
图一:演讲嘉宾:马达(燧原科技)
「不卷算力卷效率 | HAMi 社区 Meetup」深圳站由 HAMi 社区发起,密瓜智能主办,2026 年 4 月 25 日在深圳圆满结束。本文为 HAMi 社区 Meetup 深圳站回顾系列第五篇。燧原科技马达深度拆解了国产 GPU 在 Kubernetes 生态中的云原生集成方案------从 GPU Operator 全生命周期管理、CDI 标准设备注入,到基于 CNCF 四层栈的 Inference Gateway 推理网关架构,覆盖了设备发现、资源调度、容器接入、可观测性和推理优化的完整链路。
核心亮点:
- 1 个 CR 管理 7+ 核心组件,GPU Operator 实现全生命周期声明式管理
- Device Plugin + DRA 双轨调度,覆盖 K8s 1.9 ~ 1.34+ 全版本平滑过渡
- 采用 CNCF 标准 CDI 取代厂商私有环境变量,告别碎片化设备注入
- 三层 Exporter 全栈可观测,采集频率 15s、CPU 开销 < 1%
- 正在开发 GPU EPP 插件,通过队列深度、KV 命中率打分实现推理智能路由
视频回放及 PPT 下载
一、国产 GPU 云原生集成的核心挑战
燧原科技(Enflame)的 GPU 是国产 AI 加速芯片的重要力量。大模型训练与推理正推动加速卡集群从数十卡扩展到数千卡,Kubernetes 已成为 AI 基础设施的事实标准。然而在 K8s 环境中,国产 GPU 面临的挑战比英伟达更加严峻:
- 设备不可见 --- 调度器无法感知 GPU 型号、显存大小、芯片系列等硬件属性,无法做到精准调度
- 资源难管理 --- 缺少标准化的设备发现、注册、分配、回收机制,异构卡混部困难
- 运维复杂 --- 驱动、运行时、监控等 7+ 组件需要大量人工操作,集群规模扩大后问题激增
- 生态碎片化 --- 不同厂商方案各异(环境变量、注入方式、切分策略各不相同),缺乏统一的云原生集成路径
燧原的目标:构建一套标准化的云原生集成方案,让国产 GPU 的 K8s 管理体验与英伟达一样丝滑。
二、GPU Operator:全生命周期统一管理
整体架构
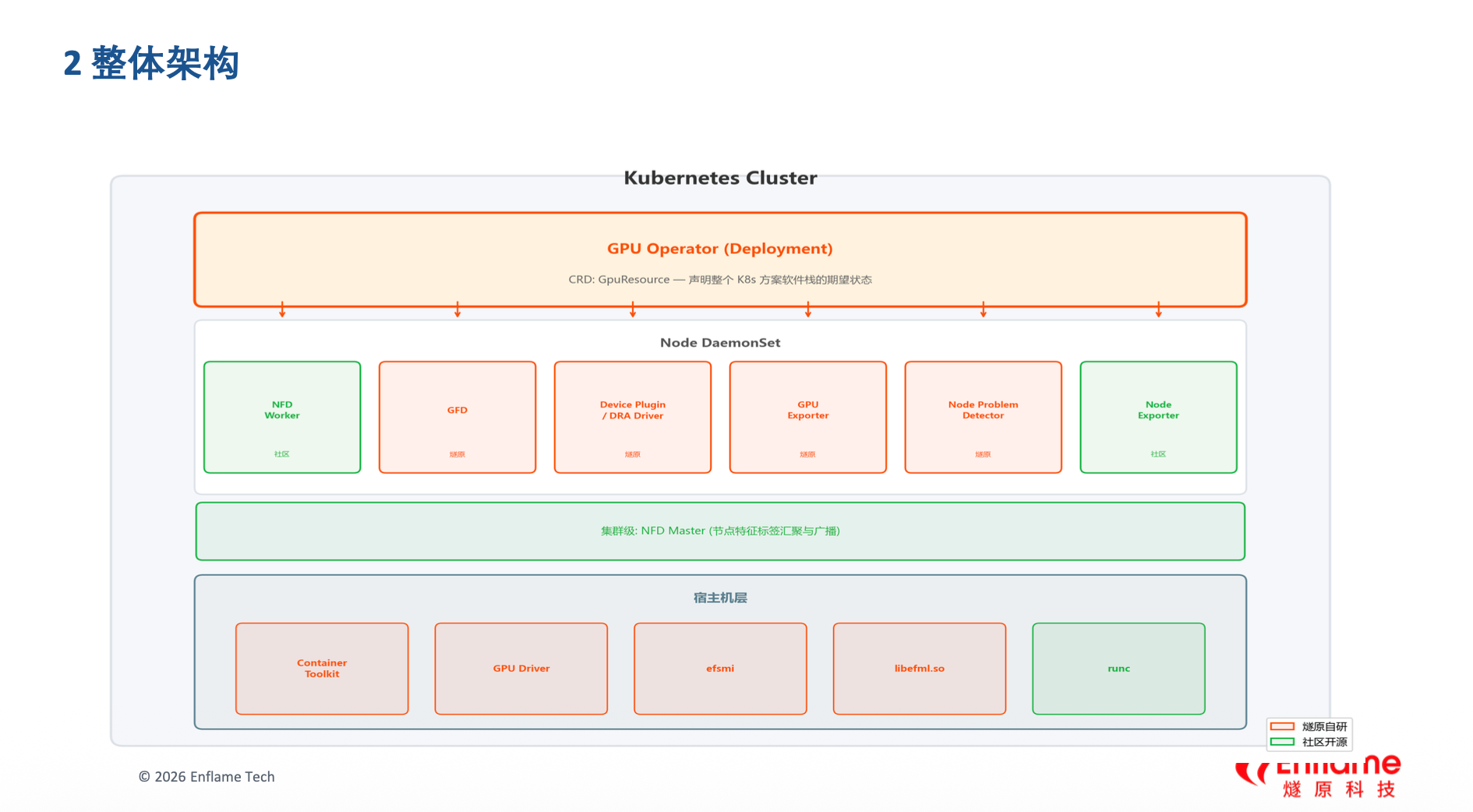 图2: GPU Operator 整体架构
图2: GPU Operator 整体架构
燧原通过 GPU Operator 统一管理 7+ 核心组件,实现从硬件到集群的全生命周期管理:
- GFD(GPU Feature Discovery)--- 自动发现 GPU 设备并暴露硬件特征为节点标签
- NFD(Node Feature Discovery)--- 发现节点级硬件特征(CPU、内存、网络等)
- Device Plugin / DRA Driver --- 将 GPU 资源上报给 K8s 调度器,支持双轨调度
- GPU Exporter --- 采集 GPU 利用率、显存、温度、功耗等指标
- NPD(Node Problem Detector)--- 内核错误/硬件异常/驱动故障检测
- Node Exporter --- 系统级 CPU/内存/磁盘/网络监控
- Container Toolkit --- OCI runtime wrapper,透明注入 GPU 设备和驱动库
CRD 声明式管理
通过 CRD(apiVersion: enflame.com/v1, kind: GpuResource)进行声明式管理,运维人员只需定义一个 CR 即可管理 7+ 组件。效果:
- 一键部署 --- 所有组件通过 CR 自动部署
- 滚动升级 --- 驱动、运行时等组件平滑升级
- 自动 Reconcile --- 配置漂移自动修复,运维复杂度显著降低
设备发现自动化
硬件属性到 K8s 节点标签的全自动管道:
GPU 硬件 → efsmi / libefml → GFD → 标签文件 → NFD → Node Labels采用三级后端自动回退,兼容不同驱动版本:
efsmi -q --json-format--- JSON 输出(推荐)efsmi -q--- 文本解析(兼容旧版)libefml.so--- CGO 绑定(最终回退)
标签每 60 秒 自动刷新,驱动升级对上层工作流无感知。运维人员可通过 nodeSelector 实现精准调度,例如 enflame.com/gpu.model: S60 或按显存大小筛选。
三、资源调度演进:Device Plugin 到 DRA
燧原实现了 Device Plugin 和 DRA Driver 双轨调度,覆盖 K8s 1.9 到 1.34+ 的全版本范围,实现平滑过渡。
| 维度 | Device Plugin | DRA Driver |
|---|---|---|
| 资源声明 | resources.limits 按数量 |
ResourceClaim + CEL |
| 设备选择 | 仅数量 | 按属性(型号/显存/profile) |
| 设备切分 | 整卡 | DRS 静态切片 |
| 多设备组合 | 不支持 | 支持 |
| 设备注入 | 环境变量 | CDI |
DRA 三步使用流程
- 定义 DeviceClass (Operator 自动部署):
kind: DeviceClass, metadata.name: enflame.com - 创建 ResourceClaim + CEL 精确选卡:通过 CEL 表达式指定型号、显存等属性
- Pod 引用 Claim:调度器 + DRA Driver 自动分配 + CDI 注入
DRS 静态切片
一张 S60 整卡显存充足时,可通过 DRS 切分为多个逻辑切片,供多个推理任务共享:
- 1g.11gb --- 4 切片,1/4 显存,适用于小模型推理(开发调试)
- 2g.22gb --- 2 切片,1/2 显存,适用于中等模型推理(中等负载)
- full --- 1 切片,完整显存,适用于训练/大模型推理(重负载)
节点启动时划分,调度器按切片粒度分配,运行时隔离由驱动与 Container Toolkit 协同保证。
四、CDI + Container Toolkit:容器透明接入
Container Toolkit 工作机制
Container Toolkit 作为 OCI runtime wrapper 拦截容器启动流程,四步完成设备注入:
- 解析容器环境变量 / CDI Spec
- 修改 OCI runtime spec
- 注入
/dev/gpu*、libefml.so、驱动库 - 调用底层 runc 启动容器
两种接入模式:
- Legacy 模式 --- 通过环境变量
ENFLAME_VISIBLE_DEVICES注入,Device Plugin 路径,兼容旧方案 - CDI 模式(推荐)--- 通过 CDI Spec + devices 字段注入,DRA 路径,标准化方案
兼容 Docker / containerd / CRI-O,与运行时解耦。
CDI:告别厂商私有环境变量
传统 GPU 容器化方案依赖厂商私有的环境变量(如 NVIDIA_VISIBLE_DEVICES),不同厂商的注入方式各不相同,缺乏标准化。
燧原采用 CDI(Container Device Interface) ------ CNCF 标准设备注入规范,取代厂商私有方案。CDI Spec(/etc/cdi/enflame.com-gpu.yaml)声明 deviceNodes、mounts、env、hooks。
CDI 四大优势:
- 标准化 --- K8s DRA、Podman、CRI-O 原生支持
- 声明式 --- Spec 描述注入内容,运行时负责执行
- 可组合 --- 多设备(GPU + RDMA)组合注入
- 动态生成 ---
enflame-ctk generate按硬件产出 Spec
五、全栈可观测
燧原构建了三层 Exporter,从芯片到集群实现全链路可观测:
- 加速卡层(GPU Exporter)--- 采集利用率、显存、温度、功耗、ECC、PCIe 等指标
- 系统层(Node Exporter)--- 采集 CPU、内存、磁盘、网络等系统级指标
- 健康层(NPD)--- 检测内核错误、硬件异常、驱动故障
生态集成路径:GPU 硬件 → libefml → GPU Exporter → Prometheus → Grafana,并接 AlertManager 实现告警。采集频率 15 秒 ,CPU 开销 < 1%,Pod 级使用量与工作负载标签关联。
六、端到端工作流
从用户提交 Pod 到 GPU 推理的完整自动化链路,用户视角:提交 Pod,其余自动化。
- 用户提交 Pod(声明 GPU 资源需求)
- K8s Scheduler 读取 GFD 节点标签 → 匹配 → 选择最优节点
- Kubelet + Device Plugin / DRA Driver 分配设备 + 生成配置
- Container Toolkit 注入
/dev/gpu*+ 驱动库 - 容器启动,应用使用 GPU 执行推理/训练
- 持续运行:GPU Exporter → Prometheus / NPD → K8s API / GFD → 标签刷新
七、Inference Gateway:推理场景专项优化
从 GPU 管理到 LLM 推理的全栈架构
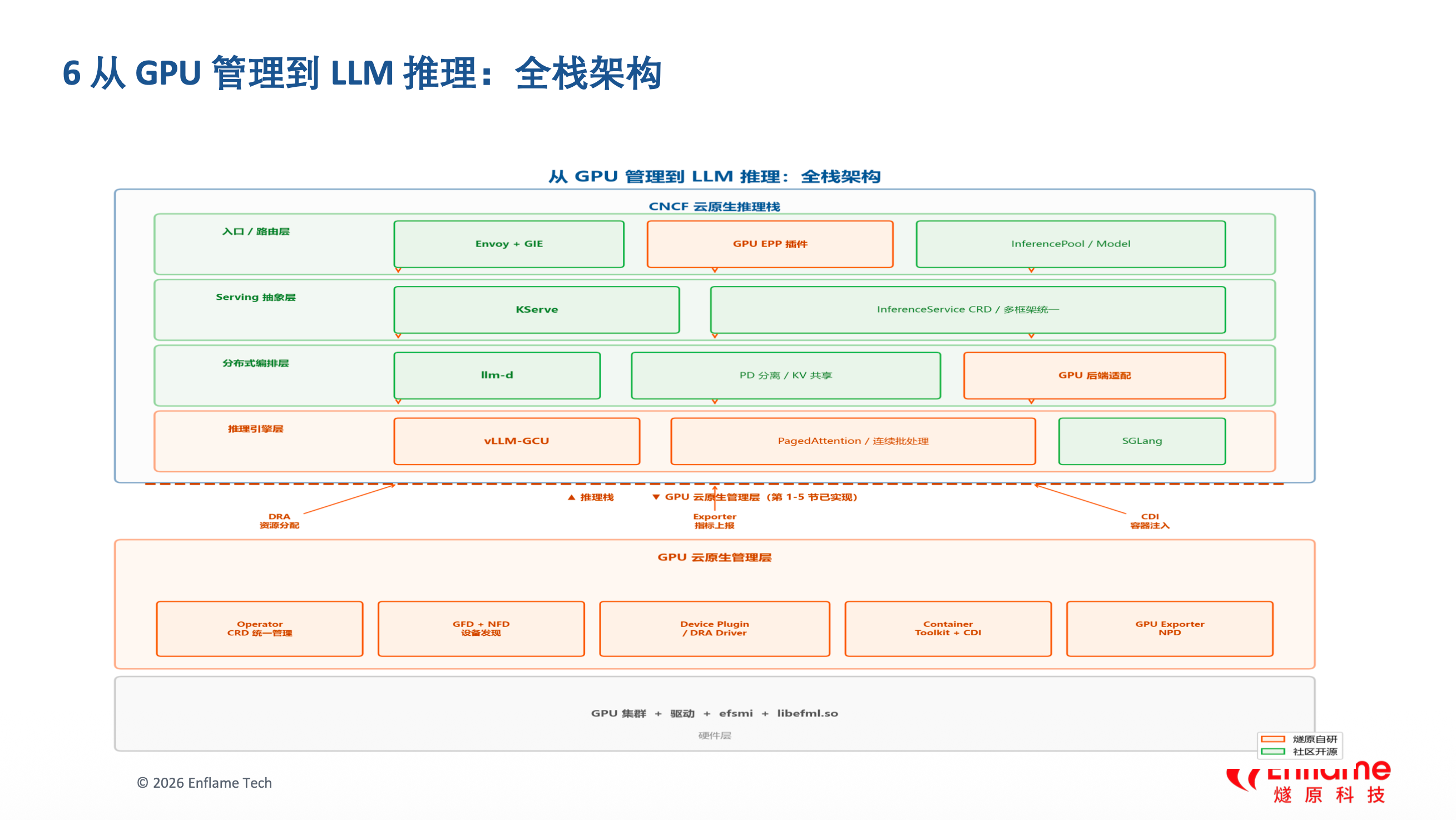 图3: Inference Gateway 全栈架构
图3: Inference Gateway 全栈架构
大模型推理正从单体部署走向分布式云原生推理,面临高并发、长上下文、KV cache 管理、SLO 保障等挑战。燧原对标 CNCF 四层标准推理栈,目标是让 GPU 作为原生后端完整接入全部四层:
| 层级 | 标准组件 | 职责 |
|---|---|---|
| 入口/路由 | Envoy + GIE | 模型感知路由、KV 打分、多租户(LLM 时代的 Ingress) |
| Serving | KServe | InferenceService CRD、多框架统一(推理的 Deployment) |
| 编排 | llm-d | Prefill/Decode 分离、跨 Pod KV 共享(vLLM 分布式调度) |
| 引擎 | vLLM / SGLang | PagedAttention、连续批处理(计算核心) |
GIE 与 llm-d 的分工(互补不替代):
- GIE 位于 Pod 之前,决定请求路由到哪个后端 Pod
- llm-d 位于 Pod 之内 / 之间,决定请求在多 Pod 之间如何协同执行
GIE:CNCF LLM 推理标准路由层
GIE(Gateway API Inference Extension)是 CNCF LLM 推理标准路由层,核心包含三个 CRD:
- InferencePool --- 推理后端组,通过 DRA 分配 GPU
- InferenceModel --- 定义模型、版本、灰度、多租户策略
- EPP(Endpoint Picker)--- gRPC 插件,Gateway 调用选 Pod
燧原正在开发的 GPU EPP 插件,通过队列深度、KV 命中率、显存余量等指标打分实现智能路由,同时支持:
- Prefix Cache 路由 --- 相同前缀落同一节点,提升 KV 命中率
- PD 分离路由 --- Prefill/Decode 独立 InferencePool,按阶段分发
- SLO 与公平性 --- 租户 priority/fairness + DRS 切片隔离,多租户 SLO 保证
- 灰度 & A/B --- InferenceModel 多版本路由 + GPU Exporter 灰度指标,上线安全
SLO 驱动的弹性伸缩
基于推理关键指标驱动 HPA,实现智能弹性:
- TTFT(Time To First Token):首 Token 延迟
- TPOT(Time Per Output Token):每 Token 生成时间
- 队列深度(Queue Depth):请求排队情况
- KV Cache 命中率:三级缓存(HBM → 主机 → NVMe)
Prefill / Decode 独立扩缩 + DRS 切片重组。最终形态:声明模型 + SLO,调度/路由/扩缩/监控全链路自动化。
燧原 GPU × HAMi:异构算力调度的协同之路
本场 Meetup 由 HAMi 社区 发起、「Dynamia 密瓜智能(Dynamia」 主办。HAMi 是 CNCF 托管的开源项目,也是目前业界唯一实现灵活、按需、弹性、可靠 GPU 虚拟化的开源方案,已支持 NVIDIA、昇腾、燧原等国内外主流 AI 芯片,最终用户超过 200 家企业。
燧原在分享中展示的全栈云原生方案------从 GPU Operator 到 DRA 调度、CDI 设备注入再到 Inference Gateway------与 HAMi 的异构算力调度能力高度互补:
燧原 × HAMi 的关键结合点:
- GPU 共享与虚拟化 --- 燧原通过 DRS 实现静态切片,HAMi 在此基础上提供更细粒度的按需、弹性 GPU 共享,支持显存隔离与算力切分,让多推理任务共享同一张燧原 GPU,利用率可从单卡 30% 提升到 80%+
- 异构混部调度 --- 燧原 GPU 作为 HAMi 已支持的设备类型之一,可通过 HAMi 统一调度层实现与 NVIDIA、昇腾等异构卡的混合部署,一套调度策略管理多厂商 GPU 集群
- DRA 标准协同 --- 燧原正在推进 DRA Driver,HAMi 也在积极对接 DRA 体系,双方在ResourceClaim、CEL 属性选择、DeviceClass 等标准上深度协作,共同推动国产 GPU 在 K8s DRA 中的标准化接入
- 全栈可观测联动 --- 燧原的三层 Exporter 体系可与 HAMi 的监控能力联动,为异构集群提供统一的 GPU 利用率视图,支撑精细化调度决策
燧原 GPU 已在 HAMi 的支持列表中。未来双方将在 DRA 深度集成、弹性调度策略、异构推理路由等方向持续协同,让国产 GPU 在云原生环境中发挥更大价值。
八、未来展望
燧原在标准化方向的关键规划:
- DRA GA 与能力扩展 --- 更丰富的 CEL 属性、跨节点 ResourceClaim、Partitionable Devices
- Inference Gateway 标准化 --- GIE beta → GA,多租户与 SLO 行为标准化
- CDI 生态收敛 --- containerd / CRI-O 原生 CDI 支持推进到 GA
- 开放生态合作 --- 与 CNCF、上游社区、框架厂商长期协作;与 HAMi 在 DRA 方向深度集成
九、核心价值总结
燧原科技围绕国产 GPU 云原生管理构建了完整的方案矩阵:
- GPU Operator(已落地)--- 解决设备管理碎片化,通过 1 个 CR 管理 7+ 组件
- Device Plugin + DRA(已落地)--- 解决资源调度不统一,覆盖 K8s 1.9 ~ 1.34+ 双轨调度
- CDI(已落地)--- 解决厂商私有方案,实现标准化设备注入
- 全栈可观测(已落地)--- 解决 GPU 黑盒运维,三层 Exporter 秒级采集
- Inference Gateway(进行中)--- 解决推理效率与 SLO 问题,智能路由 + 弹性伸缩
- HAMi DRA 集成(规划中)--- 解决异构调度统一,与 HAMi 生态共建
其中四项核心能力已落地生产环境,Inference Gateway 正在开发中,HAMi 集成处于规划阶段,整体成熟度高。
总结
燧原科技在本场分享中展示了一套完整的国产 GPU 云原生集成方案,涵盖从底层设备管理到上层推理优化的全栈能力。这套方案的核心思路是全面拥抱 CNCF 标准------通过 GPU Operator 实现声明式管理,通过 CDI 取代厂商私有方案,通过 DRA 实现精细化调度,通过 GIE 对标业界推理网关标准。
对于国产 GPU 厂商而言,燧原的实践提供了一个重要启示:云原生的竞争不仅是功能的竞争,更是标准的竞争。率先完成 CNCF 标准对齐,意味着在混合云、多云场景中拥有更强的互操作性和生态优势。而对于用户来说,选择一套已经与 K8s 生态深度融合的 GPU 管理方案,能够显著降低异构算力的接入成本和运维复杂度。
随着 DRA 逐步走向 GA、GIE 标准化推进、CDI 生态持续收敛,国产 GPU 与云原生生态的融合将越来越丝滑。燧原与 HAMi 社区在 DRA 方向的深度集成,也值得持续关注。
HAMi 是 CNCF 托管的开源项目与社区,核心方向是 GPU 虚拟化与异构算力调度,面向 AI 场景提升算力利用效率;其目标是实现 灵活、按需、弹性、可靠 的 GPU 虚拟化,并持续扩展对主流 AI 芯片生态的支持。
「密瓜智能(Dynamia) 」专注 GPU 虚拟化与异构算力调度,发起并主导 CNCF 开源项目 HAMi;同时基于 HAMi 提供商业发行版、企业产品与服务,帮助用户在真实业务中规模化使用相关能力
官网:dynamia.ai
邮箱:info@dynamia.ai
HAMi 项目地址:https://github.com/project-hami/hami
本文作者「Dynamia密瓜智能」
版权声明:本文为CSDN博主「密瓜智能」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://dynamia.ai/zh/blog/enflame-k8s-cloud-native-practice