1.树
1.1树的概念
树是一种非线性的数据结构,它是由n(n>=0)个有限节点组成一个具有层次关系的集合。把它叫做树是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。
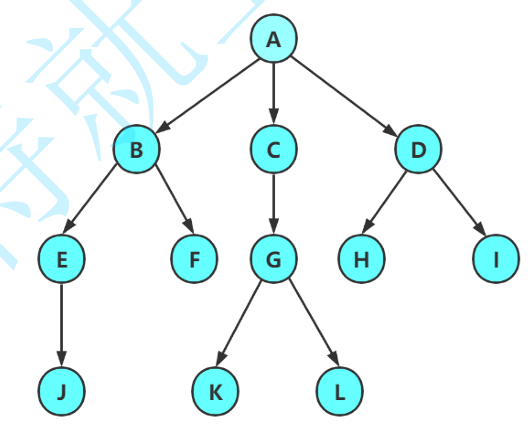
● 根节点是一个特殊的节点,没有前驱节点。
● 由于除根结点外,其余结点被分成M(M>0)个互不相交的集合T1、T2、......、Tm,其中每一个集合Ti(1<= i <= m)又是一棵结构与树类似的子树,因此,树是递归定义的 。
注意:树形结构中,子树之间不能有交集,否则就不是树形结构
1.2有关树的重要概念
节点的度:一个节点含有的子树的个数
叶节点或终端节点:度为0的节点
非终端节点或分支节点:度不为0的节点
双亲节点或父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点
孩子节点或子节点:一个节点含有的子树的根节点称为该节点的子节点
树的度:一棵树中,最大的节点的度称为树的度
节点的层次:从根开始定义起,根为第1层,根的子节点为第2层
树的高度或深度:树中节点的最大层次
节点的祖先:从根到该节点所经分支上的所有节点
1.3树的表示
有一种经典的表示方法:左孩子右兄弟表示法
节点仅保存两个指针:
● leftchild:永远指向当前节点最左侧的第一个子节点
● rightBrother:指向自己右侧紧邻的同辈兄弟节点
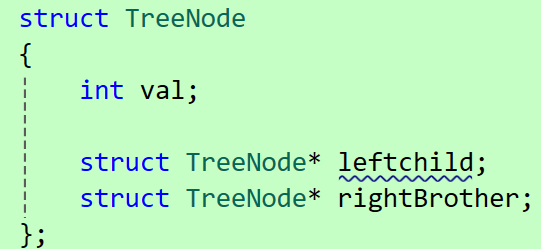
如下图:
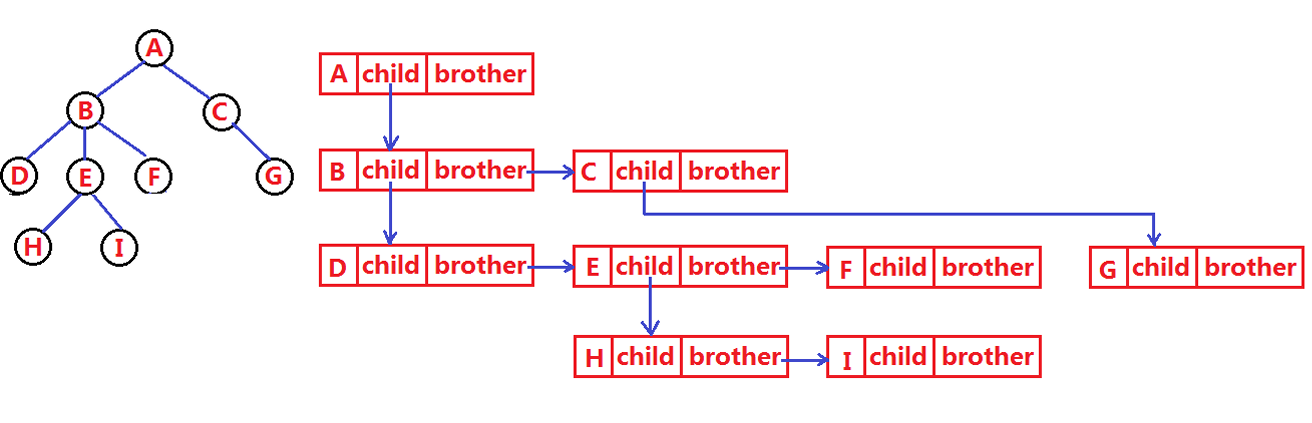
遍历子节点时,先通过leftchild找到长子,再沿着rightbrother向后逐个遍历所有兄弟,就可以完整访问所有后代。
2.二叉树概念及结构
2.1概念
二叉树是树的子集,特点为:
● 每个节点最多只能有2个子节点。
● 子节点严格区分左右,次序不能颠倒,是有序树 。
任意的二叉树都是由以下几种情况复合而成的:
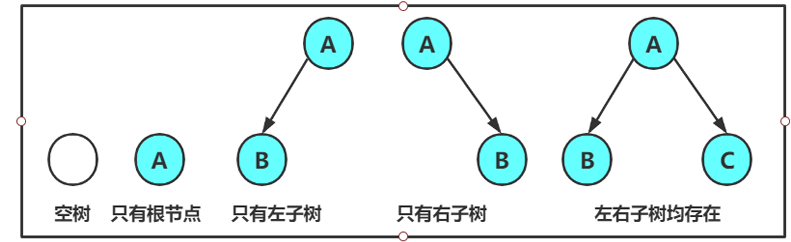
2.2特殊二叉树:
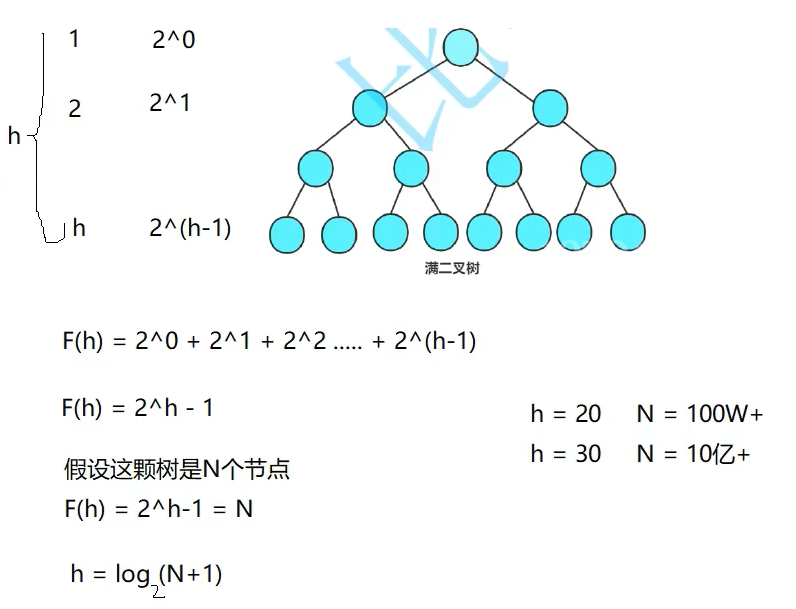
2.2.1 满二叉树
每一个层的节点数都是满的。
假设总共有h层,那么就能存2^h-1个节点
那么假设这棵树是N个节点,层数h就为log₂(N+1),推导如下图:
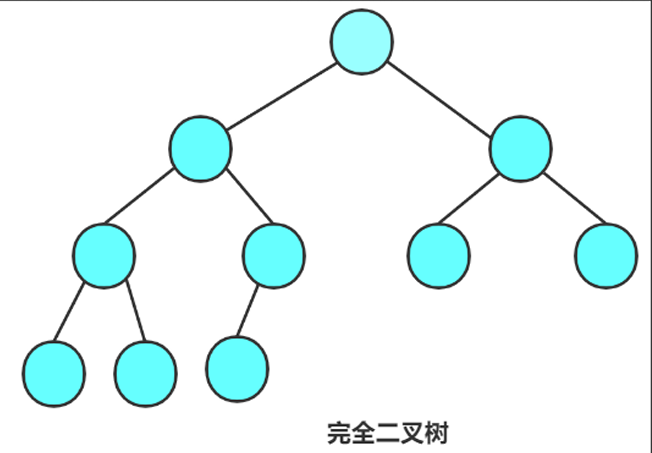
2.2.2 完全二叉树
前N-1层都是满的,最后一层的节点必须从左向右连续分布,不能留空位。
2.3二叉树的存储结构
二叉树一般可以使用两种结构存储,一种是链式结构,一种是顺序结构。
今天我们重点讲解顺序结构存储:
● 物理上是一段连续数组,逻辑上还原二叉树结构
● 当下标从0开始编号时,父子节点下标存在的数学关系如下图:
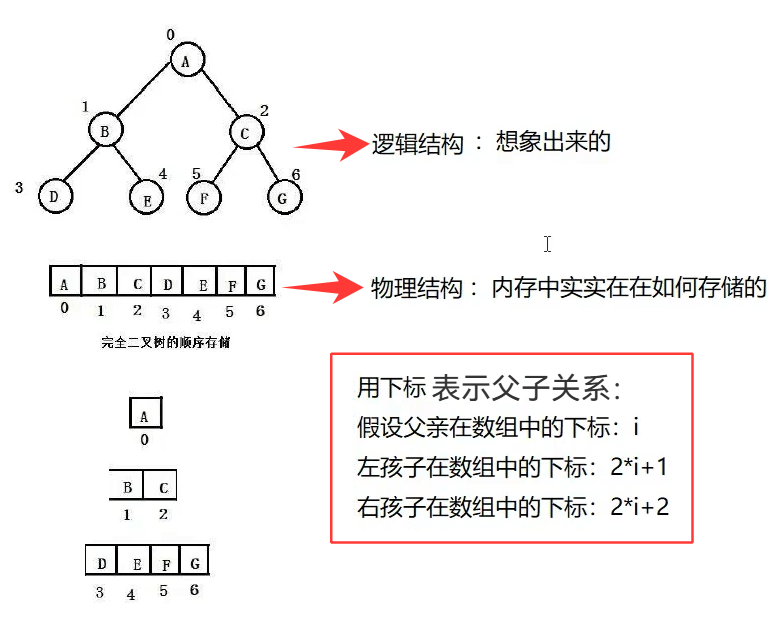
注:若假设孩子在数组中的下标为j,用整数除法逆推后,父节点下标统一用(j-1)/2来算即可
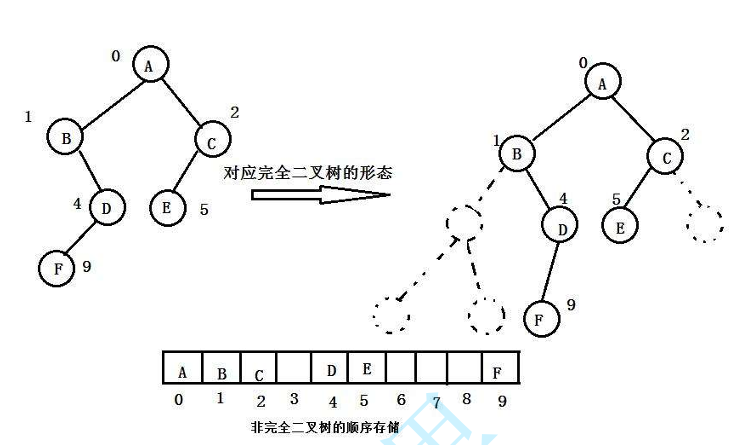
一般数组只适合表示完全二叉树,用来表示非完全二叉树会造成内存空间的浪费,如下图:
3.堆
3.1 堆的概念与结构
定义:堆在逻辑结构上是一种特殊的完全二叉树,可分为:
● 大堆:任何一个父节点的值都**>=**子节点的值。根节点为整棵树的最大值
● 小堆:任何一个父节点的值都**<=**子节点的值。根节点为整棵树的最小值。
注意:堆并不等同于有序序列,因为同一层"兄弟节点"之间并不存在确定的大小约束。
3.2 堆的实现
首先我们需要创建三个文件:Heap.h,Heap.c,Test.c
3.2.1 堆的初始化与销毁

3.2.2 堆的插入(HPPush)与向上调整算法(AdjustUp)
当我们向堆末尾插入数据时,可能会破坏原有的堆特性。因此需要通过向上调整算法重新恢复平衡。
以小堆为例,如下图:
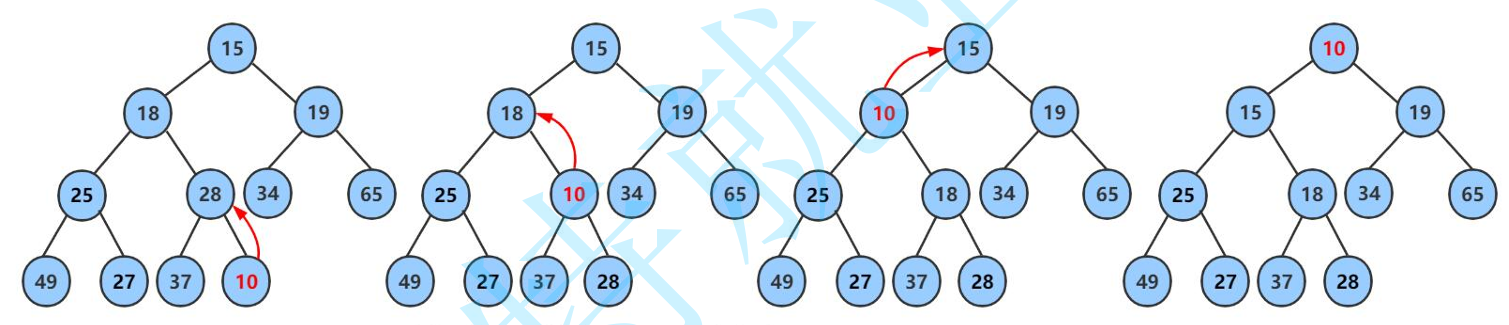
第一步:将新元素插入到堆的末尾(即最后一个叶子节点)
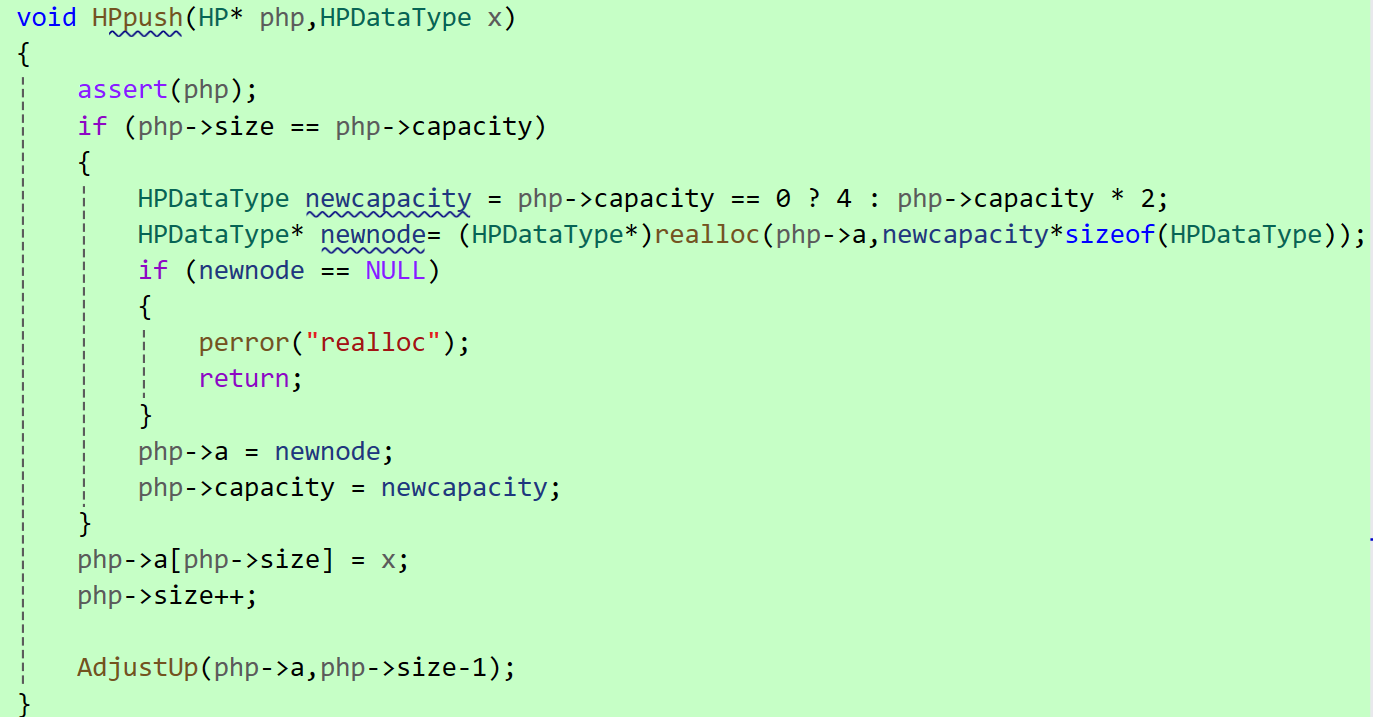
第二步:插入之后如果堆的性质遭到破坏,就将新插入的节点向上调整至正确位置。
完成向上调整函数:
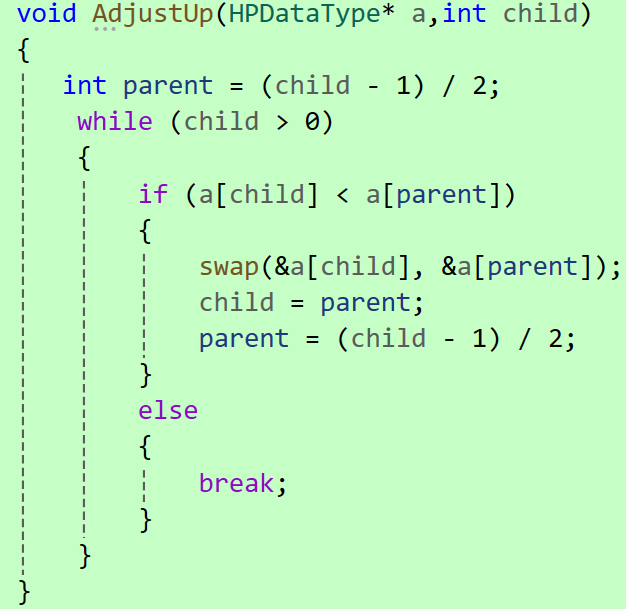
向上调整函数的核心逻辑:
传递的是新插入元素在数组中的下标,即"孩子"的位置。
通过公式计算出其父节点的位置,然后比较父节点与子节点的值。如果父节点的值大于子节点的值(以小堆为例),则违反了堆的性质。此时,交换父子节点的值,并将原来的子节点坐标移动到父节点处,成为新的子节点坐标,然后继续找到新的子节点对应的父节点。
这一过程不断重复,直到满足堆的性质(父节点 <=子节点)或到达堆顶为止。
关键点:
● 下标公式:parent=(child-1)/2,无论是左孩子还是右孩子,该公式永远成立。
● 比较交换:若子节点小于父节点(以小堆为例),则交换位置,并更新下标继续向上比较
● 终止条件:当子节点到达根部或已经满足父子关系时停止
易错点:循环条件不能设为parent>=0
因为在C语言中,当child偏移到0号位置时,parent=(0-1)/2的结果仍然是0,如果条件设为parent>=0,就会导致死循环,所以必须以child>0作为判定标准。
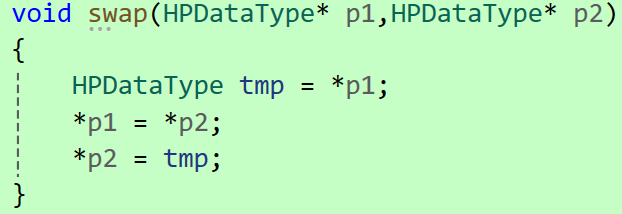
下面的swap函数供参考:
来解决一个小问题:
如果给出一个随机的数组,如何让它成为一个小堆呢?
只需要调用我们写的HPpush函数即可。
如下图,在Test.c文件中:
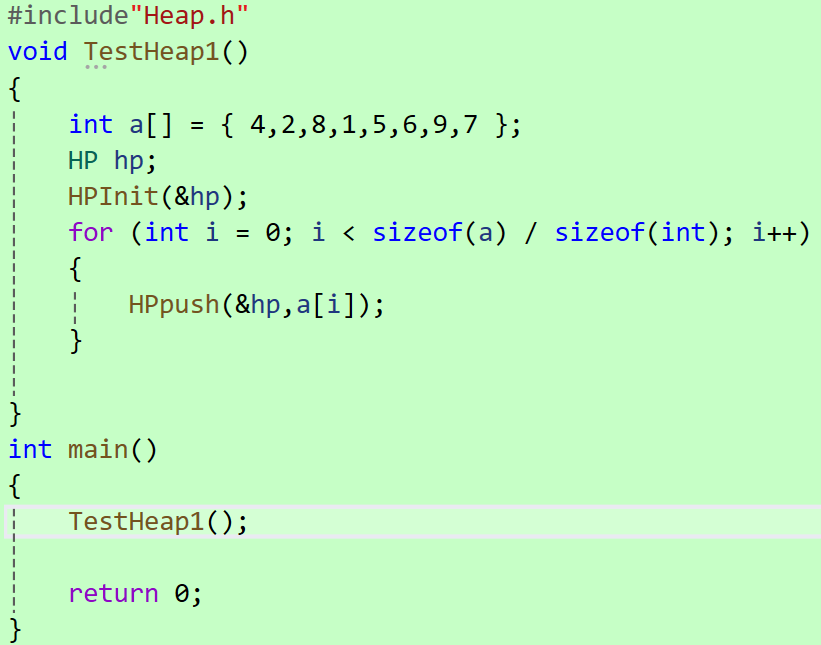
最后我们进行调试得到的结果如下:

3.2.3 堆顶删除(HPPop)与向下调整(AdjustDown)
注意:不能直接挪动数组元素来删除堆顶,这样做会打乱原来的父子关系。
正确操作如下:
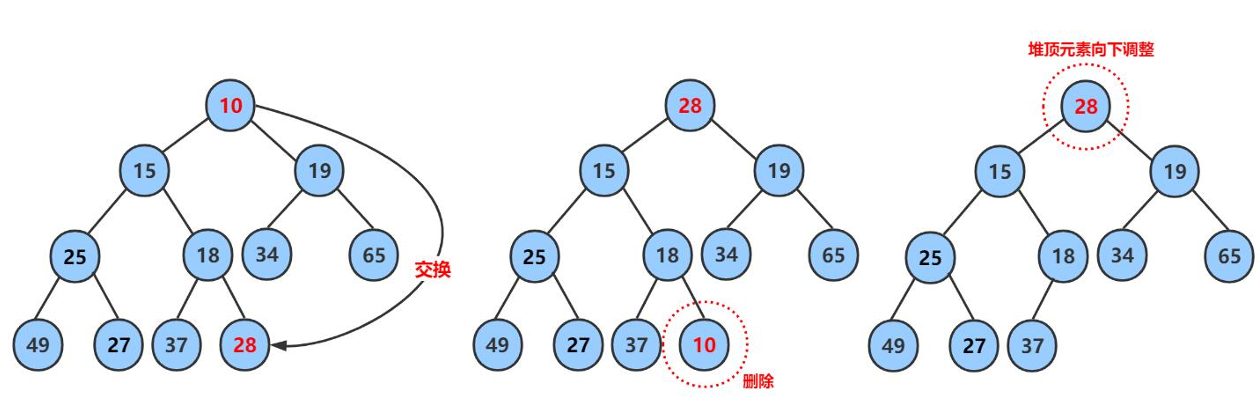 第一步:将堆顶元素与最后一个元素进行交换
第一步:将堆顶元素与最后一个元素进行交换
第二步:删除最后一个元素
完成删除操作前首先要确保堆不为空,且堆的指针非空。

第三步:将堆顶元素向下调整到满足堆特性为止
向下调整算法有一个前提:左右子树都必须是一个堆,才能调整。
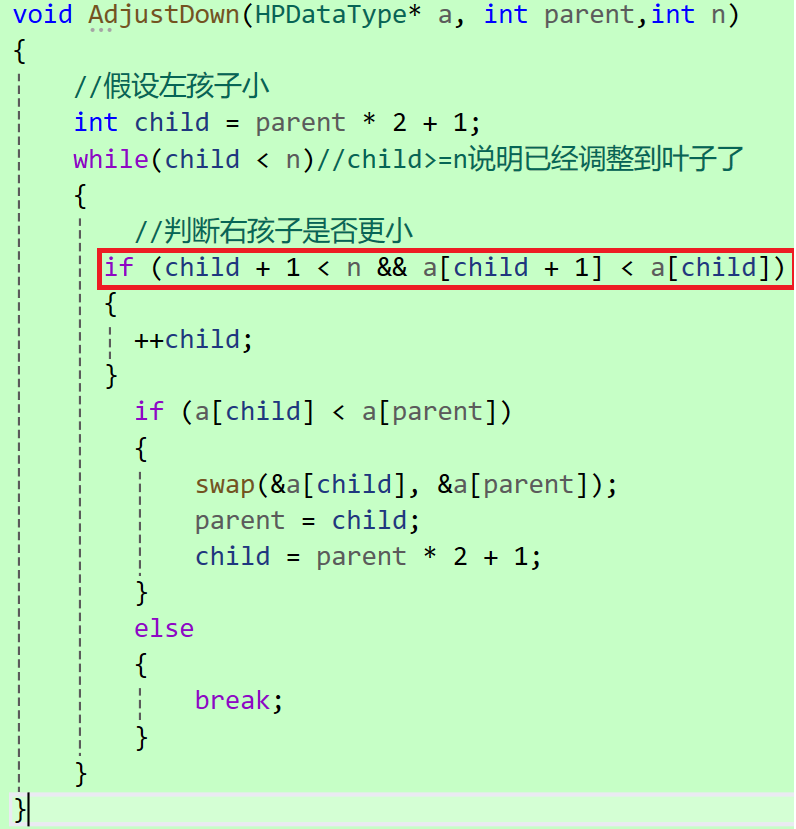
向下调整算法的核心逻辑:
传递的是根位置的下标,即"父亲"的位置。
通过公式计算出孩子坐标,然后找到左右孩子中更小的一个,如果父节点的值大于子节点的值(以小堆为例),就交换父子节点的值,并将原来的父节点的坐标移动到子节点处,成为新的父节点,然后继续找到新的父节点对应的子节点。
关键点:
● 使用了假设法,先假设左孩子更小,再判断是否应改为右孩子,这样能有效减少逻辑分支。
● if(child+1<n&&...)这一步很关键,必须要确保右孩子存在才能进行比较,防止越界。
● child>=n说明当前节点已经没有子节点了,无需向下调整。
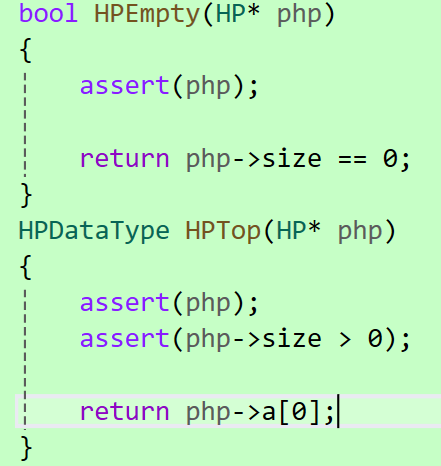
3.2.4 判空与返回堆顶的数据
不过多赘述,代码如下:
3.3堆的应用
3.3.1 堆排序
分为两步:
1.建堆
这是最容易产生惯性思维错误的地方:
• 如果排升序建小堆: 取走最小数后,剩余元素的关系全乱了,需要重新建堆,代价极大。
• 如果排升序建大堆: 堆顶是最大的。将它与末尾交换,最大值就排好了。再对剩下的元素 进行向下调整,只需 O(log N) 就能选出次大值。
结论:
● 排升序:建大堆
● 排降序:建小堆
2. 利用堆删除思想来进行排序(以降序为例)
如下图,堆排序实际上就是利用堆删除思想来完成的:


(1) 初始建小堆: 首先通过 AdjustDown 或 AdjustUp 将原始数组构建成一个小堆。
(2) 选值与交换: 将堆顶(最小值)与 aend 交换。此时 end 指向数组的最后一个有效位置。
(3) 恢复堆性: 对新的堆顶元素执行向下调整,范围缩小到 0, end-1,确保堆顶产生新的最小值。
(4) 循环收尾: 递减 end,重复上述步骤,直到所有元素处理完毕。
*建堆时间复杂度的完整推导
1.二叉树的高度(基础)
• 满二叉树:每一层节点都填满,总节点数满足 N=2^h-1,因此树高 h=log₂(N+1)
• 完全二叉树:在最少节点的情况下,树高 h=log₂N+1
具体分析过程如下:
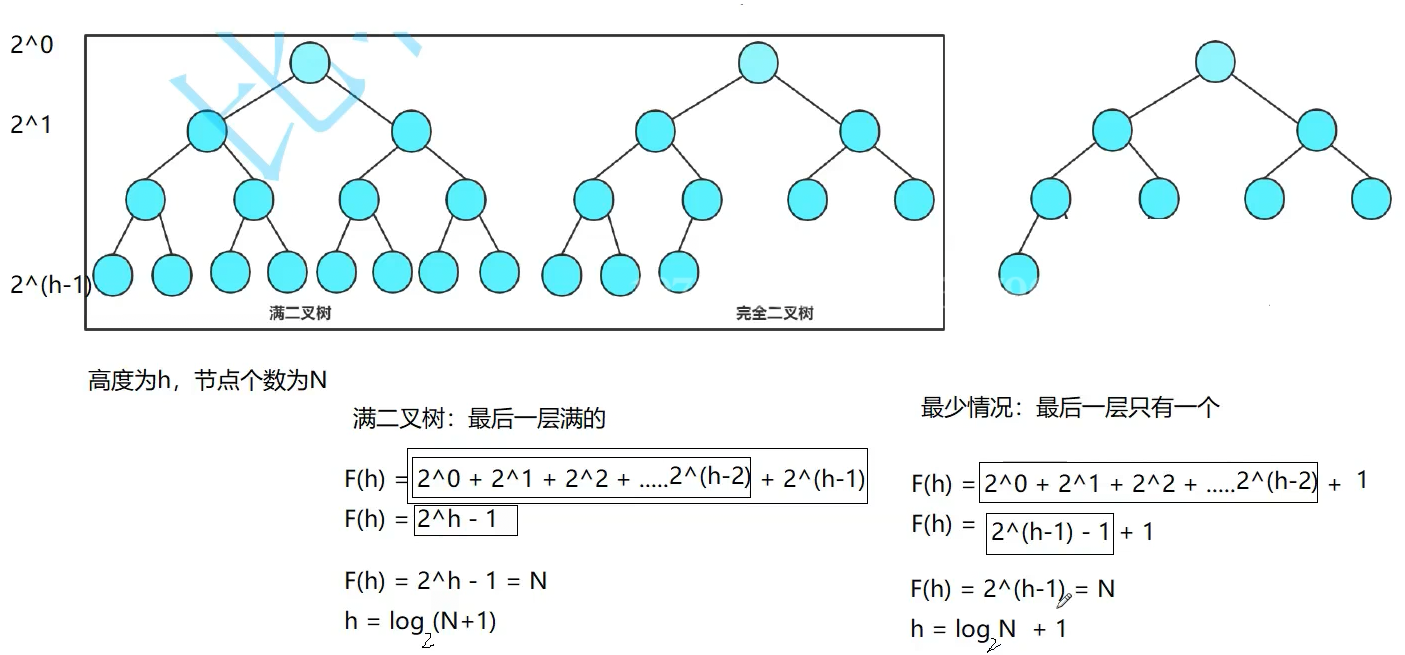
根据上图分析可得:无论是满二叉树还是完全二叉树,堆向上调整或者向下调整都是logN次(大O渐进表示法),但是二者的时间复杂度是不一样的,这是每一个初学者都易犯的错误。
2.向下调整建堆的时间复杂度:
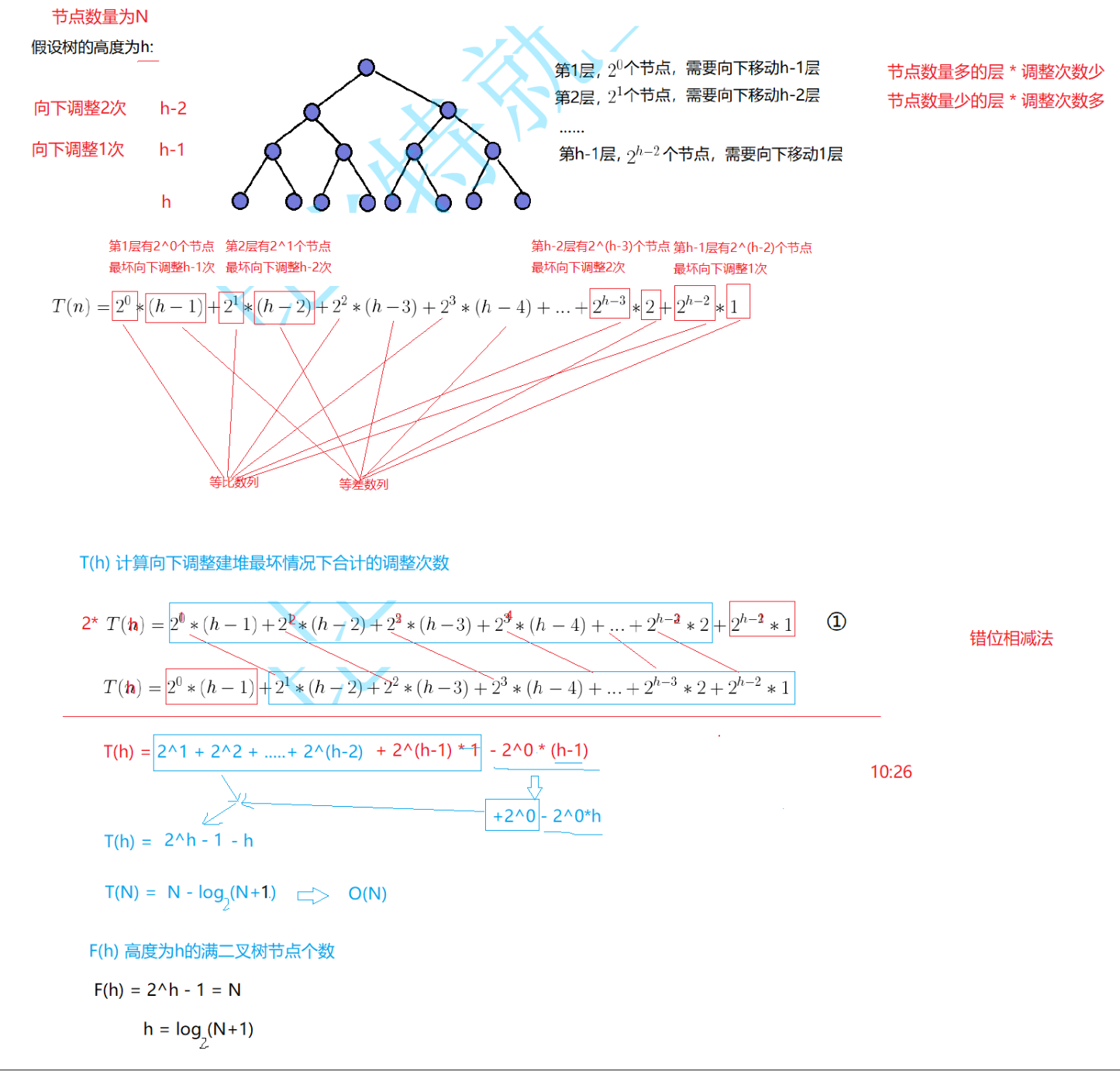
从根节点逐层向下调整,利用错位相减法对求和公式化简,最终得到建堆总时间T(N)=N-log₂(N+1),时间复杂度为O(N)。
3.向上调整建堆的时间复杂度:
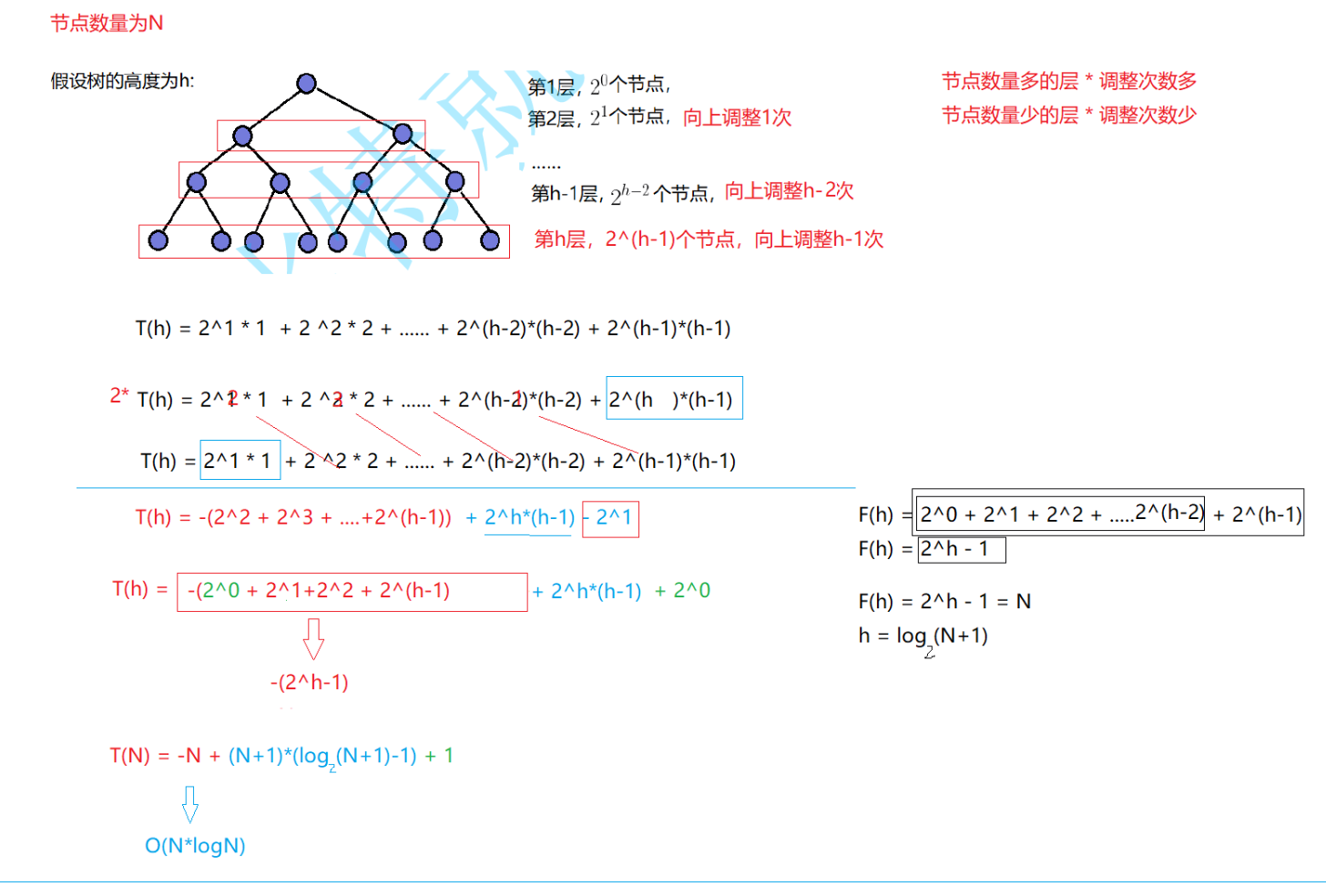
从叶子节点逐层向上比较调整,错位相减化简后,最终整体的时间复杂度为O(NlogN)。
总结:根据上述分析推导可知,向下调整建堆效率远优于向上调整建堆,所以我们在建堆时,应该优先选择向下调整算法。
因此优化过后的堆排序代码如下:

i=(n-1-1)/2:表示最后一个非叶子节点的位置
i--:自下而上先修好下层子堆,再调整上层父节点
这就是经典的弗洛伊德建堆法(Floyd Build Heap),时间复杂度O(N)。
3.3.2 TOP-K问题
TOP-K问题:即求数据集合中前K个最大的元素或者最小的元素,一般情况下数据量都比较大。
思路一:全局建大堆

优点:时间复杂度为O(N),效率较高
致命缺陷:内存爆炸
假如这里的N达到十亿量级,需要的内存大概就在4G左右,大多数场景下,机器可用内存远不足以一次性加载全部数据。
思路二:固定容量建小堆
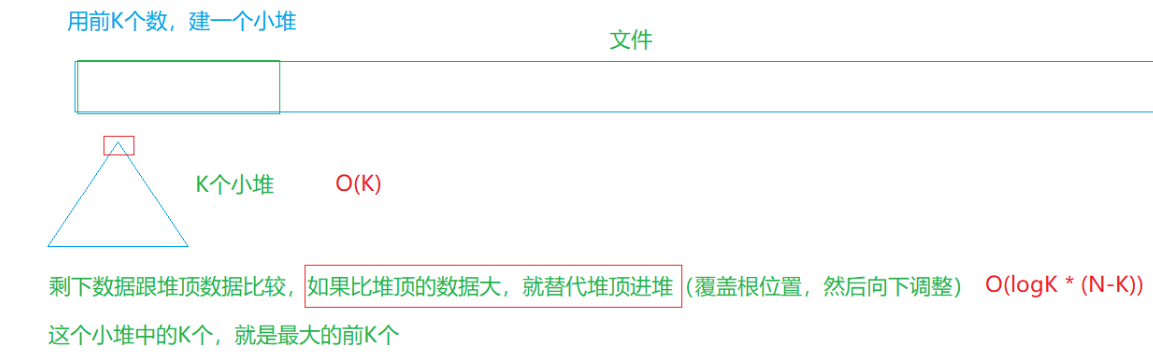
核心优势:这个方法全程内存仅占用4*K个字节,大大减少了空间的消耗