前言
想象你在玩一个4×4的迷宫游戏,出口在右下角,你不知道哪条路是通的,也不知道哪块是陷阱。你只能一步步试:走对了就记下来"这个方向能前进",踩陷阱了就记下来"这个方向不能走",最终摸索出一条从起点到出口的最优路线。这个"试错-记忆-优化"的过程,就是Q-Learning的核心思想。
1989年,Christopher J.C.H. Watkins在他的博士论文中首次提出了Q-Learning算法,1992年这篇与Peter Dayan合作的论文,给出了Q-Learning严格的收敛性证明,彻底奠定了它作为无模型强化学习基石的地位。在此之前,强化学习算法要么需要精确的环境模型,要么缺乏理论保证,而Q-Learning的出现,让智能体可以在完全未知的环境中,通过与环境的交互自动学习最优策略,开启了强化学习的新时代。
论文信息
- 标题:Q-Learning
- 会议:Machine Learning, 1992 (Vol.8, pp.279-292)
- 单位:University of Cambridge;University of Edinburgh
- 代码:github.com/dennybritz/reinforcement-learning/tree/master/TD
- 论文:https://www.cs.rhul.ac.uk/\~chrisw/new_thesis.pdf
1 问题背景:智能体如何在未知环境中做决策?
Q-Learning要解决的是马尔可夫决策过程(MDP)下的最优决策问题。简单来说,就是一个智能体在一个满足马尔可夫性的环境中,通过选择不同的动作获得奖励,最终目标是最大化长期累积奖励。
1.1 马尔可夫决策过程的五要素
一个标准的MDP由以下五个部分组成:
- 状态空间X:环境中所有可能的状态集合,比如迷宫中的每个格子就是一个状态。
- 动作空间A:智能体在每个状态下可以执行的所有动作集合,比如上下左右四个方向。
- 转移概率Pxya:在状态x执行动作a后,转移到状态y的概率。在确定性环境中,这个概率要么是0要么是1;在随机性环境中,可能有多个可能的下一个状态。
- 奖励函数Rx(a):在状态x执行动作a后,智能体获得的即时奖励。比如走到出口奖励+100,踩陷阱奖励-10,走普通格子奖励-1(鼓励尽快到达终点)。
- 折扣因子γ:0<γ<1,用来衡量未来奖励的价值。γ越接近1,智能体越看重长期奖励;γ越接近0,智能体越看重即时奖励。
通俗解释:折扣因子就像"金钱的时间价值"------今天的100块比明天的100块更值钱,明天的100块比后天的100块更值钱。在强化学习中,我们也认为"现在拿到的奖励比未来拿到的奖励更有价值"。
1.2 什么是最优策略?
我们的目标是找到一个策略π,它告诉智能体在每个状态x应该执行哪个动作a=π(x),使得智能体获得的长期折扣奖励的期望最大。
为了衡量一个策略的好坏,我们定义两个核心函数:
-
状态值函数V^π(x) :在状态x遵循策略π,能获得的长期折扣奖励的期望。
Vπ(x)≡Rx(π(x))+γ∑yPxyπ(x)Vπ(y)V^{\pi}(x) \equiv R_{x}(\pi(x))+\gamma \sum_{y} P_{x y}\\pi(x) V^{\pi}(y)Vπ(x)≡Rx(π(x))+γy∑Pxyπ(x)Vπ(y)- Rx(π(x))R_x(\pi(x))Rx(π(x)):在状态x执行策略π推荐的动作获得的即时奖励
- Pxyπ(x)P_{xy}\\pi(x)Pxyπ(x):执行该动作后转移到状态y的概率
- Vπ(y)V^\pi(y)Vπ(y):状态y的长期价值
-
动作值函数Q^π(x,a) :在状态x先执行动作a,然后遵循策略π,能获得的长期折扣奖励的期望。
Qπ(x,a)=Rx(a)+γ∑yPxyaVπ(y)Q^{\pi}(x, a)=R_{x}(a)+\gamma \sum_{y} P_{x y}a V^{\pi}(y)Qπ(x,a)=Rx(a)+γy∑PxyaVπ(y)- Rx(a)R_x(a)Rx(a):在状态x执行动作a获得的即时奖励
- PxyaP_{xy}aPxya:执行动作a后转移到状态y的概率
- Vπ(y)V^\pi(y)Vπ(y):状态y的长期价值
通俗解释:V值告诉你"这个状态好不好",Q值告诉你"在这个状态做这个动作好不好"。显然,Q值比V值更有用,因为它直接告诉我们应该选哪个动作。
最优策略π就是在每个状态x,选择Q值最大的那个动作:
π∗(x)≡argmaxaQ∗(x,a)\pi^{*}(x) \equiv argmax_{a} Q^{*}(x, a)π∗(x)≡argmaxaQ∗(x,a)
其中Q(x,a)是最优动作值函数,也就是所有可能的策略中,Q^π(x,a)的最大值。
【表格1 值函数与动作值函数对比,出处:本文绘制】
| 函数类型 | 定义 | 作用 |
|---|---|---|
| 状态值函数V^π(x) | 状态x遵循策略π的长期奖励期望 | 衡量状态的好坏 |
| 动作值函数Q^π(x,a) | 状态x做动作a后遵循策略π的长期奖励期望 | 衡量动作的好坏 |
| 最优状态值函数V*(x) | 所有策略中V^π(x)的最大值 | 状态能达到的最好价值 |
| 最优动作值函数Q*(x,a) | 所有策略中Q^π(x,a)的最大值 | 动作能达到的最好价值 |
2 Q-Learning的核心算法
Q-Learning是一种无模型的时序差分(TD)学习算法。"无模型"意味着它不需要知道环境的转移概率Pxya和奖励函数Rx(a),只需要通过与环境的交互,收集(状态、动作、奖励、下一个状态)这样的样本,就能直接学习最优Q值。
2.1 Q-Learning的更新公式
Q-Learning的核心就是下面这个简单的更新公式:
Qn(x,a)={(1−αn)Qn−1(x,a)+αnrn+γVn−1(yn)ifx=xnanda=an,Qn−1(x,a)otherwise,Q_{n}(x, a)= \begin{cases}\left(1-\alpha_{n}\right) Q_{n-1}(x, a)+\alpha_{n}\leftr_{n}+\\gamma V_{n-1}\\left(y_{n}\\right)\\right & if x=x_{n} and a=a_{n}, \\ Q_{n-1}(x, a) & otherwise, \end{cases}Qn(x,a)={(1−αn)Qn−1(x,a)+αnrn+γVn−1(yn)Qn−1(x,a)ifx=xnanda=an,otherwise,
其中
Vn−1(y)≡maxb{Qn−1(y,b)}V_{n-1}(y) \equiv max {b}\left\{Q{n-1}(y, b)\right\}Vn−1(y)≡maxb{Qn−1(y,b)}
公式符号全解释:
- Qn(x,a)Q_n(x,a)Qn(x,a):第n次更新后,状态x动作a的Q值
- αn\alpha_nαn:第n次更新的学习率,满足0≤αn<10 \leq \alpha_n < 10≤αn<1。它决定了新经验对旧Q值的修正幅度:α越大,越相信这次的新经验;α越小,越保留之前的旧经验。
- Qn−1(x,a)Q_{n-1}(x,a)Qn−1(x,a):第n-1次更新后的旧Q值,也就是智能体之前对"在x做a能得到多少奖励"的估计
- rnr_nrn:第n次交互中,智能体执行动作a后获得的即时奖励
- γ\gammaγ:折扣因子,0<γ<1,衡量未来奖励的价值
- Vn−1(yn)V_{n-1}(y_n)Vn−1(yn):第n-1次更新后,下一个状态yny_nyn的最优值函数,也就是yny_nyn所有动作中最大的Q值。这是Q-Learning最关键的一步:它假设在下一个状态会选择最优的动作。
- xn,an,ynx_n, a_n, y_nxn,an,yn:第n次交互的当前状态、执行的动作、转移到的下一个状态
通俗解释:这个公式其实就是一个"经验修正公式"。你之前对"在x做a能得到多少奖励"有一个估计(旧Q值),现在你实际做了a,得到了即时奖励r_n,还看到了下一个状态y_n的最好情况(V_{n-1}(y_n))。你用这个实际的结果,来修正你之前的估计。学习率α_n就是"修正的幅度":如果α=0.1,意味着你保留90%的旧经验,只吸收10%的新经验;如果α=0.5,意味着新旧经验各占一半。
2.2 Q-Learning的完整流程
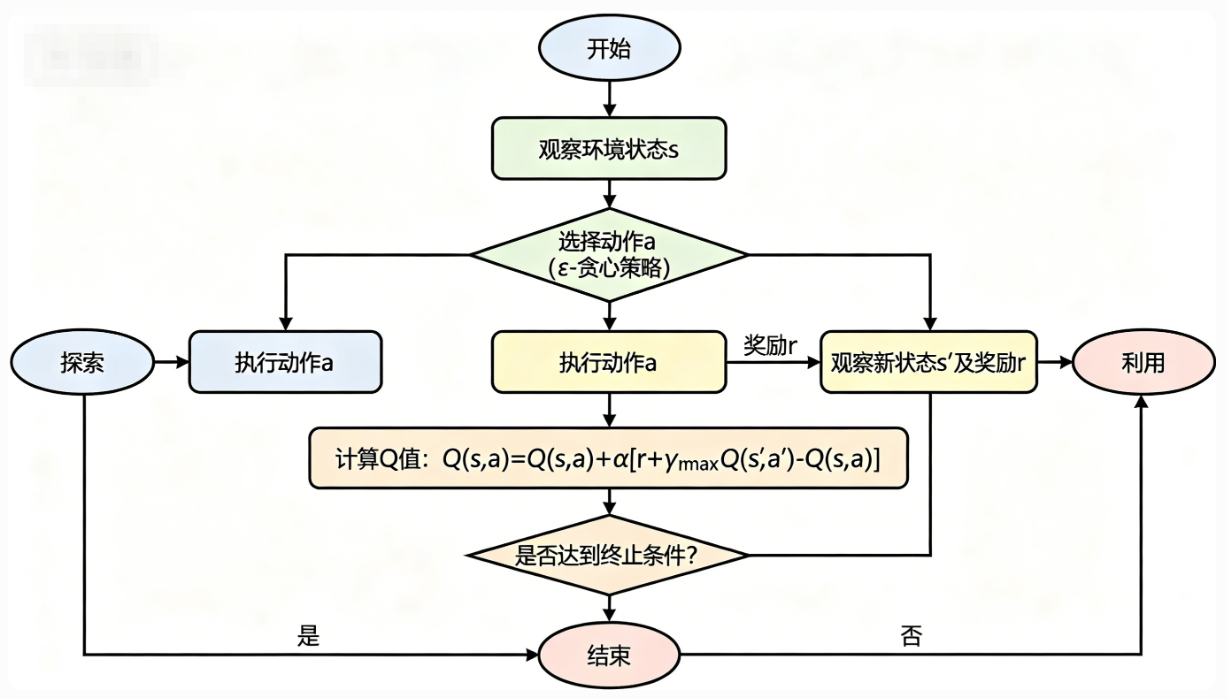
Q-Learning的执行步骤非常简单,总结起来就是:
- 初始化Q表:创建一个二维数组QXA,所有元素初始化为0或者一个小的随机数。Q表的行是状态,列是动作,每个元素就是对应状态动作对的Q值。
- 循环每个episode:一个episode就是从初始状态到终止状态的一次完整交互(比如从迷宫起点走到出口)。
- 初始化当前状态x:比如迷宫的起点。
- 循环每个时间步 :
a. 选择动作a :通常使用ε-贪婪策略:以ε的概率随机选择一个动作(探索),以1-ε的概率选择当前状态Q值最大的动作(利用)。
b. 执行动作a :获得即时奖励r和下一个状态y。
c. 更新Q值 :使用上面的更新公式,更新Qxa。
d. 状态转移 :将当前状态x设置为y。
e. 终止条件:如果y是终止状态(比如出口),结束这个episode。 - 收敛判断:当Q表的变化小于某个阈值,或者达到最大迭代次数,算法结束。此时Q表中每个状态的最大Q值对应的动作,就是最优策略。
有趣案例:用Q-Learning训练AI玩贪吃蛇。我们把贪吃蛇的游戏界面分成网格,每个网格的状态(蛇头位置、蛇身位置、食物位置)作为状态空间,动作是上下左右四个方向。奖励函数设置为:吃到食物+10,撞到墙或自己-100,其他情况-0.1(鼓励尽快吃到食物)。通过不断训练,AI会逐渐学会"绕开自己,朝着食物方向移动"的最优策略,最终能玩到很高的分数。
3 收敛定理:为什么Q-Learning一定能学到最优策略?
很多人会问:Q-Learning只是一个简单的试错算法,为什么它最终一定能学到最优的Q值?这篇论文的核心贡献,就是给出了Q-Learning的收敛性证明,保证了在满足一定条件下,Qn(x,a)会以概率1收敛到Q*(x,a)。
3.1 收敛定理的完整表述
定理 :给定有界奖励∣rn∣≤R|r_n| \leq R∣rn∣≤R,学习率0≤αn<10 \leq \alpha_n < 10≤αn<1,且满足以下两个条件:
∑i=1∞αni(x,a)=∞,∑i=1∞αni(x,a)2<∞,∀x,a\sum_{i=1}^{\infty} \alpha_{n^{i}(x, a)}=\infty, \quad \sum_{i=1}^{\infty}\left\\alpha_{n}\^{i}(x, a)\\right^{2}<\infty, \quad \forall x, ai=1∑∞αni(x,a)=∞,i=1∑∞αni(x,a)2<∞,∀x,a
其中ni(x,a)n^i(x,a)ni(x,a)表示第i次在状态x执行动作a的迭代次数。则当n→∞n \to \inftyn→∞时,Qn(x,a)→Q∗(x,a)Q_n(x,a) \to Q^*(x,a)Qn(x,a)→Q∗(x,a)对所有x,a成立,且概率为1。
条件解释:
- 奖励有界:这个条件非常容易满足,几乎所有实际问题中的奖励都是有界的。比如游戏中的分数最多是1000分,最少是-1000分。
- 学习率的和为无穷大 :∑i=1∞αni(x,a)=∞\sum_{i=1}^{\infty} \alpha_{n^i(x,a)} = \infty∑i=1∞αni(x,a)=∞。这个条件意味着,对于每个状态动作对(x,a),智能体必须无限次地尝试它。如果某个动作从来没被试过,智能体永远不知道它的好坏。同时,学习率的和为无穷大,保证了智能体永远不会停止学习,总能从新经验中学习。
- 学习率的平方和为有限 :∑i=1∞αni(x,a)2<∞\sum_{i=1}^{\infty} \\alpha_{n\^i(x,a)}^2 < \infty∑i=1∞αni(x,a)2<∞。这个条件意味着,学习率最终会降到0。这样,当智能体学到足够多的经验后,旧经验的影响会逐渐消失,Q值会收敛到一个固定的值,不会永远波动。
通俗解释:这两个学习率条件就像你学骑自行车:
- 一开始你摔得很多,学得很快(学习率大),这对应"学习率的和为无穷大"------你必须不断尝试才能学会。
- 后来你越来越熟练,摔得少了,学得也慢了(学习率逐渐变小),这对应"学习率的平方和为有限"------最终你会完全学会,不需要再调整了。
如果学习率一直很大,你会永远在调整,永远学不会;如果学习率太快降到0,你还没学会就停止了。
一个常用的满足这两个条件的学习率序列是:αn=1n\alpha_n = \frac{1}{n}αn=n1,也就是第n次更新时学习率为1/n。
3.2 收敛证明的核心思路:动作重放过程(ARP)
论文的证明非常巧妙,它构造了一个人工的马尔可夫过程,叫做动作重放过程(Action-Replay Process, ARP),然后证明了两个关键引理:
- 引理A:Qn(x,a)正好是ARP在状态<x,n>、动作a的最优值函数。
- 引理B:当n→∞时,ARP的转移概率和奖励函数会收敛到真实MDP的转移概率和奖励函数。
结合这两个引理,ARP的最优值函数Qn自然会收敛到真实MDP的最优值函数Q*。
3.2.1 什么是动作重放过程?
论文用了一个非常形象的卡片游戏来解释ARP:
想象你把每一次交互(x,a,y,r,α)都写在一张卡片上,所有卡片按照时间顺序堆成一个无限高的栈。最底部的卡片(编号0)写着初始Q值Q0(x,a)。
ARP的状态是<x,n>,表示"在第n张卡片的高度,状态是x"。当你在<x,n>做动作a时:
- 从栈顶(第n张卡片)往下找,找到第一张状态是x、动作是a的卡片,假设它的编号是t。
- 抛一个 biased 硬币,正面朝上的概率是αt,反面朝上的概率是1-αt。
- 如果正面朝上:你获得奖励rt,然后转移到状态<yt, t-1>,其中yt是这次交互的下一个状态。然后扔掉卡片t。
- 如果反面朝上:扔掉卡片t,继续往下找下一张状态是x、动作是a的卡片。
- 如果找到最底部的卡片0,游戏结束,获得奖励Q0(x,a)。
这个ARP过程完全是由Q-Learning的历史交互数据构造出来的,它和真实的MDP没有直接关系。但论文证明了,Qn(x,a)正好是ARP在状态<x,n>、动作a的最优值函数。这个证明用数学归纳法就能完成,非常简洁。
3.2.2 ARP为什么会收敛到真实MDP?
引理B证明了,当n→∞时,ARP的转移概率和奖励函数会收敛到真实MDP的转移概率和奖励函数。这个证明基于随机逼近理论:
- 对于奖励函数,ARP的期望奖励是对历史奖励的加权平均,权重是学习率α。只要学习率满足那两个条件,这个加权平均会收敛到真实的期望奖励Rx(a)。
- 对于转移概率,ARP的转移概率是对历史转移的加权平均,同样会收敛到真实的转移概率Pxya。
因此,当n足够大时,ARP和真实MDP几乎是一样的,它们的最优值函数也几乎是一样的。这就证明了Qn(x,a)→Q*(x,a)。
4 Q-Learning的扩展
论文还讨论了Q-Learning的两个重要扩展,让它能应用到更多场景中。
4.1 非折扣吸收马尔可夫过程(γ=1)
在之前的讨论中,我们假设折扣因子γ<1,这样长期奖励是有界的。但在一些有吸收状态的问题中(比如迷宫游戏,找到出口就结束了),即使γ=1,长期奖励也是有界的,因为过程最终会终止。
论文证明了,对于有吸收状态的MDP,即使γ=1,只要满足之前的收敛条件,Q-Learning仍然会收敛到最优Q值。这是因为吸收状态会终止过程,总奖励不会无限大。
4.2 多Q值更新
在标准的Q-Learning中,每次迭代只能更新一个Q值(也就是当前状态动作对的Q值)。但在实际应用中,我们可以每次迭代更新多个Q值,这样可以加快学习速度。
论文证明了,只要每个状态动作对的学习率仍然满足那两个条件,即使每次更新多个Q值,收敛性仍然保持不变。这个扩展非常重要,它为后续的批量Q-Learning、经验回放等技术奠定了理论基础。
5 核心代码实现:Q-Learning解决4×4迷宫问题
下面是一个完整的Python代码,实现Q-Learning解决4×4迷宫问题。迷宫的起点在左上角(0,0),出口在右下角(3,3),陷阱在(1,1)和(2,2)。
python
import numpy as np
import random
# 迷宫定义:0=普通格子,1=陷阱,2=出口
maze = np.array([
[0, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 2]
])
# 动作空间:上下左右
actions = ['up', 'down', 'left', 'right']
action_to_idx = {'up':0, 'down':1, 'left':2, 'right':3}
idx_to_action = {0:'up', 1:'down', 2:'left', 3:'right'}
# 状态空间:4×4=16个状态
n_states = 4 * 4
n_actions = 4
# 初始化Q表
Q = np.zeros((n_states, n_actions))
# 超参数
alpha = 0.1 # 学习率
gamma = 0.9 # 折扣因子
epsilon = 0.1 # ε-贪婪策略的探索率
n_episodes = 1000 # 训练轮数
def state_to_idx(state):
"""将(x,y)坐标转换为状态索引"""
x, y = state
return x * 4 + y
def idx_to_state(idx):
"""将状态索引转换为(x,y)坐标"""
x = idx // 4
y = idx % 4
return (x, y)
def get_next_state(state, action):
"""根据当前状态和动作,返回下一个状态和奖励"""
x, y = state
if action == 'up':
x = max(x-1, 0)
elif action == 'down':
x = min(x+1, 3)
elif action == 'left':
y = max(y-1, 0)
elif action == 'right':
y = min(y+1, 3)
next_state = (x, y)
cell_type = maze[x][y]
if cell_type == 1: # 陷阱
reward = -100
done = True
elif cell_type == 2: # 出口
reward = 100
done = True
else: # 普通格子
reward = -1
done = False
return next_state, reward, done
# 训练Q-Learning
for episode in range(n_episodes):
# 初始化状态:起点(0,0)
state = (0, 0)
done = False
while not done:
state_idx = state_to_idx(state)
# ε-贪婪策略选择动作
if random.uniform(0, 1) < epsilon:
# 探索:随机选择动作
action_idx = random.randint(0, n_actions-1)
else:
# 利用:选择Q值最大的动作
action_idx = np.argmax(Q[state_idx])
action = idx_to_action[action_idx]
# 执行动作,获得下一个状态和奖励
next_state, reward, done = get_next_state(state, action)
next_state_idx = state_to_idx(next_state)
# 更新Q值
Q[state_idx][action_idx] = (1 - alpha) * Q[state_idx][action_idx] + \
alpha * (reward + gamma * np.max(Q[next_state_idx]))
# 状态转移
state = next_state
# 每100轮打印一次进度
if (episode + 1) % 100 == 0:
print(f"Episode {episode+1}/{n_episodes} completed")
# 测试训练好的策略
print("\n训练完成,测试最优策略:")
state = (0, 0)
path = [state]
done = False
while not done:
state_idx = state_to_idx(state)
action_idx = np.argmax(Q[state_idx])
action = idx_to_action[action_idx]
next_state, reward, done = get_next_state(state, action)
path.append(next_state)
state = next_state
print("最优路径:", path)
print("最终奖励:", reward)代码解释:
- 我们把迷宫的每个格子映射为一个状态索引,方便Q表的存储。
- 使用ε-贪婪策略平衡探索和利用:10%的概率随机探索,90%的概率选择当前最优动作。
- 奖励函数设置为:普通格子-1(鼓励尽快到达终点),陷阱-100(惩罚),出口+100(奖励)。
- 训练1000轮后,Q表会收敛到最优值,此时我们可以通过选择每个状态的最大Q值对应的动作,得到最优路径。
运行代码后,你会看到AI找到了一条从起点到出口的最优路径,避开了所有陷阱。
6 Q-Learning的经典应用
Q-Learning及其变种已经被广泛应用到各个领域,下面是几个最经典的案例:
- Atari游戏AI:DeepMind在2013年提出的DQN(深度Q网络),就是用深度神经网络代替Q表,解决了高维状态空间的问题。DQN在49款Atari游戏中,有29款超过了人类专业玩家的水平,开启了深度强化学习的时代。
- 机器人控制:用Q-Learning训练机器人走路、避障、抓取物体。比如波士顿动力的机器人,就用到了强化学习技术来优化运动控制策略。
- 自动驾驶:用Q-Learning优化车辆的决策策略,比如变道、跟车、超车等。通过在仿真环境中大量训练,AI可以学会在复杂路况下做出安全的决策。
- 游戏AI:很多游戏中的NPC(非玩家角色)都用了Q-Learning的变种。比如《王者荣耀》中的AI,会根据游戏局势选择最优的技能释放和走位策略。
- 资源调度:用Q-Learning优化云计算中的资源调度、电网中的电力调度、交通中的信号控制等问题,提高资源利用率和系统效率。
7 总结与后续发展
7.1 论文的核心贡献
这篇论文是强化学习领域的里程碑式工作,它的核心贡献在于:
- 提出了Q-Learning算法:一种简单、高效、无模型的强化学习算法,不需要知道环境的转移概率和奖励函数,只需要通过交互数据就能学习。
- 给出了严格的收敛证明:证明了在满足一定条件下,Q-Learning会以概率1收敛到最优动作值函数,为算法提供了坚实的理论基础。
- 扩展了Q-Learning的应用范围:证明了Q-Learning可以应用到非折扣吸收马尔可夫过程,并且支持多Q值更新,为后续的改进奠定了基础。
7.2 后续发展
Q-Learning的出现,开启了强化学习的新时代,后续的很多先进算法都是在它的基础上发展而来的:
- Sarsa:同策略的Q-Learning,更安全,适合在线学习。
- DQN:用深度神经网络近似Q值,解决了高维状态空间问题。
- Double DQN:解决了DQN的Q值过估计问题,提高了性能。
- Dueling DQN:分离状态值和优势值,让网络更容易学习。
- Rainbow:结合了多种DQN改进,达到了Atari游戏的SOTA性能。
- PPO:基于策略梯度的算法,现在是强化学习的主流算法之一,但它的思想仍然受到Q-Learning的影响。
直到今天,Q-Learning仍然是强化学习入门的必学算法,它的核心思想------通过试错学习最优策略------已经深入到强化学习的各个分支。这篇1992年的论文,虽然已经过去了30多年,但它的理论价值和实用价值仍然不可估量。