一、背景介绍
论文地址:https://arxiv.org/pdf/1706.03762
模型优势
- 能够实现并行计算,提高模型训练效率
2.更好的特征提取能力
发展进程:
ANN人工神经网络 -> RNN循环神经网络 -> LSTM/GRU -> Seq2Seq 模型框架 ->
Seq2Seq + 注意力机制 -> Transformer -> GPT、BERT、DeepSeek、Qwen等
绝大多数大模型底层的原理都是Transformer
二、框架结构
1. Seq2Seq 与 Transformer
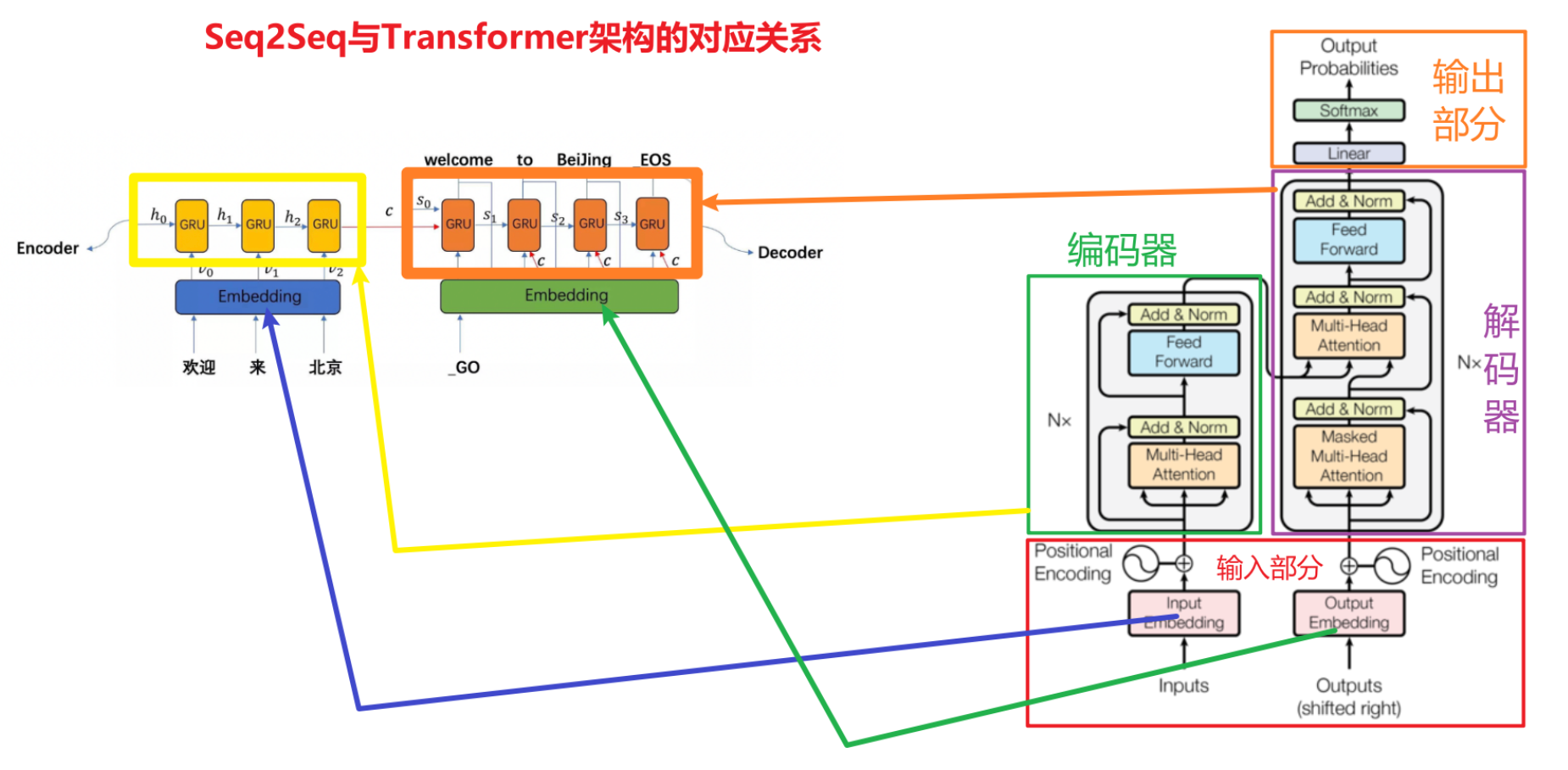
2.四大部分
① 输入部分 ② 编码器部分 ③ 解码器部分 ④ 输出部分
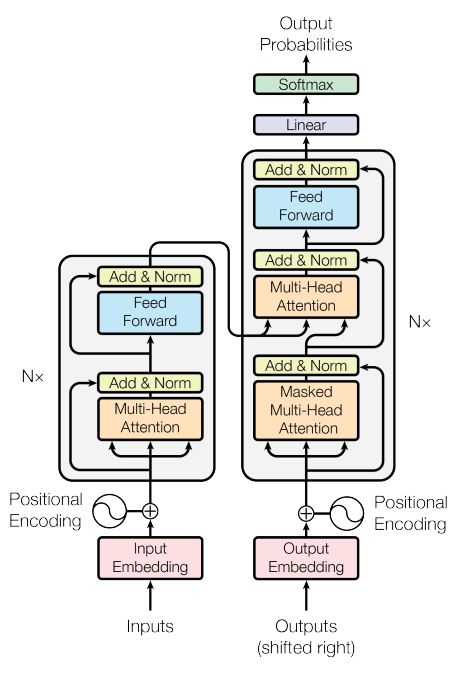
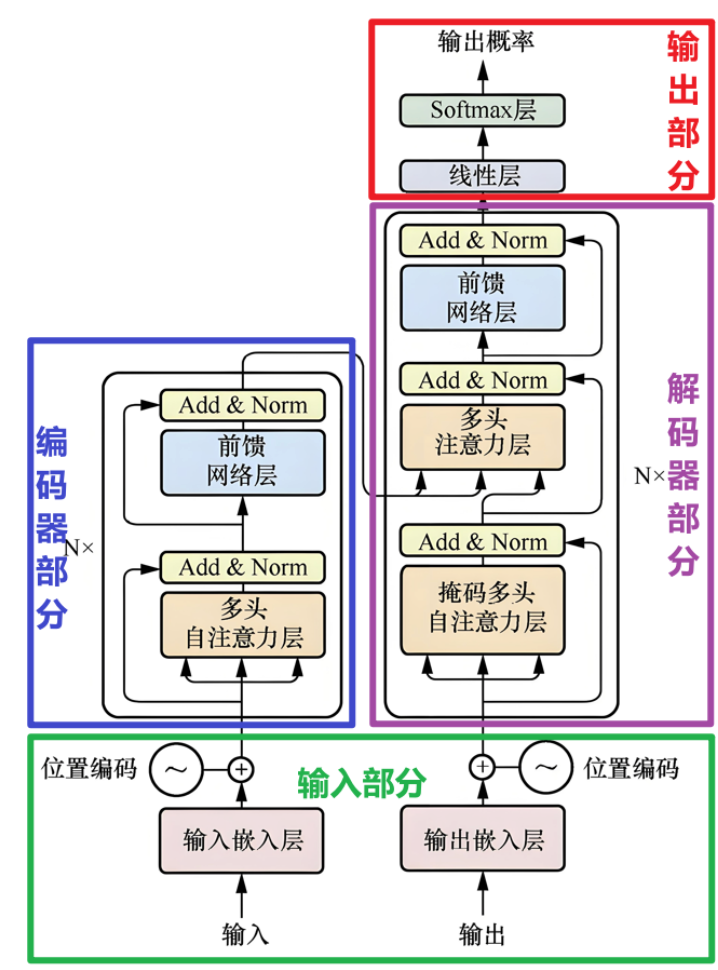
============================== ++通用部分++ ===================================
Positional Encoding:位置编码
作用:给词向量增加位置信息。transformer框架本身是不明白词和词之间的顺序关系。所以需要额外告诉它,位置不同,词的含义也不同。
例如:小龙女想 过过 过过 过过 的生活,3个过过 含义完全不一样。
Feed Forward: 前馈神经网络/前馈全连接层
作用: 对每个位置的词向量进行信息增强,经过注意力机制处理后的数据,再使用前馈网络加工一下,给每个词添加更多的额外信息。
Add & Norm: 残差连接 和 层归一化/规范化层
作用:Add残差连接,是把注意力机制计算结果和原始结果进行求和
Norm层归一化,让数据调整到正态分布中,让模型更加稳定。
============================= ++编码器端部分++ =================================
左Nx:编码器层堆叠N层,得到编码器
作用: 把【多头自注意力子层+前馈网络】堆叠了6层。论文中N的值是6
Multi-Head Attention: 多头注意力
作用: 让模型同时从多个角度关注句子中每个词的含义
例如:大家就业时候,1个老师负责100个学生就业,那么每个学生受到帮助的程度都比较少。老师人数增加到10个,平均每个老师负责10个学生,10个老师不仅能够同时搞就业,而且每个学生受到关注的程度变高
Input Embedding: 编码器端的词嵌入层
作用:把词索引转成词向量
============================= ++解码器端部分++ =================================
右Nx:将解码器层堆叠N层,得到解码器
作用:把【掩码多头自注意力子层+多头注意力子层+前馈网络子层】堆叠了6层。论文中N值是6
Multi-Head Attention:多头注意力(也称为 交叉注意力 Cross Attention)
作用:让解码器更加关注解码器端输出的哪些数据
例如:文本翻译的时候,解码器译to之前,要分别与编码器端的欢迎、来、北京计算相似性。
Masked Multi - Head Attention: 掩码多头自注意力
作用:掩码的作用是为了防止偷看未来(后面)的词
例如:文本翻译的时候,解码器得到英语单词,例如翻译to的时候,只能查看它当前已翻译得到的词(例如Welcome),不能查看还未翻译的词(例如Beijing)
Output Embedding:解码器端的词嵌入层
作用:把词索引转成词向量
3.架构概述
输入文字 -> 嵌入 -> 位置编码 -> 编码器多层加工(注意力+前馈) -> 解码器多层加工(掩码注意力 + 关联编码器(交叉注意力) + 前馈) -> 线性层 -> Softmax -> 输出概率选词
整体架构的核心:
注意力机制抓关联,多层堆叠挖深度,残差归一化稳训练
三、具体开发步骤
1.编码器
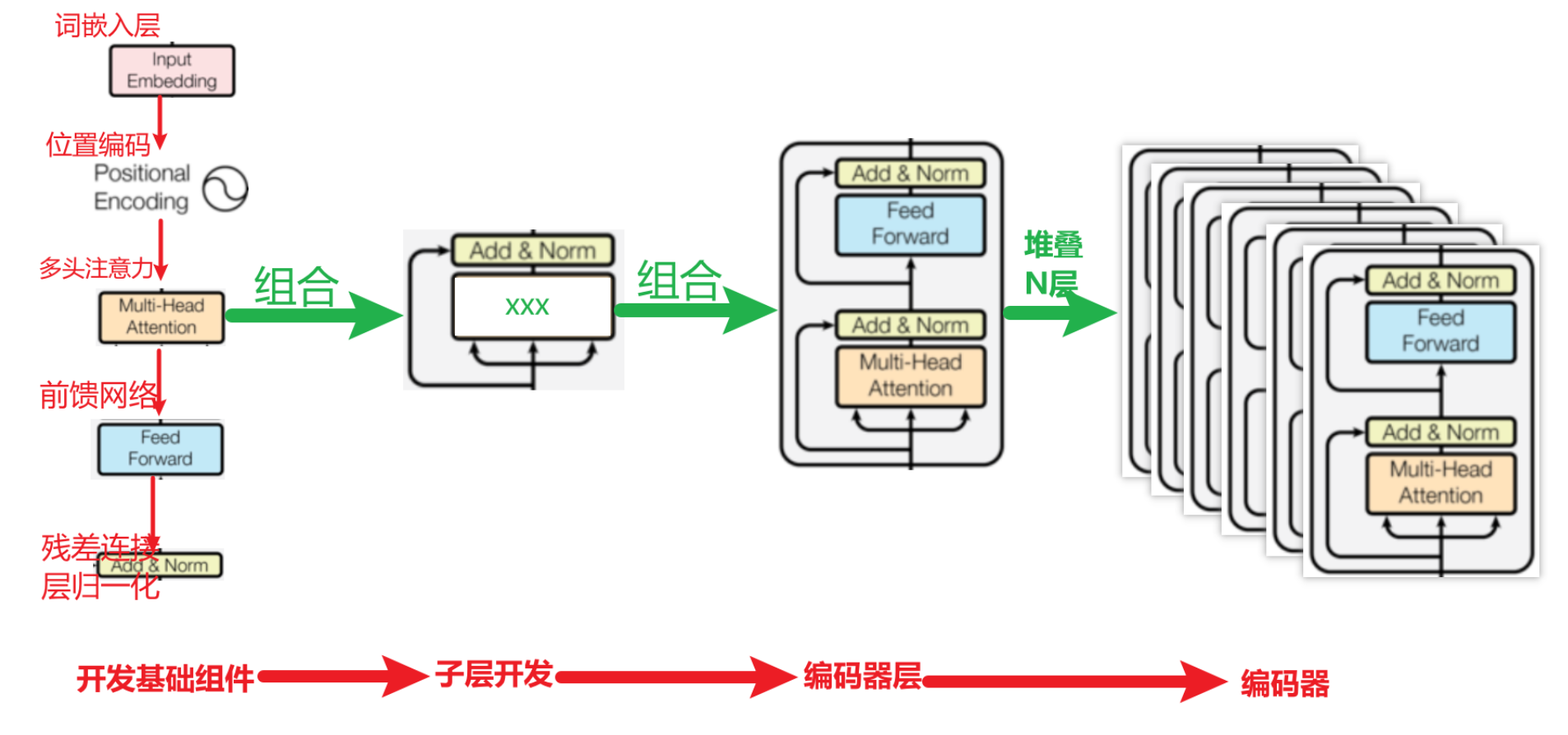
2.解码器
参考编码器的开发过程,大部分地方的功能直接服用。主要开发【掩码多头自注意力层】
3.输出部分
非常简单,nn.Liner全连接层+Softmax激活函数