块(Chunking)分块没做好,耶稣来了也救不了你!!!
面试官问:RAG检索效果差,你觉得最该背锅的是哪个环节?
我张口就来:"肯定是LLM生成能力不行啊。"
面试官笑了笑,没说话。然后给我看了一段代码------一个简单的固定长度切分,把一个完整的句子从中间砍断了。
"这块语义都不完整,你让LLM怎么救?"
我哑了。
回去翻了半个月的资料,才发现:RAG 翻车,70%的锅在分块(Chunking) 。
今天把这5种分块策略掰开揉碎讲清楚,别像我一样栽坑里。
一、先看清楚RAG的全流程
别一上来就调模型,先搞清楚数据怎么走的。

看懂没?生成器只能看到你喂给它的chunk。切不好,后面全是垃圾。
二、5种分块策略,别再只会上来就固定长度了
1. 固定分块 ------ 新手村的木剑
最简单粗暴:按固定token数切,加个重叠防止边界丢失。
ini
def fixed_chunk(text, max_tokens=512, overlap=50):
tokens = tokenize(text)
chunks = []
i = 0
while i < len(tokens):
chunk = tokens[i:i+max_tokens]
chunks.append(detokenize(chunk))
i += (max_tokens - overlap)
return chunks什么时候用?
拿它当baseline,或者处理日志、纯文本这种没结构的玩意儿。别指望它处理复杂文档。
2. 递归分块 ------ 先段落再句子
先按\n\n(段落)切,还太长就按\n切,再不行按句子切。一层层剥下去。
ini
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=200,
chunk_overlap=50,
separators=["\n\n", "\n", "。", " ", ""]
)
chunks = text_splitter.split_text(text)什么时候用?
文档有段落、章节结构。比固定长度聪明点,至少不会在半句话中间下刀。
下面的流程图把递归分块的决策逻辑画清楚了:
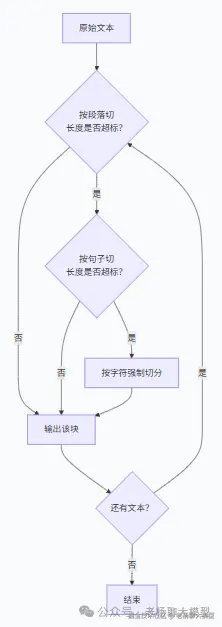
3. 语义分块 ------ 让模型判断哪里该断
把句子转成embedding,相邻句子相似度骤降的地方就是边界。语义变了,就切一刀。
ini
# 伪代码示意
sentences = split_sentences(text)
embeddings = embed(sentences)
chunks = []
current_chunk = [sentences[0]]
for i in range(1, len(sentences)):
sim = cosine_similarity(embeddings[i-1], embeddings[i])
if sim < threshold:
chunks.append(join(current_chunk))
current_chunk = [sentences[i]]
else:
current_chunk.append(sentences[i])什么时候用?
法律文书、科研论文、技术支持文档------上下文断了就出大事的场景。
代价:算embedding贵,阈值要反复调。
4. 基于结构的分块 ------ 直接读文档大纲
HTML的<h1>、<h2>,Markdown的#、##,PDF的目录------这些天然就是分块边界。
每个章节独立成块,单个章节太长再降级用递归分块。
实现要点:
- 用
BeautifulSoup(HTML)、markdown、pypdf等库抽结构 - 标题层级当根节点
- 表格、图片单独处理(要么单独成块,要么抽摘要)
说实话,这是生产环境里用得最稳的策略。配合递归分块,效果比纯语义切分还靠谱。
下面这张图对比了结构化分块和普通分块的区别:
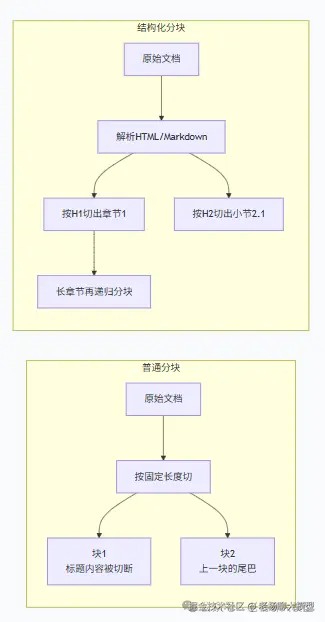
5. 延迟分块(动态分块) ------ 最高级的玩法
反转传统顺序 :先不切,存整篇文档或者大段落。等用户提问来了,检索出最相关的1-2个大段,再在这个范围内动态切细块。
有点像编程里的延迟计算------拿到上下文信息了再做决定。

适用场景:
- 长篇技术报告、学术论文(跨段落上下文很重要)
- 文档频繁更新(不用每次重算所有块)
- 法律/医疗这类高精度场景(代词指代、引用不能错)
代价呢?
计算开销大。需要支持长token的embedding模型。查询时多了一步动态切分,响应时间会涨。
三、一张表帮你选策略
| 策略 | 核心逻辑 | 适合场景 | 坑 |
|---|---|---|---|
| 固定分块 | 按长度硬切 | 日志、baseline | 语义边界乱砍 |
| 递归分块 | 层级降维切分 | 有段落结构的文档 | 依赖分隔符质量 |
| 语义分块 | embedding相似度 | 法律、论文、高精度 | 贵、阈值难调 |
| 结构化分块 | 读HTML/Markdown标签 | 技术文档、wiki | 需要解析库 |
| 延迟分块 | 查询时再动态切 | 长文、高召回场景 | 慢、贵 |
写在最后
面试那天如果我能把这些讲清楚,也不至于被怼到哑口无言。
分块这活儿,看着不起眼,决定了RAG 70%的上限。别再上来就chunk_size=512完事了。
最稳妥的组合拳:
- 技术文档 → 结构化分块 + 递归降级
- 长编报告 → 延迟分块
- 快速验证 → 固定分块打底
- 法律/医疗 → 语义分块硬扛
没有银弹。按文档类型和你的算力量力而行。
如果觉得有用,点个在看,转发给你那个还在傻傻用固定分块的同事。