
目录:
- [1.具身智能:VLA模型与World Action Model齐头并进](#1.[具身智能]:VLA模型与World Action Model齐头并进)
- [2. 多模态思考与推理成为大模型发展的新方向](#2. 多模态思考与推理成为[大模型发展]的新方向)
- [3. 世界模型:从高度一致的3D空间生成与交互->物理真实可交互](#3. [世界模型]:从高度一致的3D空间生成与交互->物理真实可交互)
- [4. 从视频生成迈向多模态与多任务统一的音视频联合生成模型](#4. 从视频生成迈向多模态与多任务统一的音视频联合生成模型)
- [5. GPT-40图像生成惊艳登场,生成理解统一模型从持续发展到反思调整](#5. GPT-40图像生成惊艳登场,生成理解统一模型从持续发展到反思调整)
- [6. 3D场景重建与物体生成双双进入基础模型时代](#6. [3D场景重建]与物体生成双双进入基础模型时代)
- [7. 视觉基础模型 持续发展,成为视觉任务、VL大模型和视觉生成的重要推动力量](#7. [视觉基础模型] 持续发展,成为视觉任务、VL大模型和视觉生成的重要推动力量)
- [8. 大模型等人工智能技术切实成为科学发现新范式](#8. 大模型等人工智能技术切实成为[科学发现]新范式)
- [9.大模型发展迈入 Agentic Al 时代](#9.大模型发展迈入 [Agentic Al 时代])
- [10. 大模型能力持续进步,国产大模型在国际开源社区表现强劲](#10. 大模型能力持续进步,[国产大模型]在国际开源社区表现强劲)
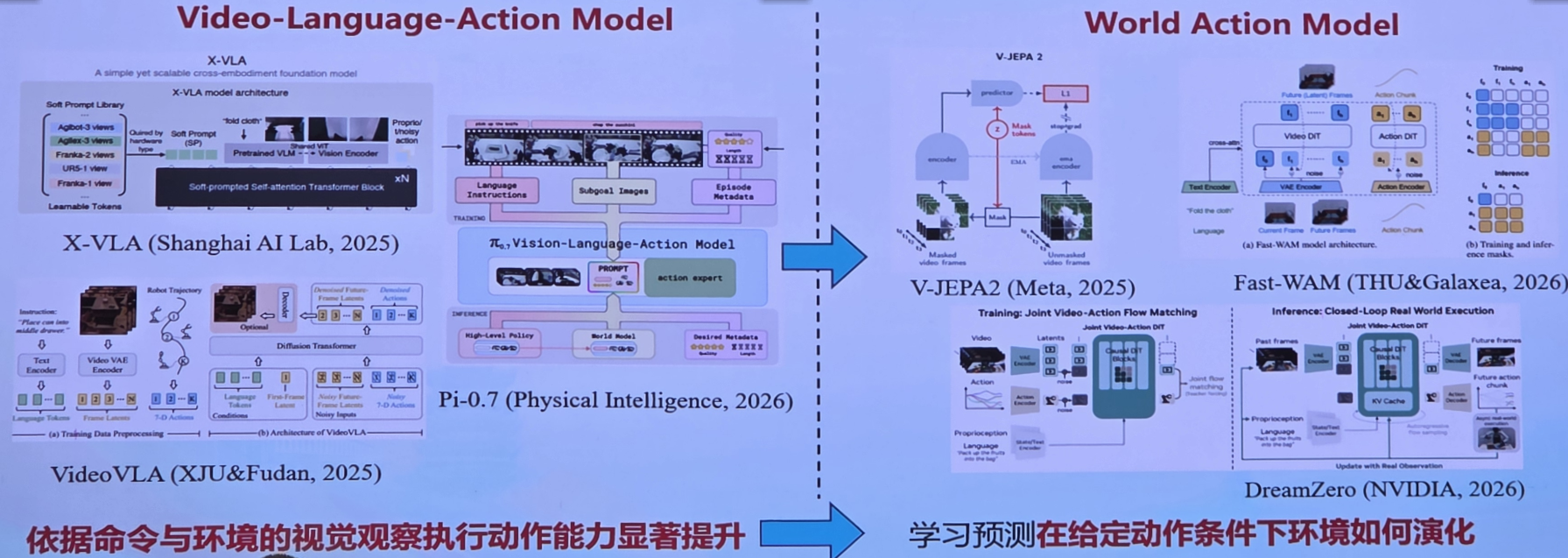
1.具身智能:VLA模型与World Action Model齐头并进
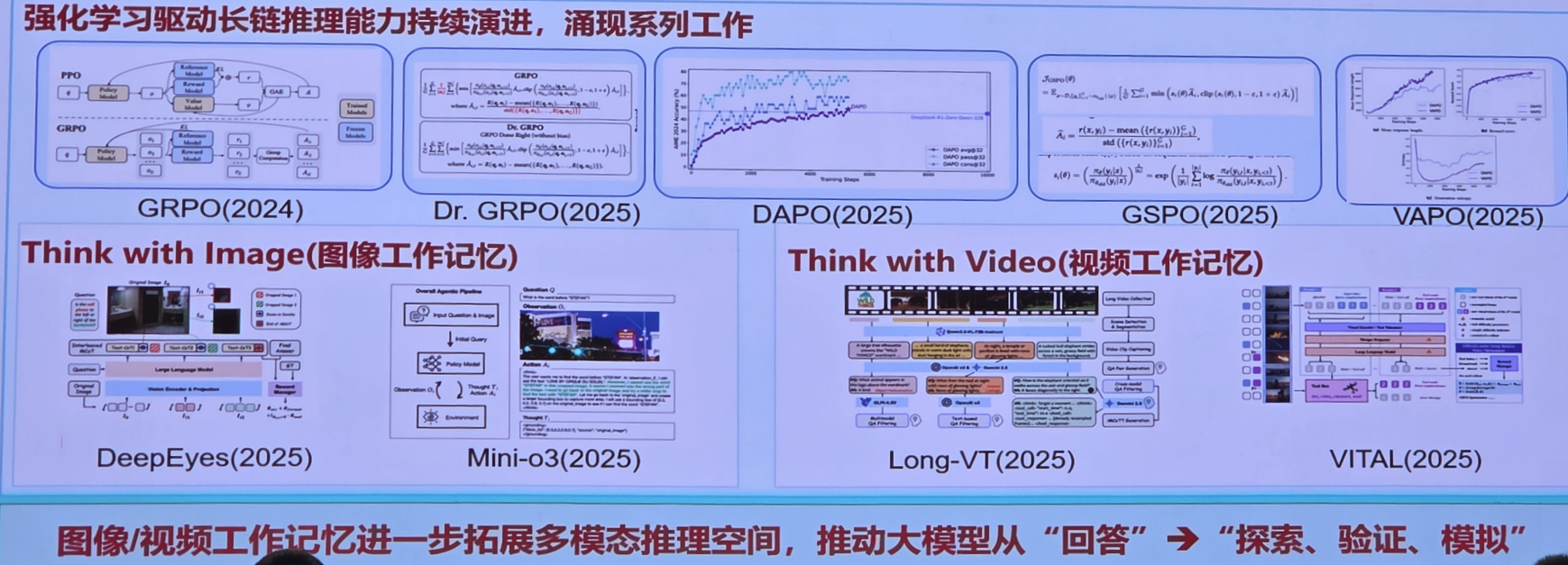
2. 多模态思考与推理成为大模型发展的新方向
3. 世界模型:从高度一致的3D空间生成与交互->物理真实可交互

4. 从视频生成迈向多模态与多任务统一的音视频联合生成模型

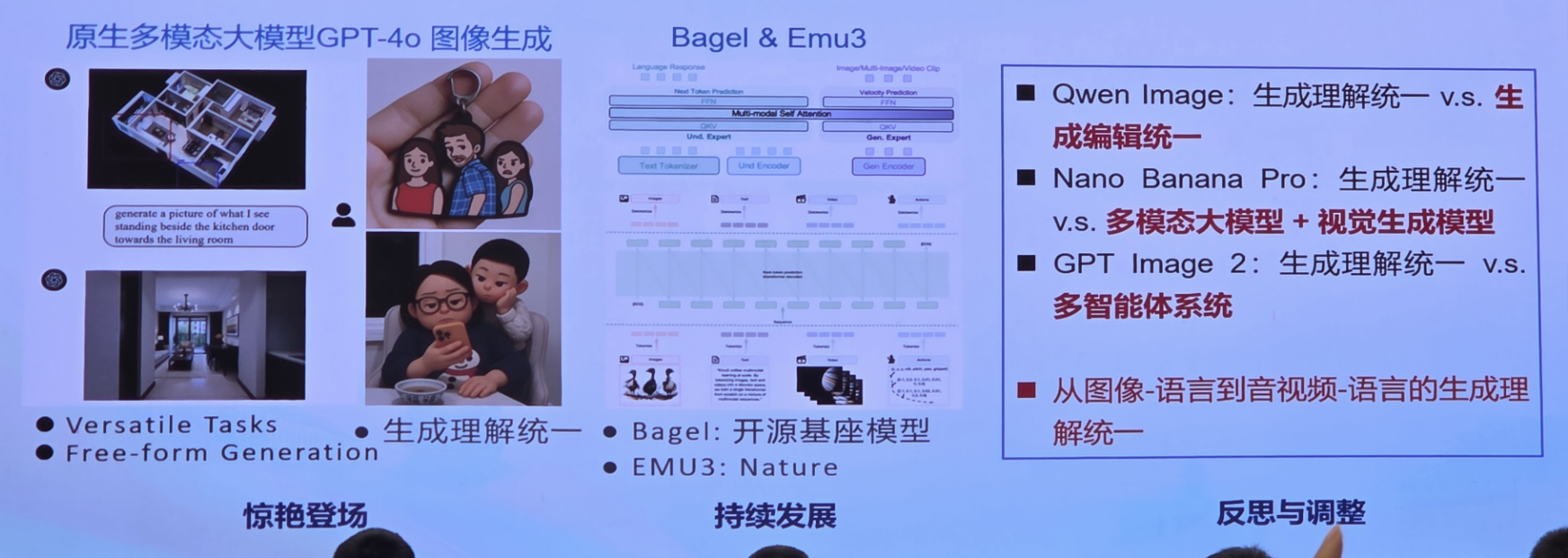
5. GPT-40图像生成惊艳登场,生成理解统一模型从持续发展到反思调整
6. 3D场景重建与物体生成双双进入基础模型时代

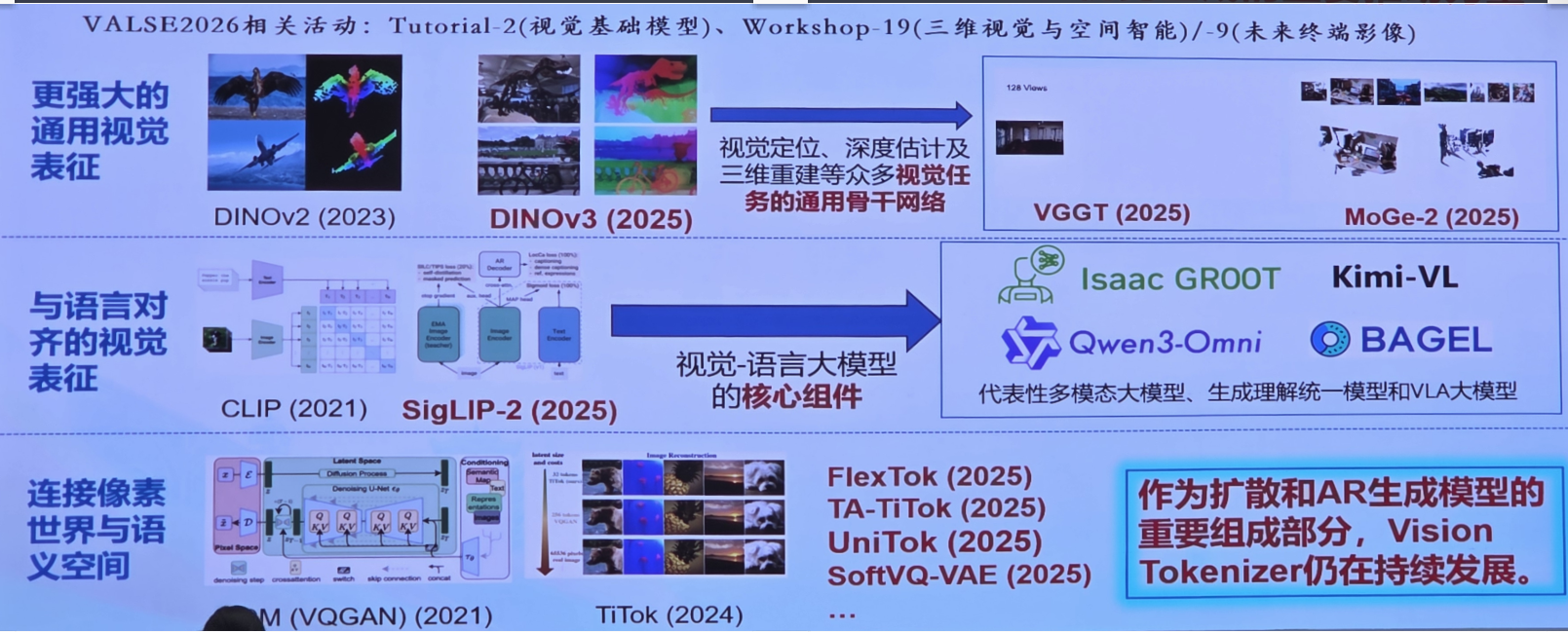
7. 视觉基础模型 持续发展,成为视觉任务、VL大模型和视觉生成的重要推动力量
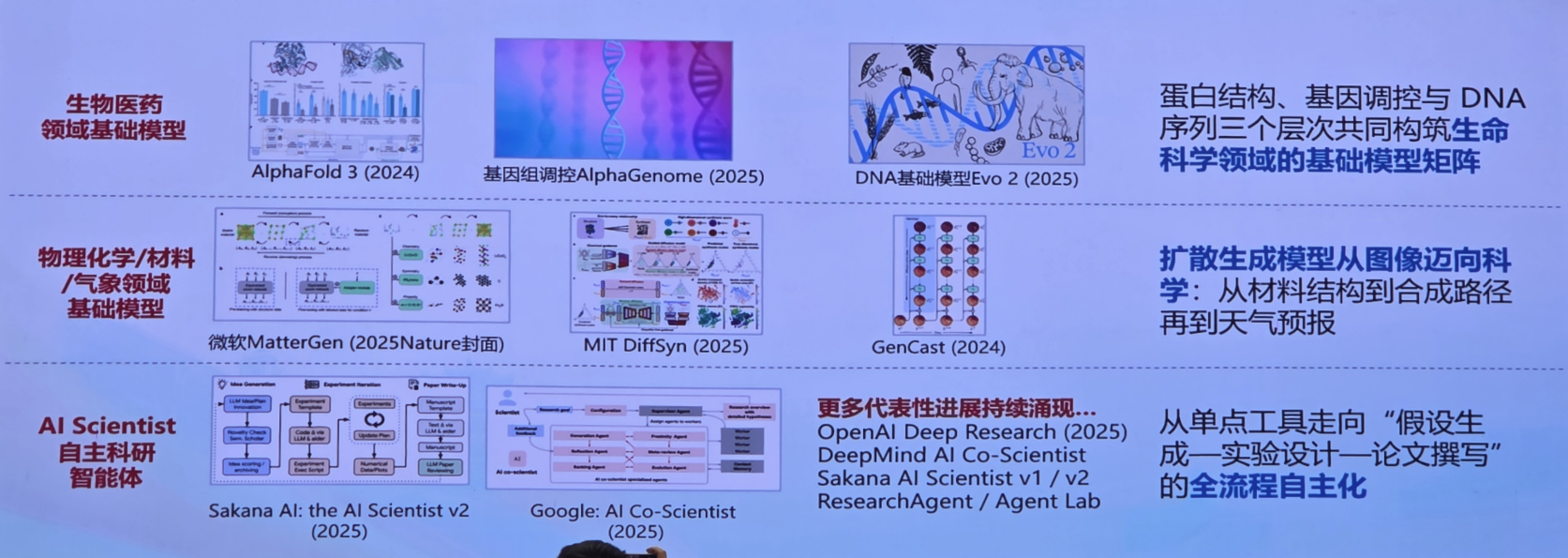
8. 大模型等人工智能技术切实成为科学发现新范式
9.大模型发展迈入 Agentic Al 时代

10. 大模型能力持续进步,国产大模型在国际开源社区表现强劲

d \sqrt{d} d 1 8 \frac {1}{8} 81 x ˉ \bar{x} xˉ D ^ \hat{D} D^ I ~ \tilde{I} I~ ϵ \epsilon ϵ
ϕ \phi ϕ ∏ \prod ∏ a b c \sqrt{abc} abc ∑ a b c \sum{abc} ∑abc
/ $$ E \mathcal{E} E