SID优化机制
长期愿景方向(3-5年)
-
统一检索与排序:
- 可微分SID作为统一框架的基础
- 端到端优化整个推荐管道(召回 + 排序 + 重排)
- 研究多阶段联合优化的理论保证
-
跨域迁移学习:
- 研究在不同领域间迁移可微分SID
- 元学习快速适应新领域的SID空间
- 探索零样本/少样本推荐场景
-
在线学习和增量更新:
- 当前是离线批量训练
- 开发在线更新SID的方法以应对物品/用户动态变化
- 研究流式数据下的可微分SID学习
-
理论保证的深化:
- 深化附录A的理论分析
- 研究可微分SID的收敛性和泛化界
- 分析Gumbel噪声的理论性质(如探索效率)
-
大规模工业应用:
- 在百万/千万级物品库上验证
- 研究分布式训练策略(数据并行 + 模型并行)
- 与现有推荐系统的集成方案(如与双塔模型结合)
开放性问题
-
最优噪声类型:
- Gumbel优于高斯,但是否存在更优的噪声分布?
- 是否可以学习数据驱动的噪声分布?
-
探索-利用的通用原则:
- 不确定性衰减的最佳时机是否有通用规律?
- 不同数据集是否需要不同的衰减策略?
-
SID的表达能力上界:
- 离散SID相比连续嵌入的本质优势和劣势是什么?
- 理论上SID的最优长度m和codebook大小K如何确定?
-
冷启动问题:
- 新物品如何快速获得高质量的可微分SID?
- 是否可以设计快速适应机制(如few-shot SID learning)?
-
与生成式检索的统一:
- 生成式推荐和生成式检索本质上有何异同?
- DIGER的思想能否直接迁移到信息检索领域?
总结
DIGER通过创新的Gumbel噪声注入 和不确定性衰减策略,首次实现了生成式推荐中语义ID与推荐目标的端到端联合优化。核心贡献在于:
理论贡献
- 证明了两阶段训练的次优性(定理A.1和A.2)
- 建立了不确定性衰减与探索-利用平衡的理论联系(定理A.3)
技术贡献
- 设计了稳定的可微分SID学习框架(DRIL)
- 提出了两种有效的不确定性衰减策略(SDUD和FrqUD)
- 解决了代码崩溃问题(Code Balance从0.40提升到0.92)
实验贡献
- 在三个数据集上达到SOTA或接近SOTA性能
- B-Shop: R@10 0.0683 (+11.9% vs baseline)
- I-Shop: R@10 0.1138 (+7.6% vs baseline)
- Yelp: R@10 0.0432 (+8.5% vs baseline)
- 深入剖析了SID动态演化、训练-推理一致性和代码利用率
- 验证了Gumbel噪声的关键作用(移除后性能暴跌58-62%)
方法论贡献
- 为生成式推荐系统开辟了端到端优化的新范式
- 提供了代码开源(https://github.com/junchen-fu/DIGER),促进社区研究
实践价值
- 超参数对λ和r鲁棒,易于应用
- 性能提升显著且稳定(在多个数据集上一致优于baseline)
- 为工业界大规模生成式推荐系统提供了理论和技术基础
DIGER为生成式推荐乃至整个信息检索领域提供了重要的方法论创新,未来在效率优化、多模态扩展、大规模应用等方面仍有广阔的研究和应用空间