近一年里,AI知识库这个话题被聊烂了,但很多人没注意到,知识库检索这件事底下分了两条路:
一条是传统 RAG(检索增强生成) ,另一条是最近越来越多产品在用的 Agent Skills 方式。两条路的实现逻辑差别很大,适合的场景也不一样。
RAG 的工作原理和它的固有局限
RAG 的全称是 Retrieval-Augmented Generation,检索增强生成。
标准流程是:先把文档切成小段(chunk),每段送进 embedding 模型变成向量,存进向量数据库。
用户问问题时,把问题也转成向量,在数据库里找相似度最高的几段,把这些段落塞进大模型的上下文,让模型基于这些内容回答。
这套流程相对成熟,开源工具多,是目前 AI 知识库产品的主流选择。但它有几个固有的问题。
1、切片精度是个难题。 文档怎么切、切多长,对检索质量影响很大。切太短丢上下文,切太长超出窗口,没有一个放之四海的最优解,每种文档类型都需要单独调。
2、向量相似度不等于语义相关。 两句话 embedding 距离近,不代表是用户想要的答案。特别是问题措辞和文档用词不一样时,召回率会明显下降。
3、无法主动决策检索范围。 传统 RAG 每次检索都是「大网捞鱼」,不区分这次问题需要从哪个文档集里找,模型也没有办法说「先去找一下这类内容,再综合判断」。
Agent Skills 的逻辑不一样
Agent Skills 的核心思路是,把知识源封装成一个可被调用的工具(Tool / Skill),让 Agent 自主决定什么时候调用、调用什么参数、拿到结果后怎么处理。
不是「每次问问题都全量搜一遍」,而是「Agent 根据问题判断,选择性地调用对应的知识接口」。
以一个笔记知识库为例,Agent Skills 的典型流程是这样:
用户问:上周的产品会议纪要里,关于定价策略说了什么?
Agent 判断:需要调用 搜索笔记 接口,参数:关键词=定价策略,时间范围=上周
→ 调用接口,拿到匹配的笔记列表
→ 再调用 获取笔记详情 接口,读取完整内容
→ 基于完整内容回答这里的关键差异:Agent 在检索前就做了决策,知道去哪找、找什么,而不是盲目把所有内容都算相似度。
Ai好记的 Skill 接口是个典型案例
Ai好记作为一款针对音视频的AI多模态知识库,开放了一套 Agent Skill 接口。
外部 Agent(比如 Claude Code)可以直接调用这个 Skill 来检索笔记内容,提供「列出笔记本」「搜索笔记」「获取笔记详情」三个接口,Agent 根据用户问题自主决定调用顺序和参数。

这比把所有笔记预先 embedding 的做法精准很多。
原因在于:笔记本身已经有人工整理的结构(标题、文件夹、时间),接口可以直接利用这层结构过滤,不需要靠向量相似度去猜「这篇和用户意图有多近」。
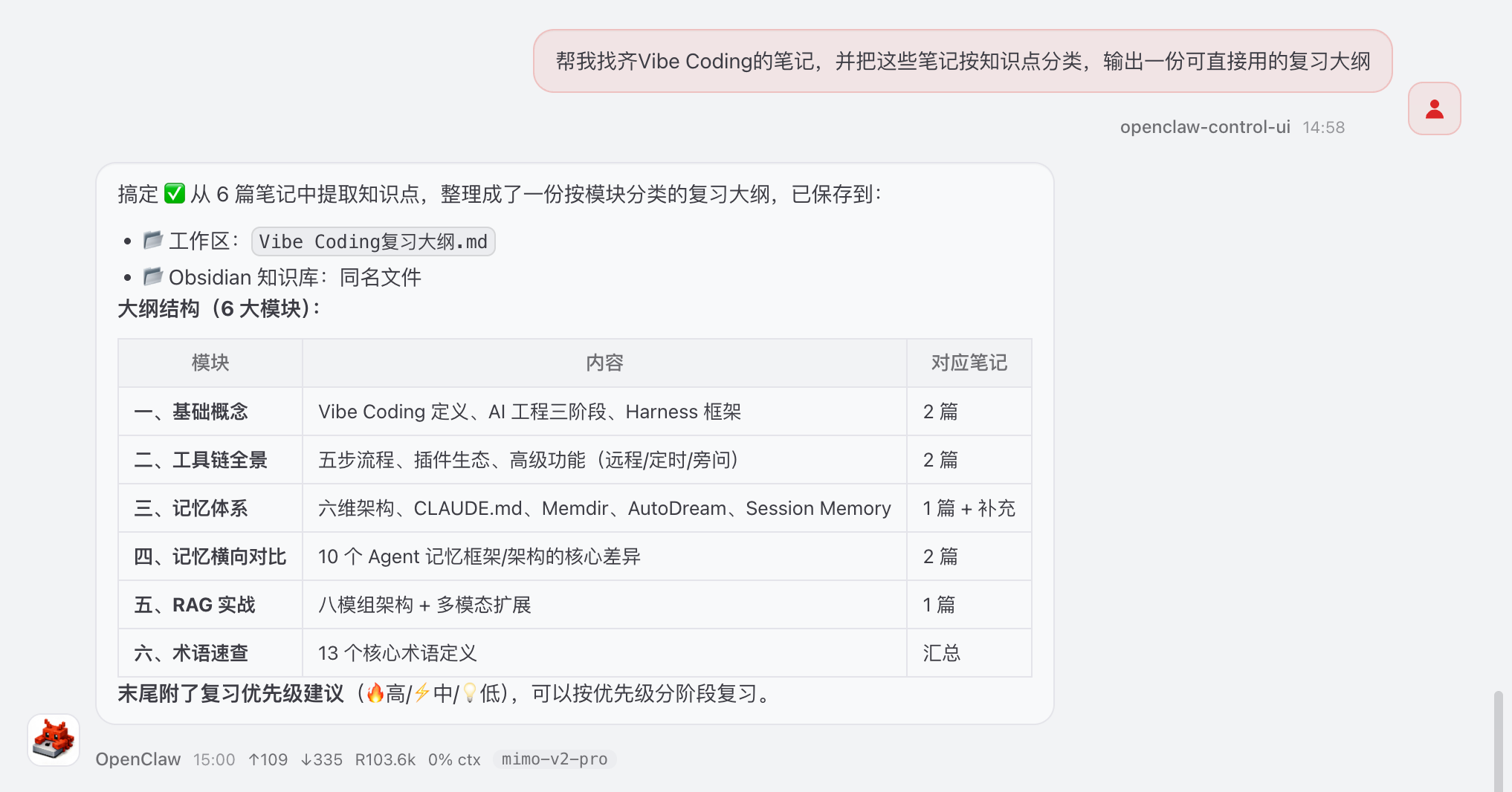
我自己用下来,问「最近关于 AI Agent 的笔记里提到了什么工具」这类有时间和主题双重限定的问题,Agent Skills 的精度明显比纯 RAG 高。
RAG 在切片时已经把时间信息稀释掉了,而 Skill 接口的时间参数是精确的。
两种方式的实际差距
| 维度 | 传统 RAG | Agent Skills |
|---|---|---|
| 检索方式 | 向量相似度匹配 | 工具调用 + 参数过滤 |
| 对文档结构的利用 | 弱(切片后结构丢失) | 强(接口可按结构查询) |
| 跨文档关联 | 有限(上下文窗口制约) | 可以多次调用,分步关联 |
| 可控性 | 低(黑盒检索) | 高(Agent 可解释检索路径) |
| 适合场景 | 非结构化文档、大量文本 | 结构化知识源、需要精确定位 |
坦率地讲,RAG 不是过时了,而是被高估了。
它适合处理大量非结构化文本,比如企业文档库、法律条文检索这类。但如果知识源本身有结构(笔记、数据库、分类目录),用 Agent Skills 反而更准。
什么场景选哪条路
两种方式不是非此即彼,越来越多的实际系统是混用的:RAG 处理非结构化的大文本,Agent Skills 处理有结构的知识源,让 Agent 自己根据问题类型决定调用哪条路。
搭建自己的 AI 知识管理系统时,以下几点可以参考:
文档没有明确分类、内容松散,优先 RAG,embedding 召回更合适。知识已经有结构(笔记、数据库、分类目录),用 Agent Skills,精度更高。
需要跨文档做多步推理,选 Agent Skills,因为 Agent 可以分步调用,中间插入判断。快速搭原型不想处理 API,RAG 工具链成熟,门槛更低。
FAQ
Q:Agent Skills 检索比 RAG 贵吗?
贵一点。每次调用工具都有 API 开销,Agent 的推理步数也更多。但精度更高意味着答案更准,一次出好比多次修正要划算。
Q:我的知识源是音视频转录文本,适合哪种?
取决于转录后有没有做结构化整理。如果只是一段段原始文本,RAG 是默认选择。如果整理成了有标题、有章节的笔记,就可以走 Agent Skills 路线,精度会更高。
Q:两种能不能同时上?
可以,而且推荐这么做。用 Agent Skills 处理结构化部分,RAG 兜底处理非结构化内容,让 Agent 自己判断每次走哪条路。这也是 AI Agent知识库 系统目前比较主流的架构方向。