ps:最快速度了解一下下,当扩充了
| 对比维度 | 全连接神经网络(普通神经网络) | 卷积神经网络(CNN) |
|---|---|---|
| 网络结构 | 输入层→全连接层→全连接层→输出层仅包含全连接层 | 输入层→卷积层→池化层→卷积层→池化层→全连接层→输出层新增卷积层、池化层 |
| 连接方式 | 全局连接:每个神经元与上一层所有神经元相连 | 局部连接 + 滑动窗口:仅连接相邻的局部数据,卷积核滑动遍历 |
| 参数数量 | 参数量极大,容易参数爆炸、过拟合、训练慢 | 参数共享,参数量极少,训练快、不易过拟合 |
| 特征提取 | 无法自动提取特征,必须人工定义规则(如:心率 > 100 为异常) | 自动分层提取特征:小波动→组合模式→整体波形 |
| 对顺序 / 位置的敏感度 | 完全不敏感,打乱数据结果不变 | 高度敏感,尊重时序 / 空间结构,具备平移不变性 |
| 适合的数据类型 | 表格数据、低维无顺序数据 | 图像、语音、心率时序、波形等有结构 / 顺序的数据 |
| 心率检测适用场景 | 简单统计判断(平均心率超标) | 专业波形识别(早搏、陡升、心律失常等形态异常) |
图像知识
- 知道图像的基本概念
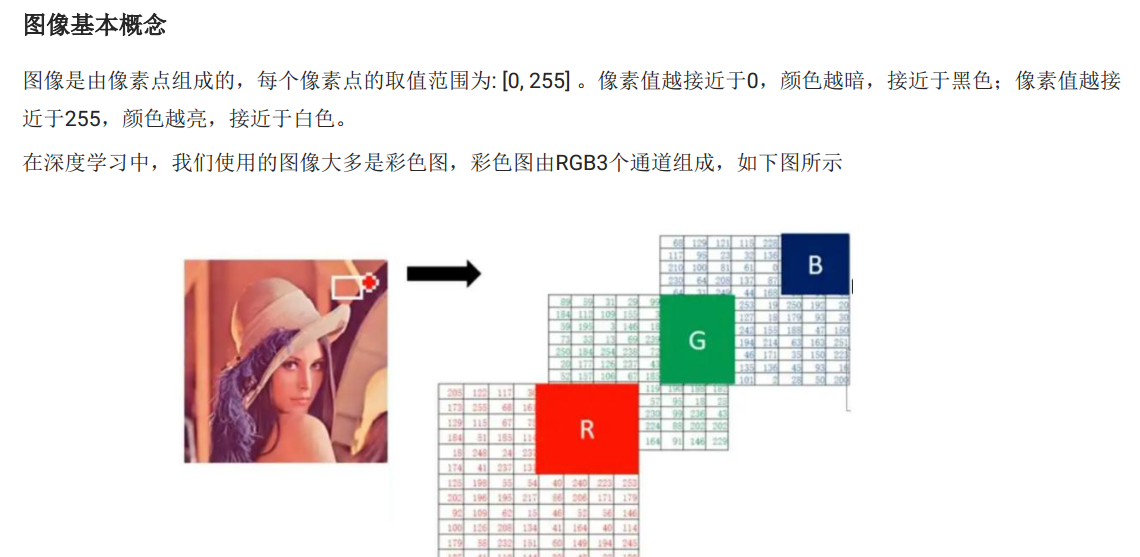
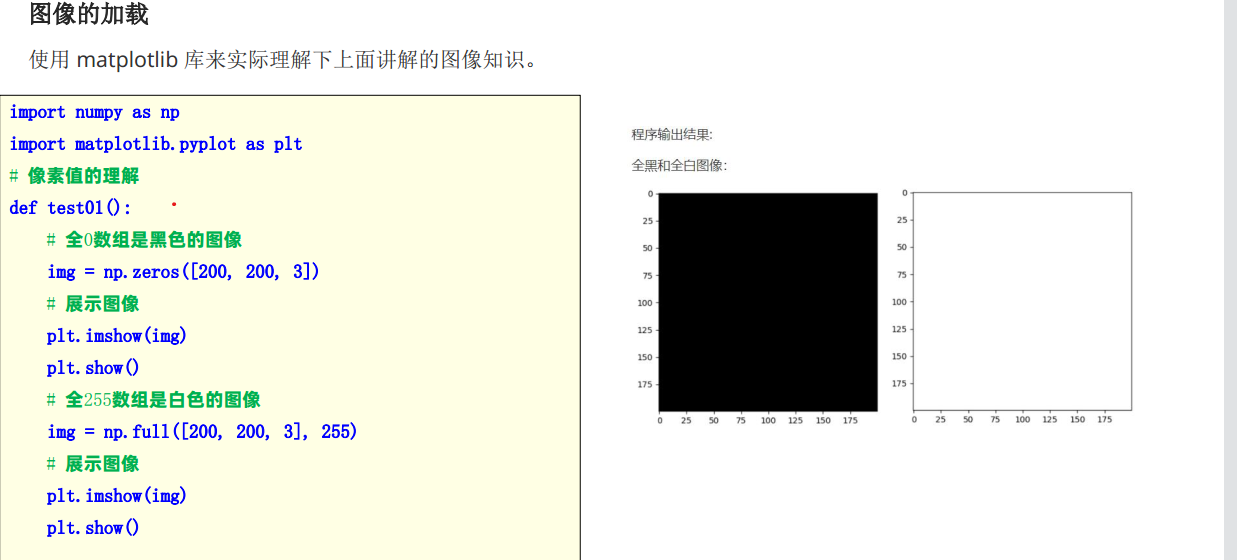
- 掌握使用matplotlib加载图片方法
Plt.imread()
Plt.imshow()

640(高):图片的纵向像素数量640(宽):图片的横向像素数量3(通道):RGB 三通道彩色图像
CNN
| 层级 | 核心作用 | 通俗理解 | 能干什么 | 核心特点 | 形象比喻 |
|---|---|---|---|---|---|
| 卷积层 | 自动提取图像 / 时序数据特征 | 拿一个小窗口,在整张图上慢慢滑动扫描 | 找边缘、找纹理、找形状、找波形尖峰 / 波动 | 局部连接、参数共享、自动学特征,不用人工写规则 | 专门看细节、找轮廓的眼睛 |
| 池化层 | 压缩数据、降维、保留关键特征 | 把卷积层扫完的大图,缩成小图,只留重点,去掉冗余 | 缩小图片尺寸、减少参数量、防止过拟合、保留主要特征 | 只保留区域最大值 / 平均值,不学习参数、简化数据 | 给图片缩大小、提纯关键信息,删多余细节 |
全连接层用来输出想要的结果。
卷积层
| 学习要点 | 核心概念 | 主要作用 |
|---|---|---|
| 1. 卷积层计算过程 | 用卷积核(小矩阵) 在输入图像上按步长滑动,逐个局部区域做加权求和,叠加偏置,得到新数据。 | 从原始图像中自动提取边缘、纹理、轮廓、细节等浅层、深层特征。 |
Pytorch API
- nn.Conv2d :PyTorch 中专门用于构建二维卷积层的工具
- 负责自动提取图像特征(边缘、纹理、形状、轮廓)
- 通过调整 5 个参数,自由控制特征种类、特征图大小、扫描范围
- 是搭建卷积神经网络(CNN)最核心的基础模块
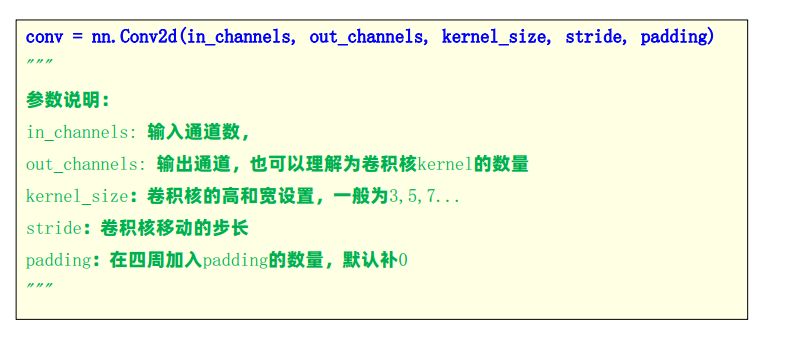
| 阶段 | 数据 | 形状 / 类型 | 作用 |
|---|---|---|---|
| 原始输入 | data/img.jpg 图像文件 |
读取后是 numpy 数组,形状 (640, 640, 3) |
原始彩色图像,高 640、宽 640、RGB 三通道 |
| 第一步处理后 | img = torch.tensor(img).permute(2, 0, 1) |
torch.Tensor,形状 (3, 640, 640) |
把通道维度从最后移到最前面,适配 PyTorch 的通道优先格式 |
| 第二步处理后 | img = img.unsqueeze(0) |
torch.Tensor,形状 (1, 3, 640, 640) |
增加一个batch维度,变成批量大小为 1 的张量 |
| 卷积层最终输入 | img.to(torch.float32) |
torch.float32 张量,形状 (1, 3, 640, 640) |
送入 nn.Conv2d 的最终数据,符合 PyTorch 输入格式:(批量数, 通道数, 高度, 宽度) |
| 维度顺序 | 数值 | 含义 | 通俗解释 |
|---|---|---|---|
第 1 维:N(Batch Size) |
1 |
批量大小 | 表示一次输入模型的样本数量,这里就是「1 张图片」 |
第 2 维:C(Channels) |
3 |
通道数 | 表示数据的特征通道,这里是「RGB 三通道彩色图」(红、绿、蓝各一个通道) |
第 3 维:H(Height) |
640 |
图像高度 | 图片纵向有 640 个像素 |
第 4 维:W(Width) |
640 |
图像宽度 | 图片横向有 640 个像素 |
torch.Size(1, 3, 319, 319)
| 项目 | 内容 |
|---|---|
| 代码作用 | 打印 卷积后输出的特征图形状 |
| 输出格式 | 一定会输出 4 个数字 |
| 4 个数字依次代表 | 几张图,输出通道数,高度,宽度 |
| 通俗理解 | 告诉你:卷积处理完后,得到了多大的特征图 |
| 核心意义 | 查看数据尺寸是否正确,避免网络报错 |
池化层
- 掌握池化层计算过程
池化层 (Pooling) 降低维度, 从而减少计算量、减少内存消耗,并提高模型的鲁棒性
- 掌握PyTorch池化层API
池化层通常位于卷积层之后,它通过对卷积层输出的特征图进行下采样,保留最重要的特征信息,同时丢弃一些不重
要的细节
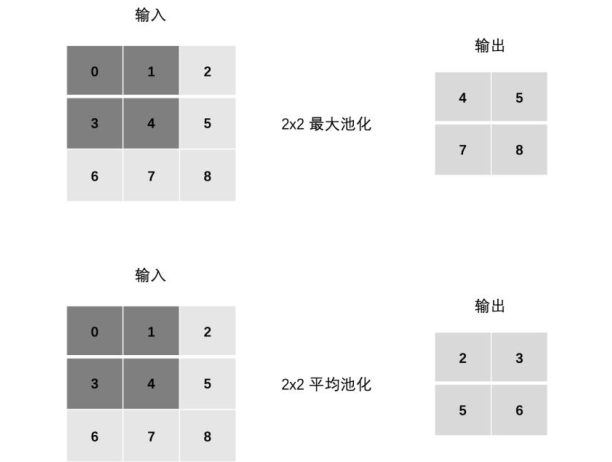
PyTorch 池化 API
最大池化
nn.MaxPool2d(kernel_size=2, stride=2, padding=1)
平均池化
nn.AvgPool2d(kernel_size=2, stride=1, padding=0)
图像分类案例 自写
- 了解CIFAR10数据集 2. 掌握分类网络搭建 3. 掌握模型构建流程
了解 CIFAR10 数据集
搭建卷积神经网络
编写训练函数
编写预测函数
导入一下工具包
数据集介绍
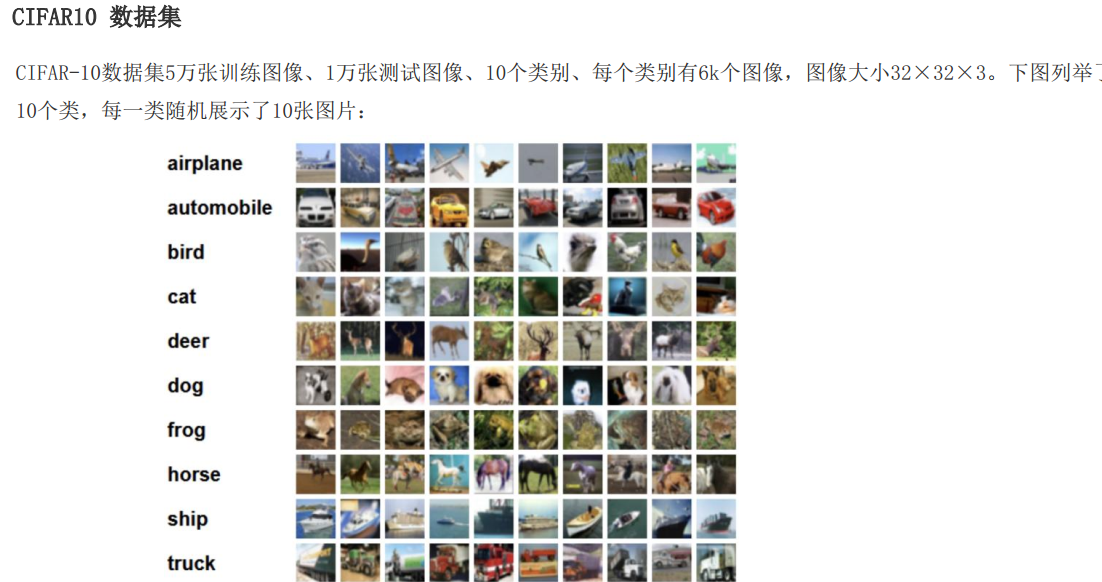
一句话:它是计算机视觉里,专门用来训练和测试图像分类模型的「公开标准图片数据集」,相当于给 AI 做 "看图认东西" 练习题的题库。
| 项目 | 具体内容 | 通俗理解 |
|---|---|---|
| 本质 | 大量标注好的图片集合 | 给 AI 做 "看图认类别" 的练习题库 |
| 规模 | 6 万张图片(5 万训练 + 1 万测试) | 训练用 5 万张题,考试用 1 万张题 |
| 类别 | 10 个固定类别 | 飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船、卡车 |
| 图像大小 | 32×32×3(像素) | 很小的彩色图,比手机头像还小,方便快速训练 |
| 作用 | 训练、测试图像分类模型 | 新手入门 CNN 最常用的 "练手数据集" |
PyTorch 中的 torchvision.datasets 计算机视觉模块封装了 CIFAR10 数据集, 使用方法如下
python
# 导入需要的库
import torchvision
from torchvision.datasets import CIFAR10
from torchvision.transforms import ToTensor
import matplotlib.pyplot as plt
# 定义函数:创建并返回CIFAR10训练集和测试集
def create_dataset():
"""
功能:加载CIFAR10数据集
返回:训练集train、测试集valid
"""
# 1. 加载训练集数据
# root='data':数据集下载后存放在当前目录的data文件夹下
# train=True:表示加载训练集
# transform=ToTensor():
# - 把PIL.Image格式的图片,转换成PyTorch能处理的Tensor张量
# - 同时自动把像素值从0~255归一化到[0.0, 1.0],方便模型计算
train = CIFAR10(
root='data',
train=True,
transform=ToTensor(),
download=True # 自动下载数据集(第一次运行需要)
)
# 2. 加载测试集数据
# train=False:表示加载测试集
valid = CIFAR10(
root='data',
train=False,
transform=ToTensor(),
download=True
)
# 把训练集和测试集返回给调用这个函数的地方
return train, valid
# 主程序入口:当你直接运行这个文件时,下面的代码会执行
if __name__ == '__main__':
# 调用上面定义的create_dataset函数,拿到训练集和测试集
train_dataset, valid_dataset = create_dataset()
# 打印数据集的类别映射:比如'airplane'对应数字0,'car'对应数字1
print("数据集类别:", train_dataset.class_to_idx)
# 打印训练集数据的形状:(50000, 32, 32, 3)
# 含义:50000张图片,每张图片是32×32像素,3个RGB通道
print("训练集数据集:", train_dataset.data.shape)
# 打印测试集数据的形状:(10000, 32, 32, 3)
print("测试集数据集:", valid_dataset.data.shape)
# 用matplotlib展示一张训练集里的图片
plt.figure(figsize=(2, 2)) # 创建一个2×2大小的画布
plt.imshow(train_dataset.data[1]) # 展示训练集里第2张图片(索引从0开始)
plt.title(train_dataset.targets[1]) # 把这张图片的标签(数字类别)设为标题
plt.show() # 显示图片窗口
- 自动下载 CIFAR10 数据集到
./data文件夹 - 控制台打印出:
- 10 个类别的名称和对应数字
- 训练集、测试集的图片数量和尺寸
- 弹出一个窗口,显示训练集里的第 2 张图片,标题是它的类别数字
流程
python
自己的图片(JPG/PNG 照片)
↓
【图片预处理】
统一尺寸 → 缩放到固定大小(如 32×32 / 224×224)
统一通道 → 转为 RGB 三通道彩色图
像素归一化 → 把 0~255 缩成 0~1 或 -1~1,方便模型计算
↓
【转为数字矩阵】
像素 → 张量 Tensor
维度调整为模型标准格式:(批量数, 通道数, 高度, 宽度)
↓
【输入层】
接收标准化后的数字张量
不做计算,只负责传递数据
↓
===============================
【前向传播开始】
概念:数据从输入层开始,依次经过卷积、激活、池化、全连接
按固定网络层级单向流动,逐层计算特征,最终输出预测结果
===============================
↓
【第一层卷积层】
卷积核滑动扫描图片
提取浅层特征:边缘、线条、基础纹理
输出多张特征图
↓
【激活函数 ReLU】
加入非线性能力
让网络能学习复杂特征(必须加!)
↓
【第一层池化层】
缩小特征图尺寸(宽高减半)
保留关键信息,降低计算量
↓
【第二层卷积层】
继续扫描特征图
提取中层特征:局部形状、部件轮廓
↓
【激活函数 ReLU】
再次增强非线性学习能力
↓
【第二层池化层】
再次压缩尺寸
进一步提炼关键特征
↓
(可重复 N 轮:卷积 → ReLU → 池化)
提取高层抽象特征:整体轮廓、物体结构、语义信息
↓
【展平层 Flatten】
把多维特征图拉直成一维长向量
适配全连接层输入格式
↓
【全连接层】
对所有特征进行加权融合
建立特征与类别之间的联系
↓
【激活函数 ReLU】
增强分类判断的表达能力
↓
【输出层】
输出每个类别的原始预测分数
===============================
【前向传播结束】
概念:完成一次从原图到预测分值的完整推理,只做正向计算,不更新参数
===============================
↓
【Softmax 函数】
把分数转为概率(总和=1)
概率最高 = 模型判断的类别
↓
【损失函数】
计算预测结果与真实标签的误差
衡量前向传播预测的对错程度
↓
【反向传播】
概念:根据损失误差,从后往前逐层求导,传回每一层
↓
【优化器】
根据反向传播传回的误差,自动更新卷积核、全连接层参数
让模型下一次前向传播预测更准确-
前向传播 输入数据按网络结构从上到下依次经过各层,逐层计算特征,最后输出预测结果;只做正向计算,不修改网络参数。
-
反向传播 根据损失函数的误差,从后往前倒着传回误差,配合优化器更新权重参数,用来训练模型、降低误差。
搭建图像分类网络
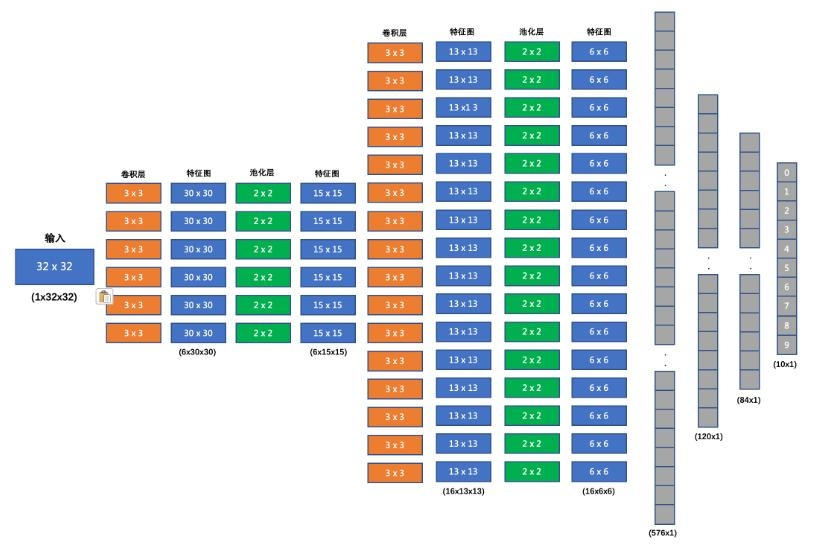
我们要搭建的网络结构如下:
-
输入形状: 32x32
-
第一个卷积层输入 3 个 Channel, 输出 6 个 Channel, Kernel Size 为: 3x3
-
第一个池化层输入 30x30, 输出 15x15, Kernel Size 为: 2x2, Stride 为: 2
-
第二个卷积层输入 6 个 Channel, 输出 16 个 Channel, Kernel Size 为 3x3
-
第二个池化层输入 13x13, 输出 6x6, Kernel Size 为: 2x2, Stride 为: 2
-
第一个全连接层输入 576 维, 输出 120 维
-
第二个全连接层输入 120 维, 输出 84 维
-
最后的输出层输入 84 维, 输出 10 维
我们在每个卷积计算之后应用 relu 激活函数来给网络增加非线性因素
构建网络代码实现如下
python
# 导入 PyTorch 神经网络工具箱
import torch
import torch.nn as nn
# ====================== 1. 模型构建 ======================
# 定义一个类,专门用来搭建图像分类模型(固定写法)
# nn.Module 是所有神经网络的父类,必须继承
class ImageClassification(nn.Module):
# ====================== 2. 定义网络结构 ======================
# __init__:初始化函数,用来定义所有层(卷积、池化、全连接)
def __init__(self):
# 固定写法:调用父类初始化
super(ImageClassification, self).__init__()
# -------------------- 第一组卷积 + 池化 --------------------
# 卷积层1:输入3通道,输出6通道,卷积核3×3,步长1
# 作用:提取图片的边缘、线条、纹理
self.conv1 = nn.Conv2d(3, 6, stride=1, kernel_size=3)
# 最大池化层1:窗口2×2,步长2
# 作用:把特征图宽高缩小一半,保留关键信息
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
# -------------------- 第二组卷积 + 池化 --------------------
# 卷积层2:输入6通道,输出16通道,卷积核3×3,步长1
# 作用:提取更复杂的特征(形状、局部结构)
self.conv2 = nn.Conv2d(6, 16, stride=1, kernel_size=3)
# 最大池化层2
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
# -------------------- 全连接层 --------------------
# 全连接层1:输入576维,输出120维
self.linear1 = nn.Linear(576, 120)
# 全连接层2:输入120维,输出84维
self.linear2 = nn.Linear(120, 84)
# 输出层:输入84维,输出10类(对应CIFAR10的10个分类)
self.out = nn.Linear(84, 10)
# ====================== 3. 定义前向传播(数据怎么走) ======================
# forward:数据流向,决定图片怎么一步步变成结果
def forward(self, x):
# x 就是输入的图片张量
# 第一步:卷积1 → 激活ReLU → 池化1
x = torch.relu(self.conv1(x))
x = self.pool1(x)
# 第二步:卷积2 → 激活ReLU → 池化2
x = torch.relu(self.conv2(x))
x = self.pool2(x)
# 第三步:展平(把二维特征图拉成一维向量)
# 作用:为了能输入到全连接层
x = x.reshape(x.size(0), -1)
# 第四步:全连接层 + ReLU激活
x = torch.relu(self.linear1(x))
x = torch.relu(self.linear2(x))
# 第五步:输出最终结果(10个类别的分数)
return self.out(x)- conv1/conv2 = 提取特征
- pool1/pool2 = 缩小图片
- relu = 让网络变聪明,学复杂特征
- linear = 做分类判断
- forward = 规定数据怎么走
输入 → conv1 → ReLU → pool1 → conv2 → ReLU → pool2 → 展平 → linear → 输出
python→ conv1 卷积层(提取浅层纹理边缘特征) → ReLU 激活函数(引入非线性、学复杂特征) → pool1 池化层(下采样缩尺寸、保留关键特征) → conv2 卷积层(提取中层形状结构特征) → ReLU 激活函数(增强非线性表达) → pool2 池化层(二次下采样、精简降维) → 展平层(多维特征转一维向量) → 全连接层(特征融合、关联类别) → 输出层(输出分类预测分值)
前向传播 输入数据按网络结构从上到下依次经过各层,逐层计算特征,最后输出预测结果;只做正向计算,不修改网络参数。
反向传播 根据损失函数的误差,从后往前倒着传回误差,配合优化器更新权重参数,用来训练模型、降低误差。
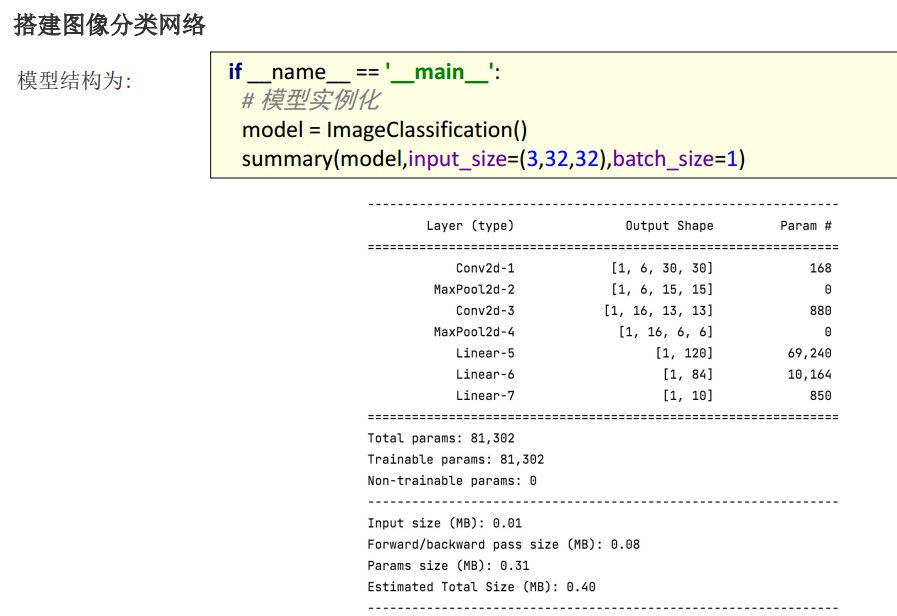
- 第一行 = 创建模型
- 第二行 = 查看模型长什么样、每层输出多大、有多少参数
| 层名 | 输出形状 | 含义(大白话) |
|---|---|---|
Conv2d-1 |
[1, 6, 30, 30] |
输入 1 张 3 通道 32×32 的图,卷积后变成 1 张 6 通道、30×30 的特征图,提取了边缘 / 纹理特征 |
MaxPool2d-2 |
[1, 6, 15, 15] |
池化后,特征图宽高减半,变成 1 张 6 通道、15×15 的特征图,无参数 |
Conv2d-3 |
[1, 16, 13, 13] |
第二次卷积后,变成 1 张 16 通道、13×13 的特征图,提取更复杂的形状特征 |
MaxPool2d-4 |
[1, 16, 6, 6] |
第二次池化后,宽高再次减半,变成 1 张 16 通道、6×6 的特征图,无参数 |
Linear-5 |
[1, 120] |
展平后进入全连接层,输出 120 维特征向量 |
Linear-6 |
[1, 84] |
第二层全连接,输出 84 维特征向量 |
Linear-7 |
[1, 10] |
输出层,输出 10 个类别的预测分数(对应 CIFAR10 的 10 个类别) |
编写训练函数
在训练时,使用多分类交叉熵损失函数,Adam 优化器. 具体实现代码如下
python
# ====================== 训练函数 ======================
# 功能:把模型喂给数据,让它学习、变聪明
# model:你的CNN网络
# train_dataset:训练用的图片数据集
def train(model, train_dataset):
# 1. 定义损失函数(CrossEntropyLoss 交叉熵)
# 作用:计算模型预测错了多少,误差有多大
criterion = nn.CrossEntropyLoss()
# 2. 定义优化器(Adam)
# 作用:根据误差,自动调整模型参数,让模型越练越准
# lr=1e-3:学习率,控制每次调整的步子大小
optimizer = optim.Adam(model.parameters(), lr=1e-3)
# 3. 训练总轮数:把全部数据看 100 遍
epoch = 100
# 开始循环训练
for epoch_idx in range(epoch):
# 构建数据加载器
# 作用:把数据集打包,一批一批喂给模型
dataloader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
sam_num = 0 # 记录已经训练了多少张图片
total_loss = 0.0 # 记录这一轮总的误差值
start = time.time() # 记录开始时间,算跑多久
# ====================== 核心训练循环 ======================
# 把数据集里的图片,一张一张喂给模型
for x, y in dataloader:
# x = 图片数据(张量)
# y = 图片真实标签(猫/狗/车...)
# 【前向传播】
# 把图片输入模型,得到预测结果
output = model(x)
# 【计算损失】
# 对比预测结果和真实答案,算误差
loss = criterion(output, y)
# 【反向传播三部曲】
optimizer.zero_grad() # 清空上一次的梯度(必须清!)
loss.backward() # 反向传播,计算梯度(误差往回传)
optimizer.step() # 更新模型参数(改错)
# 统计这一轮的总损失
total_loss += loss.item() * len(y)
sam_num += len(y)
# 打印这一轮的训练结果
print('epoch:%2s loss:%.5f time:%.2fs' %(epoch_idx + 1, total_loss / sam_num, time.time() - start))
# 训练全部结束后,保存训练好的模型参数到文件
torch.save(model.state_dict(), 'model/image_classification.pth')- 准备工具 :准备好损失函数 (算对错)、优化器(改错)
- 循环 100 轮:把所有图片给模型看 100 遍
- 逐批训练 :
- 图片输入模型 → 前向传播 → 出预测结果
- 算损失(错多少)
- 反向传播(把误差传回每一层)
- 优化器更新参数(模型改错)
- 打印进度:每轮显示当前误差、耗时
- 保存模型:训练完,把训练好的模型存成文件
输入图片 ↓(前向传播) 卷积→激活→池化→卷积→激活→池化→展平→全连接→输出 ↓ 损失函数(算误差) ↓(反向传播) 优化器(更新参数)
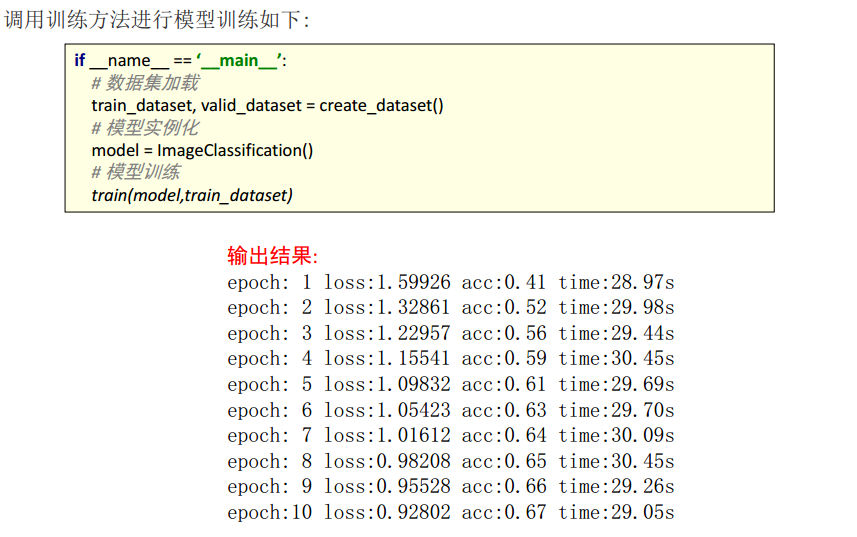
| 输出名词 | 意思(人话) | 代表什么 |
|---|---|---|
| epoch: 1 | 第 1 轮训练 | 模型把所有图片完整看了一遍 |
| loss:1.59926 | 误差值 | 数字越小 = 模型越准 |
| acc:0.41 | 准确率 | 模型答对了 41% 的题目 |
| time:28.97s | 耗时 | 这一轮花了 29 秒 |
编写预测函数
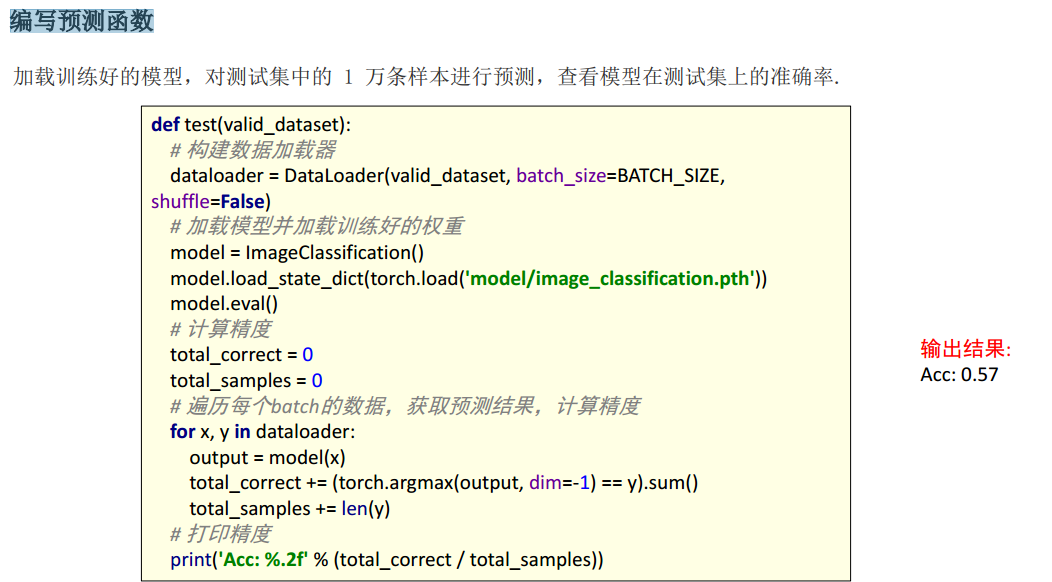
总结
掌握模型构建流程
加载数据集
模型构建
模型训练
模型测试
从程序的运行结果来看,网络模型在测试集上的准确率
并不高。我们可以从以下几个方面来进行优化:
-
增加卷积核输出通道数
-
增加全连接层的参数量
-
调整学习率
-
调整优化方法
-
修改激活函数
-
等等...