很多人一提到 CNN,就会背"卷积、池化、全连接"这几个词,但一到面试官追问:
CNN 的核心层有哪些?各层到底在干什么?
卷积层和全连接层有什么本质区别?
卷积核大小是不是越大越好?1×1 卷积到底有什么用?
为什么 VGG 喜欢用很多 3×3 卷积?ResNet 又是怎么解决深层网络训练难题的?
这篇文章就把这些高频问题一次说透。我们不走复杂公式路线,而是用最容易记住的思路,把 CNN 的底层逻辑讲清楚。
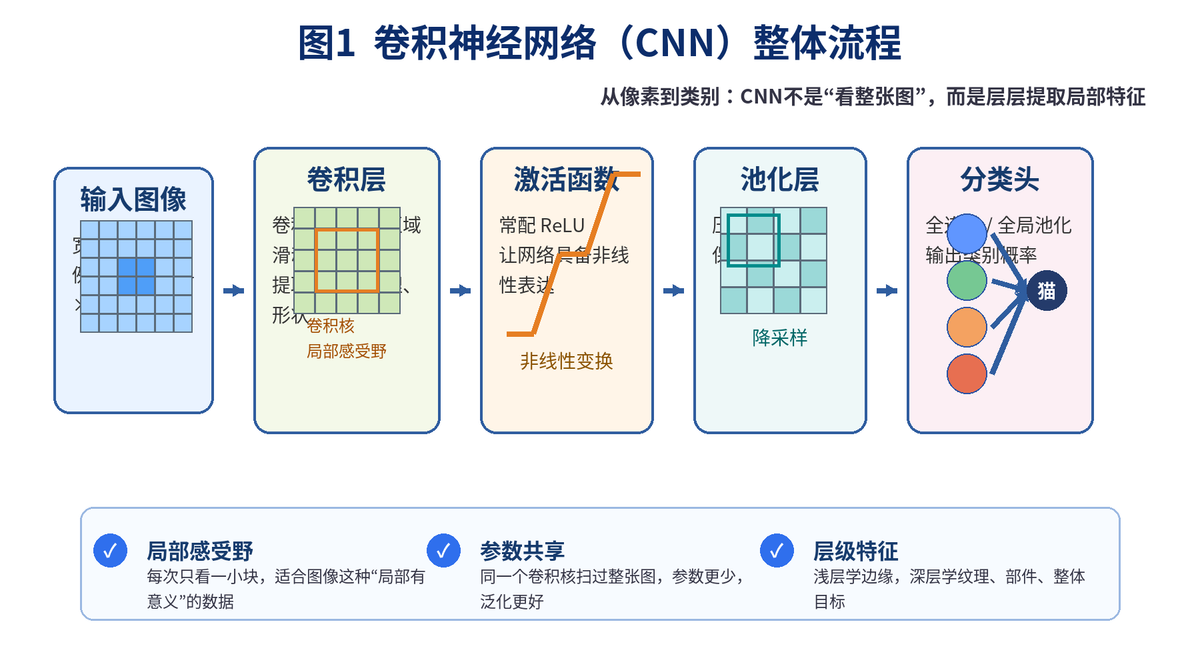
1. 什么是卷积神经网络(CNN)?
1.1 先用一句人话解释
卷积神经网络,本质上是一种特别适合处理图像数据的神经网络。它的关键思想不是一上来就看整张图,而是先看局部,再把很多局部信息一层层组合起来,最后形成对整张图的理解。
你可以把它理解成:
第一层先学会看边缘、明暗变化、简单纹理;
中间层逐步学到角点、条纹、轮廓、局部部件;
更深层再把这些部件拼起来,识别出脸、车轮、猫耳朵、文字结构等更高级特征。
所以,CNN 最大的价值不是"神秘",而是它特别符合图像数据本身的规律。图像里的信息往往具有局部性和重复性,同样的边缘、纹理、角点,可能出现在左上角,也可能出现在右下角。CNN 正好就是围绕这个特点设计出来的。
1.2 CNN 的核心层有哪些?
卷积层:负责提取局部特征,是 CNN 的核心。
激活函数:通常接在卷积层后面,给网络加入非线性表达能力。
池化层:负责压缩尺寸,减少计算量,同时保留主要信息。
分类头:可以是全连接层,也可以是全局平均池化后接分类层,用来输出最终类别。
面试里如果被问到"CNN 的核心是什么",最稳妥的回答是:卷积层是核心,池化层和分类头是配套结构,而真正让 CNN 区别于普通全连接网络的,是局部感受野和参数共享。
2. 卷积层和全连接层有什么区别?
2.1 卷积层为什么更适合图像?
全连接层的思路是:每个输入都连到每个输出。这样虽然表达能力强,但参数量很容易爆炸。假设一张图片是 224×224×3,如果直接拉平成一长串再接全连接层,参数会非常多。
卷积层则完全不同。它只看一个小窗口,比如 3×3 或 5×5,然后在整张图上滑动。也就是说,它一次只处理局部区域。这样做有两个好处:
更符合图像规律。边缘、角点、纹理这些模式,本来就是局部出现的。
参数量更省。同一个卷积核会在不同位置重复使用,不需要每个位置都单独学一套参数。
这就是 CNN 非常关键的两个概念:
局部感受野:每次只看一小块。
参数共享:同一个卷积核在整张图上反复扫描。
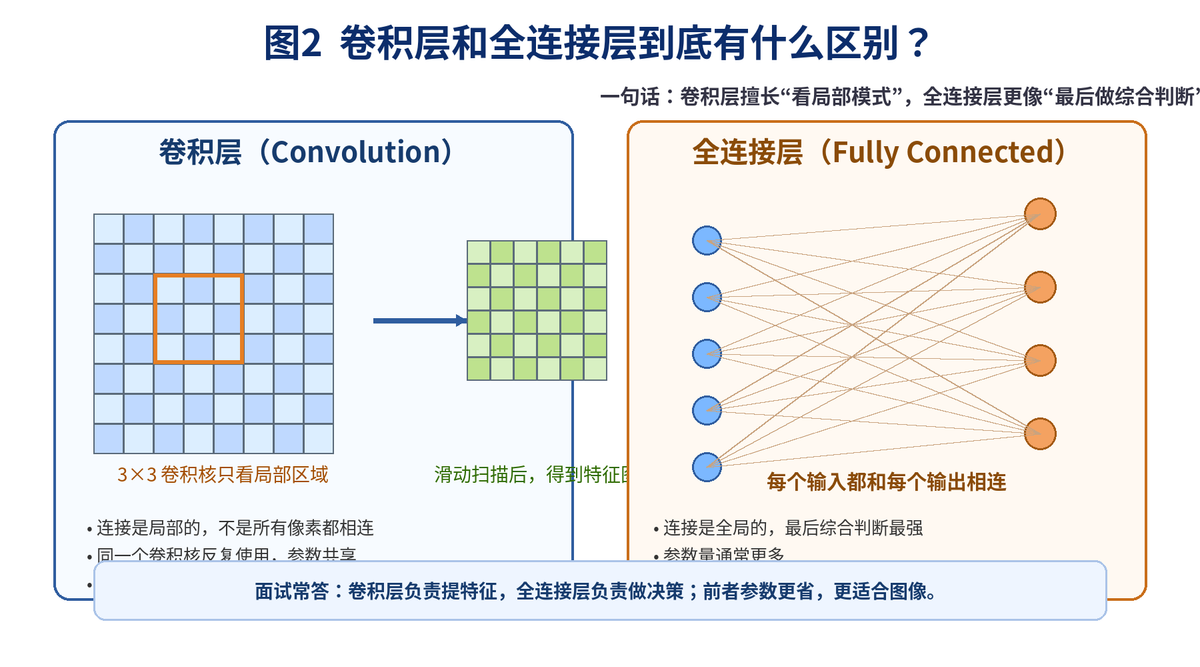
2.2 面试时怎么讲得更像实战?
你可以这样回答:卷积层负责提特征,全连接层负责做决策。卷积层通过局部连接和参数共享,大大减少了参数量,更适合图像这种有空间结构的数据;全连接层更像最后的分类器,通常放在网络后面。
现在很多现代 CNN,甚至会把传统的大型全连接层换成全局平均池化,因为这样参数更少,也更不容易过拟合。
3. 卷积层有哪些基本参数?输出大小怎么计算?
3.1 面试最爱问的四个参数
卷积核大小(Kernel Size):比如 3×3、5×5、7×7。
卷积核个数(Filters / Channels):决定输出特征图的通道数。
步长(Stride):卷积核每次移动几格。
填充(Padding):在输入边缘补 0,避免尺寸缩得太快。
其中,卷积核大小决定"看多大范围",步长决定"走多快",填充决定"边界保不保"。
3.2 输出大小怎么记最容易?
别死背复杂公式,记住一句话就行:
卷积核越大,输出通常越小;步长越大,输出更小;Padding 越多,输出越不容易缩小。
最常见的两种设置是:
valid:不补边,输出自然变小。
same:适当补边,让输出大小尽量和输入接近。
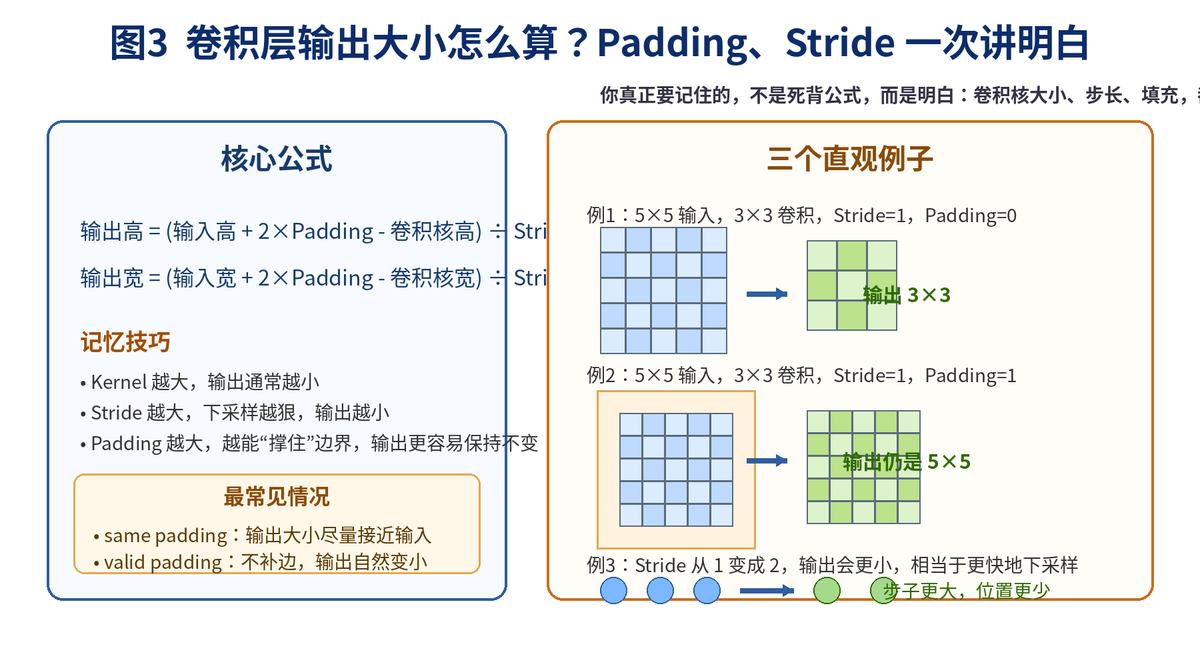
3.3 为什么通常需要 Padding?
如果不做 Padding,卷积核每扫一次,图像边缘就少一圈。层数一深,空间尺寸会很快缩没。更重要的是,边缘像素被利用得更少,容易让边界信息吃亏。
所以 Padding 的作用可以概括成两点:
控制输出尺寸,不让特征图缩得太快;
保护边缘信息,让图像边界也能被充分利用。
4. 1×1 卷积为什么这么重要?
4.1 它到底在卷什么?
很多人第一次看到 1×1 卷积会觉得奇怪:窗口只有一个点,这还叫卷积吗?
其实 1×1 卷积的重点不在空间范围,而在通道维度。它会在每个像素位置上,把这个位置的多个通道重新加权组合,所以它特别擅长"管通道"。
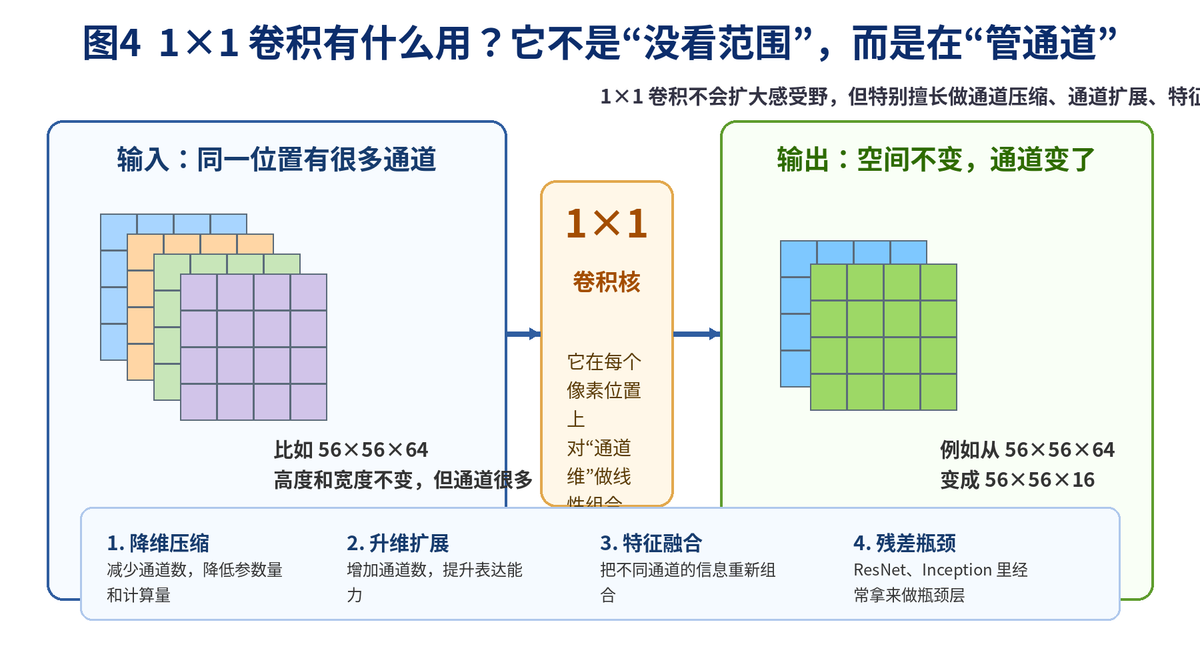
4.2 1×1 卷积常见作用
通道压缩:把很多通道压成更少通道,减少计算量。
通道扩展:把通道数变多,提升特征表达能力。
特征融合:把不同通道的信息重新组合。
瓶颈层:在 ResNet、Inception 等结构里经常作为 bottleneck 使用。
所以面试官如果问"1×1 卷积有什么用",不要答"没用"或者"只是降维"。更完整的回答是:它主要做通道方向的线性变换,用来压缩、扩展和融合特征,是现代 CNN 结构里的高频组件。
5. 池化层是什么?常见池化方法有哪些?
5.1 池化层的作用
池化层不是用来"学习"卷积核的,它更像一个下采样工具。它会把特征图压缩得更小,从而减少后续计算量,同时让网络对轻微的平移、抖动更稳。
压缩空间尺寸,降低计算成本;
保留主要信息,丢掉一部分冗余细节;
让模型对轻微位置变化更鲁棒。
5.2 常见池化方法:最大池化和平均池化
最大池化(Max Pooling):每个小窗口里取最大值,更强调最强响应。
平均池化(Average Pooling):每个小窗口取平均值,更强调整体趋势。
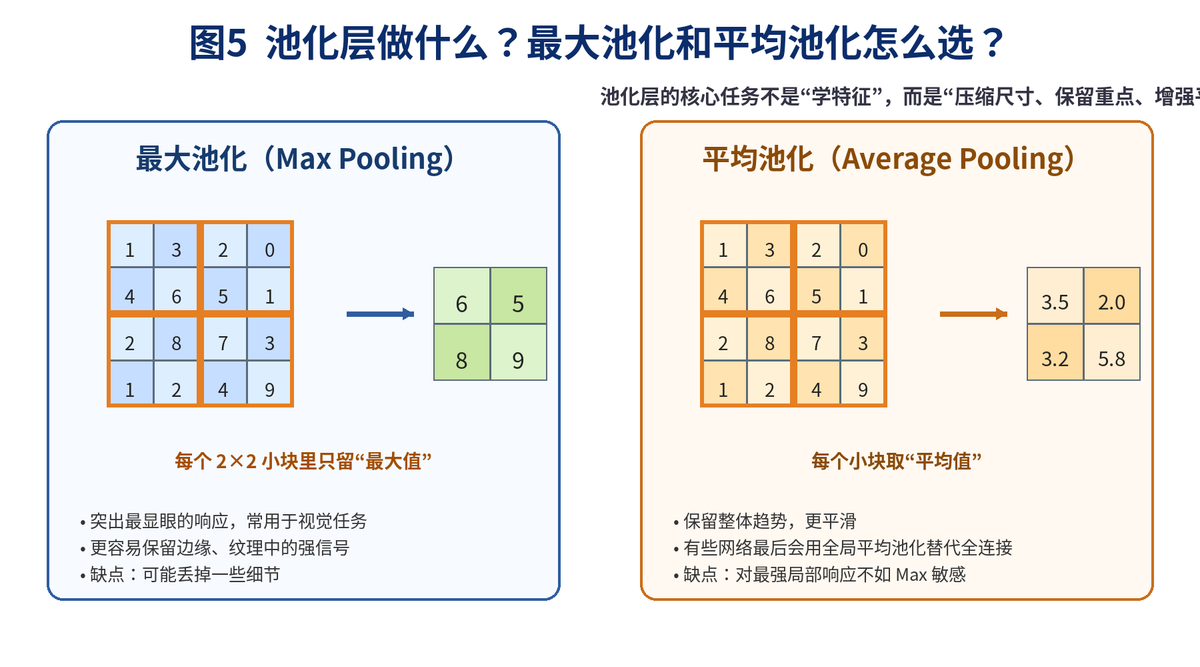
5.3 池化层和卷积层有什么区别?
卷积层负责学特征,池化层负责压尺寸。卷积层有可学习参数,池化层通常没有可学习参数。
所以面试里最标准的说法是:
卷积层是特征提取器,池化层是信息压缩器。
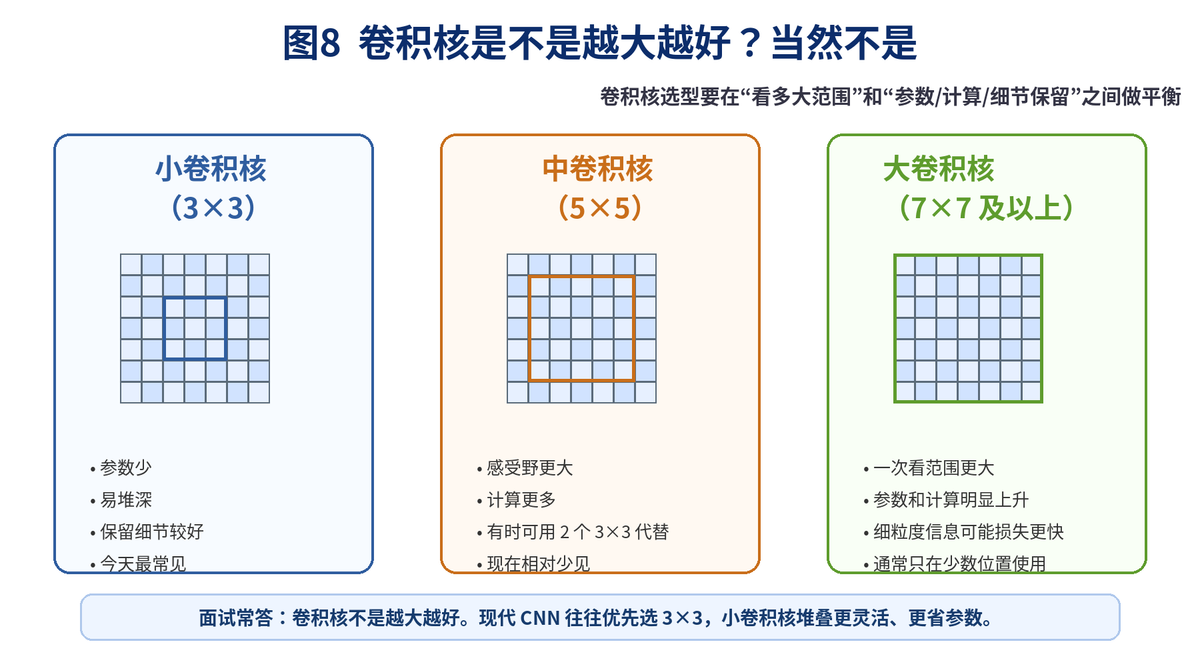
6. 卷积核是不是越大越好?为什么 VGG 常用 3×3?
6.1 卷积核大小要怎么理解?
卷积核越大,一次看到的局部范围越大,但这不意味着一定更好。因为卷积核一变大,参数量、计算量都会上去,而且过大的卷积核可能让细节信息被过早抹平。
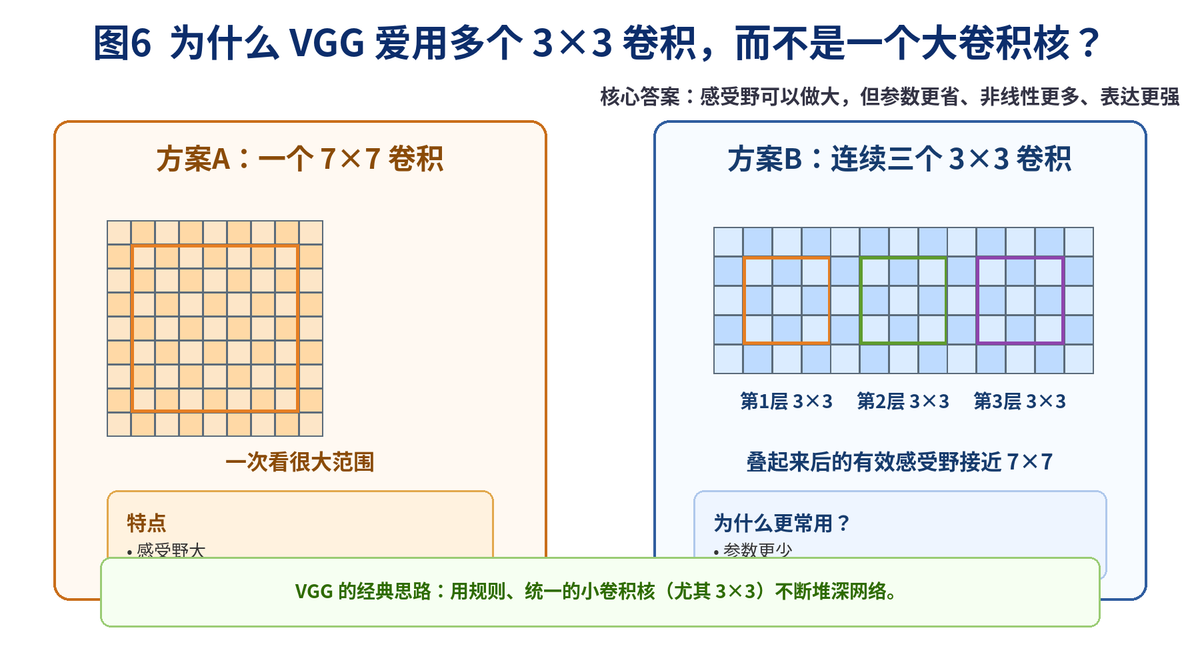
6.2 为什么 VGG 倾向堆很多 3×3?
VGG 的经典思路,就是尽量用规则统一的小卷积核,尤其是 3×3,然后不断堆深网络。
为什么这样做?核心原因有三个:
参数更省:多个小卷积核组合起来,通常比一个大卷积核更省参数。
非线性更多:每层卷积后都可以接激活函数,表达能力更强。
结构更规整:工程实现和网络设计都更方便。
6.3 面试怎么回答"卷积核大小是不是越大越好"?
标准答案是:不是。卷积核越大,感受野更大,但参数量和计算量也更大;现代 CNN 通常优先用 3×3 作为主力,再按需要搭配 1×1、5×5 或少量更大的卷积核。
7. ResNet 为什么能解决深层网络训练难题?
7.1 什么叫"退化问题"
很多初学者以为,网络越深一定越强。理论上表达能力可能更强,但实际训练时,层数加深后未必更容易优化。你会看到训练变慢、效果反而下降,这就是常说的深层网络优化困难或退化现象。
注意,这里不只是过拟合问题,而是:更深的网络不一定比浅网络更容易学到更好的解。
7.2 残差连接的核心思想
ResNet 的做法非常巧妙:既然直接学习完整映射太难,那就改成学习"增量",也就是残差。
简单说,就是让输入 x 除了走主分支做卷积,还通过一条 shortcut 近路直接传到后面,最后和主分支结果相加,变成 F(x)+x。
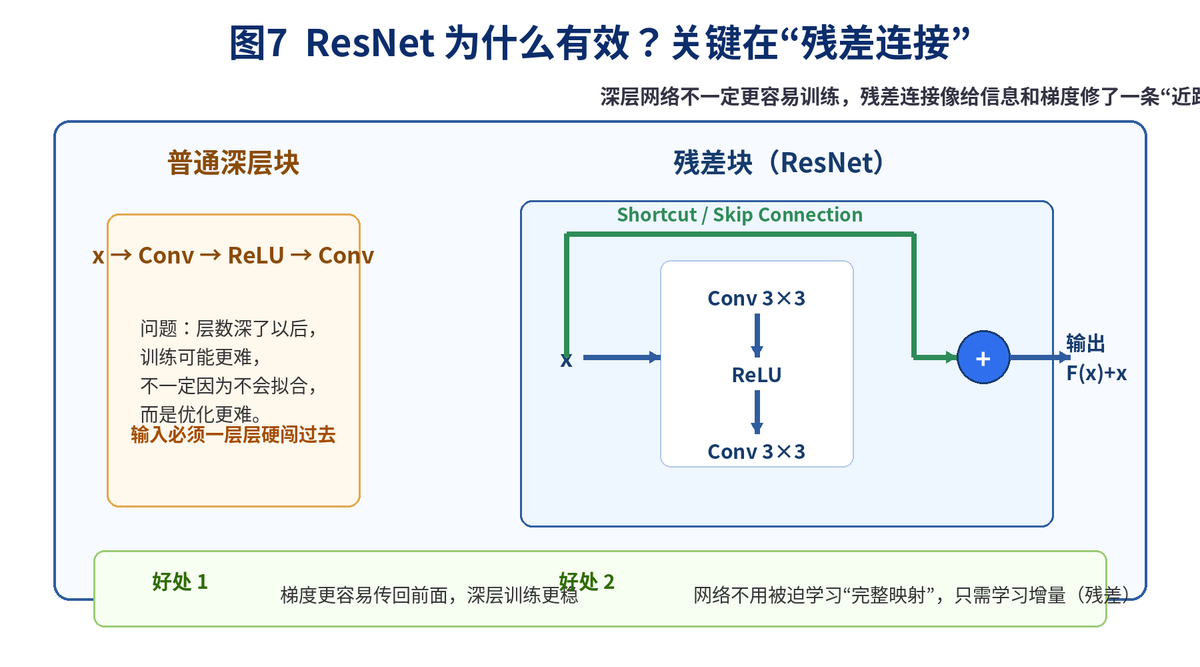
7.3 残差连接到底解决了什么?
让梯度更容易往前传,缓解深层网络训练困难;
如果某些层暂时学不到有效变换,至少还能保留输入本身,不至于彻底拖后腿;
使得构建更深的网络成为可能。
所以面试问到"ResNet 的残差连接有什么用",你可以概括为:它通过 shortcut 让网络更容易学习残差映射,改善深层网络优化难题,使更深的 CNN 更容易训练。
8. CNN 面试高频追问,怎么答更稳?
8.1 如果被问"CNN 为什么适合图像?"
你可以答:因为图像有明显的空间局部结构,同样的特征会在不同位置重复出现。CNN 通过局部感受野和参数共享,既符合图像规律,又能大幅减少参数量。
8.2 如果被问"卷积层和池化层分别做什么?"
卷积层负责提特征,池化层负责压缩尺寸和保留重点信息。卷积层有可学习参数,池化层通常没有。
8.3 如果被问"1×1 卷积、VGG、ResNet 三者分别代表什么?"
1×1 卷积:主要处理通道,常用于压缩、扩展和特征融合。
VGG:代表"小卷积核堆深网络"的设计思想。
ResNet:代表"残差连接解决深层网络训练难题"的设计思想。
9. 一段可以直接背的面试回答
如果面试官让你简单介绍 CNN,你可以这样说:
卷积神经网络是一类特别适合图像任务的神经网络。它的核心思想是通过卷积层在局部区域上滑动卷积核,逐层提取从边缘、纹理到高级语义的特征。CNN 的关键优势在于局部感受野和参数共享,这让它比普通全连接网络更适合处理有空间结构的数据。典型 CNN 结构一般包括卷积层、激活函数、池化层和分类头。卷积层负责提特征,池化层负责压缩尺寸。1×1 卷积主要用于通道压缩和融合。VGG 强调用多个 3×3 卷积堆深网络,ResNet 则通过残差连接缓解深层网络训练困难。
这段话的好处是:定义、核心思想、层结构、关键组件、经典模型,全都覆盖到了。
10. 总结
把 CNN 真正学明白,不是会背"卷积、池化、全连接"几个名词,而是要搞懂背后的设计理由:
为什么图像任务需要局部感受野;
为什么参数共享能让模型更省、更稳;
为什么池化要压缩尺寸;
为什么 1×1 卷积主要处理通道;
为什么 VGG 选择大量 3×3 卷积;
为什么 ResNet 要加 shortcut 做残差学习。
当你把这些问题讲顺了,CNN 这一块在面试里基本就不会慌。真正的高分回答,从来不是堆公式,而是把结构、原因和取舍讲明白。