目录
[1.1 二叉搜索树的核心概念与性质](#1.1 二叉搜索树的核心概念与性质)
[1.2 关于相等值的处理](#1.2 关于相等值的处理)
[2.1 性能全看 "长相":结构决定一切](#2.1 性能全看 “长相”:结构决定一切)
[2.2 聊点实在的:二叉搜索树比二分查找强在哪?](#2.2 聊点实在的:二叉搜索树比二分查找强在哪?)
[3.1 二叉搜索树节点模板类SBTnode](#3.1 二叉搜索树节点模板类SBTnode)
[3.2 二叉搜索树功能实现类 SBTree](#3.2 二叉搜索树功能实现类 SBTree)
[4.1 基本思想与代码实现](#4.1 基本思想与代码实现)
[4.2 特别情况说明](#4.2 特别情况说明)
[5.1 具体过程图文解释](#5.1 具体过程图文解释)
[5.2 代码实现详细解析](#5.2 代码实现详细解析)
[5.2.1 查找插入位置](#5.2.1 查找插入位置)
[6.1 执行删除操作时共有多少种情况](#6.1 执行删除操作时共有多少种情况)
[6.2 所有情况的应对策略思想总结](#6.2 所有情况的应对策略思想总结)
[6.2.1 直接删除法](#6.2.1 直接删除法)
[6.2.2 托孤法](#6.2.2 托孤法)
[6.2.3 替换删除法](#6.2.3 替换删除法)
[6.3 代码实现详细解析](#6.3 代码实现详细解析)
[6.3.1 先给出完整代码](#6.3.1 先给出完整代码)
[6.3.2 查找待删除结点](#6.3.2 查找待删除结点)
[6.3.3 情况一、二、三:当前结点没有左/右孩子](#6.3.3 情况一、二、三:当前结点没有左/右孩子)
[6.3.4 情况四:左右子树都存在](#6.3.4 情况四:左右子树都存在)
今天我们来聊二叉搜索树。
说白了,它就是给普通二叉树套上了一套特定的规则约束,也正是这套约束,让它拥有了远超普通二叉树的高效搜索能力。
别看它增删查操作都挺快,性能看着很亮眼,但其实这份高效背后,藏着不小的潜在效率坑。
另外还要提一句,纯key和key-value这两种不同的应用场景,对应的二叉搜索树设计和实现思路,也会有不小的差别。
一、二叉搜索树的概念
1.1 二叉搜索树的核心概念与性质
先给大家明确下基本定义:二叉搜索树 ,英文缩写BST ,也常被叫做二叉排序树。它要么是一棵空树,要么必须满足下面这三条核心性质:
- 首先是左子树的规则:如果左子树不为空,那么左子树上所有节点的值,都必须小于(部分实现允许等于)根节点的值。
- 对应的右子树刚好反过来:如果右子树存在,那上面所有节点的值,都得大于(同样部分实现允许等于)根节点的值。
- 最后也是最关键的一条递归性质:它的左子树和右子树本身,也必须各自是一棵二叉搜索树。
光讲概念肯定不好理解,我们画两个图看看:
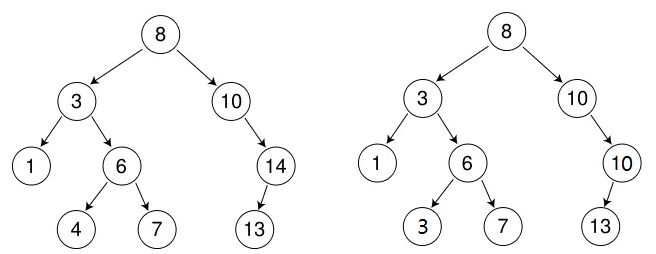
看上面这张图,就是一个标准的二叉搜索树模型。根节点是8,它左边所有子树里的数都比8小,对应我们刚才说的左子树性质;右边所有子树里的数都比8大,对应右子树性质。
而且这个规则不是只在根节点生效,是层层递归往下的,比如以3为根的左子树、以6为根的左子树,每一棵子树都得严格遵守同样的规则,这就是递归性质的体现。
再看右边这张图,二叉搜索树其实不只有左边这种键值完全不重复的实现,也允许像右边这样存在重复键值的情况。关于重复键值具体怎么处理,我们后面会专门展开讲。
1.2 关于相等值的处理
二叉搜索树里能不能插入相等的值,其实没有统一标准,主要看具体的实现和使用场景,一般分两种情况:
- 第一种是不允许重复:像C++STL里的set和map,就严格禁止插入和已有节点值相等的节点。
- 另一种就宽松多了,允许重复插入:比如multiset和multimap这两个STL容器,就支持往里面塞相等的值,这些重复值一般会被统一放到同一棵子树里,通常是右子树。
当然,set、map、multiset和multimap这几个容器,我们后面会专门写文章详细聊。这里可以先透个底,它们的底层其实都是平衡二叉树里的红黑树。
二、二叉搜索树的性能分析
2.1 性能全看 "长相":结构决定一切
先给大家说句大实话:二叉搜索树的性能好不好,完全看它长什么样,上下限差得特别大。
最理想的情况,就是它长成一棵完全二叉树 ,或者说高度特别平衡的树。这时候树的高度大概是 log₂N,不管是查找、插入还是删除,时间复杂度都是O(logN),效率非常能打。
但它也有特别拉胯的时候,如果插入的数据本身就是有序的,那二叉搜索树会直接退化成一条链表。这时候树的高度就变成了N,所有操作的时间复杂度都会暴跌到O(N),跟从头遍历数组没什么区别了。
还是看图说话最清楚:左边这棵树长得就很标准,接近完全二叉树,增删查都是 logN 的效率;右边这棵就惨了,几乎就是一条链表,所有操作都得从头走到尾,效率直接拉胯。
可能有小伙伴会好奇,好好的树怎么就变成链表了?我举个例子大家就懂了:比如你按 10,9,8,7,6,5,4,3,2,1 这个倒序序列来构建二叉搜索树。
根节点先插10,然后9比10小,插在10左边;
8比9小,又插在9左边;
后面的数一个比一个小,只能一直往左边插。
最后整棵树就变成了一条歪歪扭扭的左链表,完全失去了二叉搜索树的优势。
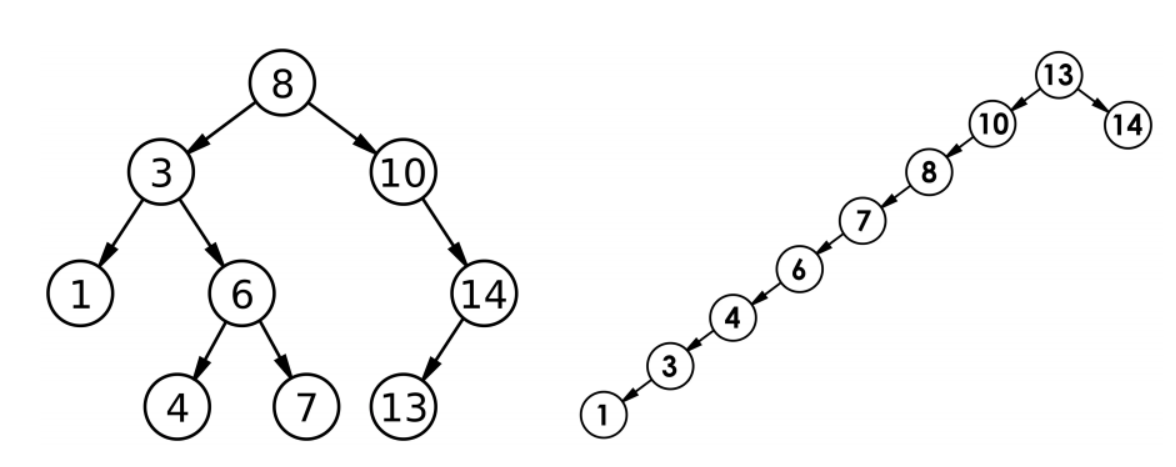
综合来看,二叉搜索树的平均时间复杂度其实是O(logN),但它的性能波动实在太大了,一旦运气不好碰到最坏情况,直接跌到O(N),这种效率在实际生产环境里是完全不能接受的。
也正因为这个硬伤,才有了二叉搜索树的各种改进版本,也就是我们接下来要重点学习的平衡二叉搜索树。像经典的AVL树和红黑树,都属于这一类。它们通过一套严格的规则,强制让树的高度始终维持在O(logN)左右,从根本上解决了退化成链表的问题,保证了增删查改操作的稳定高效。
2.2 聊点实在的:二叉搜索树比二分查找强在哪?
要搞懂平衡二叉搜索树的好,我们拿它和二分查找对比一下就清楚了。虽说二分查找也能做到O (logN)的查找效率,但它有两个挺致命的缺陷:
首先是存储上的限制太死:二分查找必须依赖支持下标随机访问的结构,比如数组,而且数据还得是有序的,这要求就有点高了。
更难受的是更新效率太低:在数组这种结构里插入或删除元素,往往得挪动一大片数据,效率实在感人。
而平衡二叉搜索树刚好补上了这两个坑:它不需要连续的存储空间 ,还能高效地处理动态数据的插入、删除和查找,这就很实用了。
好了,铺垫了这么多,接下来我们正式进入正题:聊聊二叉搜索树的增删查操作到底是怎么实现的。
三、先搭个代码框架
讲了这么多原理,终于要动手写代码了。
cpp
#pragma once
#include<iostream>
using namespace std;
namespace key{
template <class K>
class SBTnode{
public:
K _key;
SBTnode<K>* left;
SBTnode<K>* right;
SBTnode(const K& key)
:_key(key)
, left(nullptr)
, right(nullptr)
{}
};
template <class K>
class SBTree{
using Node = SBTnode<K>;
public:
///..................
protected:
Node* _root = nullptr;
};
}先把整体的架子搭出来,后面再一点点往里面填增删查的具体逻辑,这样思路不容易乱
咱们先准备两个模板类,一个是二叉搜索树的节点模板类,另一个是负责实现具体功能的二叉搜索树类。
3.1 二叉搜索树节点模板类SBTnode
这个节点类用了模板参数K,说白了就是让节点能存任意类型的数据,不管是 int、double 还是自定义类,都能往里塞。
节点内部有三个核心成员:
_key用来存节点的关键字(也就是实际数据),
left和right则是两个指针,分别指向当前节点的左孩子和右孩子。
构造函数也很简单,接收一个const K&类型的 key,把它赋给_key,同时把left和right都初始化为空指针,这样新创建的节点一开始是没有子节点的,干干净净。
3.2 二叉搜索树功能实现类 SBTree
在这个功能类里,先给节点类型起个短点的别名,方便后面写代码,可以用 typedef,也可以用 C++11 新增的using,两种方式都行,看你习惯。
接着,在类里组合进来一个根节点指针 _root,顺便给它个缺省值 nullptr,表示这棵树一开始是空的,连根节点都没有。
四、二叉搜索树的查找
4.1 基本思想与代码实现
查找的逻辑其实特别简单,我们就从根节点开始,拿着要找的值x一步步比:
说白了就是:x 比根节点大?
那咱就往右边子树找;
x 比根节点小?
那就往左边子树钻。
最多也就找树的高度那么多次,要是最后都遍历到空节点了还没见着x,那说明这树里根本就没这个值。
cpp
Node* Find(const K& key){
Node* cur = _root;
while (cur){
if (cur->_key < key)
cur = cur->right;
else if (cur->_key > key)
cur = cur->left;
else
return cur;
}
return nullptr;
}4.2 特别情况说明
这里得分两种情况聊:
要是咱们的实现不允许插入相等的值,那查找就很省心,找到第一个等于x的节点,直接返回就完事了。
但如果支持重复插入,那树里可能藏着好几个 x。这时候通常有个约定俗成的规矩:要找中序遍历下第一个出现的 x。
举个例子,比如要找值为3的节点,得找到那种 "某个节点(比如值为 1 的节点)的右孩子刚好是 3" 的,返回这个首次出现的 3 才算数。
如下图,查找3,要找到1的右孩⼦的那个3返回。
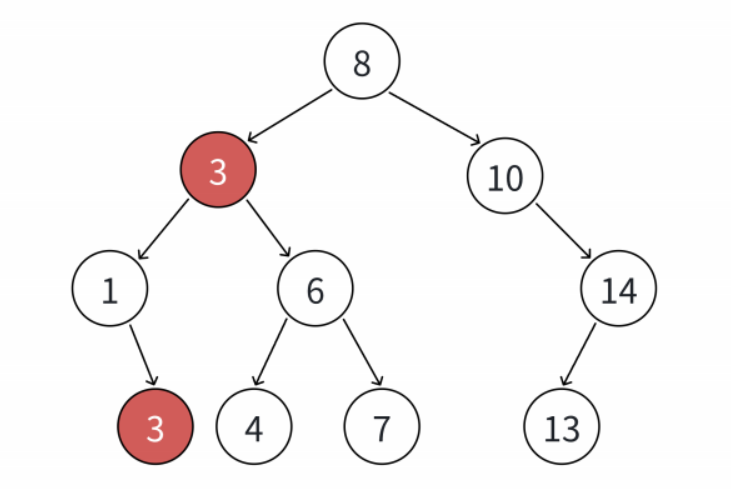
不过得提一句,关于重复值的查找规则,C++ 标准其实没做硬性规定,属于未指定行为。像 multimap、multiset 这些容器在这方面的具体实现,完全取决于编译器的选择。
五、二叉搜索树的插入
5.1 具体过程图文解释
插入的逻辑其实和查找有点像,咱们一步步来:
如果树本身是空的,那最简单,直接新增一个节点,把它赋值给root指针就行。
要是树不为空,那就得按二叉搜索树的规矩来:
- 插入值比当前节点大,就往右子树走;
- 比当前节点小,就往左子树走,一直找到一个空位置,把新节点插进去。
- 如果支持插入相等的值,那碰到和当前节点相等的值时,可以统一往右走,也可以统一往左走,找到空位插进去就行。但这里有个关键点要注意:逻辑得保持一致,别一会插左边一会插右边,不然树的规则就乱了。
光说可能有点抽象,咱们用一个具体例子来演示下这个过程:
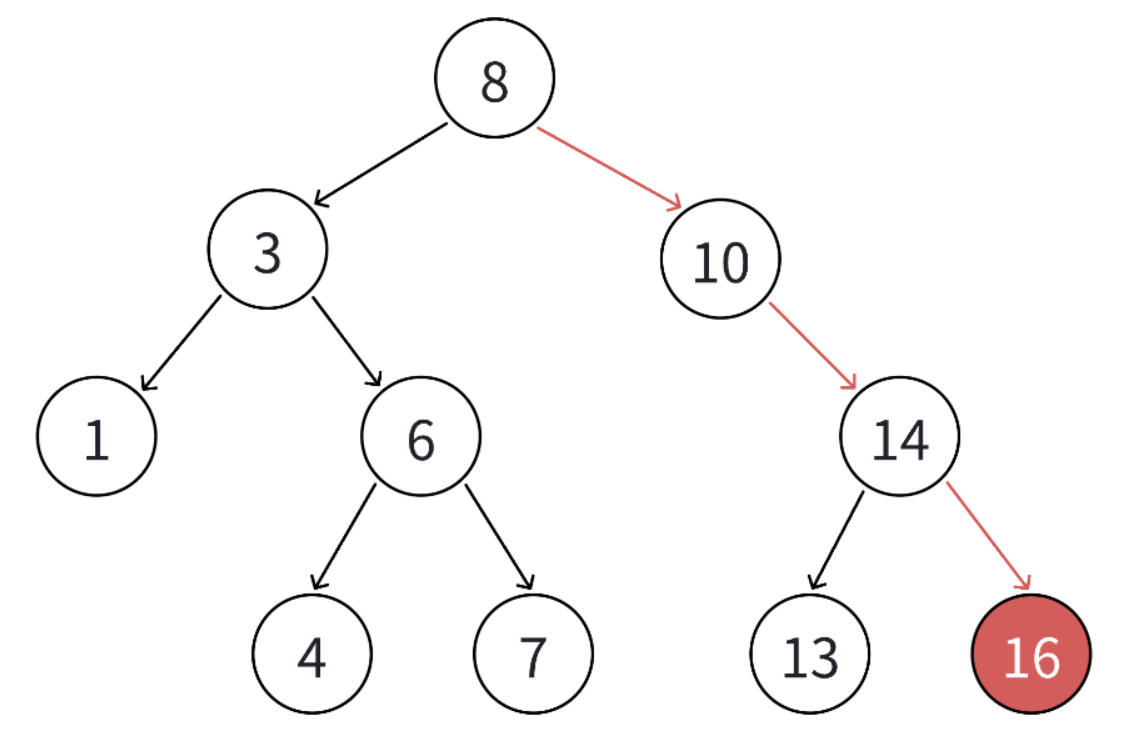
 大家看上面这棵二叉搜索树,现在我们要往里面插一个数 16。
大家看上面这棵二叉搜索树,现在我们要往里面插一个数 16。
具体操作如下图:我们就按照二叉搜索树的性质,一步步往下找,找到那个合适的空位,直接把 16插进去就行。
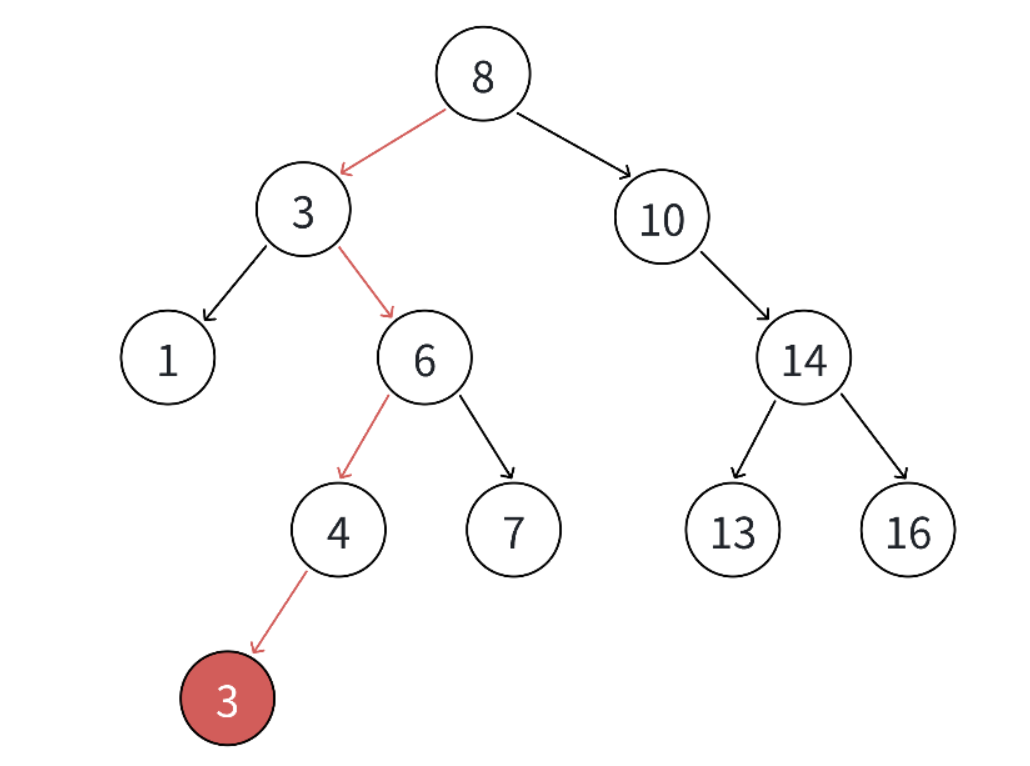
如下图,如果咱们要插入一个重复的数字,可以提前定好规矩 ------ 要么统一插在已经存在的那个重复值节点的左子树,要么统一插在右子树。
接着还是按照二叉搜索树的老套路,一步步往下找空位,找到后把新节点插进去就完事了。
5.2 代码实现详细解析
代码这块稍微有点绕,咱们别着急,分块慢慢捋。整体可以把代码拆成三部分:
第一是找插入的位置,
第二是真刀真枪地插进去,
第三是处理一些特殊情况。
5.2.1 查找插入位置
先讲第一块:怎么找插入的位置。我们还是从根节点出发,拿着要插的 key,跟当前节点 cur 的_key 比大小。大了就往右走,小了就往左走,走的时候别忘了顺手记一下父节点 parent。等 cur 走到 nullptr 的时候,说明咱们找到该插的地方了;
但要是走着走着碰到了和 key 一样的节点,那就直接返回 false,告诉外面 "不允许重复插哈"。
cpp
bool Insert(const K& key){
Node* cur = _root;
Node* parent = nullptr;
while (cur){
if (cur->_key < key){
parent = cur;
cur = cur->right;
}
else if (cur->_key > key){
parent = cur;
cur = cur->left;
}
else
return false;
}
}等位置找好了,接下来就是真的把节点插进去了。
这时候咱们刚才记的parent就派上用场了,它刚好指向待插入位置的父节点。
我们先创建一个新节点new Node(key),然后再拿 key 跟 parent 的_key 比一下大小:
- 要是 key 比父节点小,就把新节点插成它的左孩子;
- 要是比父节点大,就插成右孩子。
这么一弄,就能稳稳地保持住二叉搜索树 "左子树都比根小、右子树都比根大" 的有序结构了。
cpp
cur = new Node(key);
if (parent->_key > key)
parent->left = cur;
else if (parent->_key < key)
parent->right = cur;
return true;最后提个特殊情况,如果整棵树本身就是空的,也就是 _root 还等于 nullptr,那说明我们现在插的是这棵树的第一个节点。
这时候就不用费劲儿去查位置了,直接创建一个新节点,让 _root 指向它就行。说白了,这一步就把二叉搜索树给初始化好了。
cpp
if (_root == nullptr){
_root = new Node(key, value);
return true;
}六、二叉搜索树的删除
注意了,二叉搜索树最麻烦的部分这就来了,删除操作。
6.1 执行删除操作时共有多少种情况
首先得先找找看要删的元素在不在树里,要是压根不存在,直接返回 false就完事了。但如果找到了,那麻烦就来了,得根据要删的节点 N 的情况分四种处理:
- 第一种情况:要删的节点N左右孩子都空着,是个光杆司令。
- 第二种情况:节点N左孩子空着,但右孩子还在。
- 第三种情况:节点N右孩子空着,但左孩子还在。
- 第四种情况:最头疼的,节点N左右孩子都好好的,一个都不少。
6.2 所有情况的应对策略思想总结
针对这四种情况,我总结了三种应对策略:直接删除法、托孤法、替换删除法。
6.2.1 直接删除法
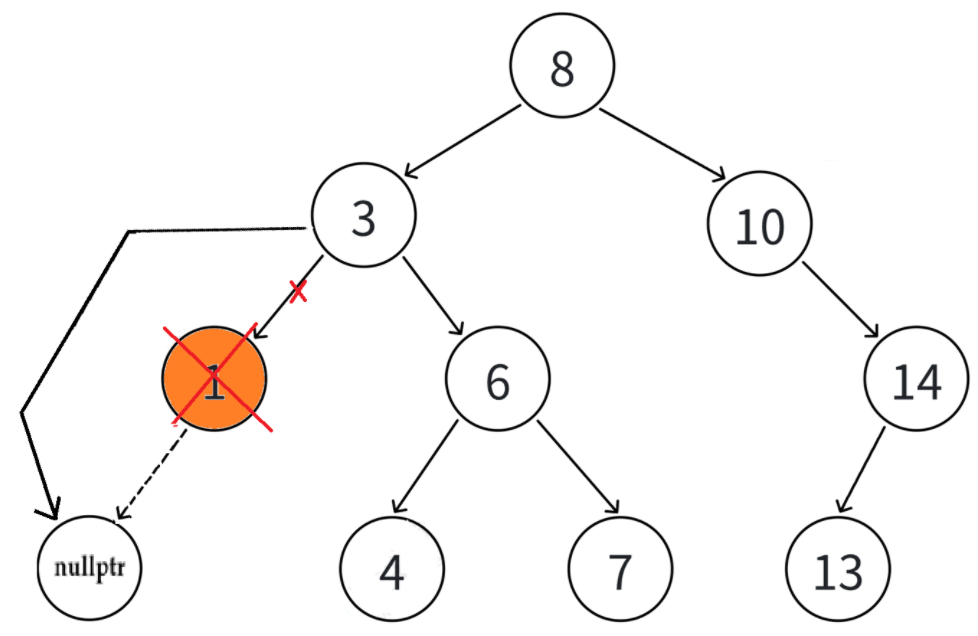
直接删除法很简单:先把N节点的父亲对应的孩子指针改成空,然后直接删掉 N 节点就行。
顺便说一句,第一种情况(左右都空)其实可以当成第二种或第三种情况来处理,效果没差。
6.2.2 托孤法
接下来是托孤法,专门处理情况二和情况三,也就是要删的节点只有一个孩子的时候。
情况二是N只有右孩子,那简单,让N的父亲把对应孩子指针直接指向 N 的右孩子,然后删掉 N 就行;
情况三反过来,只有左孩子,就让父亲指向左孩子,再删 N。
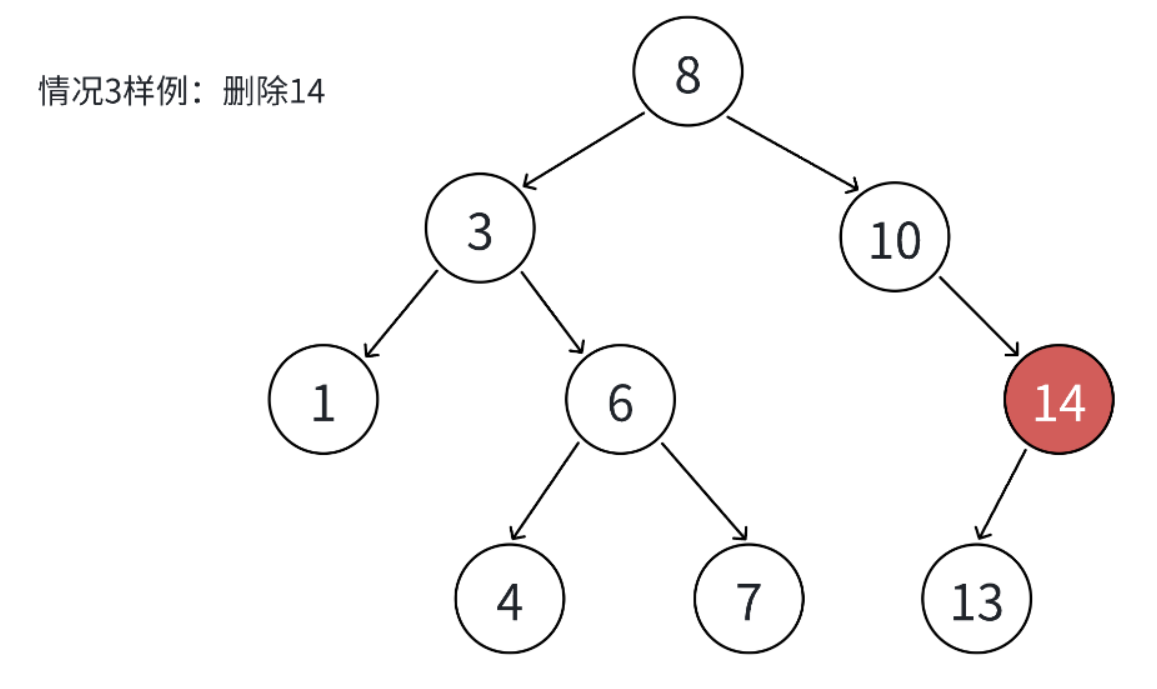
给大家看个图就懂了,比如现在要删的节点是14,它只有一个孩子13。按照托孤法的处理方式,直接让 14 的父节点 10 的右指针指向 13,然后把 14 删掉就完事了。
这么一弄,不仅把节点删了,还能保证二叉搜索树**"左小右大"**的规矩没被破坏 ------ 哪怕 13 下面还有子树,也会跟着 13 一起接回原来的位置,完全不用操心。
6.2.3 替换删除法
先给大家看张图,假设咱们现在要删的是像3或者8这种有两个子节点的节点。
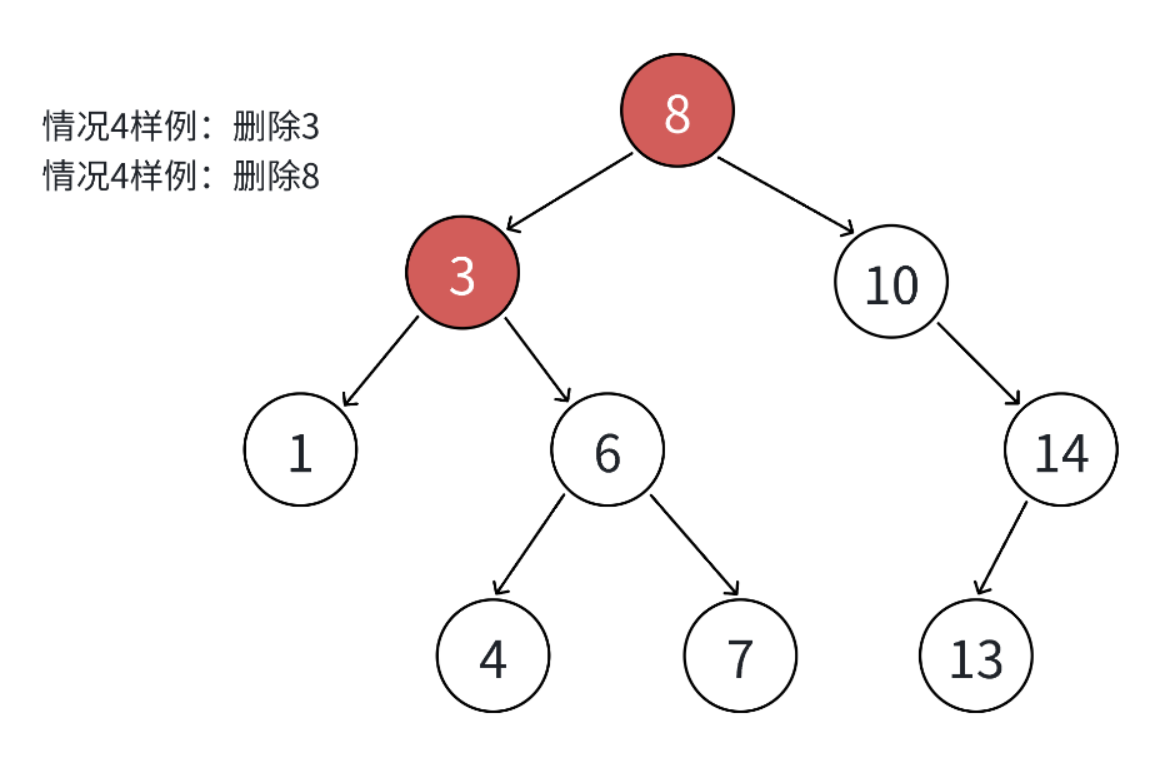
这时候直接删 N 肯定不行,它两个孩子没地方放啊。想想看,要是还用托孤法,父亲只有一个空出来的指针,指了这个孩子,另一个怎么办?所以对付这种有两个孩子的节点,我们得换个思路。
不知道大家还记不记得,我们之前删堆顶元素的时候用过一个办法:从堆底拿个数和堆顶交换,然后删掉堆底那个,再把新堆顶往下调整调整就行。
那我们能不能也用类似的思路,找个数和要删的数交换,来实现替换删除?不过二叉搜索树的规矩太严了,这个数可不能随便找。所以我们得定个规则,专门挑合适的替换数。
怎么找呢?
要么找 N 左子树里值最大的那个节点 R(也就是左子树最右边的那个),要么找 N 右子树里值最小的那个节点 R(右子树最左边的那个)。这两个节点随便拿一个放到 N 的位置,都能符合二叉搜索树的规矩。
这里说的 "替代",一开始我想的是把 N 和 R 的值交换一下,然后转头去删 R。毕竟 R 这时候肯定符合情况 2 或者 3,直接删就行。
不过这里得跟大家道个歉,我之前忽略了个问题,先直接说结论:我们只能让替代节点 R 去覆盖 N,不能让它们俩交换值,为什么呢?原理我接下来跟大家说:
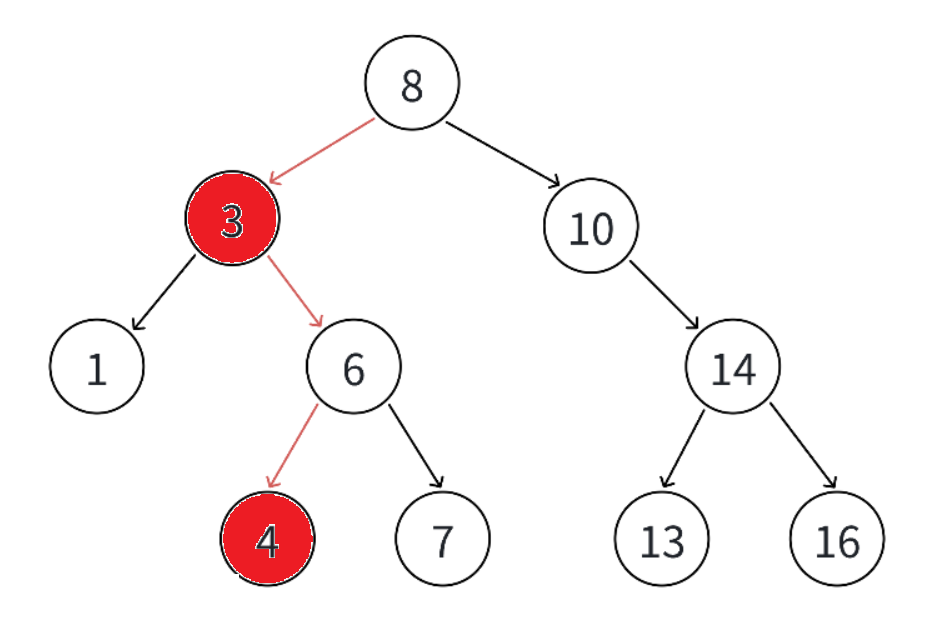
如上图,假设我们要去删除3,并且找到了右子树的最小结点4,这个时候交换4和3:如下图:
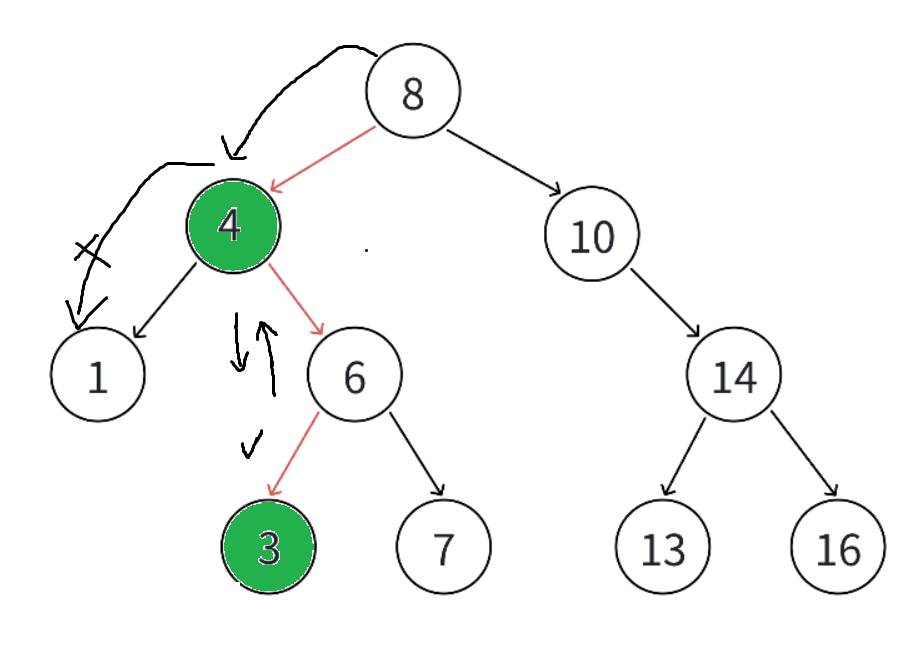
如果在这个时候继续选择从头遍历去查找3并删除的话,我们是找不到的,因为3的位置不符合二叉搜索树的规则。就是这个细节我们下面的代码要注意一下。 ok来看看代码怎么写:
6.3 代码实现详细解析
6.3.1 先给出完整代码
cpp
bool Erase(const K& key)
{
Node* parent = nullptr;
Node* cur = _root;
while (cur)
{
if (cur->_key < key)
{
parent = cur;
cur = cur->right;
}
else if (cur->_key > key)
{
parent = cur;
cur = cur->left;
}
else
{
if (cur->left == nullptr)
{
if (cur == _root)
{
_root = cur->right;
}
else
{
if (parent->left == cur)
{
parent->left = cur->right;
}
else if (parent->right == cur)
{
parent->right = cur->right;
}
}
}
else if (cur->right == nullptr)
{
if (cur == _root)
{
_root = cur->left;
}
else
{
if (parent->left == cur)
{
parent->left = cur->left;
}
else if (parent->right == cur)
{
parent->right = cur->left;
}
}
}
else
{
Node* replaceparent = cur;
Node* replace = cur->right;
while (replace->left)
{
replaceparent = replace;
replace = replace->left;
}
cur->_key = replace->_key;
if (replaceparent->left == replace)
{
replaceparent->left = replace->right;
}
else if (replaceparent->right == replace)
{
replaceparent->right = replace->right;
}
cur = replace;
}
delete (cur);
return true;
}
}
return false;
}6.3.2 查找待删除结点
cpp
Node* parent = nullptr;
Node* cur = _root;
while (cur){
if (cur->_key < key){
parent = cur;
cur = cur->right;
}
else if (cur->_key > key){
parent = cur;
cur = cur->left;
}这段代码的作用很简单,就是在二叉搜索树里先把要删的那个节点给找出来。
这里面有两个关键指针得说一下:**cur 是我们当前遍历到的节点,parent 则专门跟着记 cur 的父节点。**毕竟后面真要动手删节点的时候,得改父节点的指针才行。
查找的逻辑完全就是二叉搜索树那老一套,所以代码就是不断地往下移动,同时顺手更新 parent 的值。等循环结束了,要是发现 cur 变成了 nullptr,那说明这树里根本就没咱们要找的这个元素,函数最后直接返回 false 就完事了。
6.3.3 情况一、二、三:当前结点没有左/右孩子
cpp
if (cur->left == nullptr){
if (cur == _root)
_root = cur->right;
else{
if (parent->left == cur)
parent->left = cur->right;
else if (parent->right == cur)
parent->right = cur->right;
}
}这部分代码对应的就是咱们前面原理里说的那三种情况:
情况1是要删的节点左右孩子都空;
情况 2 和 3 则是左空右不空,或者右空左不空。
有意思的是,这三种情况在代码里其实可以揉在一起统一处理。为什么呢?
因为如果一个节点没了左/右孩子 ,那直接**让父节点指向它剩下的那个右/左孩子就行。**说白了就是咱们之前说的托孤法,很省事。
不过这里得单独提一下删除根节点的情况,代码里专门做了处理,比如直接让 _root = cur->right。毕竟根节点没有父节点,没地方托孤,只能直接修改 _root 指针本身了。
6.3.4 情况四:左右子树都存在
cpp
else
{
Node* replaceparent = cur;
Node* replace = cur->right;
while (replace->left)
{
replaceparent = replace;
replace = replace->left;
}等碰到待删除的节点左右子树都健在的时候,就不能直接删了。为啥?因为你要是直接把这个节点删了,它的左右两棵子树总不能同时接到父节点那儿去吧,所以这时候必须得用咱们之前说的替换删除法。
我这里采用的办法是,在当前节点的右子树里找那个最小的节点。怎么找呢?先一头扎进右子树,然后接着不断往左走,一直走到最左边的那个节点为止,这个节点,其实就是当前节点的中序后继。
cpp
cur->_key = replace->_key;等找到这个替换节点 replace 之后,咱们就把它的值赋给当前要删的节点 cur。这么一弄,从逻辑上讲,就相当于用 replace 把 cur 的位置给顶掉了。
这时候真正需要动手删掉的节点,就不再是原来的 cur,而是变成这个 replace 了。
cpp
if (replaceparent->left == replace)
{
replaceparent->left = replace->right;
}
else if (replaceparent->right == replace)
{
replaceparent->right = replace->right;
}这时候删replace就简单多了。为啥呢?因为它是右子树里挑出来的最小节点,肯定没有左孩子,撑死了也就只有一个右孩子 ------ 这不刚好能用咱们之前说的托孤法嘛。
具体操作也很 straightforward,只需要让 replace 的父节点 replaceparent 指向 replace->right,就能顺顺利利把 replace 从树结构里给摘下来了。
cur = replace;
}
到这里,二叉搜索树最核心的增删查改逻辑我们就全部讲完了。从最基础的概念性质到性能分析,从搭建代码框架到逐行拆解每一个操作的细节,相信你已经对二叉搜索树的工作原理有了完整且深入的理解。
不过这还不是二叉搜索树的全部内容。在下一篇文章中,我们会继续完善它的所有常用接口,包括交换函数、中序遍历、默认构造、拷贝构造、赋值重载以及析构函数。
同时,我们还会结合实际开发需求,深入讲解二叉搜索树最核心的两个应用场景,纯key搜索场景和key-value键值对搜索场景,并给出对应的完整代码实现。内容同样干货满满,敬请期待!