前言
还记得小时候守在电视机前玩《打砖块》《太空侵略者》的日子吗?你可能花了好几个星期才练到能通关,但在2013年,DeepMind的科学家们创造了一个AI,它只需要看着游戏屏幕的像素,就能自己学会玩这些游戏,而且在好几个游戏上玩得比人类专家还好。
这个AI就是深度Q网络(Deep Q-Network, DQN),它第一次成功地将深度神经网络与强化学习结合起来,解决了"从高维感官输入直接学习控制策略"这个困扰了人工智能界几十年的难题。这篇论文的发表,直接开启了深度强化学习的黄金时代,为后来的AlphaGo、ChatGPT等里程碑式的成果奠定了基础。
论文信息
- 标题:Playing Atari with Deep Reinforcement Learning
- 会议:NIPS 2013 Deep Learning Workshop
- 单位:DeepMind Technologies
- 代码:github.com/keras-rl/keras-rl/tree/master/examples/atari
- 论文:https://arxiv.org/pdf/1312.5602.pdf
1 问题背景:当深度学习遇上强化学习
在DQN出现之前,强化学习和深度学习是两个几乎完全独立的领域:
- 强化学习擅长解决序列决策问题,但只能处理低维、离散的状态空间,比如4×4的迷宫。如果状态是210×160的游戏屏幕(有超过10^10000种可能的状态),传统的Q表方法根本无法存储。
- 深度学习擅长从高维数据中提取特征,比如从图像中识别物体,但需要大量的标注数据,而且只能做静态的预测,不能处理序列决策问题。
把这两个领域结合起来看起来很自然,但实际上有三个巨大的挑战:
- 奖励稀疏且延迟:在《打砖块》游戏中,你可能打了100次砖块才得到一次高分,AI需要把很久之前的动作和最终的奖励联系起来。
- 数据高度相关:游戏的连续帧之间非常相似,不是独立同分布的,而深度学习的优化算法假设数据是独立的。
- 非平稳分布:随着AI学习到更好的策略,它遇到的状态分布也会变化,这会导致神经网络的训练不稳定,甚至发散。
之前的研究者们尝试过用神经网络来近似Q值,但都失败了,网络要么不收敛,要么收敛到很差的结果。直到DeepMind的这篇论文,用一个简单而巧妙的机制------经验回放------解决了这些问题。
2 基础知识回顾:Q-Learning
DQN本质上是用深度神经网络来近似Q-Learning中的动作值函数Q(s,a)。我们先快速回顾一下Q-Learning的核心思想。
2.1 什么是Q值?
Q值Q(s,a)表示"在状态s执行动作a,然后遵循最优策略,能获得的长期折扣奖励的期望"。简单来说,Q值就是"在这个状态做这个动作好不好"的评分。
Q值满足著名的贝尔曼方程 :
Q∗(s,a)=Es′∼Er+γmaxa′Q∗(s′,a′)∣s,aQ^{*}(s, a)=\mathbb{E}_{s' \sim \mathcal{E}}\leftr+\\gamma \\max _{a'} Q\^{\*}\\left(s', a'\\right) \| s, a\\rightQ∗(s,a)=Es′∼Er+γa′maxQ∗(s′,a′)∣s,a
公式符号全解释:
- Q∗(s,a)Q^{*}(s,a)Q∗(s,a):最优动作值函数,也就是所有可能的策略中Q(s,a)的最大值
- Es′∼E\mathbb{E}_{s' \sim \mathcal{E}}Es′∼E:对下一个状态s'求期望,s'是由环境ε决定的
- rrr:在状态s执行动作a获得的即时奖励
- γ\gammaγ:折扣因子,0<γ<1,衡量未来奖励的价值。γ=0.9意味着明天的1块钱只值今天的9毛钱
- maxa′Q∗(s′,a′)\max_{a'} Q^{*}(s',a')maxa′Q∗(s′,a′):在下一个状态s'能获得的最大Q值,也就是未来能得到的最好结果
通俗解释:贝尔曼方程其实就是一个非常朴素的道理------现在的价值=即时奖励+未来的价值。比如你现在努力学习,即时奖励是0,但未来能找到好工作,获得更高的收入,所以现在学习的Q值是很高的。
2.2 Q-Learning的更新公式
Q-Learning通过不断迭代来逼近最优Q值,更新公式是:
Q(s,a)←Q(s,a)+α(r+γmaxa′Q(s′,a′)−Q(s,a))Q(s,a) \leftarrow Q(s,a) + \alpha \left( r + \gamma \max_{a'} Q(s',a') - Q(s,a) \right)Q(s,a)←Q(s,a)+α(r+γa′maxQ(s′,a′)−Q(s,a))
公式符号全解释:
- α\alphaα:学习率,0<α<1,决定了新经验对旧Q值的修正幅度
- r+γmaxa′Q(s′,a′)r + \gamma \max_{a'} Q(s',a')r+γmaxa′Q(s′,a′):目标Q值,也就是我们认为Q(s,a)应该有的值
- r+γmaxa′Q(s′,a′)−Q(s,a)r + \gamma \max_{a'} Q(s',a') - Q(s,a)r+γmaxa′Q(s′,a′)−Q(s,a):时序差分误差(TD Error),也就是我们的预测和实际结果之间的差距
通俗解释:这个公式就是"知错就改"的数学表达。你之前认为在s做a能得到Q(s,a)的奖励,但实际做了之后,发现得到了r,而且未来还能得到γmaxa′Q(s′,a′)\gamma \max_{a'} Q(s',a')γmaxa′Q(s′,a′)的奖励,所以你用这个差距来修正你之前的估计。学习率α就是"改正的幅度"。
传统的Q-Learning用一个表格来存储所有状态动作对的Q值,但当状态是游戏屏幕这样的高维数据时,这个表格会大到无法想象。所以DQN用一个深度神经网络来近似这个Q表:
Q(s,a;θ)≈Q∗(s,a)Q(s,a;\theta) \approx Q^{*}(s,a)Q(s,a;θ)≈Q∗(s,a)
其中θ是神经网络的参数。
3 DQN的核心创新:经验回放
DQN的成功,90%要归功于**经验回放(Experience Replay)**这个机制。它的思想非常简单,但效果惊人。
3.1 什么是经验回放?
经验回放的核心思想是:把AI和环境交互的每一步经验都存起来,然后训练的时候随机抽一些经验来更新网络。
具体来说,AI在每一个时间步t,会执行一个动作a_t,得到奖励r_t,观察到下一个状态s_{t+1},然后把这个四元组(st,at,rt,st+1)(s_t, a_t, r_t, s_{t+1})(st,at,rt,st+1)存储在一个叫做**回放缓冲区(Replay Buffer)**的大数组里。当需要训练网络的时候,我们从回放缓冲区里随机采样一个小批量(比如32个)的经验,用这些经验来计算损失函数,更新网络参数。
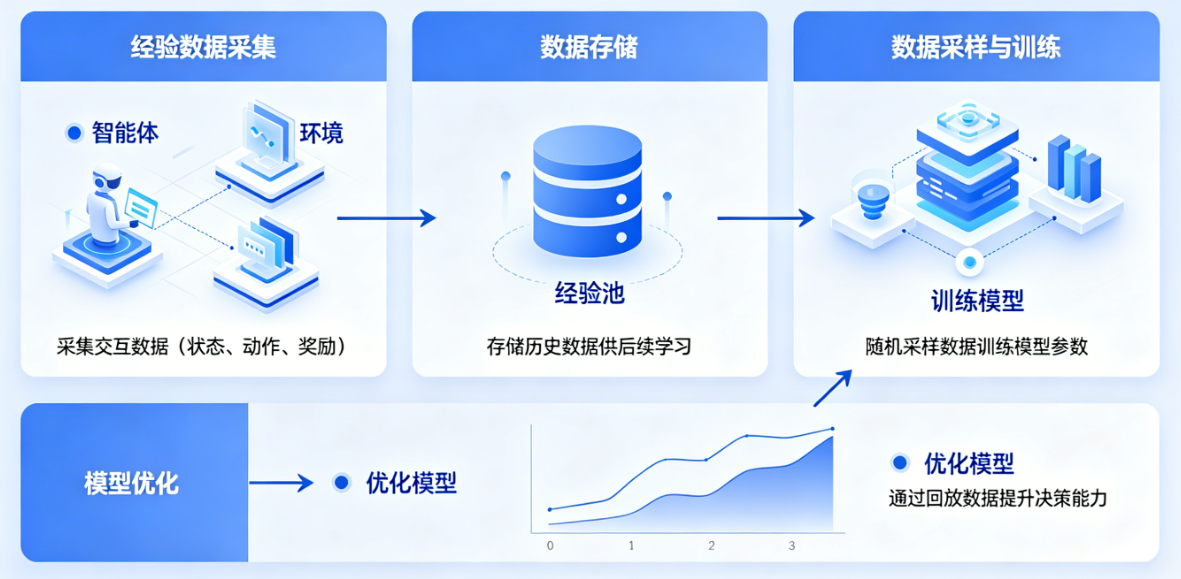
【图片1 经验回放机制示意图】
3.2 经验回放为什么能解决之前的问题?
经验回放完美地解决了我们之前提到的三个挑战中的两个:
- 打破数据相关性:随机采样让训练数据不再是连续的相似帧,而是来自不同时间、不同状态的经验,满足了深度学习对数据独立同分布的要求。
- 平滑训练分布:回放缓冲区里存储了大量过去的经验,训练数据的分布不会因为当前策略的变化而剧烈变化,让训练更加稳定。
- 提高数据效率:每一个经验可以被多次使用,大大提高了数据的利用率,减少了和环境交互的次数。
通俗解释:经验回放就像你上学时的"错题本"。你把每次做错的题都记在错题本上,然后复习的时候随机抽题来做,而不是按顺序做。这样你不会因为记住了题目的顺序而背答案,而是真正理解了知识点。而且一道错题你可以反复做,直到完全掌握,这比做10道新题还有用。
4 DQN的完整算法
现在我们把所有部分拼起来,看看DQN的完整流程是怎样的。
4.1 输入预处理
Atari游戏的原始输入是210×160的RGB图像,每秒60帧。直接用这个输入的话,计算量太大了,所以论文里做了简单的预处理:
- 把RGB图像转成灰度图,减少通道数从3到1。
- 下采样到110×84的分辨率。
- 裁剪出中间的84×84区域,这部分包含了游戏的主要内容。
- 把连续的4帧堆叠起来,作为一个状态输入。这样可以捕捉到运动信息,比如球的运动方向、敌人的移动速度等。
为什么要堆叠4帧?因为单帧图像无法告诉你物体的运动方向。比如你看到一张球在屏幕中间的图片,你不知道它是向左飞还是向右飞。但如果有连续4帧,你就能很清楚地看到它的运动轨迹。
4.2 网络架构
DQN的网络架构非常简单,就是一个标准的卷积神经网络:
- 输入层:84×84×4的灰度图像(4帧堆叠)
- 第一层卷积:16个8×8的滤波器,步长4,ReLU激活函数
- 第二层卷积:32个4×4的滤波器,步长2,ReLU激活函数
- 第三层全连接:256个神经元,ReLU激活函数
- 输出层:全连接层,神经元数量等于游戏的动作数,每个输出对应一个动作的Q值
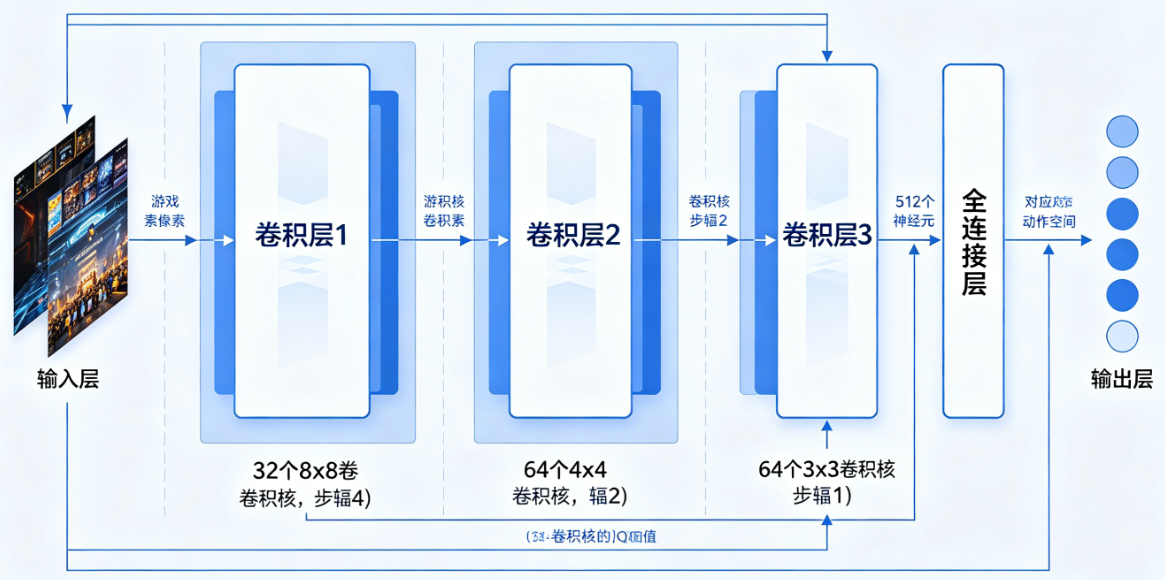
【图片2 DQN网络架构图】
这个架构没有任何游戏特定的设计,所有7个Atari游戏都用完全一样的网络。
4.3 训练流程
DQN的完整训练算法如下:
算法1 带经验回放的深度Q学习
- 初始化回放缓冲区D,容量为N
- 初始化Q网络,参数为随机权重θ
- 对于每一个episode(从游戏开始到结束):
a. 初始化游戏,得到初始状态s_1
b. 预处理得到φ_1 = φ(s_1)(φ是预处理函数)
c. 对于每一个时间步t:
i. 用ε-贪婪策略选择动作a_t:以ε的概率随机选一个动作,以1-ε的概率选Q(φ_t,a;θ)最大的动作
ii. 执行动作a_t,得到奖励r_t和下一个状态s_{t+1}
iii. 预处理得到φ_{t+1} = φ(s_{t+1})
iv. 把经验(φ_t, a_t, r_t, φ_{t+1})存储到回放缓冲区D
v. 从D中随机采样一个小批量的经验(φ_j, a_j, r_j, φ_{j+1})
vi. 计算目标Q值:
KaTeX parse error: Expected 'EOF', got '' at position 36: ...r_j & \text{如果φ_̲{j+1}是终止状态} \\ ...
vii. 计算损失函数:L=1m∑j=1m(yj−Q(φj,aj;θ))2L = \frac{1}{m} \sum{j=1}^m (y_j - Q(φ_j, a_j; θ))^2L=m1∑j=1m(yj−Q(φj,aj;θ))2
viii. 用RMSProp算法优化损失函数,更新参数θ
ix. 如果游戏结束,跳出循环
关键超参数:
- 回放缓冲区容量N=1,000,000
- 小批量大小m=32
- 折扣因子γ=0.99
- ε从1.0线性退火到0.1,在前1,000,000帧
- 训练总帧数=10,000,000
- 优化器:RMSProp,学习率=0.00025
有趣的细节:论文里把所有的奖励都裁剪到了-1,1之间,也就是正奖励变成1,负奖励变成-1,0不变。这样做是因为不同游戏的分数差异很大,比如《打砖块》的分数是个位数,而《太空侵略者》的分数是几千分。裁剪奖励可以让梯度的范围保持一致,这样同一个学习率就能在所有游戏上工作。
5 实验结果:AI玩游戏比人还厉害
论文在7个经典的Atari游戏上测试了DQN的性能,结果令人震惊。
5.1 训练稳定性分析
在强化学习中,评估训练过程是一件很困难的事情,因为平均每集奖励非常不稳定,受随机因素影响很大。论文里提出了一个更稳定的指标:平均最大Q值 ,也就是在一组固定的状态上,网络预测的最大Q值的平均值。
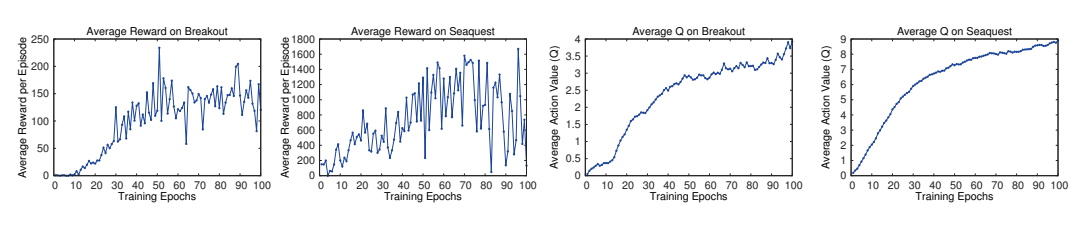
【图片3 训练过程中的平均奖励和平均Q值,出处:论文原文图2】
从图中可以看到:
- 左边的平均奖励曲线非常嘈杂,上下波动很大
- 右边的平均Q值曲线非常平滑,一直在稳定上升
这说明DQN确实在不断学习,策略的价值在不断提高,只是奖励的随机性掩盖了这个趋势。
5.2 价值函数可视化
为了证明DQN真的理解了游戏,论文可视化了《Seaquest》游戏中的价值函数变化:

【图片4 Seaquest游戏的价值函数可视化,出处:论文原文图3】
- A点:敌人出现在屏幕左边,价值函数突然上升,因为AI知道即将获得奖励
- B点:鱼雷即将击中敌人,价值函数达到峰值,因为AI预测马上就能消灭敌人
- C点:敌人被消灭,消失在屏幕上,价值函数回落到原来的水平
这个可视化非常直观地证明了DQN不是在随机乱按,而是真的学会了预测未来的奖励,理解了游戏的规则。
5.3 与其他方法的对比
论文把DQN和当时最好的几种方法进行了对比,结果如下:
【表格1 不同方法在7个Atari游戏上的平均得分对比,出处:论文原文表1】
| 方法 | Beam Rider | Breakout | Enduro | Pong | Q*bert | Seaquest | Space Invaders |
|---|---|---|---|---|---|---|---|
| Random | 354 | 1.2 | 0 | -20.4 | 157 | 110 | 179 |
| Sarsa | 996 | 5.2 | 129 | -19 | 614 | 665 | 271 |
| Contingency | 1743 | 6 | 159 | -17 | 960 | 723 | 268 |
| DQN | 4092 | 168 | 470 | 20 | 1952 | 1705 | 581 |
| Human Expert | 7456 | 31 | 368 | -3 | 18900 | 28010 | 3690 |
结果分析:
- DQN在6个游戏上超过了之前所有的强化学习方法,而且优势非常明显。比如在《Breakout》游戏上,之前最好的方法只能得6分,而DQN能得168分。
- DQN在3个游戏 上超过了人类专家:
- 《Breakout》:人类专家得31分,DQN得168分
- 《Enduro》:人类专家得368分,DQN得470分
- 《Pong》:人类专家得-3分(也就是输3分),DQN得20分(赢20分)
- 最令人惊叹的是,DQN不需要任何手工特征,只需要原始的像素输入。而其他方法都用了大量的手工设计的特征,比如背景减法、颜色通道分离、物体检测等。
有趣的案例:在《Breakout》游戏中,DQN学会了一个非常聪明的策略:它会先在砖块的边缘打一个洞,然后让球穿过洞,在砖块的顶部反弹,这样球会自动消灭很多砖块,不需要AI再操作。这个策略是人类玩家很难想到的,但DQN通过不断试错自己发现了。
6 核心代码实现:DQN玩CartPole
下面是一个完整的、可运行的DQN代码,用PyTorch实现,解决经典的CartPole游戏。CartPole的目标是让小车保持平衡,不让杆子倒下来,非常适合用来演示DQN的核心思想。
python
import gym
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import random
from collections import deque
# 超参数
BATCH_SIZE = 32
LR = 0.001
GAMMA = 0.99
EPSILON_START = 1.0
EPSILON_END = 0.01
EPSILON_DECAY = 0.995
MEMORY_CAPACITY = 10000
TARGET_UPDATE = 100
# 设备配置
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Q网络
class DQN(nn.Module):
def __init__(self, state_dim, action_dim):
super(DQN, self).__init__()
self.fc1 = nn.Linear(state_dim, 64)
self.fc2 = nn.Linear(64, 64)
self.fc3 = nn.Linear(64, action_dim)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
return self.fc3(x)
# 经验回放缓冲区
class ReplayBuffer:
def __init__(self, capacity):
self.buffer = deque(maxlen=capacity)
def push(self, state, action, reward, next_state, done):
self.buffer.append((state, action, reward, next_state, done))
def sample(self, batch_size):
batch = random.sample(self.buffer, batch_size)
states, actions, rewards, next_states, dones = zip(*batch)
return (
torch.tensor(states, dtype=torch.float32).to(device),
torch.tensor(actions, dtype=torch.long).to(device),
torch.tensor(rewards, dtype=torch.float32).to(device),
torch.tensor(next_states, dtype=torch.float32).to(device),
torch.tensor(dones, dtype=torch.float32).to(device)
)
def __len__(self):
return len(self.buffer)
# DQN Agent
class DQNAgent:
def __init__(self, state_dim, action_dim):
self.state_dim = state_dim
self.action_dim = action_dim
self.epsilon = EPSILON_START
self.policy_net = DQN(state_dim, action_dim).to(device)
self.target_net = DQN(state_dim, action_dim).to(device)
self.target_net.load_state_dict(self.policy_net.state_dict())
self.target_net.eval()
self.optimizer = optim.Adam(self.policy_net.parameters(), lr=LR)
self.memory = ReplayBuffer(MEMORY_CAPACITY)
def select_action(self, state):
if random.random() < self.epsilon:
return random.randint(0, self.action_dim - 1)
else:
state = torch.tensor(state, dtype=torch.float32).unsqueeze(0).to(device)
with torch.no_grad():
q_values = self.policy_net(state)
return q_values.argmax().item()
def update(self):
if len(self.memory) < BATCH_SIZE:
return
states, actions, rewards, next_states, dones = self.memory.sample(BATCH_SIZE)
# 计算当前Q值
current_q = self.policy_net(states).gather(1, actions.unsqueeze(1)).squeeze(1)
# 计算目标Q值
with torch.no_grad():
next_q = self.target_net(next_states).max(1)[0]
target_q = rewards + GAMMA * next_q * (1 - dones)
# 计算损失
loss = nn.MSELoss()(current_q, target_q)
# 优化
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
# 衰减epsilon
self.epsilon = max(EPSILON_END, self.epsilon * EPSILON_DECAY)
def update_target(self):
self.target_net.load_state_dict(self.policy_net.state_dict())
# 训练
if __name__ == "__main__":
env = gym.make("CartPole-v1")
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
agent = DQNAgent(state_dim, action_dim)
total_steps = 0
for episode in range(500):
state, _ = env.reset()
episode_reward = 0
while True:
action = agent.select_action(state)
next_state, reward, done, truncated, _ = env.step(action)
done = done or truncated
agent.memory.push(state, action, reward, next_state, done)
agent.update()
state = next_state
episode_reward += reward
total_steps += 1
if total_steps % TARGET_UPDATE == 0:
agent.update_target()
if done:
break
print(f"Episode {episode+1}, Reward: {episode_reward}, Epsilon: {agent.epsilon:.3f}")
# 如果连续10次奖励都超过475,认为训练完成
if episode >= 10 and np.mean([agent.memory.buffer[-i][2] for i in range(1, 11)]) > 475:
print("训练完成!")
break
env.close()代码说明:
- 这个实现加入了2015年Nature版DQN的固定目标网络(Fixed Q-Targets)改进,让训练更加稳定。
- 经验回放缓冲区用deque实现,自动丢弃最旧的经验。
- ε-贪婪策略的ε随着训练逐渐衰减,从1.0降到0.01,平衡探索和利用。
- 每100步更新一次目标网络,让目标Q值保持稳定。
运行这个代码,你会看到AI从一开始只能坚持几帧,到后来能坚持几百帧,完美地平衡杆子。
7 总结与后续发展
7.1 论文的核心贡献
这篇论文是人工智能领域的里程碑式工作,它的核心贡献在于:
- 证明了深度神经网络可以和强化学习成功结合,直接从高维感官输入(像素)学习控制策略,不需要任何手工特征。
- 提出了经验回放机制,解决了强化学习中数据相关性和非平稳分布的问题,让深度神经网络的训练变得稳定。
- 展示了DQN的通用性:同一个网络架构和超参数,在7个不同的Atari游戏上都取得了超过人类专家的性能。
7.2 后续发展
DQN的出现开启了深度强化学习的黄金时代,后续的很多先进算法都是在它的基础上发展而来的:
- Nature DQN(2015):加入了固定目标网络,进一步提高了训练稳定性。
- Double DQN(2015):解决了DQN的Q值过估计问题,提高了性能。
- Prioritized Experience Replay(2015):给经验回放缓冲区里的经验赋予不同的优先级,让重要的经验被更多次采样。
- Dueling DQN(2016):把Q值分解为状态值和优势值,让网络更容易学习。
- Rainbow(2017):结合了6种DQN的改进,达到了Atari游戏的SOTA性能。
直到今天,DQN仍然是深度强化学习入门的必学算法,它的核心思想------用神经网络近似值函数+经验回放------已经深入到强化学习的各个分支。这篇2013年的论文,虽然已经过去了13年,但它的影响力仍然无处不在。