模块 0:开篇与问题导入
1. 我们要解决什么问题?------ 二分类问题的再思考
在机器学习的诸多任务中,二分类(Binary Classification)是最基础也最核心的问题之一。简单来说,当我们有一堆已知类别的数据(比如:一部分是猫,一部分是狗;或者一部分是良性肿瘤,一部分是恶性肿瘤),我们希望算法能学到一个"规则",当新数据到来时,能准确判断它属于哪一类。
在数学上,如果数据表现为空间中的点,这个"规则"通常就是一个分离超平面(Separating Hyperplane)。在二维平面中,超平面是一条直线;在三维空间中,它是一个平面;在更高维的空间中,它就被统称为超平面。
2. 从感知机说起:多个分离超平面的困惑
在学习 SVM 之前,你可能接触过感知机(Perceptron)模型。感知机的目标很简单:只要能找到一个超平面,把两类点完全分开就行。
但这里隐藏着一个巨大的困惑:如果数据是线性可分的,那么能把它们分开的超平面有无数个。 想象你在桌子上放了一把红豆和一把绿豆,你要在它们中间放一根筷子隔开。只要中间有空隙,这根筷子稍微倾斜一点、平移一点,都能完美地把两堆豆子分开。
感知机会在找到任意一个满足条件的超平面时就停止工作。但是,这无数个超平面在面对"未知的未来数据"时,表现是一样的吗?显然不是。有的超平面离某类数据太近,稍微有一点噪声,新数据就可能被分错。
3. 直觉切入:哪一个分离超平面"最好"?
直觉告诉我们:最好的分离超平面,应该恰好在两类数据的"正中间"。 它不仅要把两类点分开,还要尽可能地远离距离它最近的那些数据点。这就好比我们在两国边境之间设立非武装缓冲区,缓冲区越宽,两国发生摩擦的概率就越小,和平的"信心"就越足。
这个缓冲区,在 SVM 中就被称为间隔(Margin)。SVM 的核心直觉就是:寻找那个能使"间隔"最大化的分离超平面。
想象一张桌面上画着一个坐标系,左上角有一群红点,右下角有一群蓝点,两者之间有明显的空隙(线性可分)。
-
你可以在这个空隙里画出无数条直线,把红点和蓝点完美隔开(这就像是感知机的做法)。
-
现在,你拿来一块有一定宽度的透明长方形玻璃砖,放在这两群点中间。
-
你不断地加宽这块玻璃砖,同时微调它的角度,直到玻璃砖的上下两个边缘分别"卡住"了几个最突出的红点和蓝点,再也无法继续变宽为止。
-
此时,这块玻璃砖正中间的那条中心线,就是我们要找的"最好"的分离超平面;而玻璃砖的宽度,就是最大化的"间隔(Margin)"。
这把"不断加宽直到卡住"的尺子,就是支持向量机(SVM)最核心的几何直觉。
4. 基本知识点
-
线性可分与线性不可分的直观定义:
-
线性可分: 存在至少一个线性超平面,能够将不同类别的数据点没有任何错误地完全分在超平面的两侧。
-
线性不可分: 无论怎么画直线(或平面),总会有数据点被分错,无法用单一的线性结构完美切割。
-
-
点到直线的距离公式(复习):
在二维平面中,一条直线方程可以表示为
。空间中任意一点
在高维空间中,我们将超平面表示为
-
分类的"信心"从何而来?
如果一个数据点距离分离超平面很远,我们非常确信它属于某一类(高置信度);如果一个数据点紧贴着超平面,稍微有一点测量误差或扰动,它就可能跨界(低置信度)。因此,超平面到最近点的距离(间隔)越大,我们对分类结果的整体信心就越足。
模块 1:线性可分支持向量机(硬间隔最大化)
1.1 函数间隔与几何间隔
我们在模块0中直观感受了"间隔(Margin)"。在数学上,为了精确定义它,我们需要引入两个核心概念:函数间隔 和几何间隔。
知识点
分类超平面方程:
在特征空间中,我们将分离超平面记为 。
其中, 是超平面的法向量,决定了超平面的方向;
是截距项,决定了超平面到原点的距离。
函数间隔(Functional Margin)的定义:
对于给定的训练集,一个样本点 (其中
表示类别)到超平面的函数间隔定义为:
-
直觉解释:
-
整个数据集的函数间隔
函数间隔的致命缺点:缩放问题 函数间隔有一个严重的问题。如果我们将参数 和
同时乘以一个倍数(比如变成
和
),超平面的位置完全没有改变 (因为
等价于
),但是,计算出的函数间隔
却变成了原来的两倍! 这显然不合理。我们需要一个不受参数成比例缩放影响的指标。
几何间隔(Geometric Margin)的定义:
为了解决缩放问题,我们将超平面的法向量 进行归一化(除以它的模长
)。这就像是物理中的单位向量。
样本点 到超平面的几何间隔定义为:
-
几何意义: 几何间隔正是我们在模块0中提到的、真实世界中点到直线的垂直物理距离(带正负号)。
-
不变性: 无论 w 和b 怎么成比例缩放,||w|| 也会同比例缩放,比值
实例:计算函数间隔和几何间隔演示缩放问题
假设有一个正样本点 ,类别
。
有一个超平面 :
。这里
,
。
-
计算函数间隔
-
计算几何间隔
现在,我们将 的方程参数放大 10 倍,得到超平面
:
。这里
,
。
-
计算
-
计算
结论: 超平面没动,几何间隔(真实距离)没变,但函数间隔随参数缩放而改变了。
1.2 硬间隔最大化原始问题
现在我们明白了,要找到"最好"的超平面,就是要最大化最小的几何间隔 。这被称为硬间隔最大化(Hard Margin Maximization)。
知识点
-
直观的优化目标:
我们要找一组
写成数学式子就是:
(注:s.t. 是 subject to 的缩写,意为"受限于以下条件")
转化目标函数:利用函数间隔的固定化技巧
因为几何间隔 ,上面的优化问题可以改写为:
还记得刚才函数间隔的"缩放问题"吗?现在它反而成了我们的神兵利器!因为无论怎么成比例缩放 和
,几何间隔(也就是我们要优化的核心目标)是不变的。
因此,我们可以强制规定 最小的函数间隔 。这就好比我们在坐标系里随意画了一条线,然后强制把最近点到这条线的函数距离标为"1个单位"。
代入 后,目标函数变成了最大化
。
凸二次规划的标准形式:
在数学优化中,最大化 不太好求解,等价于最小化||w||,我们做个公式优化,最小化||w||也等价于最小化
。(加个
和平方是为了后续求导方便,不影响最优解)。
于是,我们得到了 SVM 最经典的基本型(原始问题):
这是一个标准的凸二次规划(Convex Quadratic Programming, QP)问题。目标函数是二次的,约束条件是线性的,这意味着它有唯一的全局最优解,没有令人头疼的局部最优问题!
实例:用简单的三点数据集写出完整的数学规划问题
假设我们的训练集只有 3 个点:
正类 ():
,
负类 ():
将这三个点代入 SVM 的基本型中,我们得到具体的优化问题:
目标函数:
约束条件:
对于点 (正类):
对于点(正类):
对于点 (负类):
只要将这个具体的凸二次规划问题交给优化求解器,就能直接算出最优的 和
。
1.3 支持向量与间隔边界
在我们列出的约束条件 中,大于号和等号有着本质的区别。
原子知识点
-
什么是支持向量(Support Vector)?
在线性可分的情况下,训练数据集的样本点中,使得约束条件等号成立的样本点 ,就被称为支持向量。
即满足
这些点距离分离超平面最近。
-
间隔边界:
正类的支持向量所在的超平面方程为:
负类的支持向量所在的超平面方程为:
这两个平行的超平面被称为间隔边界。
我们要找的真正的分离超平面
-
模型的稀疏性(SVM 最神奇的特性):
在决定最终分离超平面位置时,只有支持向量起作用 ,其他所有的非支持向量(满足
如果我们将非支持向量从数据集中全部删掉,再重新训练 SVM,得到的超平面和原来一模一样!
这就好比两军对垒,决定战线位置的只有站在最前线交火的士兵(支持向量),后方大本营里的人(非支持向量)就算撤走,战线也不会改变。这种特性被称为模型的稀疏性,它极大地提高了模型的泛化能力和计算效率。
1.4 拉格朗日对偶性(深入底层)
目前为止,我们构造出了一个凸二次规划问题。虽然可以直接用现成的求解器计算,但为了后续引入"核技巧"(解决非线性问题),我们必须用数学手法将其转化为对偶问题。这一步是 SVM 从直觉走向高阶算法的分水岭。
知识点
拉格朗日函数构造:
为了处理带有不等式约束的优化问题,我们引入拉格朗日乘子(Lagrange Multiplier) 。
对每一个约束条件分配一个乘子,构造拉格朗日函数:
(注意:中括号里的部分其实就是把约束条件 移项过来的形式)
极大极小博弈:
我们的原始优化问题,可以等价地写成一个极小极大问题:
在凸优化理论中,只要满足一定条件(Slater条件),上面那个博弈的出场顺序是可以交换的,且结果完全一样。这就叫强对偶性。
根据拉格朗日对偶性(强对偶定理),由于我们的问题是凸优化且满足Slater条件,极小极大可以交换位置,变成对偶问题:
对偶问题的推导(分两步):
先对 和
求极小: 分别对
和
求偏导数并令其为0。
将结果代回拉格朗日函数: 把求得的 和
代回
中,经过一系列化简(主要是利用上述两个条件消去
和
),我们得到一个只包含变量
的函数。
这就是 SVM 的核心对偶形式 !注意,数据点之间只以内积 的形式出现,这是后续"核技巧"成立的基石。
KKT条件看支持向量:
在对偶理论中,最核心的是 KKT(Karush-Kuhn-Tucker)互补松弛条件:
这个条件非常严苛。它告诉我们,对于任意一个样本点 ,只有两种可能:
-
-
通过 KKT 条件,我们从数学的最底层,完美地解释了为什么 SVM 具有"稀疏性"------大部分 都会被优化为 0。
在真实世界中,数据往往不会像我们想象的那么完美。上一模块我们推导的"硬间隔最大化"建立在一个非常苛刻的前提下:数据必须完全线性可分。
但在实际应用中,只要出现一个调皮的"噪点"跑到了对方的阵营里,硬间隔的数学模型就会瞬间崩溃,直接告诉你"无解"。为了让 SVM 从一个理想化的数学玩具变成真正能在工业界大杀四方的利器,我们需要赋予它一种"包容错误"的能力。
这就是我们现在要探索的模块 2:线性支持向量机(软间隔最大化)。
模块 2:线性支持向量机(软间隔最大化)
2.1 从硬间隔到软间隔的动机
原子知识点
-
理想与现实的差距: 真实数据由于测量误差、异常事件等原因,很少完全线性可分。总会有那么几个离群点(Outliers)混在敌对阵营中。
-
硬间隔的脆弱性: 回想我们在模块0做的思想实验,那块在两类数据中间不断加宽的"玻璃砖"。如果这时突然有一颗红豆掉在了绿豆堆里,这块玻璃砖不仅无法变宽,甚至连放都放不进去。在数学上,这意味着不存在满足所有约束条件
允许部分点"犯错"的思想: 既然无法做到 100% 完美,不如我们退一步,允许少数数据点跨越间隔边界,甚至跨越分类超平面。只要绝大多数点分对了,并且这个"间隔"足够大,它依然是一个好模型。这种允许存在一定误差的间隔,被称为软间隔(Soft Margin)。
实例:直观感受硬间隔的崩溃
想象在一个只有 10 个样本的数据集中,9 个正样本在左边,9 个负样本在右边,本来中间有一条极宽的马路。此时,如果把第 10 个负样本强行扔到最左边去。硬间隔 SVM 会因为找不到一条绝对切分所有点的直线而直接报错;而软间隔 SVM 则会"战略性放弃"这一个异常点,依然把直线画在那条宽阔的马路上。
2.2 松弛变量与惩罚参数
为了让数学公式懂得"包容",我们需要引入两个极其优雅的变量:松弛变量(Slack Variable)和惩罚参数(Penalty Parameter)。
知识点
引入松弛变量 :
原本的硬约束是:函数间隔必须大于等于 1,即 。
现在,我们给每个样本发一张"豁免卡" 。约束条件变成了:
的几何意义:
-
-
-
-
所以,
目标函数加入惩罚项:
如果我们无限量地发放"豁免卡",模型就会变成乱分一气。所以我们要对"犯错"进行惩罚。我们将目标函数修改为:
惩罚参数 的作用:
决定了我们要以多大的力度去惩罚错误。这是 SVM 中最重要的超参数!
-
C 很大(极端情况
-
实例:调节 C 的权衡
假如你在设计一个银行的反欺诈模型。如果 C设置得特别大,模型为了抓住所有坏人,可能会变得神经质,把很多好人也冻结账户(过拟合);如果 C 设置得比较小,模型心态比较平和,间隔很大,虽然放过了一两个坏人,但正常用户的体验会好很多(泛化能力强)。
2.3 软间隔的对偶问题
神奇的是,尽管我们在原始问题中引入了松弛变量 和参数
,当我们走完与模块 1.4 完全一样的"拉格朗日乘子法
求偏导
代回"的流程后,得到的对偶问题形式竟然出奇地简单且相似。
对于每个约束 y_i(w·x_i+b) ≥ 1-ξ_i 引入乘子 α_i ≥ 0,对于每个 ξ_i ≥ 0 引入乘子 μ_i ≥ 0,拉格朗日函数为:
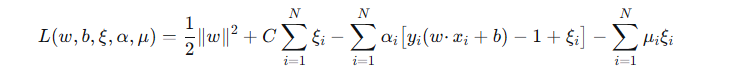
先对 w,b,ξ 极小化。求偏导置零:
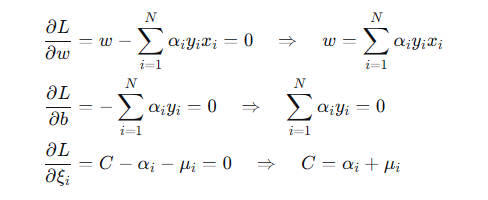
将结果代回 L,整理后得到软间隔对偶问题:
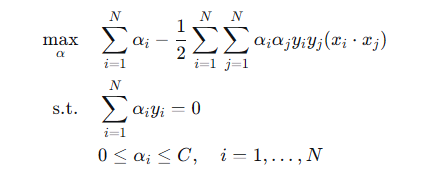
知识点
对偶问题的惊人相似性:
由于我们要优化的目标函数和硬间隔一模一样
唯一改变的,是乘子 的约束条件,从原来的
,变成了被 C 封顶的盒子约束(Box Constraint):
的三种情况与物理意义:
通过 KKT 互补松弛条件,我们可以精准定位每一个样本点的状态:
-
-
-
可见,即使样本被错分或落入间隔内部,只要 α_i = C,它们依然是支持向量,会影响最终 w。这与硬间隔完全不同,硬间隔中只有刚好在间隔边界上的点才是支持向量。
2.4 合页损失函数(Hinge Loss)
软间隔SVM还可以用无约束的"损失函数+正则化"视角来理解,这为学习算法提供了另一种视角。这就不得不提机器学习中鼎鼎大名的合页损失函数。
知识点
软间隔原始目标 min ½‖w‖² + C ∑ξ_i,约束 ξ_i ≥ 1 - y_i(w·x_i+b) 且 ξ_i ≥ 0,这两个约束可以合并为:
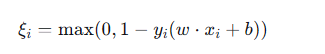
这个函数就是合页损失(Hinge Loss)。它衡量样本距离"安全边界"(即函数间隔 ≥1)有多远:
-
若函数间隔 ≥1,损失为 0 ------ 样本足够安全。
-
若函数间隔 <1,损失线性增长 ------ 样本越靠近边界或越过边界,代价越大。
于是软间隔原始问题等价于无约束优化:
其中 λ = 1/(2C)(对比标准形式可得)。前半部分是经验风险(损失),后半部分是正则化项(控制间隔大小)
这清楚地展示了SVM的结构:合页损失项驱动经验风险最小化,二范数项驱动间隔最大化(正则化)。
假设某正样本 y=+1,超平面 w·x+b = 0.3,则 z=0.3。合页损失 = max(0, 1-0.3) = 0.7。因为函数间隔小于1,样本处于间隔内部,所以有损失,会驱动模型增大间隔。
如果同一超平面对另一个正样本输出 w·x+b = 2.5,损失为0,它对梯度没有贡献,模型不再调整以适应这个点。
这就直观解释了为什么不是支持向量的点不影响决策边界。
在模块 2 中,我们通过引入"软间隔",让 SVM 学会了包容现实世界中的"噪点"。但如果数据的本质特征就是非线性的呢?比如著名的"异或(XOR)问题",或者像同心圆一样分布的数据,无论你怎么画直线、怎么容忍错误,都无法将它们分开。
这时候,我们需要让 SVM 进行一次维度跃迁。这就是我们要讲的------非线性支持向量机与"核技巧(Kernel Trick)"。
模块 3:非线性支持向量机与核技巧
3.1 非线性问题的挑战
知识点
线性模型在异或问题上的失败:
想象坐标系中有 4 个点:和
是正类(红点),
和
是负类(蓝点)。这在逻辑电路中对应"异或"门。你可以尝试用一支笔在纸上画一条直线,试着把红蓝点分开。你会发现这绝对不可能。线性模型在这里彻底失效了。
你找不到一条直线把红点蓝点分开对不对。
升维思想:映射到高维空间: 既然在二维平面上切不开,我们能不能把它抛到三维空间里去切? 这就是处理非线性问题的核心哲学:低维空间中线性不可分的数据,映射到高维特征空间后,大概率会变得线性可分。
接下来我们把这4个点映射到三维,好像就能分开了呢
哈哈哈,这也是现代深度学习理论的一个基石,维度映射
高维映射函数 : 我们假设存在一个映射函数
,能够将原本在低维空间的数据
,逐一转换到高维空间变成
。一旦到了高维空间,我们就继续使用模块 1 的硬间隔或模块 2 的软间隔寻找一个"高维的平整切面"(超平面)即可。
3.2 核函数与核技巧 (The Kernel Trick)
升维的思想很丰满,但现实很骨感。
直接在高维空间中操作会遇到"维数灾难"。比如,把二维映射到三维还好,但如果映射到百万维、甚至无穷维呢?
这就是"核技巧"闪亮登场的地方。它是机器学习史上最优雅的数学魔术之一。
知识点
只出现内积的神奇对偶问题:
回顾我们在模块 1.4 中推导出的最终对偶目标函数:
请注意! 所有的样本数据 和
,在这个长长的公式里,仅仅且只以点积(内积)
的形式出现!
如果我们要在高维空间做 SVM,公式就会变成计算 。
核函数的定义:
核函数 被定义为两个低维向量在映射到高维空间后的内积:
核技巧的精髓(避免高维计算灾难):
核技巧 的想法是:能不能不显式地计算高维映射 φ(x),而直接在原始低维空间中计算出一个标量值,它恰好等于高维空间中的内积 φ(x_i)·φ(x_j) 呢?
核技巧的核心在于:我们不需要显式地知道 是什么,也不需要真的把数据映射到高维!
只要我们能找到一个函数,能够直接在低维原始空间 中,通过两个向量
和
的简单计算,得出它们在高维空间的内积结果,我们就绕过了所有恐怖的高维运算。
这就是"在低维空间计算,达到高维空间升维效果"的魔法。
比如,二维坐标 变成三维坐标的公式是:
(注:这里的 只是为了让后面的数学结果完美对齐,不用深究)。
假设我们有两个点:点 和点
。
-
升维 A: 把
-
升维 B: 把
-
算内积: 在三维空间里,把这两个新坐标做内积:
最终结果 = 121
刚才只是从二维到三维。如果是一幅 像素的图像,升维后可能是上百万维。你需要先算出两个上百万维的新坐标,然后再做一百万次乘法和加法。计算机的内存和 CPU 会瞬间爆炸。
天才的数学家发现,对于某些特定的升维公式,我们可以完全跳过计算高维坐标的步骤 ,直接用低维的数据算出一个结果,这个结果竟然和"老实人路线"算出来的高维内积一模一样!
这个"抄近道的公式",就是核函数 。
对于刚才那个升维,对应的核函数公式极其简单:把两个点在低维的内积算出来,然后平方。
过程演示(依然是点 和
):
-
算二维内积:
-
用核函数公式(平方):
最终结果 = 121
你看!在这个过程中,计算机从头到尾都不知道三维空间的坐标是什么,它只是做了几个最简单的二维加减乘除,就直接拿到了高维空间里复杂的运算结果!
这就是核函数的全过程:用低维的计算量,白嫖高维的计算结果。
3.3 正定核与 Mercer 定理(深入底层)
你可能会问:既然核函数这么好用,我是不是可以随便写一个函数 当核函数?
答案是不行。这个函数必须能对应上某个空间里的内积才行。
知识点
-
如何判断一个函数是不是核函数?
如果我们不知道
-
Gram 矩阵
对于任意给定的数据集包含 N 个样本,我们用候选核函数两两计算它们的值,组成一个
-
正定核的充要条件(Mercer 定理的意义):
数学家 Mercer 证明了一个定理(我们不证,只用结论):
一个对称函数
这给了我们极大的自由!只要我们验证一个函数满足 Mercer 定理,我们根本不需要知道那个高维空间长什么样,直接拿来用就行了。
假设我们想用函数 K(x, z) = (x·z)^2,判断它是否为正定核。
取两个样本 x₁ = (1,0), x₂ = (-1,0)。
计算 Gram 矩阵:
G = [[K(x₁,x₁), K(x₁,x₂)], [K(x₂,x₁), K(x₂,x₂)]]
= [[(1)², (-1)²], [(-1)², (1)²]] = [[1, 1], [1, 1]]
它的特征值是 2 和 0,半正定。再取几组数据测试都半正定,且它可展为 (x₁²)(z₁²) + (x₂²)(z₂²) + 2x₁x₂z₁z₂,确实对应高维内积。所以它是正定核。
若我们尝试 K(x, z) = - (x·z)^2,显然 Gram 矩阵负定,不是核函数。
3.4 常用核函数及其直觉
在实际应用中,我们很少去自己构造核函数并证明它半正定,而是直接使用前人证明过的经典核函数。
知识点
线性核 (Linear Kernel):
这其实就是没有任何映射。当你使用线性核时,非线性 SVM 就退化成了我们模块 1 和 2 讲的普通线性 SVM。
多项式核 (Polynomial Kernel):
它可以实现多项式的交叉项组合。参数 控制了映射到的高维空间的维度上限(比如前面例子中
映射到了三维)。它适合正交属性比较强的数据。
高斯核 / 径向基函数核 (RBF Kernel):
这是 SVM 中最强大、最常用的核函数,没有之一!
如果你将高斯核在数学上用泰勒展开,你会发现它包含了 的无穷次幂。这意味着:高斯核隐式地将数据映射到了无穷维的空间! 既然空间维度是无穷的,理论上它可以拟合任何复杂的非线性边界。
其中,超参数 (Gamma)极其关键:
-
-
Sigmoid 核:
当使用 Sigmoid 核时,SVM 的行为非常像一个包含一层隐藏层的多层感知机(神经网络)。这也揭示了 SVM 与深度学习之间的隐秘联系。
实例
我们在二维平面上放 4 个点。
-
正类(打标签为 +1):
-
负类(打标签为 -1):
如果你把这 4 个点画在纸上,它们形成了一个正方形的四个顶点,正类和负类处于对角线的位置。无论你怎么画一条笔直的直线,都绝对无法将正类和负类分开。
接下来,我们看看不同核函数是如何接招的。
1. 线性核 (Linear Kernel):数学死局
底层公式:
线性核不进行任何升维。SVM 试图在二维空间里找一条直线方程:。
为了把数据分开,SVM 必须满足以下分类条件(函数间隔大于 0):
-
对于点
-
对于点
-
对于点
-
对于点
计算流程的崩溃:
我们把条件 2 和条件 3 加起来,得到 。
因为条件 1 规定了 ,所以
必然是一个负数。
这就意味着 必须是一个负数。
但是,条件 4 又死死地要求 必须是正数。
计算机在这一步直接卡死,抛出矛盾:线性核在此数据集上无解(如果强行用软间隔,它只能胡乱画一条线,准确率 50%)。
2. 多项式核 (Polynomial Kernel):"交叉组合"
底层公式: 我们选用 2 次多项式核
多项式核的魔法在于,它在做平方展开时,偷偷产生了一个 的交叉项 。对应到高维空间的坐标本质是
。
计算流程(SVM 的视角):
SVM 算出了一组参数,并在高维空间找到了一个平整的超平面(切面)。这个切面的隐式方程是:
(注:这组参数是优化器算出来的,我们直接拿来验证)
现在,我们把 4 个点的坐标依次喂进去:
-
测点
(成功预测为正类!)
-
测点
(成功预测为正类!)
-
测点
(成功预测为负类!)
-
测点
(成功预测为负类!)
看明白了吗? 多项式核通过引入平方项和交叉项,使得原本平坦的坐标系发生弯曲。在它的眼里,A 和 B的得分都被拉到了 1,而 C 和 D的得分都被压到了 -1。异或问题被完美解决!
3. 高斯核 (RBF Kernel):"山峰与山谷"
底层公式:
高斯核根本不关心坐标轴长什么样,它只算两点之间的直线距离。距离越近,核函数值越接近 1;距离越远,越接近 0。
假设我们设。
在高斯核的视角下,SVM 的决策函数变成了用核函数"投票":
(正类贡献正分,负类贡献负分。假设优化器算出的权重 都为 1)
你可以把这想象成地理学:正类点 A 和 B 在地上建起了两座高峰(+),负类点 C和 D在地上砸出了两个深坑(-)。
计算流程(验证点 A):
当我们要预测点 的类别时,系统计算点 A 到所有 4 个点的距离,并套用高斯公式:
-
A 到 A(自己): 距离为 0。
-
A 到 B(同类): 距离的平方为
-
A 到 C(异类): 距离的平方为
-
A 到 D(异类): 距离的平方为
综合得分:
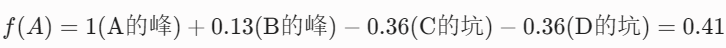
大于0
预测结果:正类!
计算流程(验证点 C):
我们要预测点 的类别时:
-
C 到 A(异类): 距离平方为 1。
-
C 到 B(异类): 距离平方为 1。
-
C 到 C(自己): 距离平方为 0。
-
C 到 D(同类): 距离平方为 2。
综合得分:

预测结果:负类!
总结一下流程的本质区别
面对异或问题:
-
线性核说: "我要画一条直线。"(画不出来,死机)。
-
多项式核说: "我把数据的坐标平方一下,再把 x 和 y 乘起来当成新坐标,突然发现它们分开了。"
-
高斯核说: "我不管什么坐标!我直接在正类脚下垫高土堆,在负类脚下挖深坑。走到哪边算哪边的势力范围。"
题外话:
在数学层面上,SVM 确实是一件完美的艺术品:它有严密的统计学习理论支撑,它能保证找到全局最优解(绝不陷入局部最优),它的核技巧优雅至极。 在 2012 年深度学习全面爆发之前,SVM 统治了机器学习界长达十几年。
既然 SVM 这么完美,为什么现在满世界都在谈论深度学习(神经网络)呢?
原因在于,当人类进入"大数据"和"感知智能(图像、语音、文本)"时代后,SVM 暴露出了三个极其致命的缺陷。深度学习正是因为打破了这三个死结,才迎来了它的时代。
致命缺陷一:特征工程的死结("喂饭"与"自己吃"的区别)
这是 SVM 痛失王座的最核心原因。
-
SVM 的尴尬:只懂裁判,不懂观察 假设你要做一个"猫狗识别"任务。如果你直接把一张图片的几百万个像素点的 RGB 颜色值作为数字直接扔给 SVM,不管你用什么核函数,SVM 都会彻底懵圈,准确率惨不忍睹。 为什么?因为像素本身的数值和"这是一只猫"之间,没有任何简单的数学规律。 在传统机器学习时代,为了让 SVM 起作用,人类必须先手动提取"特征" 。算法工程师要苦熬几个月写代码,计算图片的边缘、纹理、色彩直方图(比如 SIFT、HOG 特征),然后把提取出来的高度浓缩的特征丢给 SVM,SVM 才能在这些特征上画出完美的分界线。 结论:SVM 的完美,建立在人类事先帮它把数据整理好的基础上。它是个完美的"决策者",但它是个瞎子。
-
深度学习的降维打击:端到端学习(End-to-End) 深度学习(比如卷积神经网络 CNN)最伟大的突破就是特征表示学习。你不需要告诉它什么是边缘、什么是纹理。你只要把原始的几百万个像素直接"泼"给它,它通过一层一层的网络,自己就能学会:第一层看边缘,第二层看轮廓,第三层看猫耳朵...... 深度学习把"特征提取"和"分类决策"融合在了一起,彻底解放了人类。
致命缺陷二:算力与大数据的诅咒(O(N\^2) 的噩梦)
SVM 是一个小数据时代的王者,但在大数据面前它会"自爆"。
-
核函数的代价:
我们刚才讲过,无论是训练还是测试,SVM 底层都需要计算数据点两两之间的内积(或者核函数)。如果你有 100 万张图片,你需要计算一个
-
深度学习的解法:小批量(Mini-batch)
神经网络的训练机制是梯度下降。就算你有 10 亿张图片,它也可以每次只看 64 张图片(一个小批量),算一算误差,更新一下参数,然后再看下 64 张。它的计算量与数据量是线性关系的,而且极其适合用 GPU 并行加速。
致命缺陷三:"扁平"与"深邃"的认知差异
-
SVM 是扁平的: 无论你的核函数有多强大(即便是无穷维的高斯核),SVM 终究只是把数据做了一次映射,然后切了一刀。这种"单层"结构在面对极其复杂的逻辑嵌套时,表达能力依然有限。
-
深度学习是深邃的: 神经网络可以有几十层、上百层。这种层级结构(Hierarchical)极其契合真实世界的规律:原子组成大分子,大分子组成细胞,细胞组成器官......深度学习能够一层一层地抽象概念,这是浅层模型无论如何也做不到的。
现在还要学 SVM 吗?
当然要!而且必须学好。
-
如果你手头有 海量的图像、音频、文本等非结构化数据,毫无疑问,上深度学习。
-
如果你在公司里处理的是 Excel 表格里的结构化数据(几千到几万条记录的财务数据、医疗指标等) ,并且要求模型有一定的可解释性、不需要庞大的算力,那么 SVM、随机森林、XGBoost 依然是秒杀深度学习的最佳选择。
SVM 代表了人类用纯粹的数学逻辑去对抗复杂数据的巅峰。懂了 SVM,你才算真正懂了什么是"分类边界",什么是"优化目标",什么是"高维映射"。带着这种严谨的数学直觉再去学深度学习的"黑盒子",你的视野会比别人开阔得多。
准备好迎接支持向量机(SVM)工程实现上最伟大的壮举了吗?
前面三个模块,我们已经把 SVM 的数学大厦彻底封顶。但是,把这套理论搬进计算机时,却遇到了一个算力上的"死胡同"。1998 年,微软研究院的 John Platt 发明了 SMO(序列最小最优化)算法,凭借极其巧妙的"分而治之"思想,让 SVM 真正走向了工业界的千家万户。
模块 4:序列最小最优化算法(SMO)
回顾一下我们最终要解的对偶问题
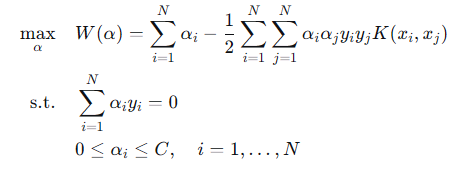
4.1 对偶问题求解的困难
原子知识点
-
规模灾难的根源:
回顾我们的对偶问题,我们需要求出一组乘子
假设你有一个包含 10 万个样本的数据集。传统的二次规划(QP)求解器需要把所有变量放进内存里构建一个
-
SMO 的基本思想:分而治之(Divide and Conquer)
既然 10 万个变量一起优化会死机,那我能不能每次只挑一个变量来优化,把其他 99,999 个变量当成常数固定住呢?
答案是:不行。
-
为什么必须选"两个"变量?
回想一下我们在模块 1.4 中推导出的对偶问题约束条件:
这个条件像一条铁链把所有的
因此,为了保持这个等式成立,我们最少必须同时改变两个变量(比如
4.2 两个变量的二次规划求解
当我们把目光聚焦在只有两个变量的优化上时,原本堪比登天的数学难题,瞬间变成了一道高中生都能解的抛物线极值题。
固定变量,推导子问题: 我们将 和
视作变量,其余所有的
视作常数。 此时,约束条件变成了:
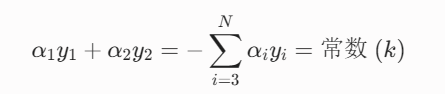
从双变量变为"单变量"优化:
既然 ,而且
只能是 +1 或 -1。我们完全可以用
把
表示出来:
把这个式子代入原本极其复杂的目标函数中,目标函数瞬间变成了一个只包含 的一元二次函数 。求一元二次函数的极值(顶点),只需要简单的求导公式即可,我们将其称为未剪辑的最优解
。
剪辑约束(Clipping):带盒子的跷跷板
算出了理想的极值点还不行,别忘了在软间隔(模块 2)中,每一个都有一个"盒子约束":
所以,和
必须被死死限制在一个边长为
的正方形盒子里。
-
如果它们是异号 (一个正类一个负类,
-
如果它们是同号 (都是正类或负类,
我们必须沿着这条线段,找到合法的上下界(
4.3 变量选择启发式
既然每次只能挑两个变量,而我们有 10 万个变量。到底该挑哪两个才能让整个算法收敛得最快呢? 这是决定 SMO 算法是"跑得飞快"还是"慢如蜗牛"的灵魂所在。
John Platt 为 SMO 设计了一套极度聪明的双层循环启发式(Heuristics)策略。
原子知识点
-
外层循环:寻找"最坏的分子"(选择第一个变量
外层循环的目标是找碴。它遍历所有样本点,寻找那些违背 KKT 条件最严重的点。
回想一下 KKT 条件,如果一个点
-
内层循环:寻找"最佳搭档"(选择第二个变量
既然
为了让算法进步最大,SMO 的策略是:选择能让
具体怎么衡量?模型维护了一个"误差缓存(Error Cache)",记录了每个点当前的预测值和真实值的差
-
阈值
每次优化完一对
-
终止条件:天下太平
就这样,挑两个最刺头的变量,优化,剪平,再挑两个,再优化......
直到外层循环巡视了所有的样本,发现每一个人都乖乖遵守了 KKT 条件 (在允许的数值精度