从零实现Transformer:第 4 部分 - Residual Connection的两种实现 Pre-LN 和 Post-LN
flyfish
Pre-LN = Pre-Layer Normalization
Post-LN = Post-Layer Normalization
Pre = 预先、在前面
Post = 在后、在末尾
Layer Normalization = 层归一化
Pre-LN:前置层归一化
Post-LN:后置层归一化
Pre-LN vs Post-LN
符号定义
xxx:当前模块原始输入
LN(⋅)\text{LN}(\cdot)LN(⋅):层归一化
Sublayer(⋅)\text{Sublayer}(\cdot)Sublayer(⋅):子层(自注意力 / FFN前馈网络)
Dropout(⋅)\text{Dropout}(\cdot)Dropout(⋅):随机失活
+++:残差连接逐元素相加
Post-LN 公式(原始 Transformer)
y=LN( x+Dropout(Sublayer(x)) ) \boldsymbol{y = \text{LN}\Big(\ x + \text{Dropout}\big(\text{Sublayer}(x)\big)\ \Big)} y=LN( x+Dropout(Sublayer(x)) )
对应代码
python
return self.norm(x + self.dropout(sublayer(x)))Pre-LN 公式(现代大模型 GPT)
y=x+Dropout( Sublayer(LN(x)) ) \boldsymbol{y = x + \text{Dropout}\Big(\ \text{Sublayer}\big(\text{LN}(x)\big)\ \Big)} y=x+Dropout( Sublayer(LN(x)) )
对应代码
python
return x + self.dropout(sublayer(self.norm(x)))直接对比
| 类型 | 数学公式 | 关键位置 |
|---|---|---|
| Post-LN | y=LN(x+Dropout(Sublayer(x)))y = \boldsymbol{\text{LN}}\big(x + \text{Dropout}(\text{Sublayer}(x))\big)y=LN(x+Dropout(Sublayer(x))) | LN 在残差相加外面 |
| Pre-LN | y=x+Dropout(Sublayer(LN(x)))y = x + \text{Dropout}\big(\text{Sublayer}(\boldsymbol{\text{LN}}(x))\big)y=x+Dropout(Sublayer(LN(x))) | LN 在子层最里面 |
Post-LN :最后归一
Pre-LN:先归一
AI生成的Post-LN 和 Pre-LN
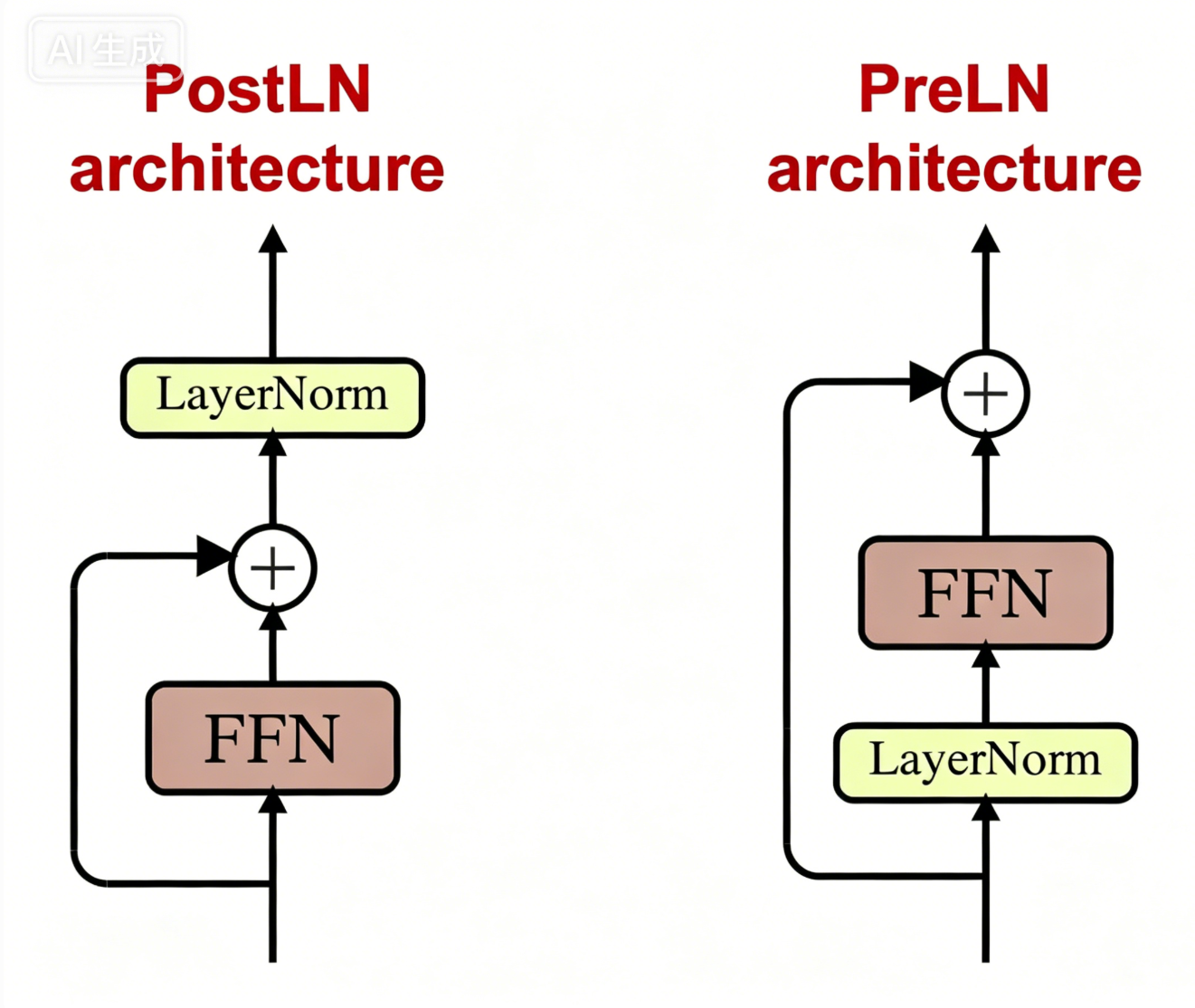
FFN(PositionwiseFeedForward,前馈网络)
cpp
import torch
import torch.nn as nn
# ===================== 公共模块 两者完全一致,无任何区别 =====================
class LayerNormalization(nn.Module):
"""层归一化"""
def __init__(self, features: int, eps: float = 1e-6):
super().__init__()
self.eps = eps
self.gamma = nn.Parameter(torch.ones(features))
self.beta = nn.Parameter(torch.zeros(features))
def forward(self, x: torch.Tensor):
mean = x.mean(dim=-1, keepdim=True)
var = ((x - mean) ** 2).mean(dim=-1, keepdim=True)
normalized = (x - mean) / torch.sqrt(var + self.eps)
return self.gamma * normalized + self.beta
class PositionwiseFeedForward(nn.Module):
"""Transformer前馈网络"""
def __init__(self, d_model: int, d_ff: int, dropout: float):
super().__init__()
self.linear_1 = nn.Linear(d_model, d_ff)
self.linear_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
self.activation = nn.ReLU()
def forward(self, x):
return self.linear_2(self.dropout(self.activation(self.linear_1(x))))
# ===================== 仅残差连接的 forward 函数不同! =====================
# 版本1:Post-LN(原始Transformer)
class ResidualConnection_PostLN(nn.Module):
def __init__(self, features: int, dropout: float):
super().__init__()
self.dropout = nn.Dropout(dropout)
self.norm = LayerNormalization(features)
def forward(self, x, sublayer):
# Post-LN 公式:LN(x + Dropout(Sublayer(x)))
return self.norm(x + self.dropout(sublayer(x)))
# 版本2:Pre-LN(现代大模型 GPT)
class ResidualConnection_PreLN(nn.Module):
def __init__(self, features: int, dropout: float):
super().__init__()
self.dropout = nn.Dropout(dropout)
self.norm = LayerNormalization(features)
def forward(self, x, sublayer):
# Pre-LN 公式:x + Dropout(Sublayer(LN(x)))
return x + self.dropout(sublayer(self.norm(x)))
# ===================== 【测试代码】验证两种结构 =====================
if __name__ == "__main__":
# 固定随机种子,保证结果可复现
torch.manual_seed(42)
# 超参数配置
d_model = 512 # 模型维度
d_ff = 2048 # 前馈网络中间维度
dropout = 0.1 # Dropout概率
# 构造输入:[batch_size, seq_len, d_model]
x = torch.randn(2, 10, d_model)
print(f"输入张量形状: {x.shape}")
# 初始化子层(前馈网络)
ffn = PositionwiseFeedForward(d_model, d_ff, dropout)
# 1. 测试 Post-LN 残差连接
post_ln = ResidualConnection_PostLN(d_model, dropout)
out_post = post_ln(x, ffn)
print(f"\nPost-LN 输出形状: {out_post.shape}")
# 2. 测试 Pre-LN 残差连接
pre_ln = ResidualConnection_PreLN(d_model, dropout)
out_pre = pre_ln(x, ffn)
print(f"\nPre-LN 输出形状: {out_pre.shape}")输出
cpp
输入张量形状: torch.Size([2, 10, 512])
Post-LN 输出形状: torch.Size([2, 10, 512])
Pre-LN 输出形状: torch.Size([2, 10, 512])