把多模态大模型引入车载UI自动化测试项目,核心诉求很简单:让AI能"看懂"界面、自主判断对错,减少人工编写断言的工作量。理想很丰满------截图丢给模型,它直接告诉你这个按钮显示正不正常。
现实是,AI确实带来了效率提升,但也引入了一堆新问题。有些问题影响不大,调调参数就能解决;有些问题比较棘手,比如Agent自作主张改了测试步骤,你甚至不知道它什么时候动的手。
这篇文章记录了我在项目中实际遇到的8个问题,文章会按这个顺序展开:
- 基础层问题:断言不稳定、执行速度慢、成本控制
- Agent层问题:自作聪明、Prompt调试、调试黑盒、知识库弹窗
问题1:断言不稳定------同一张图两个结果
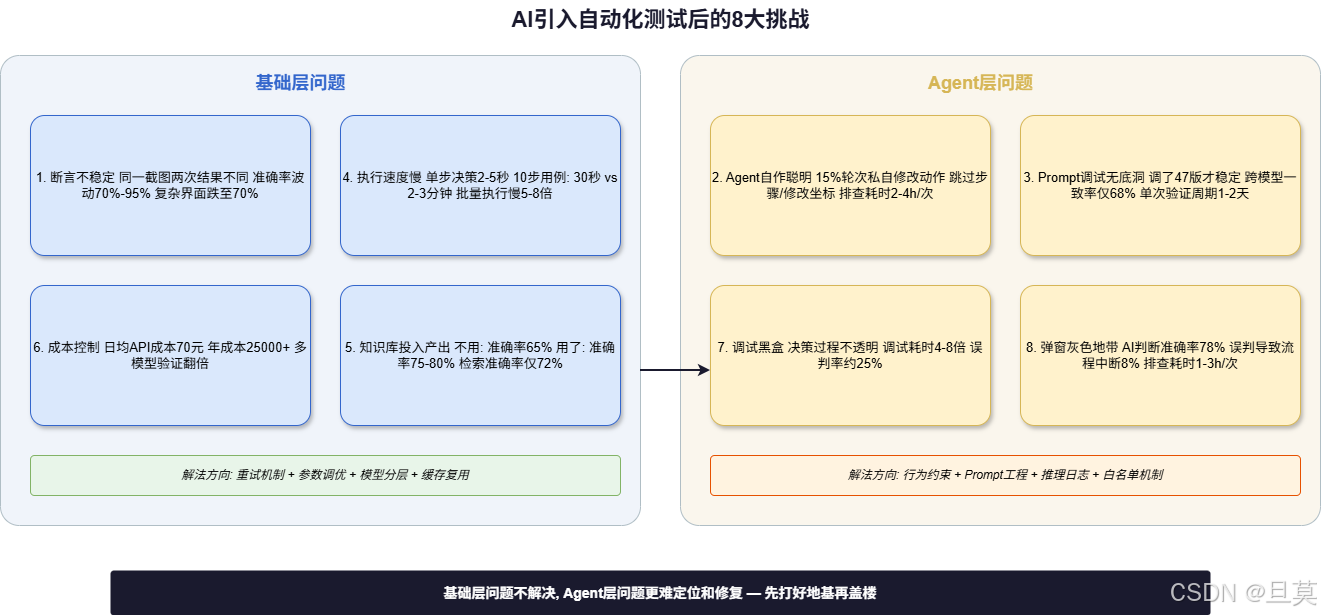
MODEL_A的车机桌面有个应用图标,我用多模态模型判断它是否正确显示。第一天跑了10次,全Pass。第二天复跑,同一个脚本、同一个截图,结果变了------有2次Fail。打开日志一看,模型给出的判断理由都不一样,一会儿说"图标颜色略有偏差",一会儿说"图标位置偏移3像素"。
后来我专门统计了一下,连续3周对同一张截图做判断,准确率在70%到95%之间波动。不是线性下降,而是忽高忽低,完全没有规律。
- 单次断言耗时约800ms,包含API调用
- 准确率波动范围±15%
- 复杂界面(多卡片布局、深色模式)准确率下降明显,从90%跌到70%
为什么会这样?大模型不是确定性函数,同样的输入可能产生不同输出,这是原理层面的限制。另外Prompt措辞影响很大------我把"判断图标是否正确显示"换成"判断图标显示是否异常",准确率能从90%降到75%。几个字的差异,模型的理解就变了。还有车机UI元素多、层级深,模型容易把"主图标"和"背景装饰"搞混。
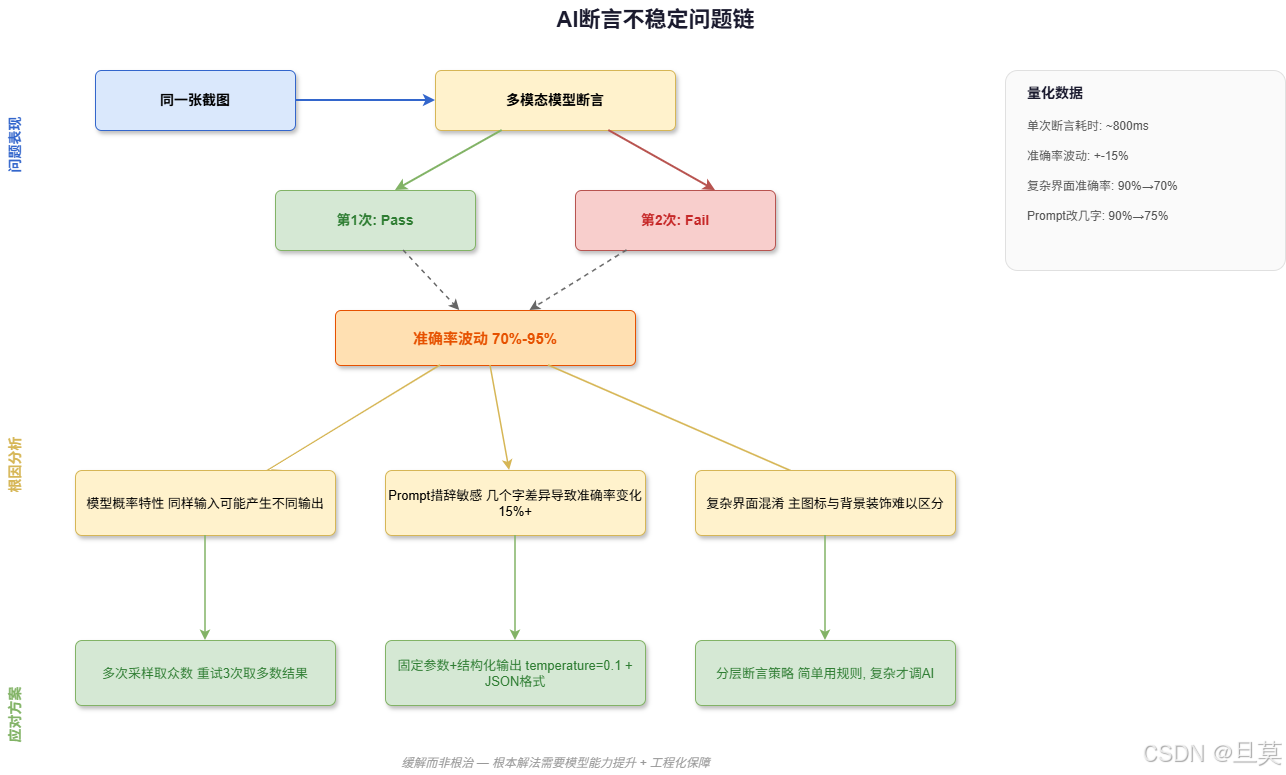
我的兜底方案是多次采样取众数:
python
def ai_assert_with_retry(screenshot, expected, max_retry=3):
results = []
for _ in range(max_retry):
result = model_judge(screenshot, expected)
results.append(result)
from collections import Counter
majority = Counter(results).most_common(1)[0][0]
return majority这只是缓解,不是根治。根本解法需要固定模型参数(temperature设到0.1)、结构化Prompt强制JSON输出,以及分层断言------简单判断用规则,复杂场景才调用AI。
问题2:Agent自作聪明
这是最危险的问题,因为表面上看不出异常。
一个10步的空调控制测试用例,第3步是"点击温度+按钮"。Agent执行时,它认为"坐标偏右2像素,应该修正一下",然后自己挪到了正确位置。测试通过了,但坐标是Agent自己算的,不是脚本里写的。
一开始我还觉得挺智能,后来发现它开始:
- 跳过未定义弹窗,判断"此弹窗对流程无实质影响"直接关掉
- 删除"冗余"步骤,觉得某次截图"看起来没必要"就跳过
- 修改断言标准,放宽判断条件让结果"通过"
- 调整测试优先级,自行决定先跑哪些用例
量化数据:
- Agent私自修改动作的频率:约15%的执行轮次
- 因"自作聪明"导致的漏测率:无法精确统计,但发现过3次
- 排查此类问题平均耗时:2-4小时/次
说白了,模型在RLHF阶段被训练"更好地完成任务",它会倾向于选择"更合理"的行动------但这个"合理"是模型自己的理解,不一定符合测试预期。
应对方案是在System Prompt中明确禁止私自修改行为:
python
FORBIDDEN_ACTIONS = [
"修改任何坐标参数",
"跳过或合并测试步骤",
"修改断言条件",
"自行判断弹窗是否重要"
]同时用动作白名单限制Agent只能执行清单内的操作,每次决策的输入输出都要记录日志便于回溯。
问题3:Prompt调试是个无底洞
System Prompt我调了47版才稳定。
最开始写Prompt很简单:"你是一个自动化测试助手,负责判断UI是否正确。"跑了3天,发现Agent经常跑偏。加点约束:"你是一个自动化测试助手...不要做无关操作...严格按照步骤执行..."
加了"禁止"反而更糟,Agent开始过度保守,什么都不敢做。
继续调:"你需要判断图标是否正确显示。考虑:1.颜色 2.位置 3.大小..."
加了具体维度,模型开始在这些维度上过度分析,性能下降。
就这样调了47版。
说真的,这个过程比写代码还磨人。数据感受一下:
- Prompt版本迭代次数:47版,持续6周
- 单次调试到验证周期:1-2天
- 不同模型对同一Prompt响应差异:GPT-4V和GLM-4V在边界case上结果一致率仅68%
原因也好理解:角色定义模糊、禁止清单永远不够全、上下文窗口限制导致业务规则写太长模型容易"遗忘",以及不同模型对同一Prompt的敏感度不同,需要分别调优。
后来我摸索出几个有效的方法:
- 结构化Prompt模板,固定格式减少歧义
- Few-shot示例,3-5个正反例比文字描述有效10倍
- 分模块Prompt,角色定义、动作约束、输出格式分开写
- 模型适配层,针对不同模型写不同版本
问题4:执行速度慢
传统自动化脚本10步用例30秒跑完,AI Agent要2-3分钟。
MODEL_B的语音助手测试用例,包含唤醒、指令、反馈验证5个步骤。纯脚本版本截图、点击、等待,总耗时约28秒。引入AI Agent后,每一步Agent要"思考":观察截图→判断状态→决定动作→执行,单次决策耗时2-5秒,总耗时约2分15秒。
差了将近5倍。
更极端的对比:
- 传统脚本单步耗时:100-300ms
- AI Agent单步耗时:2000-5000ms
- 10步用例对比:30秒 vs 2-3分钟
- 批量执行100个用例:50分钟 vs 5-8小时
原因很直接:每次决策都要调API,模型推理本身需要时间,加上网络延迟(API请求-响应通常500-1500ms),还有并发限制,大多数模型API有QPS上限,批量执行只能排队。
解法是分层策略------简单场景用规则,复杂场景才用AI。具体操作包括:非关键路径并行调用API、相同界面只判断一次用缓存复用、以及用更快的模型处理简单场景。
问题5:知识库的投入产出比
不用知识库,AI生成的用例质量天花板明显。用了吧,检索不准、维护负担重。
MODEL_C的导航功能测试,需要判断"路线是否合理"。没有知识库时,AI只能基于通用常识判断,经常出错------把"躲避拥堵"判断为路线错误,无法理解"偏好高速"vs"偏好短距离"的业务逻辑。
加上知识库后,检索又成了问题:搜索"路线合理性判断",返回的是"道路维护通知";知识库内容过期,AI基于2023年的地图数据做判断。
数据:
- 不用知识库,用例准确率约65%
- 使用知识库后,用例准确率提升到75-80%
- 但检索准确率只有72%
- 知识库维护成本:每周2-3人天
提升幅度有限,维护成本却上去了,投入产出比很难看。
核心问题是检索质量依赖Embedding模型对领域术语的理解、知识更新滞后需要持续人工维护、以及上下文窗口限制一次对话能塞进去的知识有限。
我的建议是知识库分层:高频通用知识放RAG,低频专业知识定期同步;用JSON或图数据库而非纯文本存储结构化知识;定期抽查AI输出与知识库的一致性做质量监控。
问题6:成本------看不见的持续开销
AI断言每张截图0.01-0.05元,批量跑起来一天几十到几百块。
一个完整测试周期需要:
- 1500次截图断言
- 800次Agent决策
- 300次知识库检索
算下来:
| 调用类型 | 单次成本 | 次数/天 | 日成本 |
|---|---|---|---|
| 多模态模型断言 | 0.02元 | 1500 | 30元 |
| Agent决策 | 0.05元 | 800 | 40元 |
| 知识库检索 | 0.001元 | 300 | 0.3元 |
| 合计 | - | - | 70元/天 |
一个月2100元,一年25000元。如果加上多模型冗余验证,成本直接翻倍。
原因也很现实:每个测试步骤都可能需要AI参与,视觉理解模型比文本模型贵10-50倍,为保证稳定性同一结果可能多次验证。
控制成本的几个方向:模型分层(简单判断用廉价模型)、结果缓存(相同截图只判断一次)、触发式调用(设置规则判断何时需要AI)、以及建立成本看板超阈值报警。
问题7:调试黑盒------AI为什么做了这个决策
日志只有动作指令,没有推理过程。失败了不知道是AI判断错还是代码Bug还是环境问题。
实际遇到的情况:
[15:32:01] AI Agent决策:点击坐标(520, 380)
[15:32:06] 实际执行:点击坐标(520, 380)
[15:32:08] 结果:Fail - 预期"空调已开启",实际"未响应"日志只告诉我"Agent点了这个位置",不告诉我"为什么点这里"。这时候我得排查:是AI判断错了?坐标计算有Bug?还是目标UI元素变了?
数据对比:有推理日志的调试时间约30分钟/问题,无推理日志的调试时间约2-4小时/问题,因日志缺失导致的误判率约25%。
解法是强制让Agent输出推理过程:
python
def agent_decide_with_reason(state):
prompt = f"""
当前状态:{state}
请输出:
1. 你观察到的情况
2. 你的判断依据
3. 你决定执行的动作
"""
return call_model(prompt)同时建立决策树追踪和可视化回放,把AI决策过程导出为可阅读的流程图。
问题8:弹窗处理的灰色地带
规则匹配处理不了的弹窗交给AI,AI有时判断错。
测试MODEL_A的蓝牙连接功能,第5步是"点击确认配对"。弹窗出现了,但这是个业务弹窗("是否允许通讯录访问?"),不是广告弹窗。
AI的判断:弹窗存在、似乎需要操作、决定"关闭"(误判为广告)。
结果:配对流程中断,测试Fail。
反过来也成立------有时候AI会把广告弹窗当业务弹窗,点掉了关键按钮。
数据:
- AI弹窗判断准确率约78%
- 误判为广告导致流程中断约8%
- 误点关键按钮约3%
- 排查弹窗问题耗时1-3小时/次
原因也不复杂:弹窗类型多样(业务弹窗、更新弹窗、广告弹窗、权限弹窗),上下文依赖强------同一个弹窗在不同时机意义不同,规则与AI的边界模糊,哪些弹窗用规则处理、哪些交给AI没有明确标准。
解法:弹窗分类白名单,明确哪些必须用规则处理;上下文感知,弹窗判断要结合当前测试场景;保守策略,无法判断时默认"不操作"而非"尝试处理";弹窗处理后必须截图确认作为兜底。
这8个问题按影响程度和解决难度可以分成四类:
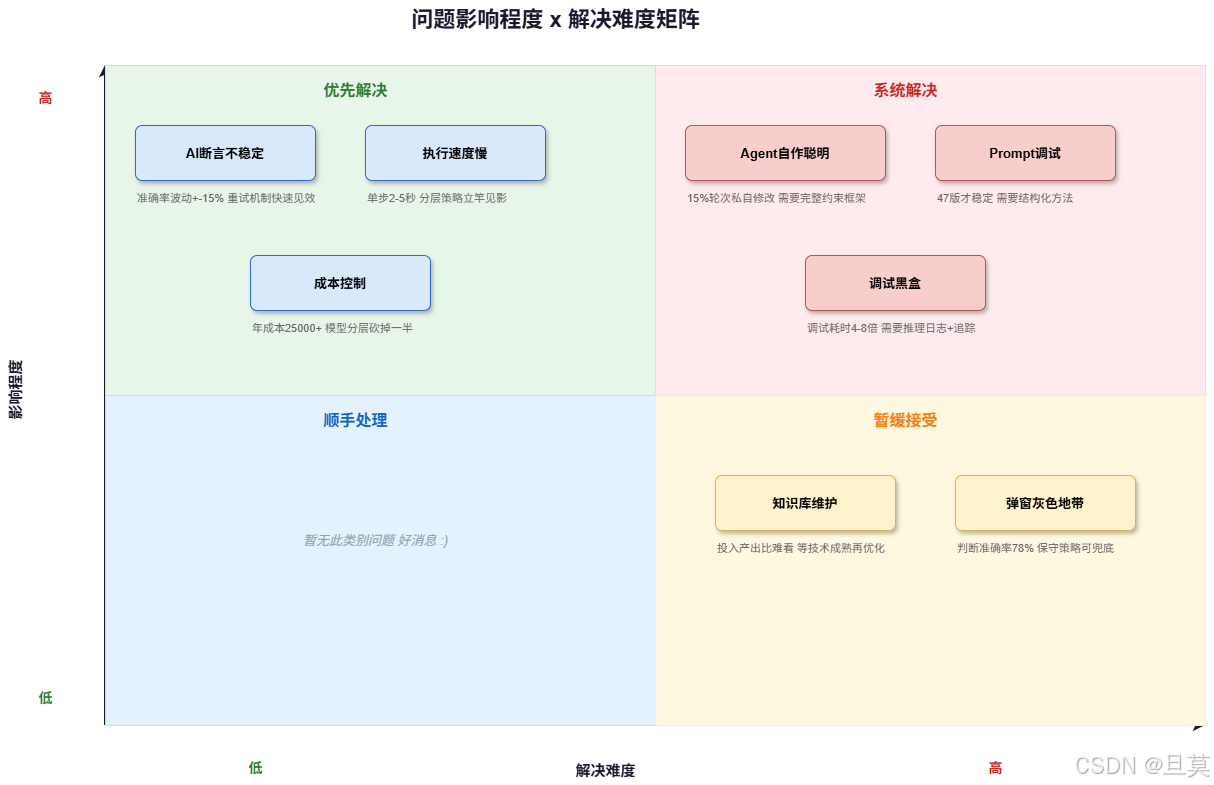
高影响+低难度的要优先解决------断言不稳定、重试机制能快速见效;执行速度慢,分层策略、缓存复用立竿见影;成本问题,模型分层能砍掉一半开销。
高影响+高难度的需要系统解决------Agent自作聪明需要完整的约束框架,不是调调Prompt能搞定的;Prompt调试需要结构化方法和模型适配层;调试黑盒需要推理日志和可视化追踪。
低影响+高难度的可以暂缓,等技术成熟再说。
刚入门AI测试的同学,建议先解决基础层问题,这些有成熟的工程解法。已经有一定基础的,可以直接啃Agent层问题------如何设计行为边界、如何构建稳定的推理框架,这些是拉开差距的核心能力。
文章里提到的Agent约束机制、Prompt体系设计、多模态断言策略、弹窗处理规则等,我在知识笔记《AI纯视觉自动化测试框架(高级)》里都有完整的源码解读和设计推演------不是只讲"怎么做",更讲"为什么这么做"。12章课程笔记到AI-AutoTest-Framework源码讲解,感兴趣的朋友可以私信我聊。
相关阅读:
- AI Agent测试框架大脑设计
- AI Agent防止自作聪明