基于深度学习的制造成本估算特征可视化研究
论文核心:提出一种融合3D CNN与3D Grad-CAM的制造成本估算框架,在实现高精度成本预测的同时,通过特征可视化提供可解释性,揭示影响成本的3D CAD关键几何区域。
一、研究背景与动机
1.1 问题来源
| 维度 | 说明 |
|---|---|
| 产业背景 | 在线制造平台兴起,客户上传CAD模型后需实时获取制造成本报价 |
| 痛点 | 传统成本估算依赖专家人工审核,耗时费力,无法满足按需服务的实时性要求 |
| 关键数据 | 工程设计仅占总成本5%,却决定了70%的最终制造成本(Boothroyd, 1994) |
| 核心需求 | 在开发早期阶段实时准确预测成本,以便修改设计、在满足工程性能的同时达成目标成本 |
1.2 现有方法局限
定性技术 ──┬── 直观法(基于经验)
└── 类比法(基于历史数据)── 回归分析 / ANN
定量技术 ──┬── 参数法
└── 分析法- 线性回归:可解释性强,但面对复杂非线性模式预测能力有限
- ANN(人工神经网络) :可处理非线性关系,但输入通常为1D数据,丢失3D空间信息
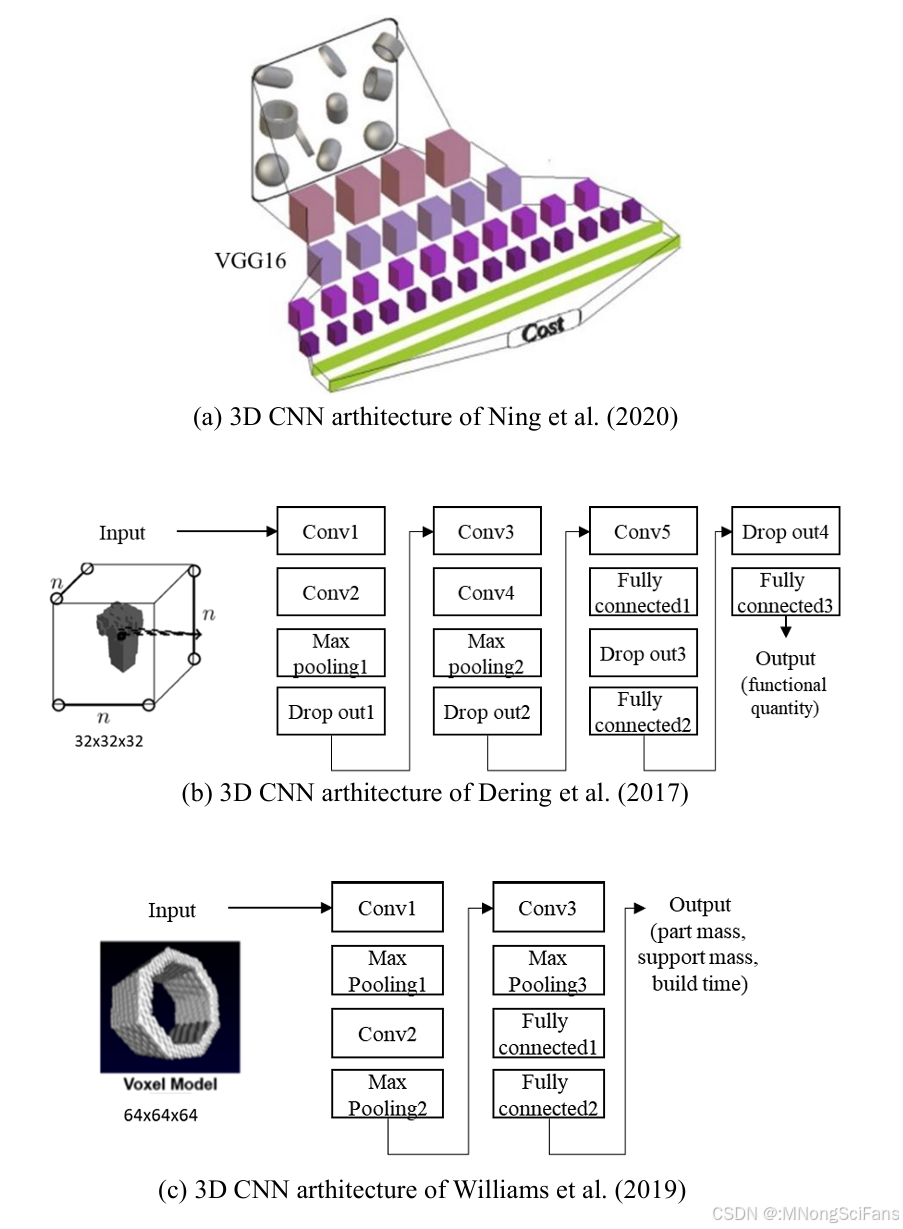
- 3D CNN(Ning et al., 2020) :可自动提取3D CAD特征,但缺乏可解释性------无法解释成本判断依据
1.3 研究目标
提出一种基于深度学习的制造成本估算特征可视化流程,实现高精度预测 + 可解释性双重目标。
二、核心理论与方法框架
2.1 研究框架总览(三阶段)
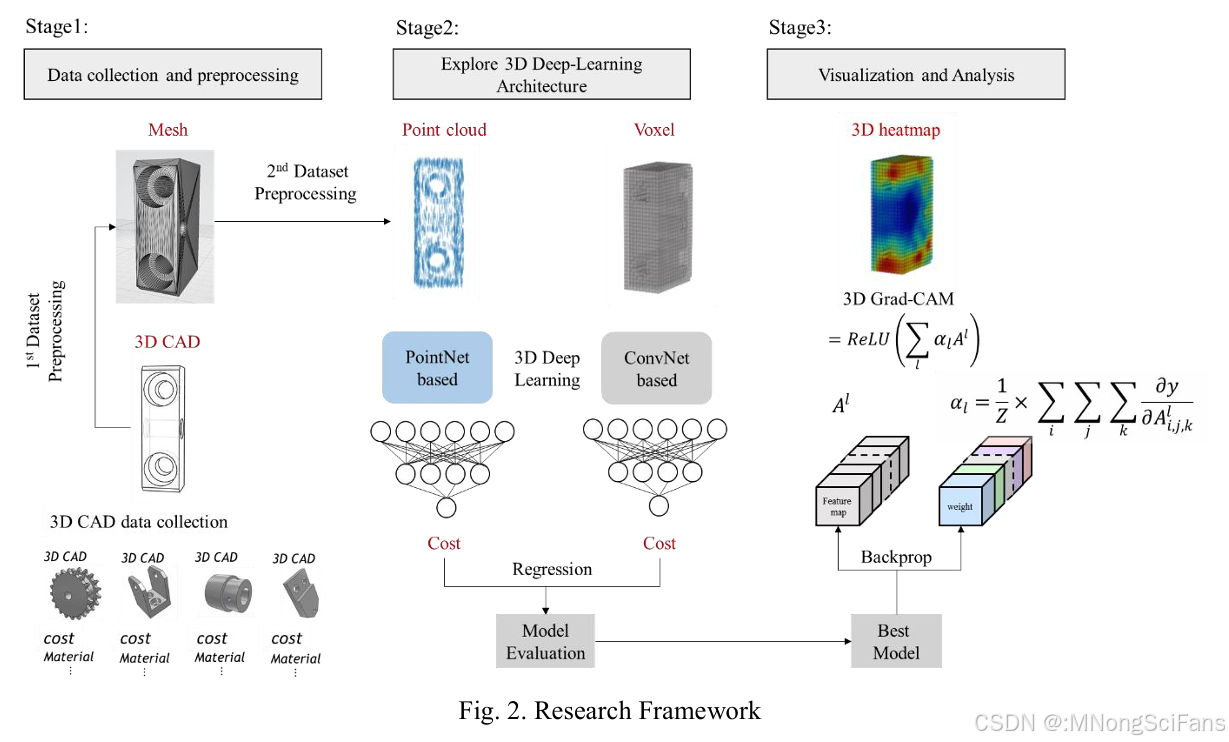
┌──────────────────────────────────────────────────────────────────┐
│ Stage 1: 数据收集与预处理 │
│ 1,006个CNC零件 → 3D CAD + 成本 + 材料 │
│ → 网格(Mesh) → 点云(Point Cloud) / 体素(Voxel) │
│ → 体积/材料/成本 归一化 │
├──────────────────────────────────────────────────────────────────┤
│ Stage 2: 3D深度学习架构探索 │
│ PointNet-based / ConvNet-based → 回归预测成本 → 模型评估选优 │
├──────────────────────────────────────────────────────────────────┤
│ Stage 3: 可视化与分析 │
│ 3D Grad-CAM → 热力图 → 解释成本预测依据 → 检测加工特征/难度 │
└──────────────────────────────────────────────────────────────────┘2.2 数据收集与预处理
2.2.1 数据来源
- 来源:MISUMI在线平台(2020年)
- 规模:1,006个CNC加工零件
- 类别:34类不同零件
- 属性:3D CAD模型 + 价格 + 材料信息
2.2.2 预处理流程
| 阶段 | 操作 | 工具/方法 |
|---|---|---|
| 第一阶段 | 3D CAD → 网格文件(Mesh) | FreeCAD + Python API |
| 计算几何体积 | numpy-stl库 |
|
| 第二阶段 | 网格 → 点云(Point Cloud) | 加权随机采样 + 质心法(Iglesias, 2017) |
| 网格 → 体素(Voxel) | 三角面片与3D网格求交(Adam, 2020) | |
| 数值归一化 | Min-Max / 对数归一化 | |
| 材料编码 | One-Hot编码(11维向量) |
2.2.3 归一化方法
Min-Max归一化:
xnew=x−xminxmax−xminx_{\text{new}} = \frac{x - x_{\min}}{x_{\max} - x_{\min}}xnew=xmax−xminx−xmin
对数归一化:
xnew=lnxx_{\text{new}} = \ln xxnew=lnx
对数归一化后数据分布更趋对称、接近正态,对偏态分布(右偏的成本/体积数据)效果显著。
2.2.4 材料编码方案
| 大类 | 具体型号 | One-Hot向量 |
|---|---|---|
| Steel | Structural Steel | 1,0,0,0,0,0,0,0,0,0,0 |
| Steel | S45C | 0,1,0,0,0,0,0,0,0,0,0 |
| Steel | S50C | 0,0,1,0,0,0,0,0,0,0,0 |
| Steel | SS400 | 0,0,0,1,0,0,0,0,0,0,0 |
| Steel | S35C | 0,0,0,0,1,0,0,0,0,0,0 |
| Aluminum | A6061 | 0,0,0,0,0,1,0,0,0,0,0 |
| Aluminum | Aluminum Alloys | 0,0,0,0,0,0,1,0,0,0,0 |
| Aluminum | A5052 | 0,0,0,0,0,0,0,1,0,0,0 |
| Aluminum | A2011 | 0,0,0,0,0,0,0,0,1,0,0 |
| Aluminum | 2000 Series Al Alloys | 0,0,0,0,0,0,0,0,0,1,0 |
| Stainless | SUS304 / SUS303 | 0,0,0,0,0,0,0,0,0,0,1 |
2.3 深度学习模型架构
2.3.1 基线模型对比
本研究测试了5种基线架构,共 90个模型组合(5架构 × 2归一化 × 3损失函数 × 3输入组合):
| 序号 | 架构 | 输入格式 | 特点 |
|---|---|---|---|
| 1 | VoxNet | 体素(32³) | 早期3D CNN,2层卷积+1层池化 |
| 2 | PointNet | 点云(2048) | 直接处理点云,无需体素化 |
| 3 | Dering et al. (2017) | 体素(32³) | 5层卷积+Dropout,用于增材制造功能预测 |
| 4 | Williams et al. (2019) | 体素(64³) | 3层卷积+池化,用于增材制造参数预测 |
| 5 | Ning et al. (2020) | 体素(64³) | VG16风格,用于成本预测(无可解释性) |
训练超参数:
- 学习率:0.0001
- 优化器:Adam
- 批量大小:16
- 最大轮数:1000(采用早停法防过拟合)
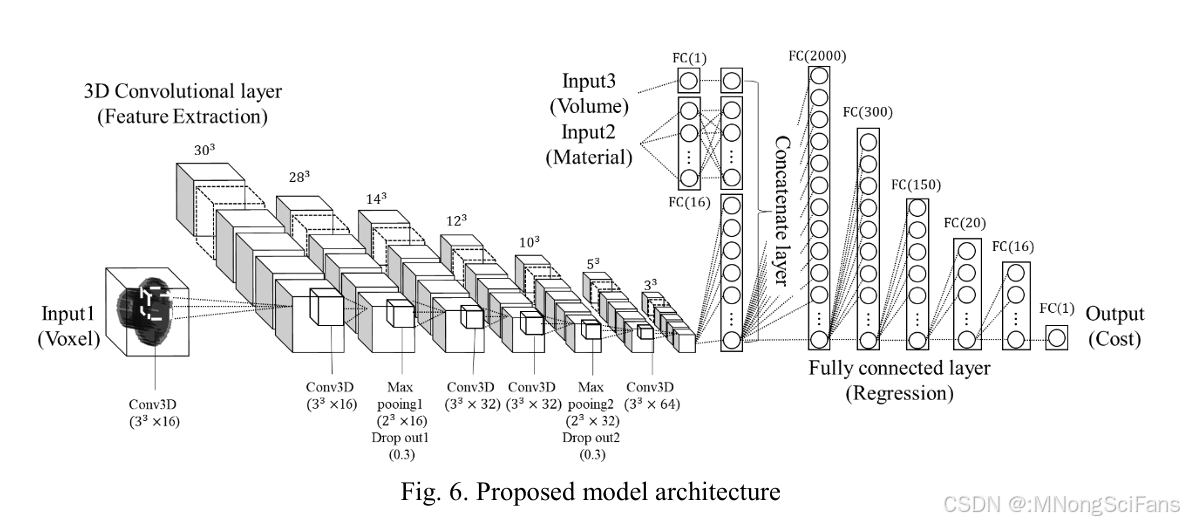
2.3.2 提出模型(Proposed Model)
核心设计思想 :基于Dering et al. (2017)架构改进,采用三路输入 + 深层回归头的设计。
输入端:
| 输入通道 | 数据 | 维度 |
|---|---|---|
| Input1 | 体素数据 | 32×32×32 |
| Input2 | 材料类型 | 16(One-Hot后经全连接层) |
| Input3 | 体积信息 | 1(经全连接层) |
特征提取路径(3D卷积):
| 层 | 核大小 | 滤波器数 | 激活函数 | 备注 |
|---|---|---|---|---|
| Conv3D ×2 | 3×3×3 | 16 | LeakyReLU | Xavier初始化 |
| Max Pooling | 2×2×2 | --- | --- | 下采样 |
| Dropout | --- | --- | --- | p=0.3 |
| Conv3D ×2 | 3×3×3 | 32 | LeakyReLU | |
| Max Pooling | 2×2×2 | --- | --- | |
| Dropout | --- | --- | --- | p=0.3 |
| Conv3D | 3×3×3 | 64 | LeakyReLU | |
| Flatten | --- | --- | --- | 展平为一维 |
回归路径(全连接层):
三路输入拼接后,依次经过:2000 → 300 → 150 → 20 → 16 → 1(输出成本)
关键改进:
- LeakyReLU替代ReLU(α=0.1),避免"死亡ReLU"问题
- Xavier初始化,提升训练稳定性
- 回归头采用5层递减全连接层(原模型仅2层),增强非线性拟合能力
- 总参数量仅 4,245,369,远小于Ning et al.的81,862,691
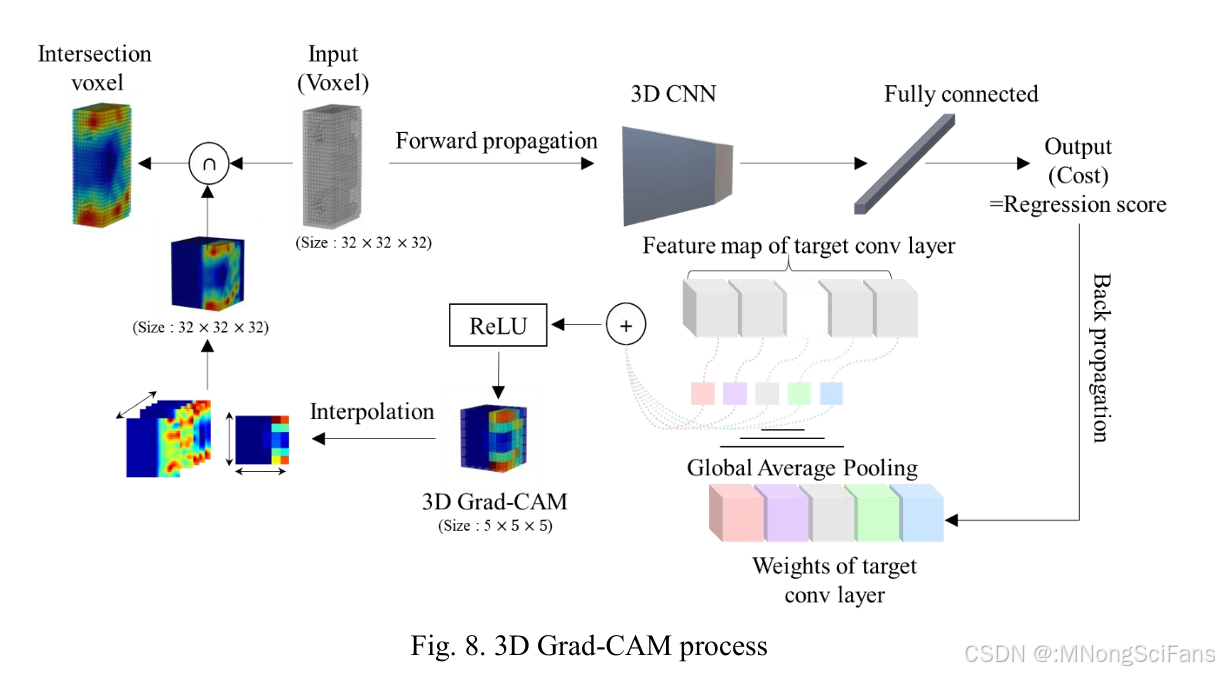
2.4 3D Grad-CAM 可视化方法
2.4.1 核心原理
3D Grad-CAM 是2D Grad-CAM(Selvaraju et al., 2016)在三维空间的扩展,通过反向传播获取目标卷积层对输出回归值的梯度,计算各特征图权重,线性组合后经ReLU生成3D热力图。
权重计算:
αl=1Z×∑i∑j∑k∂y∂Ai,j,kl\alpha_l = \frac{1}{Z} \times \sum_i \sum_j \sum_k \frac{\partial y}{\partial A_{i,j,k}^l}αl=Z1×i∑j∑k∑∂Ai,j,kl∂y
3D Grad-CAM生成:
L3D-Grad-CAM=ReLU(∑lαl×Al)L_{\text{3D-Grad-CAM}} = \text{ReLU}\left(\sum_l \alpha_l \times A^l\right)L3D-Grad-CAM=ReLU(l∑αl×Al)
其中:
- yyy:回归输出(预测成本)
- AlA^lAl:第lll个特征图的激活值
- αl\alpha_lαl:第lll个特征图的全局平均池化权重
- ZZZ:归一化因子
2.4.2 后处理流程
3D Grad-CAM输出(低分辨率)
→ 三维插值(对齐到输入体素尺寸32³)
→ 与输入体素取交集
→ 生成3D热力图(红色=高影响区域)2.4.3 可视化层级特征
| 卷积层 | 特征图尺寸 | 可视化特点 |
|---|---|---|
| Conv1 | 30³ | 捕捉边缘、表面等低级几何特征 |
| Conv2 | 28³ | 提取局部形状特征 |
| Maxpool1 | 14³ | 空间降维 |
| Conv3 | 12³ | 更高抽象特征 |
| Maxpool2 | 10³ | 进一步降维 |
| Conv5 | 3³ | 高度抽象,分辨率低,区域模糊 |
关键发现:浅层卷积更擅长捕捉具体几何特征(如孔、齿),深层卷积特征更抽象但定位模糊。
三、实验设计与结果
3.1 实验设置
| 项目 | 配置 |
|---|---|
| 数据集 | 1,006个CNC零件,80%训练/20%测试 |
| 模型总数 | 108个(含提出模型的变体) |
| 评估指标 | RMSE、MAPE |
| 硬件 | GPU: NVIDIA TITAN Xp |
| 对比维度 | 架构 × 归一化 × 损失函数 × 输入组合 |
3.2 成本预测性能对比
3.2.1 各架构最佳模型
| 架构 | 输入 | 归一化 | 损失函数 | RMSE | MAPE |
|---|---|---|---|---|---|
| VoxNet | Voxel(32), Mat, Vol | Min-max | MAE | 2,716.24 | 29.76 |
| PointNet | Point(2048), Mat, Vol | Log | MSE | 3,503.78 | 21.17 |
| Dering et al. | Voxel(32), Mat, Vol | Log | MSE | 2,014.87 | 12.93 |
| Williams et al. | Voxel(64), Mat, Vol | Log | MAE | 2,165.35 | 14.12 |
| Ning et al. | Voxel(64), Mat, Vol | Log | MSE | 1,047.47 | 10.63 |
| 提出模型 | Voxel(32), Mat, Vol | Log | MAE | 1,290.41 | 8.76 |
3.2.2 综合性能对比
| 指标 | 提出模型 | Ning et al. (2020) | Dering et al. (2017) |
|---|---|---|---|
| MAPE | 8.76% ✅ | 10.63% | 12.93% |
| RMSE | 1,290.41 | 1,047.47 ✅ | 2,014.87 |
| 参数量 | 4.25M ✅ | 81.86M(~20倍) | --- |
| 训练时间 | ~20.5 min ✅ | ~6.7 h(~20倍) | --- |
| R值 | 0.9954 ✅ | 0.9949 | 0.9839 |
结论 :提出模型以1/20的参数量和训练时间,实现了最优的MAPE(8.76%)和最高相关性(R=0.9954)。相比基准架构Dering et al.,RMSE降低36%,MAPE降低32%。
3.3 关键实验发现
发现一:材料数据至关重要
| 输入组合 | RMSE | MAPE | RMSE降幅 | MAPE降幅 |
|---|---|---|---|---|
| 仅体素 | 10,644.07 | 42.76 | --- | --- |
| 体素 + 材料 | 1,925.68 | 21.33 | 81.9%↓ | 50.1%↓ |
| 体素 + 材料 + 体积 | 1,290.41 | 8.76 | 87.9%↓ | 79.5%↓ |
材料成本通常超过总制造成本的50%(Jung, 2002),加入材料信息后预测精度大幅提升。
发现二:对数归一化优于Min-Max归一化
- CAD数据包含大量不相关部分,对数归一化可更好地标准化输入
- 对数变换使偏态分布趋于对称,帮助模型学习更精确的差异
- 对于MAPE指标,对数归一化在大多数情况下明显占优
发现三:损失函数选择依赖架构
- 提出模型最优损失函数为MAE(最小化MAPE)
- 不同架构的最优损失函数不同,需针对性调优
3.4 加工特征可视化结果
3.4.1 CNC加工特征检测
3D Grad-CAM成功识别以下典型CNC加工特征(无需显式标注):
| 特征类型 | 可视化结果 | 说明 |
|---|---|---|
| Pocket(凹槽) | 凹槽区域显著激活 | 模型精准定位凹槽 |
| Step(台阶) | 台阶边缘高亮 | 边缘几何变化被捕捉 |
| Slot(槽) | 槽区域明显激活 | 开放槽特征清晰识别 |
| O-ring(O型圈) | 内部圆周被激活 | 圆环结构被关注 |
| Gear齿 | 齿和孔周围红色高亮 | 齿轮关键加工区域 |
| 轴套孔 | 孔周围区域高亮 | 孔特征为成本敏感区 |
模型在未输入加工特征标签 的情况下,自主发现了这些关键区域,验证了3D Grad-CAM的特征发现能力。
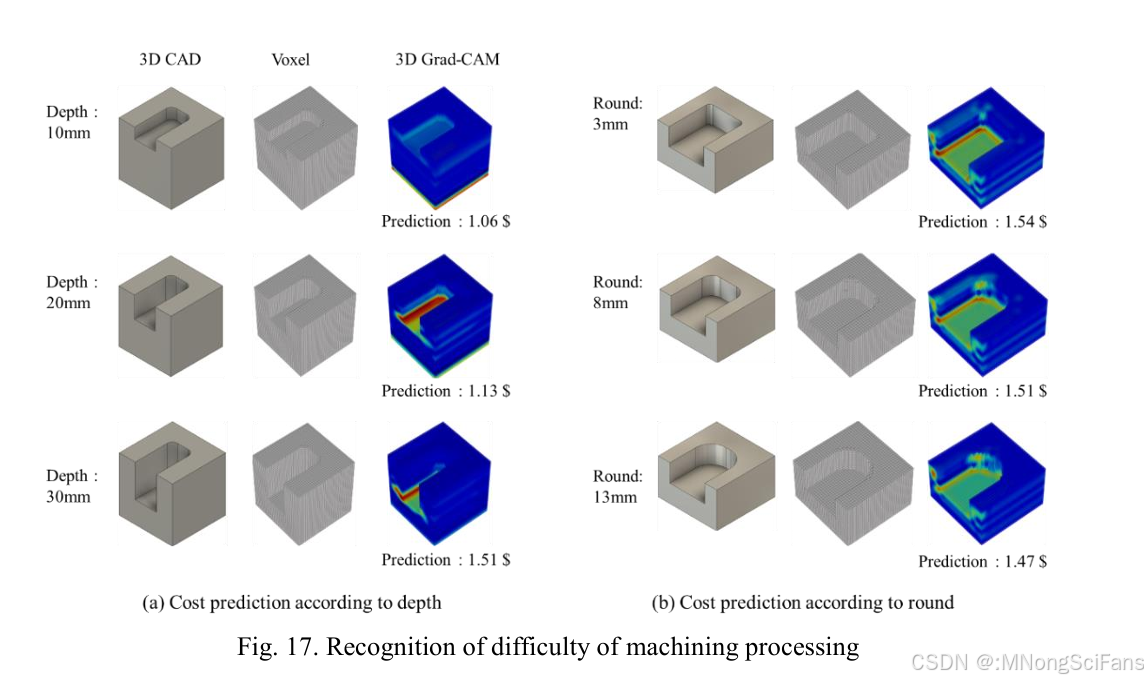
3.4.2 加工难度区分实验
实验A:不同加工深度的成本预测
| 深度 | 预测成本 | Grad-CAM激活区域 | 成本上升原因 |
|---|---|---|---|
| 10mm | 1.065 | 底面轻微激活 | 基准 |
| 20mm | 1.135 | 底面激活增强 | 振动增大 |
| 30mm | 1.515 | 底面显著激活 | 稳定性下降,振幅最大 |
实验B:不同圆角半径的成本预测
| 圆角半径 | 预测成本 | Grad-CAM激活区域 | 成本上升原因 |
|---|---|---|---|
| 13mm | 1.475 | 圆角区域轻微激活 | 可用大直径刀具 |
| 8mm | 1.515 | 圆角区域中度激活 | 刀具直径适中 |
| 3mm | 1.545 | 圆角区域显著激活 | 需小直径刀具,加工时间长 |
核心结论 :模型能区分相似形状CAD模型之间的加工难度差异,深度越大成本越高,圆角越小成本越高,且3D Grad-CAM的激活区域与加工难点精准对应。
四、研究贡献总结
4.1 方法论贡献
| 贡献 | 描述 |
|---|---|
| 多源数据融合 | 首次将3D CAD体素 + 材料One-Hot + 几何体积三路输入融合,显著提升成本预测精度 |
| 3D Grad-CAM可视化 | 将2D Grad-CAM扩展至3D,首次用于制造成本估算的可解释性分析 |
| 高效架构设计 | 以1/20参数量和训练时间达到最优MAPE,证明轻量模型可通过架构优化超越大模型 |
| 加工特征自动发现 | 模型无需加工特征标注即可自动识别Pocket/Slot/Step/O-ring等CNC特征 |
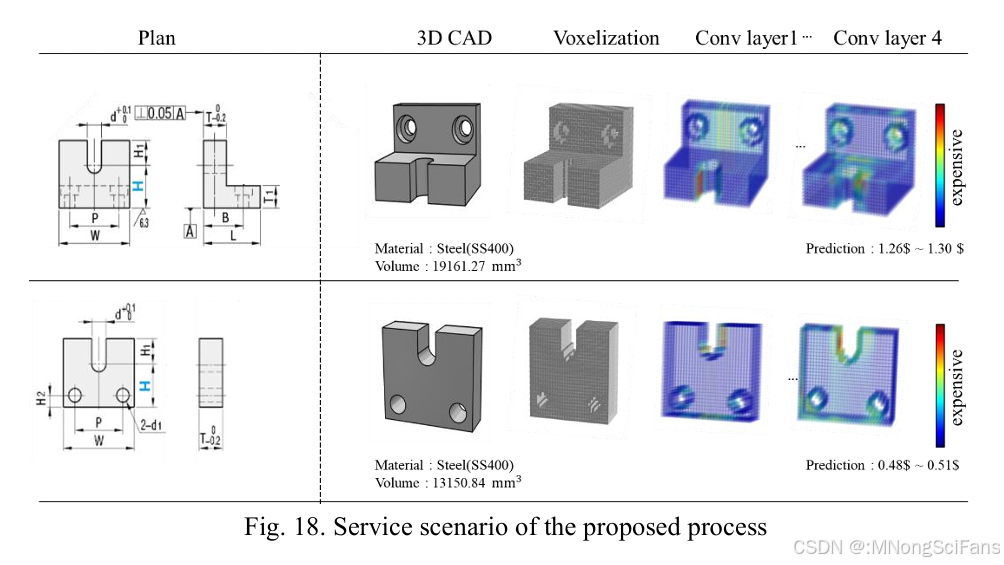
4.2 实践价值
设计师创建3D CAD模型
→ 自动体素化
→ 模型预测成本 + 3D Grad-CAM热力图
→ 设计师识别高成本区域
→ 修改CAD设计降低成本
→ 迭代优化(面向制造的设计 DFM)4.3 未来研究方向
- 实证验证:通过CNC加工模拟与专家访谈,验证深度学习提取特征对实际制造成本的显著性
- 因素建模:构建能反映加工振动、刀具选择等物理因素的深度学习模型
- 多方法对比:引入多种XAI(可解释人工智能)技术进行可视化和对比分析
- 可制造性评估:从成本预测扩展至更全面的可制造性(manufacturability)评估
五、关键技术参考
| 技术/模型 | 来源 | 应用 |
|---|---|---|
| VoxNet | Maturana & Scherer, 2015 | 基于体素的3D物体识别 |
| PointNet | Qi et al., 2017 | 基于点云的3D物体分类/分割 |
| FeatureNet | Zhang et al., 2018 | 基于3D CNN的加工特征识别 |
| Grad-CAM | Selvaraju et al., 2016 | 梯度加权的类激活映射(2D) |
| 3D CNN成本预测 | Ning et al., 2020 | 3D CAD成本预测(无可解释性) |
六、附录:完整模型性能数据
表A1:所有模型RMSE与MAPE评估结果
VoxNet
| 输入 | 归一化 | RMSE(MSE) | RMSE(MAE) | RMSE(MSLE) | MAPE(MAE) | MAPE(MSLE) |
|---|---|---|---|---|---|---|
| Voxel(32) | Minmax | 9,562.98 | 9,643.55 | 9,577.47 | 73.87 | 62.87 |
| Voxel(32) | Log | 9,603.53 | 9,792.90 | 10,121.68 | 54.05 | 56.53 |
| Voxel(32),Mat | Minmax | 2,934.82 | 2,325.73 | 2,947.66 | 33.31 | 33.08 |
| Voxel(32),Mat | Log | 3,759.66 | 3,384.20 | 3,575.19 | 21.67 | 20.65 |
| Voxel(32),Mat,Vol | Minmax | 3,175.89 | 2,716.24 | 3,141.18 | 46.63 | 29.76 |
| Voxel(32),Mat,Vol | Log | 4,279.03 | 3,582.26 | 3,109.07 | 21.54 | 19.14 |
PointNet
| 输入 | 归一化 | RMSE(MSE) | RMSE(MAE) | RMSE(MSLE) | MAPE(MAE) | MAPE(MSLE) |
|---|---|---|---|---|---|---|
| Point(2048) | Minmax | 8,238.97 | 8,301.45 | --- | 75.85 | 47.80 |
| Point(2048) | Log | 7,848.32 | 8,102.08 | --- | 38.47 | 38.96 |
| Point(2048),Mat | Minmax | --- | 5,165.62 | --- | --- | 40.05 |
| Point(2048),Mat | Log | 14,360.73 | 8,116.47 | --- | 79.14 | 32.51 |
| Point(2048),Mat,Vol | Minmax | 9,430.96 | 5,103.17 | --- | 214.82 | 47.74 |
| Point(2048),Mat,Vol | Log | 3,803.78 | 3,724.84 | 3,785.82 | 21.17 | 26.95 |
Dering et al. (2017)
| 输入 | 归一化 | RMSE(MSE) | RMSE(MAE) | RMSE(MSLE) | MAPE(MAE) | MAPE(MSLE) |
|---|---|---|---|---|---|---|
| Voxel(32) | Minmax | 9,693.04 | 9,493.96 | 9,320.58 | 66.13 | 48.23 |
| Voxel(32) | Log | 9,678.50 | 11,310.82 | 10,403.58 | 47.33 | 42.00 |
| Voxel(32),Mat | Minmax | 2,217.01 | 1,813.02 | 2,146.88 | 34.00 | 23.68 |
| Voxel(32),Mat | Log | 2,436.63 | 4,176.82 | 4,568.14 | 21.06 | 24.39 |
| Voxel(32),Mat,Vol | Minmax | 1,684.68 | 1,615.86 | 1,794.75 | 28.11 | 21.09 |
| Voxel(32),Mat,Vol | Log | 2,014.87 | 2,574.63 | 3,779.48 | 12.89 | 14.44 |
Williams et al. (2019)
| 输入 | 归一化 | RMSE(MSE) | RMSE(MAE) | RMSE(MSLE) | MAPE(MAE) | MAPE(MSLE) |
|---|---|---|---|---|---|---|
| Voxel(64) | Minmax | 10,100.41 | 9,599.60 | 9,981.19 | 72.96 | 69.94 |
| Voxel(64) | Log | 9,790.24 | 9,842.57 | 9,960.12 | 59.24 | 56.36 |
| Voxel(64),Mat | Minmax | 3,154.01 | 2,932.19 | 3,079.07 | 47.61 | 52.86 |
| Voxel(64),Mat | Log | 2,348.79 | 2,771.57 | 2,749.41 | 17.80 | 16.38 |
| Voxel(64),Mat,Vol | Minmax | 3,291.00 | 2,695.29 | 3,336.64 | 37.05 | 33.76 |
| Voxel(64),Mat,Vol | Log | 3,318.75 | 2,165.35 | 3,117.80 | 24.27 | 14.12 |
Ning et al. (2020)
| 输入 | 归一化 | RMSE(MSE) | RMSE(MAE) | RMSE(MSLE) | MAPE(MAE) | MAPE(MSLE) |
|---|---|---|---|---|---|---|
| Voxel(64) | Minmax | 7,102.95 | 7,988.06 | 7,788.32 | 78.11 | 59.81 |
| Voxel(64) | Log | 8,626.35 | 8,390.24 | 8,769.09 | 44.88 | 42.50 |
| Voxel(64),Mat | Minmax | 6,915.51 | 7,169.04 | 7,097.48 | 134.80 | 115.98 |
| Voxel(64),Mat | Log | 1,565.27 | 1,486.90 | 1,299.94 | 12.86 | 11.43 |
| Voxel(64),Mat,Vol | Minmax | 9,040.21 | 7,136.89 | 6,374.03 | 139.10 | 113.18 |
| Voxel(64),Mat,Vol | Log | 1,047.27 | 1,140.85 | 1,062.55 | 10.43 | 10.96 |
提出模型(Proposed Model)
| 输入 | 归一化 | RMSE(MSE) | RMSE(MAE) | RMSE(MSLE) | MAPE(MAE) | MAPE(MSLE) |
|---|---|---|---|---|---|---|
| Voxel(32) | Minmax | 10,290.33 | 10,644.07 | 11,151.45 | 45.29 | 42.76 |
| Voxel(32) | Log | 5,163.67 | 5,287.54 | 5,219.51 | 48.10 | 48.07 |
| Voxel(32),Mat | Minmax | 7,948.82 | 8,271.09 | 7,646.84 | 68.57 | 63.69 |
| Voxel(32),Mat | Log | 882.89 | 9,249.08 | 8,991.28 | 41.46 | 41.12 |
| Voxel(32),Mat,Vol | Minmax | 1,332.49 | 1,377.27 | 1,399.76 | 27.93 | 22.76 |
| Voxel(32),Mat,Vol | Log | 1,137.45 | 1,333.06 | 1,305.52 | 21.65 | 20.58 |
| Voxel(32),Mat,Vol | Minmax | 1,137.45 | 1,333.06 | 1,305.52 | 21.65 | 20.58 |
| Voxel(32),Mat,Vol | Log | 1,825.31 | 1,290.41 | 1,816.94 | 11.44 | 8.76 ✅ |
注:加粗行为提出模型的最优配置,MAPE=8.76%为所有108个模型中的最佳结果。