摘要
我们介绍了光流估计网络,称为FlowFormer,一种基于Transform的神经网络架构,用于学习光流。FlowFormer化由图像对构建的4D cost volume,将成本编码到一个新的潜在空间中具有交替组转换器(AGT)层的成本内存中,并通过一个带有动态位置成本查询的循环Transform解码器对位置 cost queries进行解码。在sinintel基准测试中,FlowFormer的平均终点误差(AEPE)分别为1.159和2.088,比已发布的最佳结果误差分别降低了16.5%和15.5%
我们的贡献可以概括为四个方面。
1)我们提出了一种新的基于Transform的神经网络结构FlowFormer,用于光流量估计,它实现了最先进的流量估计性能。
2)设计了一种新颖的cost volume编码器,有效地将成本信息聚合为紧凑的潜在cost tokens。
3)我们提出了一种循环成本解码器,该解码器通过动态位置成本查询循环解码成本特征,迭代细化估计光流。
4)据我们所知,我们第一次验证imagenet预先训练的传输
1 引言
光流旨在以二维位移场的形式,估算源图像与目标图像之间逐像素的对应关系。在许多下游视频任务中,如动作识别 45,36,60、视频修补 28,49,13、视频超分辨率 30,5,38 和帧插值 50,33,20,光流作为提供密集对应关系的基础组件,为预测提供了有价值的线索。
光流估计中采用的一般假设是:由光流诱导的两张图像中对应位置的表观特征保持不变。传统上,光流被建模为一个优化问题,旨在通过正则化项最大化跨图像对应位置之间的视觉相似度。随着深度学习的快速发展和训练数据的涌现,基于深度卷积神经网络的方法极大地推动了该领域的发展。最新的方法计算特征对之间的代价(即视觉相似度),并在此基础上回归光流。
大多数成功的网络架构设计是通过改进代价 (cost)的编码和解码来实现的。PWC-Net 42 和 RAFT 46 是两个近期的代表性深度学习方法 。PWC-Net 42 利用扭曲特征构建分层局部代价体,并从这些局部代价中逐步估计光流。RAFT 46 构建了一个 H×W×H×WH \times W \times H \times WH×W×H×W 的四维代价体,用于测量 H×WH \times WH×W 图像对中所有像素对之间的相似度,并通过在局部窗口内迭代检索局部代价来回归光流残差。
最近,Transformer 因其建模长距离关系的能力而备受关注,这有助于光流估计。Perceiver IO 24 是开创性的工作,它使用基于 Transformer 的架构学习光流回归。然而,它直接处理图像对的像素,忽略了将视觉相似度编码为代价以用于光流估计这一成熟的领域知识。因此,它需要大量的参数和约 80 倍的训练样本来捕捉所需的输入-输出映射。因此,我们提出一个问题:我们能否同时享受 Transformer 的优势和之前里程碑式工作中代价体的优势?这一问题要求为光流估计设计新的 Transformer 架构,以有效聚合来自代价体的信息。在本文中,我们引入了新颖的光流 Transformer(FlowFormer)来解决这一具有挑战性的问题。
FlowFormer 采用编码器-解码器架构进行代价体的编码和解码。在构建四维代价体之后,FlowFormer 包含两个主要组件:1) 代价体编码器,将四维代价体嵌入到潜在代价空间,并完全编码该空间中的代价信息;2) 循环代价解码器,从编码后的潜在代价特征中估计光流。与以前的工作相比,我们的 FlowFormer 的主要特点是适配 Transformer 架构以有效处理代价体,代价体是紧凑且信息丰富的表示,已在光流估计社区中得到广泛探索,用于估计精确的光流。
使用 Transformer 转换四维代价体的朴素策略是直接对四维代价体进行标记化并应用 Transformer。然而,这种策略需要使用数千个标记,计算负担过重。为了解决这一挑战,我们在代价编码器中提出了两项关键设计。我们提出了一种两步标记化策略:1) 将四维代价体中的每个二维代价图(记录了一个源像素与所有目标像素之间的视觉相似度)像 Transformer 网络中常见的那样,转换为图像块(patches);2) 进一步将每个代价图的代价块投影为 KKK 个潜在代价标记。通过这种方式,H×W×H×WH \times W \times H \times WH×W×H×W 的四维代价体可以被转换为 H×W×KH \times W \times KH×W×K 个标记。其次,我们不在所有标记之间执行自注意力机制,而是在同一代价图内的标记以及不同代价图之间的标记上交替执行注意力机制。换句话说,这是一种对属于同一源像素的潜在代价标记以及跨不同源像素的标记进行聚合的交织堆叠结构。结合这两项设计,FlowFormer 将代价体编码为紧凑且具有全局感知能力的潜在代价标记,称为"代价记忆"(cost memory)。
经典的 Transformer 架构(如 DETR 4)通过堆叠的交叉注意力层从编码后的记忆中解码信息。与它们不同,受 RAFT 启发,我们的代价解码器仅采用一个循环注意力层,将代价解码 formulate 为具有动态位置代价查询的循环查询过程:基于当前估计的光流,我们查询代价记忆以回归光流残差。在每次迭代中,我们根据当前光流计算所有源像素在目标图像中的对应位置,然后用这些位置动态更新位置代价查询。随后,我们通过交叉注意力从代价记忆中获取代价特征,并使用共享的门控循环单元(GRU)头进行残差光流回归。此外,RAFT 仅使用浅层 CNN 作为图像特征编码器。我们发现,我们的 FlowFormer 受益于使用 ImageNet 预训练的 Transformer 骨干网络。
我们的贡献可总结为四个方面:1) 我们提出了一种新颖的基于 Transformer 的神经网络架构 FlowFormer,用于光流估计,达到了最先进(SOTA)的光流估计性能。2) 我们设计了一种新颖的代价体编码器,有效将代价信息聚合为紧凑的潜在代价标记。3) 我们提出了一种循环代价解码器,通过具有动态位置代价查询的循环方式解码代价特征,以迭代细化估计的光流。4) 据我们所知,我们首次验证了 ImageNet 预训练的 Transformer 能够受益于光流估计。
2 相关工作
光流。传统上,光流被建模为最大化图像对之间视觉相似度并带有正则化的优化问题 17,1,2,40。该时期的主要改进来自于对相似度和正则化项的更好设计。深度神经网络的兴起极大地推动了该领域的发展。FlowNet 12 是第一个用于光流估计的端到端卷积网络。其后续工作 FlowNet2.0 23 采用了带有扭曲操作的堆叠架构,性能与最先进(SOTA)方法相当。随后,一系列工作,以 SpyNet 37、PWC-Net 42,43、LiteFlowNet 21,22 和 VCN 53 为代表,采用了从粗到细和迭代估计的方法论。这些模型在粗略阶段不可避免地存在丢失小尺度快速运动物体的问题。为了缓解这一问题,Teed 和 Deng 46 提出了 RAFT 46,它以粗-细(即每次迭代中的多尺度搜索窗口)和循环的方式执行光流估计。基于 RAFT 架构,许多工作 25,48,26,57,16 被提出,旨在降低计算成本或提高光流精度。最近,光流被扩展到更具挑战性的设置,如低光照 61、雾天 52 和光照变化 18。
在这些探索中,视觉相似度是通过卷积神经网络编码的高维特征的相关性来计算的,包含像素对视觉相似度的代价体作为支持光流估计的核心组件。然而,它们对代价信息的利用缺乏有效性。我们提出了 FlowFormer,它通过 Transformer 47 在潜在空间中聚合代价体。Perceiver IO 24 开创性地使用了 Transformer 47,11,4,能够在光流中建立长距离关系,并达到了最先进的性能。它忽略了代价体,显示了 Transformer 架构强大的表达能力,但代价是训练样本增加了约 80 倍。相比之下,我们提议将代价体保持为紧凑的相似度表示,并通过 Transformer 架构全局聚合相似度信息,从而将搜索空间推向极致。这种全局编码操作在大位移和遮挡的困难案例中尤其有益。
计算机视觉中的 Transformer。Transformer 在自然语言处理中取得了巨大成功 47,9,10,这激发了用于图像分类的自注意力机制的发展 34,11,8。此后,基于 Transformer 的架构被引入到许多其他视觉任务中,如检测 4、点云处理 15,58、图像修复 6,31、视频修补 56,32、视觉 grounding 54 等,并在大多数任务中达到了最先进水平。引人注目的性能通常归功于其长距离建模能力,这也是光流估计所期望的特性。视觉 Transformer 面临的挑战之一是视觉标记数量庞大,因为计算成本随标记数量呈二次方增长。Twins 8 提出了一种空间可分离自注意力(SS Self-Attention)层,用于在排列在二维平面上的标记之间传播信息。我们也在代价体编码器中采用 SS 自注意力,以在跨代价图之间传播信息。Perceiver IO 24 提出了一种通用的 Transformer 骨干网络,尽管需要大量参数,但达到了最先进的光流性能。视觉对应任务 44,19,7,27,51 是计算机视觉的主流。最近,Transformer 也引领了此类任务 39,44,7,27 的趋势,这与我们
方法
光流估计任务要求输出一个逐像素的位移场 f : R² → R²,该位移场将源图像 I_s 中每一个二维位置 x ∈ R² 映射到目标图像 I_t 中对应的二维位置 p = x + f(x)。为了充分利用近期的视觉 Transformer 架构以及此前基于 CNN 的光流估计方法中广泛使用的四维代价体,我们提出了 FlowFormer,这是一种基于 Transformer 的架构,通过对四维代价体进行编码和解码,以实现精确的光流估计。如图 1 所示,我们展示了 FlowFormer 的整体架构,该架构通过两个主要组件处理来自孪生特征的四维代价体:1)一个代价体编码器,将四维代价体编码到潜在空间以形成代价记忆;2)一个代价记忆解码器,基于编码后的代价记忆和上下文特征来预测逐像素的位移场。
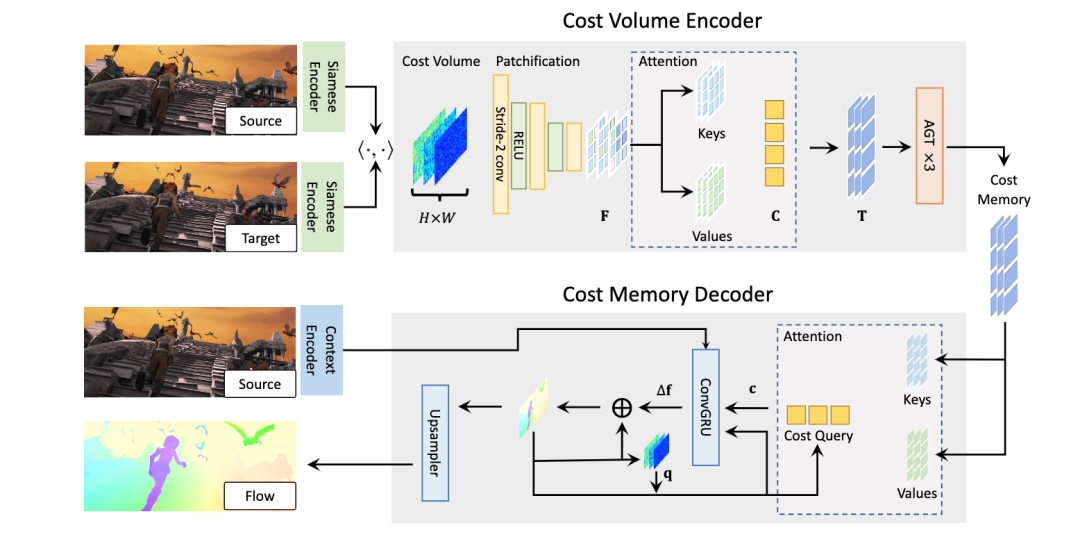
图1 FlowFormer的体系结构。FlowFormer通过三个步骤估算光流量:1)根据图像特征构建4Dcost volume。2)成本卷编码器,将成本卷编码到成本内存中。3)循环Transform解码器,将具有源图像上下文特征的代价内存解码为流
3.1 构建4D代价体积
使用骨干视觉网络从输入的 HI×WI×3H_I \times W_I \times 3HI×WI×3 RGB图像中提取 H×W×DfH \times W \times D_fH×W×Df 的特征图,通常设置 (H,W)=(HI/8,WI/8)(H, W) = (H_I/8, W_I/8)(H,W)=(HI/8,WI/8)。在提取源图像和目标图像的特征图后,我们通过计算源图像和目标图像特征图中所有像素对之间的点积相似度,构建一个 H×W×H×WH \times W \times H \times WH×W×H×W 的4D代价体积。
3.2 代价体积编码器
为了估计光流,需要基于编码在4D代价体积中的源-目标视觉相似度,确定源像素在目标图像中的对应位置。所构建的4D代价体积可以被视为一系列大小为 H×WH \times WH×W 的2D代价图,每个代价图测量单个源像素与所有目标像素之间的视觉相似度。我们将源像素 xxx 的代价图记为 Mx∈RH×WM_x \in \mathbb{R}^{H \times W}Mx∈RH×W。在如此复杂的代价图中寻找对应位置通常具有挑战性,因为两幅图像中可能存在重复模式和非判别性区域。当仅考虑图局部窗口内的代价时(如先前的基于CNN的光流估计方法所做的那样),任务变得更加具有挑战性。即使仅估计单个源像素的准确位移,考虑其上下文源像素的代价图也是有益的。
为了解决这一具有挑战性的问题,我们提出了一种基于Transformer的代价体积编码器,将整个代价体积编码为代价内存。我们的代价体积编码器包含三个步骤:1) 代价图分块,2) 代价块令牌嵌入,以及 3) 代价内存编码。以下详细阐述这三个步骤的细节。
代价图分块。 遵循现有的视觉Transformer方法,我们使用步长卷积对每个源像素 xxx 的代价图 Mx∈RH×WM_x \in \mathbb{R}^{H \times W}Mx∈RH×W 进行分块,以获得一系列代价块嵌入。具体而言,给定一个 H×WH \times WH×W 的代价图,我们首先在其右侧和底部填充零,使其宽度和高度成为8的倍数。然后,通过三层步长为2的卷积堆栈(后接ReLU激活函数)将填充后的代价图转换为特征图 Fx∈R⌈H/8⌉×⌈W/8⌉×DpF_x \in \mathbb{R}^{\lceil H/8 \rceil \times \lceil W/8 \rceil \times D_p}Fx∈R⌈H/8⌉×⌈W/8⌉×Dp。特征图中的每个特征对应输入代价图中的一个 8×88 \times 88×8 块。这三个卷积层的输出通道数分别为 Dp/4,Dp/2,DpD_p/4, D_p/2, D_pDp/4,Dp/2,Dp。
通过潜在摘要进行块特征标记化。 虽然分块为每个源像素产生了一系列代价块特征向量,但此类块特征的数量仍然很大,阻碍了不同源像素之间信息传播的效率。实际上,代价图具有高度冗余性,因为只有少数高代价最具信息量。为了获得更紧凑的代价特征,我们进一步通过 KKK 个潜在码字 C∈RK×DC \in \mathbb{R}^{K \times D}C∈RK×D 对每个源像素 xxx 的块特征 FxF_xFx 进行摘要总结。具体而言,潜在码字通过点积注意力机制查询每个源像素的代价块特征,将每个代价图进一步摘要为 KKK 个维度为 DDD 的潜在向量。潜在码字 C∈RK×DC \in \mathbb{R}^{K \times D}C∈RK×D 随机初始化,通过反向传播更新,并在所有源像素间共享。用于摘要 FxF_xFx 的潜在表示 TxT_xTx 如下获得:
Kx=Conv1×1(Concat(Fx,PE)),Vx=Conv1×1(Concat(Fx,PE)),Tx=Attention(C,Kx,Vx).(1) \begin{aligned} K_x &= \text{Conv}{1 \times 1}(\text{Concat}(F_x, PE)), \\ V_x &= \text{Conv}{1 \times 1}(\text{Concat}(F_x, PE)), \\ T_x &= \text{Attention}(C, K_x, V_x). \end{aligned} \quad (1) KxVxTx=Conv1×1(Concat(Fx,PE)),=Conv1×1(Concat(Fx,PE)),=Attention(C,Kx,Vx).(1)
在将代价块特征 FxF_xFx 投影以获得键 KxK_xKx 和值 VxV_xVx 之前,将块特征与位置嵌入序列 PE∈R⌈H/8⌉×⌈W/8⌉×DpPE \in \mathbb{R}^{\lceil H/8 \rceil \times \lceil W/8 \rceil \times D_p}PE∈R⌈H/8⌉×⌈W/8⌉×Dp 进行拼接。给定一个2D位置 ppp,我们根据COTR 27 将其编码为长度为 DpD_pDp 的位置嵌入。最后,通过对查询、键和值执行多头点积注意力,源像素 xxx 的代价图可以被摘要为 KKK 个潜在表示 Tx∈RK×DT_x \in \mathbb{R}^{K \times D}Tx∈RK×D。
通常,K×D≪H×WK \times D \ll H \times WK×D≪H×W,因此对于每个源像素 xxx,潜在摘要 TxT_xTx 提供了比每个 H×WH \times WH×W 代价图更紧凑的表示。对于图像中的所有源像素,总共有 (H×W)(H \times W)(H×W) 个2D代价图。它们的摘要表示因此可以转换为潜在4D代价体积 T∈RH×W×K×DT \in \mathbb{R}^{H \times W \times K \times D}T∈RH×W×K×D。
潜在代价空间中的注意力。 上述两个阶段将原始4D代价体积转换为潜在且紧凑的4D代价体积 TTT。然而,直接对4D体积中的所有向量应用自注意力仍然过于昂贵,因为计算成本随令牌数量呈二次方增长。如图2所示,我们提出了一种交替组Transformer层( alternate-group , AGT),它以两种相互正交的方式对令牌进行分组,并交替应用两种组内的注意力,从而降低了注意力成本,同时仍能实现所有令牌之间的信息传播。
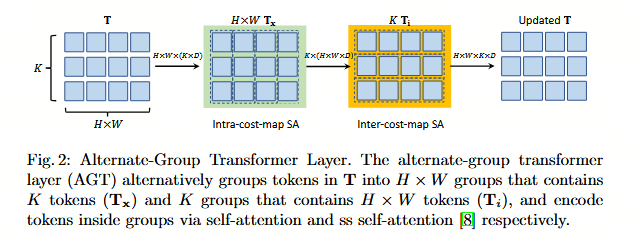
(图2说明:交替组Transformer层。交替组Transformer层(AGT)交替地将T中的令牌分组为包含K个令牌(TxT_xTx)的H×WH \times WH×W组和包含H×WH \times WH×W个令牌(TiT_iTi)的K组,并分别通过自注意力和SS自注意力8编码组内的令牌。)
第一种分组针对每个源像素进行,即每个 Tx∈RK×DT_x \in \mathbb{R}^{K \times D}Tx∈RK×D 形成一个组,并在每个组内进行自注意力操作:
Tx=FFN(Self-Attention(Tx(1),...,Tx(K)))对于所有 x∈Is,(2) T_x = \text{FFN}(\text{Self-Attention}(T_x^{(1)}, \dots, T_x^{(K)})) \quad \text{对于所有 } x \in I_s, \quad (2) Tx=FFN(Self-Attention(Tx(1),...,Tx(K)))对于所有 x∈Is,(2)
其中 Tx(i)T_x^{(i)}Tx(i) 表示编码源像素 xxx 代价图的第 iii 个潜在表示。在对每个源像素 xxx 的所有 KKK 个潜在令牌执行自注意力之后,更新后的 TxT_xTx 进一步通过前馈网络(FFN)变换,然后重新组织以形成更新后的4D代价体积 TTT。自注意力和FFN子层均采用Transformer中常见的残差连接和层归一化设计。这种自注意力操作传播了每个代价图内部的信息,我们将其称为代价图内自注意力(intra-cost-map self-attention)。
第二种方式将所有潜在代价令牌 T∈RH×W×K×DT \in \mathbb{R}^{H \times W \times K \times D}T∈RH×W×K×D 根据 KKK 个不同的潜在表示分组为 KKK 个组。因此,每个组将在空间域通过 Twins 8 中提出的空间可分离自注意力(SS-Self-Attention)拥有维度为 DDD 的 (H×W)(H \times W)(H×W) 个令牌以进行信息传播:
Ti=FFN(SS-SelfAttention(Ti))对于 i=1,2,...,K,(3) T_i = \text{FFN}(\text{SS-SelfAttention}(T_i)) \quad \text{对于 } i = 1, 2, \dots, K, \quad (3) Ti=FFN(SS-SelfAttention(Ti))对于 i=1,2,...,K,(3)
此处我们稍微滥用符号表示,将 Ti∈R(H×W)×DT_i \in \mathbb{R}^{(H \times W) \times D}Ti∈R(H×W)×D 表示为第 iii 组。更新后的 TiT_iTi 随后重新组织以获得更新后的4D潜在代价体积 TTT。此外,视觉相似的源像素应具有相干的光流,这已被先前的方法 25, 7 所验证。因此,我们在生成查询和键时,通过将源图像的上下文特征 ttt 与代价令牌拼接,将不同源像素之间的外观亲和度整合到 SS-SelfAttention 中。我们称该层为代价图间自注意力层,因为它在不同源像素之间传播代价体积的信息。注意,这些操作与 CATs 7 不同,后者增强了代价图"层级内"的相关性以及"层级间"的多级相关性。
上述自注意力操作的参数在不同的组之间共享,并顺序运行以形成提出的交替组注意力层。通过多次堆叠交替组Transformer层,潜在代价令牌可以有效地在源像素之间以及潜在表示之间交换信息,从而更好地编码4D代价体积。通过这种方式,我们的代价体积编码器将 H×W×H×WH \times W \times H \times WH×W×H×W 的4D代价体积转换为长度为 DDD 的 H×W×KH \times W \times KH×W×K 潜在令牌。我们将最终的 H×W×KH \times W \times KH×W×K 令牌称为代价内存,用于解码以估计光流。
3.3 用于光流估计的代价内存解码器
给定由代价体积编码器编码的代价内存,我们提出了一个代价内存解码器来预测光流。由于输入图像的原始分辨率为 HI×WIH_I \times W_IHI×WI,我们在 H×WH \times WH×W 的分辨率下估计光流,然后使用可学习的凸上采样器 46 将预测的光流上采样到原始分辨率。然而,与寻求抽象语义特征的先前视觉Transformer不同,光流估计需要从代价内存中恢复密集对应关系。受 RAFT 46 的启发,我们提出使用代价查询从代价内存中检索代价特征,并通过递归注意力解码器层迭代细化光流预测。
代价内存聚合。 为了预测 H×WH \times WH×W 个源像素的光流,我们生成一系列 (H×W)(H \times W)(H×W) 个代价查询,每个查询负责通过对代价内存执行共同注意力来估计单个源像素的光流。为了生成源像素 xxx 的代价查询 QxQ_xQx,我们首先根据其当前估计的光流 f(x)f(x)f(x) 计算其在目标图像中的对应位置 p=x+f(x)p = x + f(x)p=x+f(x)。然后,通过裁剪代价图 MxM_xMx 上以 ppp 为中心的 9×99 \times 99×9 局部窗口内的代价,检索局部 9×99 \times 99×9 代价图块 qx=Crop9×9(Mx,p)q_x = \text{Crop}_{9 \times 9}(M_x, p)qx=Crop9×9(Mx,p)。代价查询 QxQ_xQx 随后基于编码自局部代价 qxq_xqx 和 ppp 的位置嵌入 PE(p)PE(p)PE(p) 的特征 FFN(qx)\text{FFN}(q_x)FFN(qx) 进行制定,该特征可以通过交叉注意力从源像素 xxx 的代价内存 TxT_xTx 中聚合信息:
Qx=FFN(FFN(qx)+PE(p)),Kx=FFN(Tx),Vx=FFN(Tx),cx=Attention(Qx,Kx,Vx).(4) \begin{aligned} Q_x &= \text{FFN}(\text{FFN}(q_x) + PE(p)), \\ K_x &= \text{FFN}(T_x), \quad V_x = \text{FFN}(T_x), \\ c_x &= \text{Attention}(Q_x, K_x, V_x). \end{aligned} \quad (4) QxKxcx=FFN(FFN(qx)+PE(p)),=FFN(Tx),Vx=FFN(Tx),=Attention(Qx,Kx,Vx).(4)
交叉注意力总结了来自代价内存的每个源像素的信息以预测其光流。由于 QxQ_xQx 是根据每次迭代的馈送位置动态更新的,我们称之为动态位置代价查询。我们注意到,键和值可以在开始时生成并在后续迭代中重复使用,这节省了计算量,这也是我们递归解码器的优势。
递归光流预测。 我们的代价解码器迭代回归光流残差 Δf(x)\Delta f(x)Δf(x),以细化每个源像素 xxx 的光流,即 f(x)←f(x)+Δf(x)f(x) \leftarrow f(x) + \Delta f(x)f(x)←f(x)+Δf(x)。我们采用 ConvGRU 模块,并遵循与 GMA-RAFT 25 类似的设计用于光流细化。然而,我们递归模块的关键区别在于使用代价查询从代价内存中自适应地聚合信息,以实现更准确的光流估计。具体而言,在每次迭代中,ConvGRU 单元以检索到的代价特征和代价图块拼接 Concat(cx,qx)\text{Concat}(c_x, q_x)Concat(cx,qx)、来自上下文网络的源图像上下文特征 txt_xtx 以及当前估计的光流 fff 作为输入,并按如下方式输出预测的光流残差:
Δf(x)=ConvGRU(Concat(cx,qx),tx,f(x)).(5) \Delta f(x) = \text{ConvGRU}(\text{Concat}(c_x, q_x), t_x, f(x)). \quad (5) Δf(x)=ConvGRU(Concat(cx,qx),tx,f(x)).(5)
每次迭代生成的光流通过凸上采样器上采样到源图像的大小 46,并在所有递归迭代中使用逐渐增加的权重由真实光流进行监督。
5 结论
我们提出了 FlowFormer,一种用于光流估计的基于 Transformer 的架构。FlowFormer 将一对图像构建的 H×W×H×W 四维代价体概括为 H×W×K 个长度为 D 的 token,随后通过交替组 Transformer(AGT)对这些代价 token 进行高效且有效的编码。得益于这种设计,生成的代价内存能够从代价体中捕捉关键信息,并获得紧凑的代价特征。最后,代价内存解码器利用动态位置代价查询,从代价内存中吸收代价信息,从而摆脱了局部窗口的限制,以进行残差光流回归。据我们所知,FlowFormer 是首个将 Transformer 与代价体深度整合用于光流估计的方法。借助紧凑的代价 token 以及 Transformer 的长程关系建模能力,FlowFormer 达到了最先进的精度,并展现出强大的跨数据集泛化能力。