论文信息
- 标题:Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
- 会议/预印本:arXiv 2020 (cs.LG)
- 单位:加州大学伯克利分校,谷歌研究大脑团队
- 相关代码:github.com/rail-berkeley/d4rl (D4RL基准库)
- 论文:https://arxiv.org/pdf/2005.01643.pdf
引言:为什么我们需要离线RL?
你有没有想过,为什么强化学习(RL)在《星际争霸》《围棋》里能吊打人类,但在现实世界却举步维艰?
- 让机器人学走路:摔个几万次才能学会,硬件都摔报废了
- 训练自动驾驶:总不能真的让车去撞墙吧?
- 医疗决策:拿病人做实验?伦理委员会第一个不同意
- 推荐系统:随便推垃圾内容,用户分分钟卸载
传统RL是个"边玩边学"的熊孩子,必须不断跟环境交互才能进步。但现实世界里,很多交互要么太贵,要么太危险,要么根本不可能。这时候,离线强化学习(Offline RL) 就站出来了:不用跟环境说一句话,只用之前存好的历史数据,就能训练出强大的决策模型。
这篇由RL界大佬Sergey Levine领衔的综述,堪称离线RL的"圣经",从基础理论到前沿算法,从核心挑战到工业应用,给你讲得明明白白。今天我们就来扒一扒这篇神作,看看离线RL到底是怎么解决"不用交互也能学"这个世纪难题的。
一、什么是离线RL?先搞懂三种RL范式
首先我们来对比一下三种最常见的RL范式,看完你就明白离线RL到底特殊在哪里了。
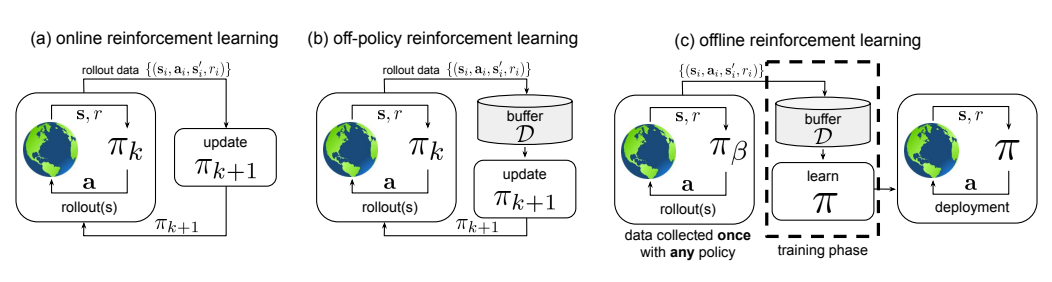
图1:在线、离策略、离线RL对比(出处:论文图1)
- 图(a)在线RL :智能体用当前策略πk\pi_kπk收集数据,然后用这些数据更新πk\pi_kπk得到πk+1\pi_{k+1}πk+1,循环往复。
大白话:边玩边学,学一点用一点,就像你上课边听边做笔记。 - 图(b)离策略RL :有个回放池DDD,里面存了所有历史策略π0\pi_0π0到πk\pi_kπk收集的数据,每次更新都从DDD里采样。
大白话:有个错题本,平时做题都记下来,复习的时候随便抽。但还是会不断往错题本里加新题。 - 图©离线RL :数据集DDD是一次性收集好的,训练过程中完全不跟环境交互,也不添加新数据。
大白话:给你一本历年高考真题,你就靠这本真题复习,然后直接上考场。
二、离线RL的数学基础与核心挑战
2.1 马尔可夫决策过程(MDP):RL的通用语言
所有RL问题都可以用马尔可夫决策过程来描述,定义为一个六元组:
M=(S,A,T,d0,r,γ)M=(S, A, T, d_0, r, \gamma)M=(S,A,T,d0,r,γ)
其中每个符号的含义:
- SSS:状态空间,所有可能的状态的集合。大白话:游戏里所有可能的画面。
- AAA:动作空间,智能体所有可能的动作的集合。大白话:游戏里所有可以按的按键。
- T(st+1∣st,at)T(s_{t+1}|s_t, a_t)T(st+1∣st,at):状态转移概率,在状态sts_tst执行动作ata_tat后,转移到状态st+1s_{t+1}st+1的概率。大白话:按了跳跃键后,角色跳起来的概率。
- d0(s0)d_0(s_0)d0(s0):初始状态分布,游戏开始时第一个状态的概率分布。大白话:游戏开局的初始画面。
- r(st,at)r(s_t, a_t)r(st,at):奖励函数,在状态sts_tst执行动作ata_tat得到的即时奖励。大白话:吃了金币加10分,撞了墙减100分。
- γ∈(0,1]\gamma \in (0,1]γ∈(0,1]:折扣因子,未来奖励的折扣系数。大白话:明天的1块钱不如今天的1块钱值钱,γ\gammaγ越大越看重长远利益。
RL的终极目标是学习一个策略π(at∣st)\pi(a_t|s_t)π(at∣st)(在状态sts_tst下选择动作ata_tat的概率分布),使得期望累积奖励最大:
J(π)=Eτ∼pπ(τ)∑t=0Hγtr(st,at)J(\pi)=\mathbb{E}{\tau \sim p{\pi}(\tau)}\left\\sum_{t=0}\^{H} \\gamma\^{t} r(s_t, a_t)\\rightJ(π)=Eτ∼pπ(τ)t=0∑Hγtr(st,at)
其中:
- τ=(s0,a0,...,sH,aH)\tau=(s_0,a_0,...,s_H,a_H)τ=(s0,a0,...,sH,aH):一条轨迹,也就是从开始到结束的一整局游戏。
- pπ(τ)p_{\pi}(\tau)pπ(τ):策略π\piπ产生的轨迹的概率分布。
- HHH:轨迹的最大长度,也就是一局游戏最多走多少步。
- E\mathbb{E}E:期望,也就是平均下来的累积奖励。
离线RL的问题定义 :给你一个固定的数据集D={(sti,ati,st+1i,rti)}D=\{(s_t^i,a_t^i,s_{t+1}^i,r_t^i)\}D={(sti,ati,st+1i,rti)},这些数据是由某个未知的行为策略πβ\pi_{\beta}πβ收集的,你只能用这个数据集来学习最优策略π∗\pi^*π∗,训练过程中完全不能跟环境交互。
2.2 离线RL的致命难题:分布偏移
离线RL看起来很美好,但为什么直到最近几年才火起来?因为它有一个几乎无解的核心挑战:分布偏移(Distribution Shift)。
大白话解释:训练数据是行为策略πβ\pi_{\beta}πβ产生的,而我们要学习的策略π\piπ跟πβ\pi_{\beta}πβ不一样,所以π\piπ会访问到一些πβ\pi_{\beta}πβ从来没去过的状态,在这些状态下,模型的预测完全不可靠。
论文里用了一个非常经典的行为克隆(BC)例子来说明这个问题的严重性:
- 定理2.1(行为克隆误差界) :如果用经验风险最小化训练BC,在训练分布上的泛化误差是ϵ\epsilonϵ,那么最终的误差界是O(H2ϵ)O(H^2\epsilon)O(H2ϵ),也就是跟时间步长的平方成正比。
- 定理2.2(DAgger误差界) :如果允许在线收集数据(也就是DAgger算法),误差界是O(Hϵ)O(H\epsilon)O(Hϵ),跟时间步长线性成正比。
这意味着什么?比如一个100步的任务,BC的误差会是DAgger的100倍!就像你学开车,教练只教了你在直路上怎么开。BC学完后,第一次遇到转弯,因为从来没见过,就瞎打方向盘,然后车就开到沟里去了,后面的所有步骤都错了。而DAgger会让教练在你开错的时候纠正你,所以误差不会累积。
但离线RL连DAgger都做不了,因为不能在线交互。更要命的是,Q-learning这类动态规划算法会主动 去选择那些Q值被高估的动作,也就是"捡漏",专门挑那些模型瞎猜出来的高Q值动作,导致误差越来越大,这就是论文里著名的"unlearning效应"。
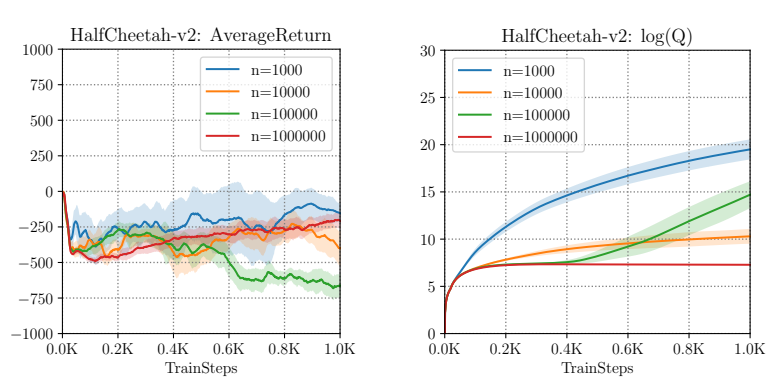
图2:SAC算法在离线设置下的unlearning效应(出处:论文图2)
- 左图:随着训练步数增加,实际回报先上升然后急剧下降
- 右图:Q值的对数随着训练步数不断上升
- 关键发现:即使把数据集从1000增加到100万,这个现象依然存在!
这说明什么?这不是过拟合! 过拟合是数据太少导致的,增加数据量会缓解。但unlearning效应是分布偏移导致的,不管你有多少数据,只要模型开始选择分布外的动作,Q值就会被高估,然后策略就崩了。
三、离线RL算法三大流派
为了解决分布偏移问题,研究者们提出了三大类算法,我们一个一个来讲。
3.1 基于重要性采样的方法:给数据加权
重要性采样的核心思想很朴素:既然数据是行为策略πβ\pi_{\beta}πβ收集的,那我们就给每条数据加一个权重,把它变成目标策略π\piπ下的期望。
最朴素的重要性采样估计器:
J(πθ)=Eτ∼πβ(τ)πθ(τ)πβ(τ)∑t=0Hγtr(s,a)J(\pi_{\theta})=\mathbb{E}{\tau \sim \pi{\beta}(\tau)}\left\\frac{\\pi_{\\theta}(\\tau)}{\\pi_{\\beta}(\\tau)} \\sum_{t=0}\^{H} \\gamma\^{t} r(s,a)\\rightJ(πθ)=Eτ∼πβ(τ)πβ(τ)πθ(τ)t=0∑Hγtr(s,a)
其中πθ(τ)πβ(τ)=∏t=0Hπθ(at∣st)πβ(at∣st)\frac{\pi_{\theta}(\tau)}{\pi_{\beta}(\tau)}=\prod_{t=0}^{H} \frac{\pi_{\theta}(a_t|s_t)}{\pi_{\beta}(a_t|s_t)}πβ(τ)πθ(τ)=∏t=0Hπβ(at∣st)πθ(at∣st)是轨迹的重要性权重,也就是目标策略产生这条轨迹的概率除以行为策略产生这条轨迹的概率。
但这个估计器有个致命的问题:方差太大! 因为重要性权重是乘积形式,100步的话就是100个分数相乘,只要有一步的权重很大,整个估计就会爆炸。
为了降低方差,人们提出了很多改进:
- 每决策重要性采样(PDIS):把未来步的权重去掉,因为t时刻的奖励只跟t时刻之前的动作有关
- 双重鲁棒估计器:结合了重要性采样和模型估计,只要其中一个是对的,整个估计就是无偏的
- 边际化重要性采样 :直接估计状态分布的比值ρπ(s)=dπ(s)dπβ(s)\rho^{\pi}(s)=\frac{d^{\pi}(s)}{d^{\pi_{\beta}(s)}}ρπ(s)=dπβ(s)dπ(s),而不是轨迹的比值,方差更小
但总的来说,基于重要性采样的方法在长轨迹、高维空间下表现都不好,因为方差问题始终解决不了。
3.2 基于动态规划的方法:目前的主流
这是目前离线RL最主流的方法,核心是学习Q值函数,然后用Q值函数来导出策略。
3.2.1 基础方法:FQI和LSPI
拟合Q迭代(FQI)是最基础的离线动态规划算法,步骤很简单:
- 初始化Q函数
- 用当前Q函数计算目标值y=r+γmaxa′Q(s′,a′)y=r+\gamma \max_{a'} Q(s',a')y=r+γmaxa′Q(s′,a′)
- 用监督学习拟合Q函数,使得Q(s,a)≈yQ(s,a) \approx yQ(s,a)≈y
- 重复步骤2-3直到收敛
最小二乘策略迭代(LSPI)是线性函数近似下的FQI,因为线性情况下可以直接解线性方程组,不用梯度下降。
但这些基础方法在深度神经网络下都会遇到前面说的unlearning效应,因为max操作会主动选择分布外的动作,导致Q值过估计。
3.2.2 策略约束方法:不要离行为策略太远
既然问题出在策略π\piπ跟πβ\pi_{\beta}πβ差太远,那我们就约束π\piπ不要离πβ\pi_{\beta}πβ太远!这就是策略约束方法的核心思想。
通用的策略约束目标:
πk+1←argmaxπEs∼DEa∼π(a∣s)\[Q\^k+1π(s,a)]s.t.D(π,πβ)≤ϵ\pi_{k+1} \leftarrow \arg\max_{\pi} \mathbb{E}{s \sim D}\left\\mathbb{E}_{a \\sim \\pi(a\|s)}\[\\hat{Q}_{k+1}\^{\\pi}(s,a)\right] \quad s.t. \quad D(\pi, \pi{\beta}) \leq \epsilonπk+1←argπmaxEs∼DEa∼π(a∣s)\[Q\^k+1π(s,a)]s.t.D(π,πβ)≤ϵ
其中D(π,πβ)D(\pi, \pi_{\beta})D(π,πβ)是两个分布之间的距离度量,常用的有:
- KL散度:DKL(π∣∣πβ)=Ea∼πlogπ(a∣s)πβ(a∣s)D_{KL}(\pi||\pi_{\beta})=\mathbb{E}_{a \sim \pi}\\log \\frac{\\pi(a\|s)}{\\pi_{\\beta}(a\|s)}DKL(π∣∣πβ)=Ea∼πlogπβ(a∣s)π(a∣s)
- 最大均值差异(MMD):基于核函数的分布距离度量
- Wasserstein距离:也叫推土机距离,衡量把一个分布变成另一个分布需要的最小代价
论文里用了一个非常有趣的1D线世界例子来说明不同约束的区别:
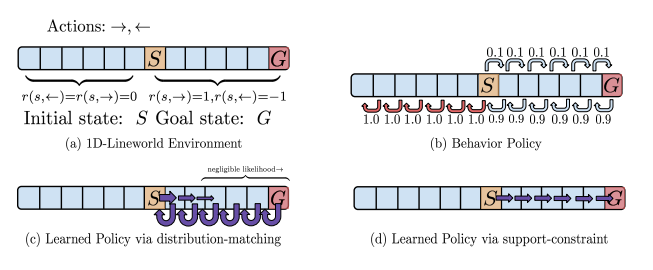
图3:1D线世界环境下的策略对比(出处:论文图3)
- 环境:从S出发,要走到G,只能左右走
- 行为策略:90%的概率往左走,10%的概率往右走
- 分布约束(KL散度):学到的策略还是大部分往左走,因为KL散度要求分布相似,所以永远到不了G
- 支持约束(MMD):学到的策略可以100%往右走,因为MMD只要求动作在行为策略的支持范围内,也就是只要行为策略曾经往右走过,不管概率多小,都可以选
这个例子完美说明了为什么KL散度有时候不好用,而MMD更适合离线RL。
3.2.3 保守Q学习(CQL):目前最流行的算法
CQL是目前最流行的离线RL算法之一,它的核心思想是直接正则化Q函数,让分布外动作的Q值尽可能低,分布内动作的Q值尽可能准。
CQL的损失函数:
E~(B,ϕ)=α⋅C(B,ϕ)+E(B,ϕ)\tilde{\mathcal{E}}(B, \phi)=\alpha \cdot \mathcal{C}(B, \phi) + \mathcal{E}(B, \phi)E~(B,ϕ)=α⋅C(B,ϕ)+E(B,ϕ)
其中:
- E(B,ϕ)\mathcal{E}(B, \phi)E(B,ϕ):标准的Bellman误差,也就是Q(s,a)−(r+γmaxa′Q(s′,a′))Q(s,a)-(r+\gamma \max_{a'} Q(s',a'))Q(s,a)−(r+γmaxa′Q(s′,a′))的平方和
- C(B,ϕ)\mathcal{C}(B, \phi)C(B,ϕ):保守正则项,最常用的是:
CCQL1(B,ϕ)=Es∼B,a∼μ(a∣s)Qϕ(s,a)−E(s,a)∼BQϕ(s,a)\mathcal{C}{CQL_1}(B, \phi)=\mathbb{E}{s \sim B,a \sim \mu(a|s)}Q_{\\phi}(s,a) - \mathbb{E}_{(s,a) \sim B}Q_{\\phi}(s,a)CCQL1(B,ϕ)=Es∼B,a∼μ(a∣s)Qϕ(s,a)−E(s,a)∼BQϕ(s,a)
其中μ(a∣s)∝exp(Q(s,a))\mu(a|s) \propto \exp(Q(s,a))μ(a∣s)∝exp(Q(s,a))是当前Q函数诱导的策略分布。
大白话解释:CQL做了两件事:
- 让所有可能被当前策略选择的动作的Q值尽可能低(第一项)
- 让数据集中出现过的动作的Q值尽可能准(第二项和Bellman误差)
这样一来,分布外的动作Q值会被压得很低,模型就不会去选它们了,完美解决了Q值过估计的问题。
核心代码:CQL的核心实现(PyTorch)
python
import torch
import torch.nn as nn
import torch.optim as optim
class QNetwork(nn.Module):
def __init__(self, state_dim, action_dim, hidden_dim=256):
super().__init__()
self.fc1 = nn.Linear(state_dim + action_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, hidden_dim)
self.fc3 = nn.Linear(hidden_dim, 1)
def forward(self, state, action):
x = torch.cat([state, action], dim=-1)
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
return self.fc3(x)
class CQLAgent:
def __init__(self, state_dim, action_dim, lr=3e-4, alpha=1.0, gamma=0.99):
# 双Q网络,缓解过估计
self.q1 = QNetwork(state_dim, action_dim)
self.q2 = QNetwork(state_dim, action_dim)
self.target_q1 = QNetwork(state_dim, action_dim)
self.target_q2 = QNetwork(state_dim, action_dim)
self.target_q1.load_state_dict(self.q1.state_dict())
self.target_q2.load_state_dict(self.q2.state_dict())
self.optimizer = optim.Adam(
list(self.q1.parameters()) + list(self.q2.parameters()),
lr=lr
)
self.alpha = alpha # 保守系数
self.gamma = gamma # 折扣因子
def update(self, batch):
state, action, reward, next_state, done = batch
# 计算目标Q值(用目标网络)
with torch.no_grad():
# 这里假设用确定性策略,实际可以用随机策略
next_action = torch.tanh(self.policy(next_state))
target_q1 = self.target_q1(next_state, next_action)
target_q2 = self.target_q2(next_state, next_action)
target_q = reward + (1 - done) * self.gamma * torch.min(target_q1, target_q2)
# 计算标准Bellman误差
current_q1 = self.q1(state, action)
current_q2 = self.q2(state, action)
bellman_loss = torch.mean((current_q1 - target_q)**2 + (current_q2 - target_q)**2)
# 计算CQL正则项(用随机动作采样估计)
random_actions = torch.rand_like(action) * 2 - 1 # 假设动作范围是[-1,1]
q1_random = self.q1(state, random_actions)
q2_random = self.q2(state, random_actions)
# logsumexp对应CQL1的第一项
cql1_q1 = torch.logsumexp(q1_random, dim=1) - current_q1
cql1_q2 = torch.logsumexp(q2_random, dim=1) - current_q2
cql_loss = torch.mean(cql1_q1 + cql1_q2)
# 总损失 = Bellman损失 + 保守正则项
total_loss = bellman_loss + self.alpha * cql_loss
# 反向传播优化
self.optimizer.zero_grad()
total_loss.backward()
self.optimizer.step()
# 软更新目标网络
self._update_target_networks()
return total_loss.item()
def _update_target_networks(self, tau=0.005):
# 软更新:目标网络 = tau * 主网络 + (1-tau) * 目标网络
for param, target_param in zip(self.q1.parameters(), self.target_q1.parameters()):
target_param.data.copy_(tau * param.data + (1 - tau) * target_param.data)
for param, target_param in zip(self.q2.parameters(), self.target_q2.parameters()):
target_param.data.copy_(tau * param.data + (1 - tau) * target_param.data)3.3 基于模型的方法:先学环境再做决策
基于模型的方法的核心思想是:先从数据中学一个环境模型Tψ(st+1∣st,at)T_{\psi}(s_{t+1}|s_t,a_t)Tψ(st+1∣st,at),然后用这个模型来生成虚拟数据,或者直接用模型来规划。
但基于模型的方法也有分布偏移的问题:策略会主动去选择那些模型预测错误的状态,也就是"利用模型的漏洞",导致在真实环境中表现很差。
为了解决这个问题,人们提出了保守模型基RL方法:
- MOPO:给奖励函数加一个惩罚项,惩罚模型不确定性高的状态
- MoREL:当模型不确定性太高时,进入一个吸收态,奖励为0
论文里提到,基于模型的方法在很多任务上表现很好,特别是当数据量比较大的时候,因为模型可以利用数据中的结构信息,泛化能力更强。
四、离线RL的应用与基准
4.1 基准数据集:D4RL
论文里介绍了D4RL基准库,这是目前离线RL最常用的基准,包含了各种任务的数据集:
- 机器人:HalfCheetah、Hopper、Walker2D等MuJoCo环境
- 导航:Maze2D
- 自动驾驶:CARLA
- 推荐系统:Adroit
- 医疗:MIMIC-IV
D4RL的数据集按照质量分为不同的等级:
- random:完全随机策略收集的数据
- medium:中等水平策略收集的数据
- expert:专家策略收集的数据
- mixed:混合了不同水平策略的数据
4.2 工业应用:离线RL已经在改变世界
论文里介绍了离线RL在多个领域的成功应用:
- 机器人:Google用50万次抓取数据训练视觉抓取策略,不用任何在线交互就能达到90%以上的抓取成功率
- 医疗:用MIMIC-III数据集训练败血症治疗策略,比人类医生的治疗方案降低了15%的死亡率
- 自动驾驶:用数百万公里的人类驾驶数据训练驾驶策略,避免了在线训练的危险
- 广告推荐:用用户点击日志训练推荐策略,提高了20%的点击率和转化率
- 对话系统 :用数十亿条人类对话日志训练对话策略,让机器人更会聊天
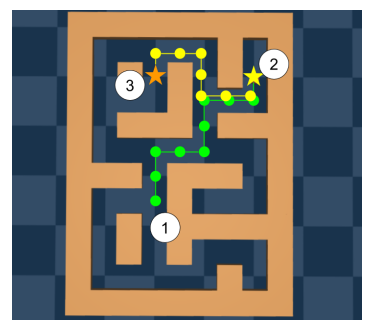
图4:离线RL利用轨迹的组合性(出处:论文图4)
这个图展示了离线RL最神奇的能力:组合性。如果数据集里有从1到2的轨迹,也有从2到3的轨迹,那么离线RL可以组合出从1到3的轨迹,也就是学会了数据里没有的更长的轨迹。这就是为什么离线RL可以比行为策略表现更好的原因。
五、未来展望与开放问题
虽然离线RL已经取得了很大的进展,但还有很多问题没有解决,论文最后讨论了几个最重要的开放问题:
- 更好的分布偏移处理:目前的方法都是约束策略不要离行为策略太远,但这限制了策略的提升空间,未来需要更好的方法来处理分布偏移
- 不确定性估计:更准确的不确定性估计是离线RL的关键,特别是在高维空间下
- 数据集质量:目前的数据集都是随便收集的,未来需要研究什么样的数据集最适合离线RL
- 离线预训练+在线微调:先用大量离线数据预训练一个通用策略,然后用少量在线数据微调,这可能是未来RL的主流范式
- 因果推理:离线RL本质上是一个反事实推理问题,结合因果推理的方法可能会带来突破
结语
离线RL正在把强化学习从一个"需要不断试错的熊孩子"变成一个"能从历史中学习的智者"。它让RL第一次有了大规模落地的可能,因为我们终于可以不用再担心交互的成本和危险了。
虽然离线RL还有很多问题没有解决,但它的前景是无限的。想象一下,未来我们可以用所有的历史数据来训练AI医生、AI司机、AI老师,让它们比人类更专业、更可靠。这就是离线RL的终极目标:把数据变成决策的力量。