Transformer 是由 Google 在 2017 年的经典论文《Attention Is All You Need》中提出的一种深度学习架构。它彻底抛弃了以往处理序列数据时常用的 RNN(循环神经网络)和 CNN(卷积神经网络),完全依赖于注意力机制(Attention Mechanism)。
Transformer 的核心架构详解
Transformer 的原始架构分为 Encoder(编码器) 和 Decoder(解码器)。但在后续发展中,很多模型只取其一(例如 BERT 只用 Encoder,GPT 系列只用 Decoder)。
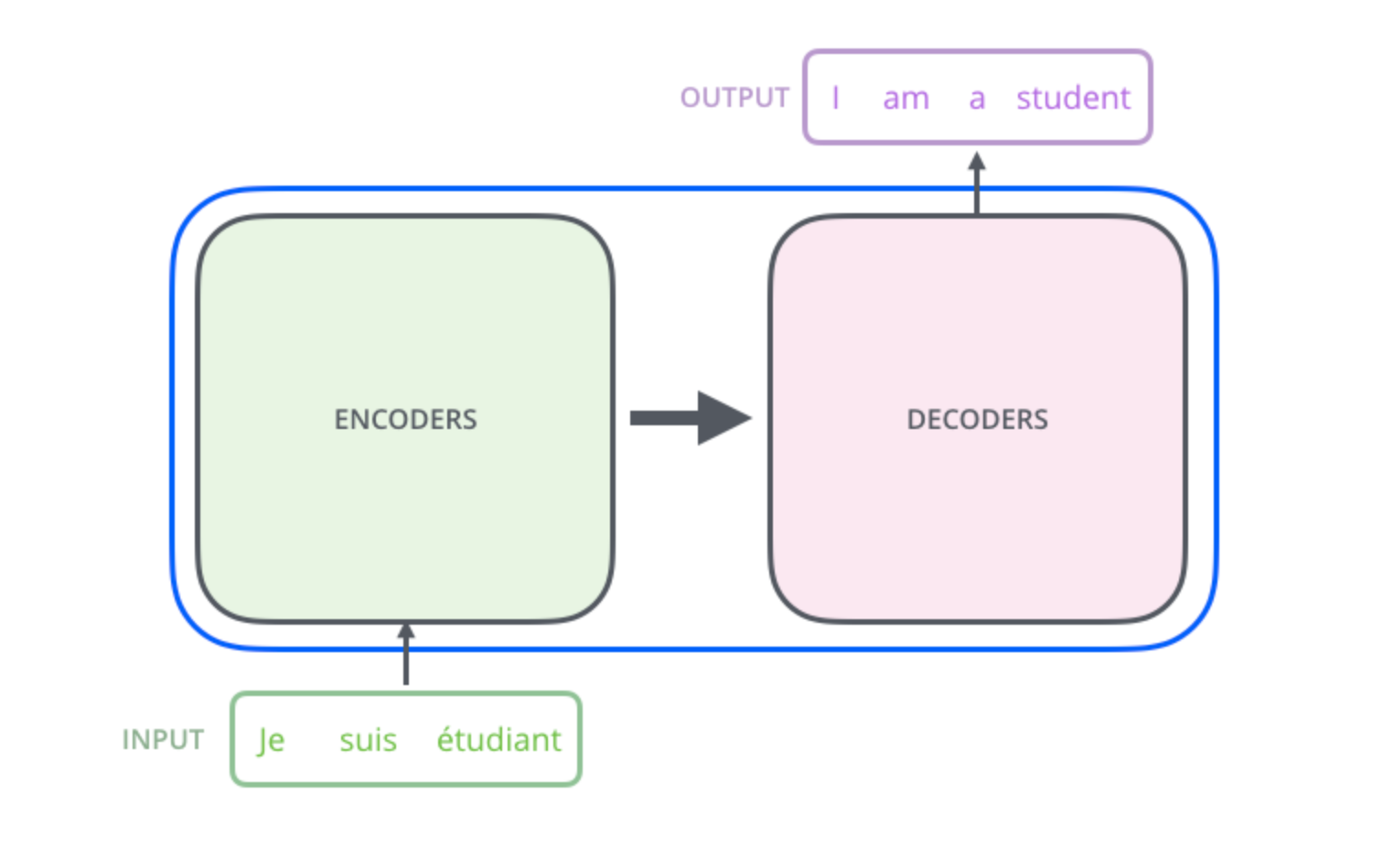
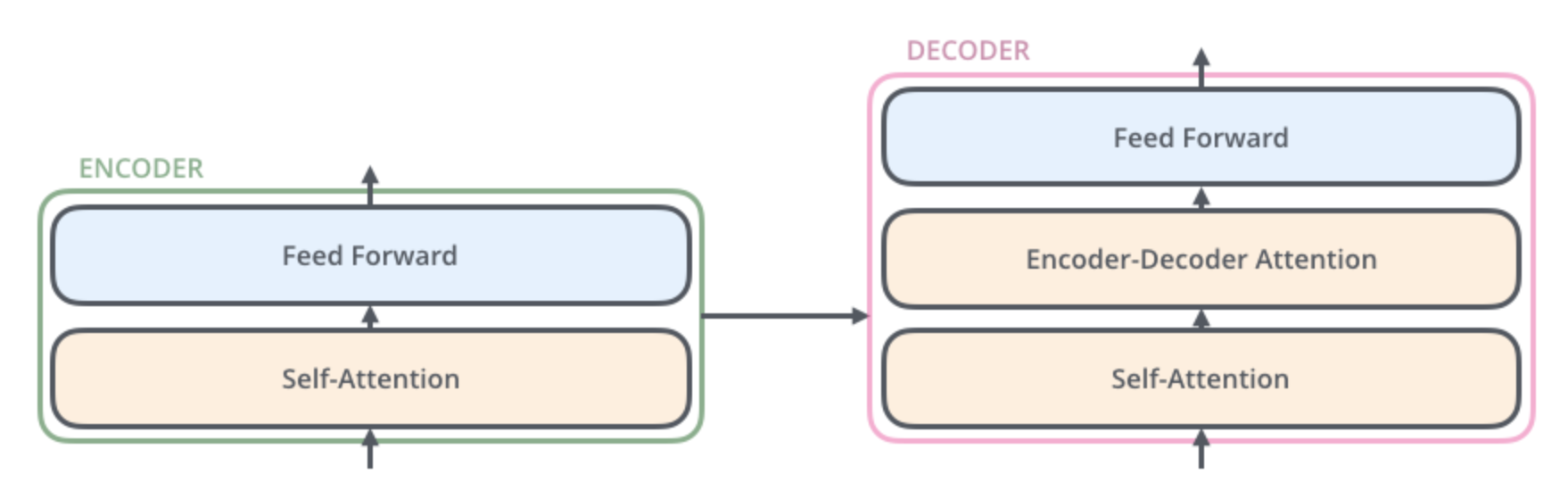
它的核心创新包含以下四个关键组件:
1. 自注意力机制 (Self-Attention)
这是 Transformer 的灵魂。在阅读一句话时,自注意力机制允许模型在处理当前词时,"看一眼"句子中的所有其他词,从而获得更丰富的上下文信息。
举个例子:
" The animal didn't cross the street because it was too tired"
这句话中的"它"指的是什么?是指街道还是动物?对人类来说,这是个简单的问题,但对算法来说却并非如此。
当模型处理单词"它"时,自我注意力机制使其能够将"它"与"动物"联系起来。
其他功能如:
序列建模:自注意力可以用于序列数据(例如文本、时间序列、音频等)的建模。它可以捕捉序列中不同位置的依赖关系,从而更好地理解上下文。这对于机器翻译、文本生成、情感分析等任务非常有用。
在数学实现上,输入序列会被映射为三个矩阵:Q (Query, 查询) , K (Key, 键) , 和 V (Value, 值)。
-
Query: 当前正在处理的词,它在问:"我需要句子中哪些其他词的信息?"
-
Key: 句子中所有其他的词,它们在回答:"我包含了什么特征?"
-
Value: 句子中所有词的实际内容/特征表示。
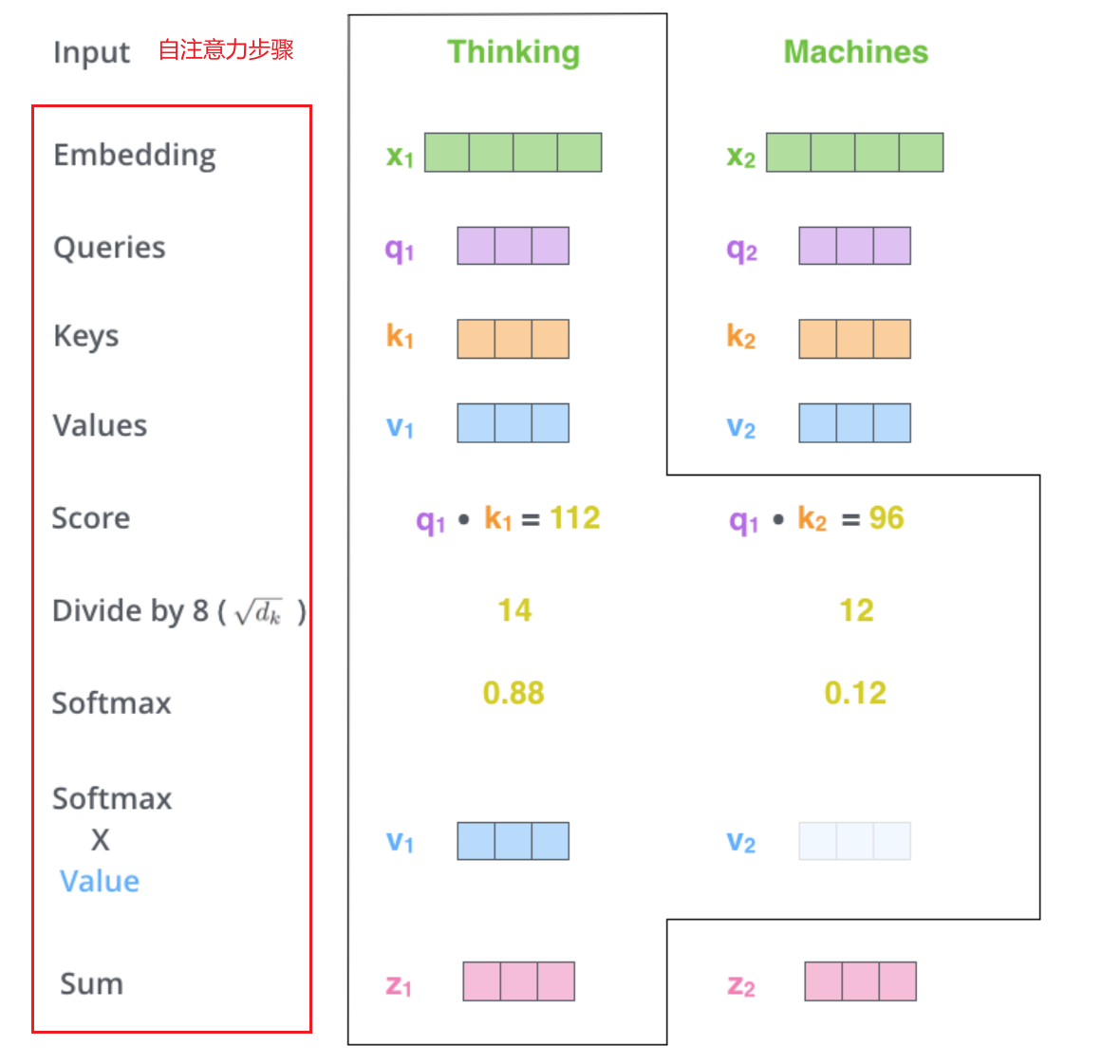
通过计算 Q 和 K 的点积,模型可以得出当前词与所有词的相关度(即 Attention Score)。核心公式如下:
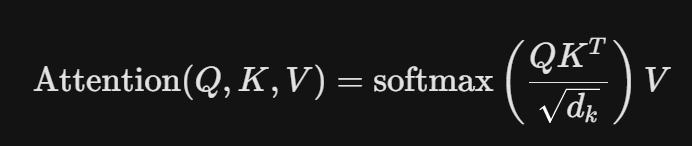
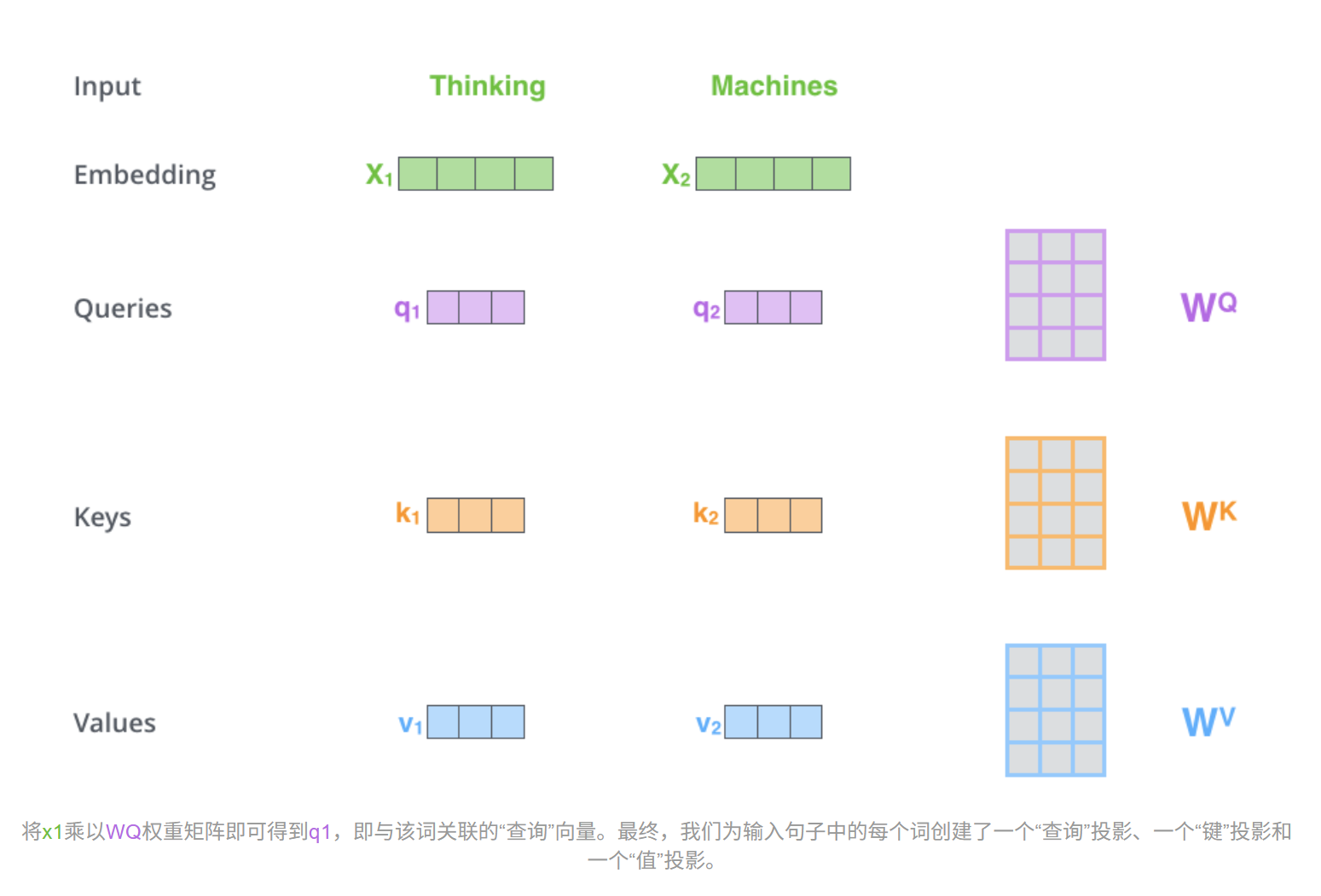
全部步骤如图所示:
2. 前馈神经网络与残差连接 (FFN & Add/Norm)
在每一层注意力的后面,都有一个基于位置的前馈神经网络 (Position-wise Feed-Forward Network)。它包含两个线性变换和一个 ReLU 激活函数,用于进一步提取特征。
此外,为了训练深层网络而不发生梯度消失或爆炸,Transformer 大量使用了:
-
残差连接 (Residual Connection): x + \\text{Sublayer}(x)
-
层归一化 (Layer Normalization): 在隐层维度上进行标准化,这对于 NLP 等序列变长的任务非常稳定。
(注:除以 sqrt{d_k}是为了防止点积结果过大导致 softmax 梯度消失,这被称为缩放点积注意力)
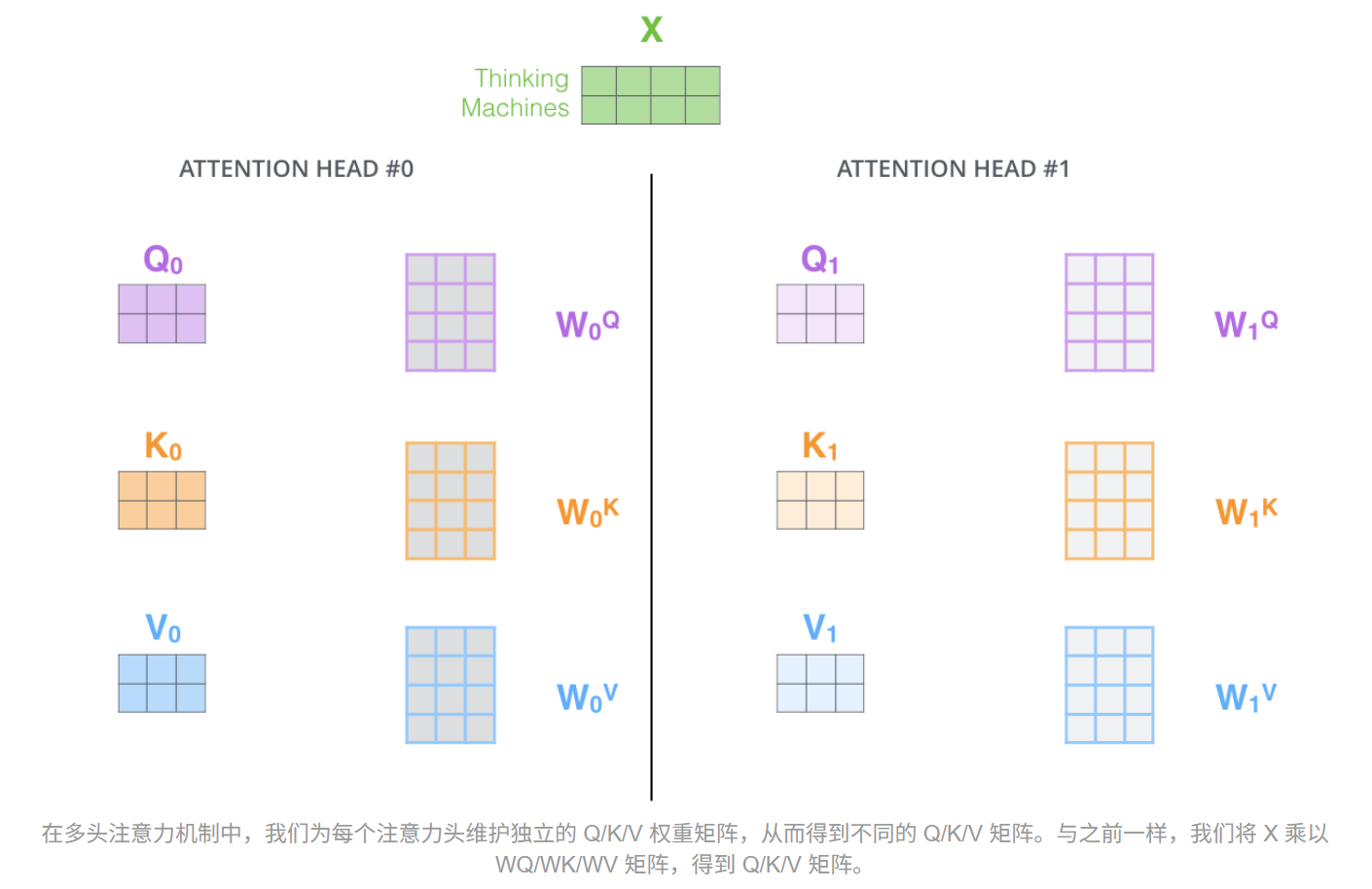
3. 多头注意力 (Multi-Head Attention)
如果模型只有一组 Q, K, V 矩阵,它可能只能关注到一种维度的关系(比如语法关系)。为了让模型拥有多维度的理解能力,Transformer 引入了"多头"概念。
模型会将高维的特征向量拆分成多个"头"(Heads),每个头独立进行上述的自注意力计算。比如一个头专门负责寻找代词指代的实体(如"it"指向"animal"),另一个头专门负责寻找动宾关系。最后,将所有头的结果拼接(Concat)起来,再经过一个线性层融合。
使用多头注意力机制,我们不仅拥有一个,而是多个查询/键/值权重矩阵集(Transformer 使用八个注意力头,因此每个编码器/解码器最终都会有八组)
4. 位置编码 (Positional Encoding)
因为 Transformer 抛弃了 RNN,它是并行处理所有词的,这就导致模型完全不知道词在句子中的顺序(对它来说,"狗咬人"和"人咬狗"是一样的)。
为了解决这个问题,需要显式地将位置信息注入到输入特征中。原始论文使用了不同频率的正弦和余弦函数来生成位置编码:
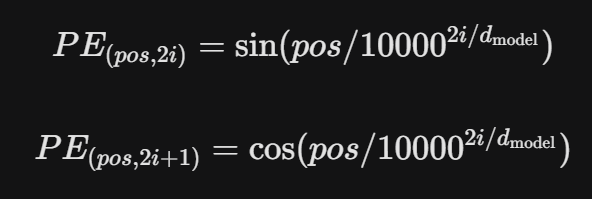
这个编码直接加在词向量上,使得模型能够区分相对位置和绝对位置。
(二)从 PyTorch 视角看 Transformer
在实际工程落地中,利用 PyTorch 开发和调试此类模型非常便捷。在 PyTorch 中构建模型时,并不需要每次都手写上述复杂的公式。PyTorch 提供了高度优化的原生接口:
-
torch.nn.MultiheadAttention:直接实现了多头注意力计算。 -
torch.nn.TransformerEncoderLayer:包含了一层完整的自注意力、Add/Norm 和 FFN。 -
torch.nn.Transformer:完整的 Transformer 架构。
在多模态架构(MLLMs)中,Transformer 的通用性得到了极大体现。图像可以被切分成 Patches(如 ViT 所做),声音可以被转化为频谱图特征序列,这些序列统统可以像文本 Token 一样被送入 Transformer 中进行特征对齐和融合。
(三)解码侧
编码器首先处理输入序列。然后,顶层编码器的输出被转换为一组注意力向量 K 和 V。
每个解码器在其"编码器-解码器注意力"层中都会使用这些注意力向量,以帮助解码器关注输入序列中的适当位置:
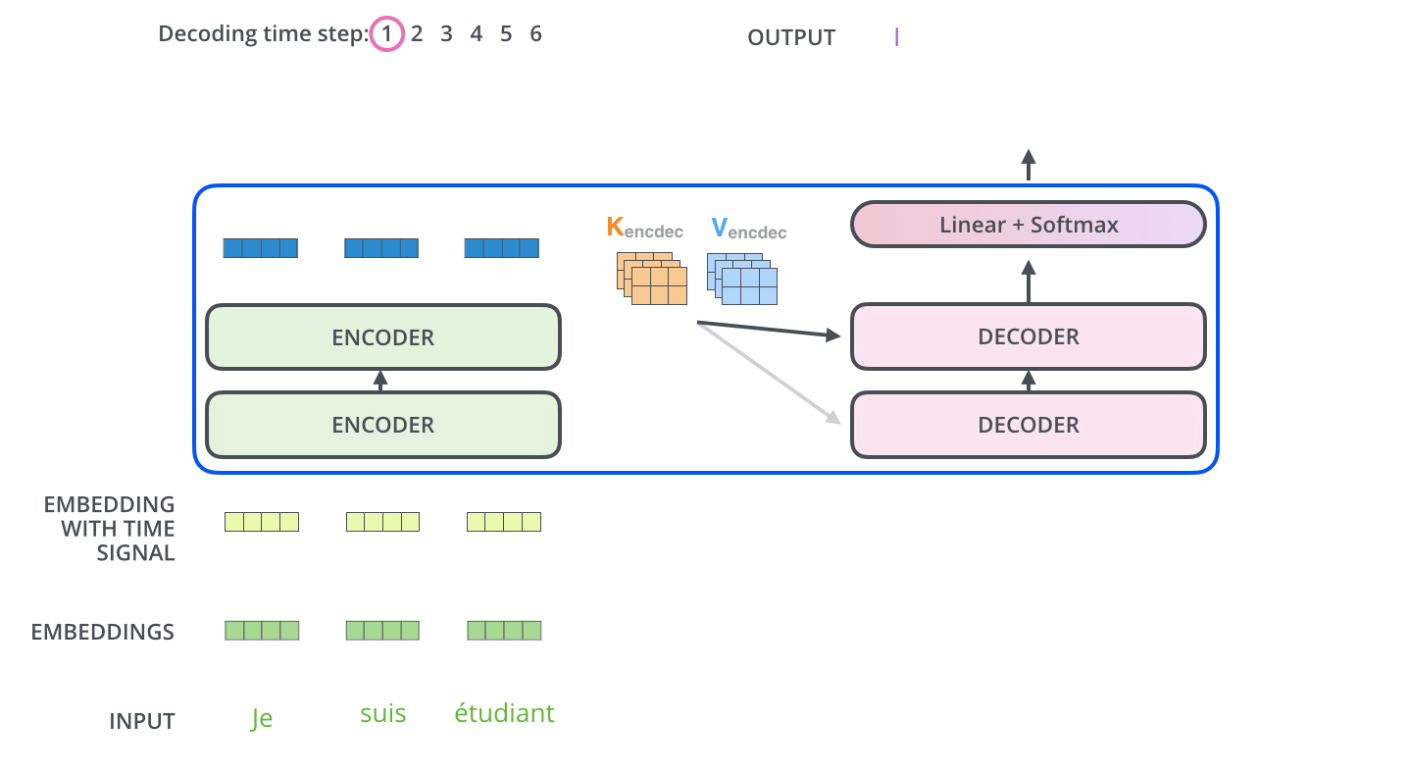
解码器中的自注意力层与编码器中的自注意力层的工作方式略有不同:
在解码器中,自注意力层只能关注输出序列中较早的位置。这是通过-inf在自注意力计算的softmax步骤之前屏蔽较晚的位置(将其设置为0)来实现的。
"编码器-解码器注意力"层的工作原理与多头自注意力类似,只是它从下一层创建查询矩阵,并从编码器堆栈的输出中获取键和值矩阵。
(四)最终线形层和softmax层
解码器栈输出一个浮点数向量。我们如何将其转换为单词?这就是最后一个线性层的任务,其后紧接着一个 Softmax 层。
线性层是一个简单的全连接神经网络,它将解码器堆栈产生的向量投影到一个更大的向量,称为 logits 向量。
参考: