整体架构图如下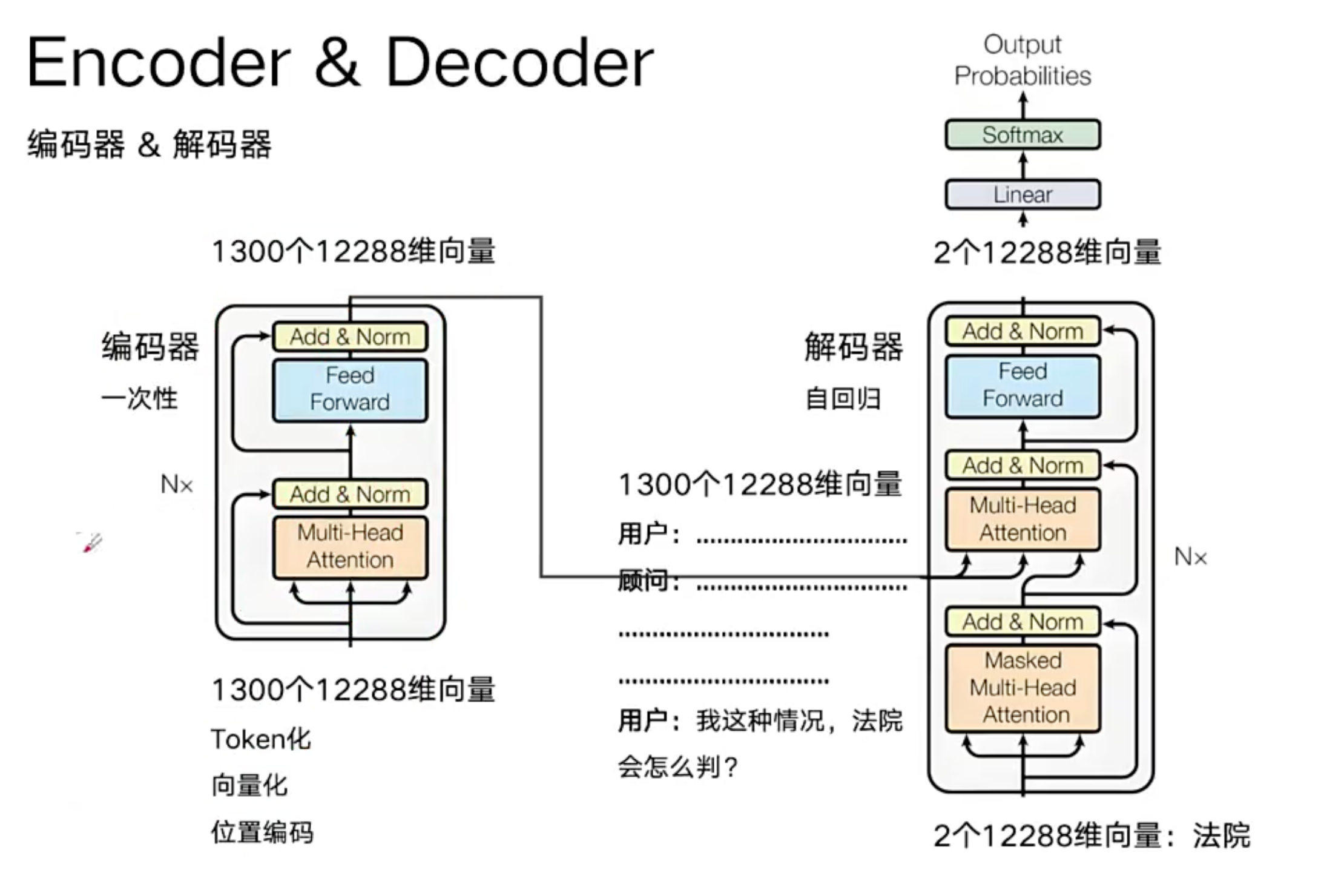
一、Transformer是什么?
Transformer 是 Google 在 2017 年论文:
Attention Is All You Need
提出的深度学习架构。
核心思想:
不再使用 RNN/LSTM 的顺序计算,而是通过 Attention 机制一次性关注整个序列。
整体流程为:输入 - 转为token - 向量化 - 位置编码 - decoder ,最后一个- liner(点乘) - softmax(归一化)- 输出几万个概率
二、为什么Transformer会出现?
在 Transformer 之前:
RNN
↓
LSTM
↓
GRU存在问题:
1. 无法并行
例如:
我
↓
喜欢
↓
学习
↓
AI必须一个一个计算。
2. 长距离依赖差
例如:
小明去了北京旅游,
......
三天后他回来了。模型很难关联:
他
↓
小明Transformer解决方案:
所有Token同时计算通过 Attention:
任意Token
↓
关注
↓
任意Token三、Transformer整体结构
图里的结构:
Input
↓
Encoder
↓
Decoder
↓
Output四、Encoder(编码器)
整体工作原理为,比如输入1300个token
input【0】 = Embedding【0】+ Position【0】
...
input【1299】 = Embedding【1299】+ Position【1299】
产生1300个向量
围绕着中心主题次,1300个向量分别与其他向量 聚合 产生新的 1300个向量
然后做多轮组合,GPT3 是96轮,目前最新的模型已经是100多轮了
作用:
理解输入内容。
例如:
用户输入:
我这种情况,法院会怎么判?首先:
Tokenization
变成:
我
这种
情况
法院
会
怎么
判Embedding
每个词变成向量:
我
↓
[0.12,0.55...]
法院
↓
[0.77,0.88...]Position Encoding
因为:
Attention不知道顺序。
所以加:
位置编码告诉模型:
谁在前
谁在后Multi-Head Attention
这是 Encoder 最核心部分。
例如:
我这种情况
法院会怎么判模型会自动发现:
法院
↓
关注
↓
判关系。
Feed Forward
进一步提取特征。
Add & Norm
做:
残差连接
+
LayerNorm保证训练稳定。
整个 Encoder:
Attention
↓
FFN
↓
Attention
↓
FFN重复 N 层。
图中的:
Nx就是这个意思。
五、Decoder(解码器)
现在已经延伸为decoder-only(就是不需要编码器的输入)
大概意思是可以举例为:
输入提示词比如1300个,第一轮后,1300+1个token,然后再进行下一轮
输出后的最后一个,代表所有的回复
右边部分。
作用:
生成文本。
例如:
输入:
法院会怎么判生成:
法院
↓
会
↓
根据
↓
具体
↓
情况一个字一个字输出。
所以图里写:
自回归就是:
预测下一个Token六、为什么有两个Attention?
说起注意力机制的话,就会产生疑问什么是注意力机制?
注意力机制就是把注意力放在重要的事情上
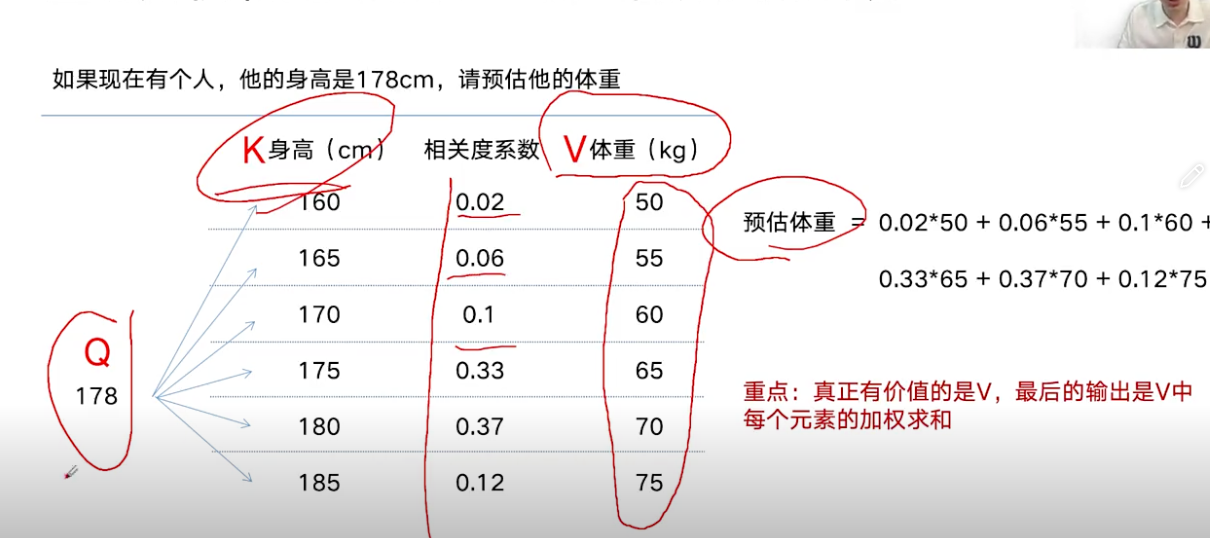
QKV:核心是用Q和K去计算相关度系数,计算方式为点乘然后再softmax(归一化)
第一层
Decoder里面有:Masked Attention
图中:
Masked Multi-Head Attention作用:
不能偷看未来。
例如:
我 爱 学习 AI预测:
学习不能看到:
AI所以:
Mask未来内容。
这样做的好处就是,可以省下一半算力,比如原来是输入1300个token,那么整体计算是1300的平方,加了掩码后,可以为1300的平方 除以2
第二层
Cross Attention
图中:
Multi-Head Attention作用:
看 Encoder 输出。
例如:
用户:
我这种情况法院会怎么判生成回答时:
当前Token
↓
关注
↓
用户输入七、Attention核心原理
Transformer灵魂。
公式:
Attention(Q,K,V)=softmax(QKTdk)VAttention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})VAttention(Q,K,V)=softmax(dkQKT)V
Q:
我要找什么K:
我是什么V:
我的内容过程:
Q × K计算相关性。
softmax通过归一化变成权重。
再:
权重 × V得到结果。
KV Cache
KV Cache 是一种以内存换速度 的优化技术,主要用于自回归生成任务(如 GPT、LLaMA 生成文本)。
1. 核心问题:为什么要用 KV Cache?
自回归生成时,模型每次只生成 1 个新 token ,但生成时需要看到所有之前 token 的上下文。
如果不做缓存,每生成一个新 token,模型都会重新计算之前所有 token 的 Key 和 Value,导致计算量随生成长度线性增长(O(n²) 复杂度)。
2. 直观理解
假设你已经生成了句子:"今天 天气 真好",现在要生成下一个词。
-
Attention 机制:新 token 需要和所有之前的 token(今天、天气、真好)计算注意力。
-
Key/Value:每个 token 在 attention 中对应的 K、V 向量。
-
关键观察 :
之前 token 的 K、V 在生成下一个 token 时不会改变(因为它们的 token 内容不变,模型参数也固定)。
因此,我们可以:
-
生成第一个 token 时,计算并缓存所有 token 的 K、V。
-
生成第二个 token 时,只需计算新 token 的 K、V,并复用之前缓存的 K、V。
-
依次类推。
3. KV Cache 工作原理
没有 KV Cache:
- 每步计算所有历史 token 的 K、V → 大量重复计算。
有 KV Cache:
-
维护一个缓存,存储已生成 token 的 K、V。
-
每步:
-
只计算当前新 token 的 Q、K、V。
-
将新 token 的 K、V 追加到缓存中。
-
用当前 Q + 缓存的全部 K、V 计算 attention。
-
4. 效果对比
| 方式 | 计算复杂度 | 内存占用 |
|---|---|---|
| 无 Cache | O(n²) | 较低 |
| 有 Cache | O(n) | 较高(存储所有历史 K、V) |
生成长序列(如 2048 tokens)时,KV Cache 能带来 10~100 倍 的速度提升。
5. 代价
-
显存消耗 :
缓存大小 =
batch_size × seq_len × num_heads × head_dim × 2(K 和 V)例如:LLaMA-7B (32 heads, 128 dim, 2048 tokens) 约 1GB 显存。
-
实现复杂度:需要管理不同 batch 中不同序列的缓存。
八、Encoder和Decoder分别对应什么模型?
这是面试高频。
Encoder一般用来做分析
Decoder一般用来做回答
BERT
只保留 Encoder
Input
↓
Encoder适合:
分类
检索
EmbeddingGPT
只保留 Decoder
Input
↓
Decoder适合:
文本生成
聊天
AgentT5
保留完整结构
Encoder
+
Decoder适合:
翻译
摘要
问答九、为什么GPT最终赢了?
因为 GPT 的目标:
预测下一个Token天然适合:
生成而:
聊天
Agent
代码生成本质都是:
Next Token Prediction面试版回答(2分钟)
Transformer 是 Google 在 2017 年提出的基于 Attention 的深度学习架构,用来解决 RNN 无法并行训练和长距离依赖的问题。其核心由 Encoder 和 Decoder 组成,Encoder 负责理解输入,Decoder 负责生成输出。每层主要包含 Multi-Head Attention、Feed Forward、残差连接和 LayerNorm。Attention 通过 Q、K、V 机制计算不同 Token 之间的关联关系,使模型能够关注整个上下文。后来 BERT 保留 Encoder 用于理解任务,GPT 保留 Decoder 用于生成任务,目前主流大模型如 GPT、Qwen、DeepSeek 都属于 Decoder Only 架构。