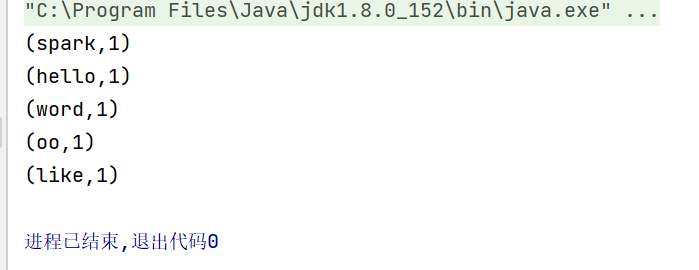
本案例在文件中读取,上面是文件路径
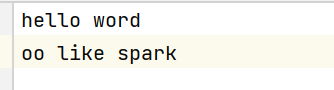
这是文件内容
代码如下:
java
package RDD.test;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import java.util.Arrays;
public class RDD_test_WordCount {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf().setMaster("local").setAppName("sparkcore");
JavaSparkContext context = new JavaSparkContext(sparkConf);
JavaRDD<String> rdd = context.textFile("data/word.txt");
JavaRDD<String> rdd1 = rdd.flatMap(line -> Arrays.asList(line.split(" ")).iterator());
JavaPairRDD<String, Iterable<String>> stringIterableJavaPairRDD = rdd1.groupBy(num -> num);
JavaPairRDD<String, Integer> stringIntegerJavaPairRDD = stringIterableJavaPairRDD.mapValues(
ite -> {
int len = 0;
for (String s : ite) {
len++;
}
return len;
}
);
stringIntegerJavaPairRDD.collect().forEach(System.out::println);
context.close();
}
}运行结果为: