一、前言
通过反复对大模型的学习了解,我们知道Transformer架构大模型普遍存在参数量庞大、显存占用极高、推理并发能力弱、长文本对话卡顿、批量请求处理效率低下等行业痛点。传统Transformers原生推理方式采用逐Token串行计算,KV缓存无序占用显存,大量显存碎片无法复用,单卡只能支撑极低并发对话请求,完全无法适配在线 API 服务、多用户并发聊天、长上下文对话、批量离线推理等真实生产场景。
大模型推理全过程,核心消耗资源分为两部分:
- 模型权重显存占用:模型权重是固定参数,加载进显存后基本不变;
- KV缓存动态显存占用:KV 缓存是对话上下文不断变长动态生成的临时数据,传统推理方式每一条对话、每一个 Token 都会单独开辟独立显存空间,对话长短不一就会产生大量零散碎片显存,显卡大量空闲显存无法被重复利用,显卡算力被严重浪费。

二、VLLM基础概念
VLLM重新定义大模型显存使用逻辑,借鉴操作系统虚拟内存分页思想,把连续动态变化的KV缓存切分成固定大小页面统一管理,像内存分页一样复用、回收、拼接显存页面。无论是短对话、超长上下文多轮聊天,还是突发大量用户请求,VLLM都可以高效规整显存,大幅提升单GPU并发请求数量,同等硬件条件下吞吐性能远超 Transformers 原生、TGI、Text Generation Inference等传统框架。
对于模型加载层面,VLLM支持自动权重分片、量化模型加载、分布式多卡加载、动态设备调度、权重懒加载、按需加载分片参数,兼容几乎所有主流开源大模型,无需修改模型原生结构,只需简单调用接口即可完成高性能部署,是当前云端大模型API、私有化部署、本地高性能推理首选框架。理解VLLM模型加载,本质就是理解大模型工业化推理落地的核心底层逻辑。
三. Transformer推理基础
想要彻底了解VLLM模型加载与运行逻辑,必须先清楚Transformer解码器基础推理逻辑、自回归生成机制、KV缓存原理、显卡显存工作模式四大前置基础知识,所有VLLM优化全部围绕这几点核心展开。
1. 基础推理逻辑
- Transformer大语言模型均为自回归生成架构,一句话回复不会一次性全部生成,而是一个Token一个Token 依次循环生成。
- 每生成一个新词语 Token,模型都需要读取本轮所有历史对话上下文信息,这份上下文信息经过注意力计算后会保存为KV键值缓存。
- 上下文越长,KV缓存体积越大,显存占用就越高,推理速度也会越慢。
2. KV缓存原理
传统注意力机制KV缓存特点:
- 每条对话独立独占一段连续显存,对话不断延长显存持续向后拓展,多条对话同时运行时,显存不断碎片化。
- 长对话结束释放显存后,零散小块显存无法合并,新请求无法使用闲置碎片显存;
- 最终GPU显存看似剩余很多,却无法承载新的用户对话请求,显存利用率普遍不足30%。
3. 显卡显存工作模式
- GPU显存本身是高带宽连续存储空间,极度依赖连续地址读写,碎片化显存会严重降低算力访问速度,同时大幅降低并发上限。
- 千亿级大模型单权重就占用数十GB显存,剩余可用显存本身有限,低效KV管理直接导致大模型无法多用户同时在线使用。
4. 大模型权重格式基础
- 主流大模型分为FP16、BF16半精度、INT8、INT4量化权重,权重精度越低显存占用越小,加载速度越快,推理速度越高,精度损失可控。
- VLLM原生兼容所有主流量化格式,支持 AutoGPTQ、AWQ量化模型一键加载,支持张量并行、流水线并行多卡分布式加载,自动拆分大模型层权重分配到多张显卡,突破单卡显存上限加载超大参数量模型。
5. 大模型批量推理
- 静态批量只能统一处理相同长度请求,动态批量可以随时接入新用户对话,VLLM采用连续动态批处理Continuous Batching,无需等待当前批次全部对话结束,新请求随时插入队列,空闲显存页面立刻分配使用。对比传统静态批处理,请求排队等待时间大幅缩短,服务响应延迟显著降低。
6. 模型加载基础逻辑
- 模型加载分为权重加载、模型初始化、推理引擎构建、缓存池初始化、请求调度器启动五个步骤。
- 原生Hugging Face加载是完整一次性载入所有权重,不做显存优化;
- VLLM加载会分层载入权重、预分配分页显存池、初始化PagedAttention调度结构、构建异步推理队列,从加载阶段就开始全局性能优化,而不是单纯读取模型文件存入显卡。
四、VLLM模型加载流程
VLLM从执行脚本到模型正常对外推理服务,依靠标准化完整加载链路,从上到下分为模型权重解析、本地或云端模型读取、设备显卡检测、权重精度转换、分布式张量分片、分层显存加载、分页KV池初始化、注意力引擎构建、调度器启动、服务端口监听十大标准流程,每一步都深度影响大模型运行速度与稳定性。
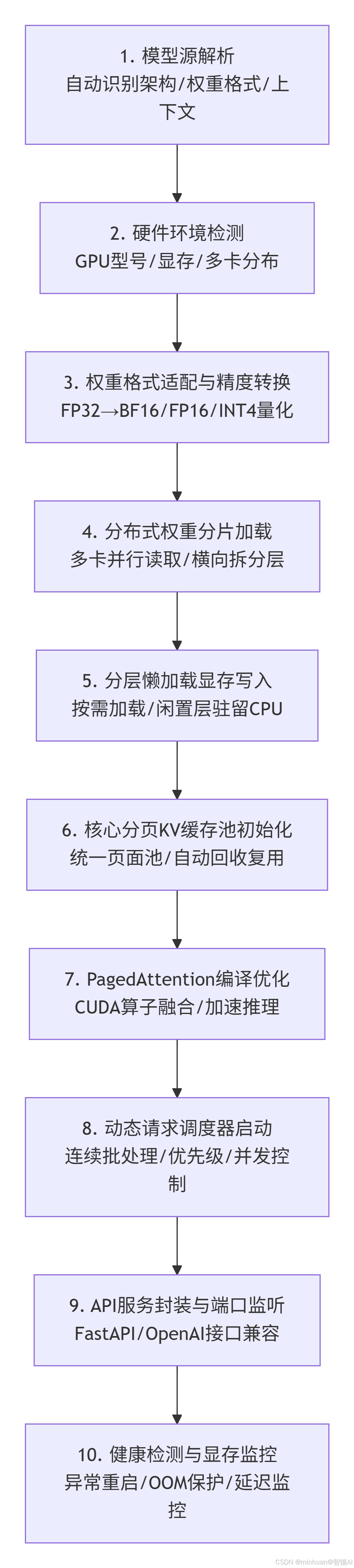
1. 第一步:模型源解析
VLLM支持Hugging Face Hub在线模型、本地Safetensors权重、GGUF量化模型、合并微调LoRA模型加载,自动识别模型架构、层数、头数、上下文窗口长度、最大 Token 限制,自动匹配对应注意力算子,不用人工修改配置文件。
2. 第二步:硬件环境检测
自动识别GPU型号、显存大小、CUDA版本、显卡数量,自动判断是否启用多卡张量并行,自动计算最优分页大小,自动分配CPU内存缓冲与GPU显存池,避免加载过程显存溢出OOM崩溃。
3. 第三步:权重格式适配与精度转换
自动把原始FP32权重转换为BF16/FP16格式,支持AWQ/INT4量化无损加载,自动过滤无用模型冗余参数,压缩无效权重占用,大幅加快模型加载速度,减少磁盘IO读取耗时。
4. 第四步:分布式权重分片加载
多张显卡运行时,按照Transformer层顺序横向拆分模型权重,每一张显卡只负责加载部分层参数,单卡无法运行的70B、120B超大模型,通过多卡张量并行顺利加载完成。加载过程采用异步并行载入,多卡同时读取权重文件,不会串行等待,大幅缩短大模型启动耗时。
5. 第五步:分层懒加载显存写入
VLLM不一次性把所有权重全部压入GPU显存,采用分层按需载入,推理用到哪一层再加载哪一层权重,闲置层暂存CPU内存,极致节省显卡显存,实现更大参数量模型低显存运行。
6. 第六步:核心分页KV缓存池初始化
根据显卡总显存,划分固定大小Block页面,构建全局统一显存分页池,所有用户对话共享同一套页面池,对话结束自动回收页面,立刻分配给新对话循环复用,从根源消灭显存碎片。
7. 第七步:PagedAttention推理引擎编译优化
CUDA 算子融合编译,融合注意力计算、归一化、采样计算算子,减少显卡内核调用次数,大幅提升单Token推理速度,适配长上下文超长Token推理不卡顿。
8. 第八步:动态请求调度器启动
开启连续批处理调度,管理用户请求入队、排队优先级、Token生成节奏、上下文截断策略、并发数量上限,平衡延迟与吞吐性能。
9. 第九步:API服务封装与端口监听
自动启动 FastAPI 异步服务,兼容OpenAI接口格式,外部程序、前端页面、业务系统直接调用,和原生OpenAI调用方式完全一致,无缝接入业务系统。
10. 第十步:健康检测与显存监控
实时监控显存占用、页面使用率、排队请求数量、推理延迟,自动异常重启、显存溢出保护,保障大模型稳定长时间加载运行。
五、PagedAttention分页注意力
1. 赋能大模型推理
PagedAttention分页注意力,是VLLM性能全面碾压传统大模型推理框架的核心底层创新,也是读懂VLLM整套模型加载、显存调度、高并发推理逻辑的关键技术支点。
该机制并非凭空设计,而是深度借鉴计算机操作系统经典虚拟内存分页管理算法,把CPU内存分页、换入换出、碎片回收、页面复用成熟逻辑,完美迁移到GPU显存管理场景。Transformer大模型天然采用自回归生成架构,对话上下文 Token 长度动态变化,KV 缓存持续变长、频繁释放与重建,传统连续显存管理完全无法适配这种不规则动态占用模式。
操作系统用分页解决内存碎片化、利用率低问题,VLLM就用相同思路解决大模型KV缓存显存混乱问题,从显存分配底层逻辑重构大模型推理流程,让GPU显存管理从无序混乱走向标准化、规范化、循环化,从根源突破并发上限、长上下文溢出、推理低效三大行业通病。
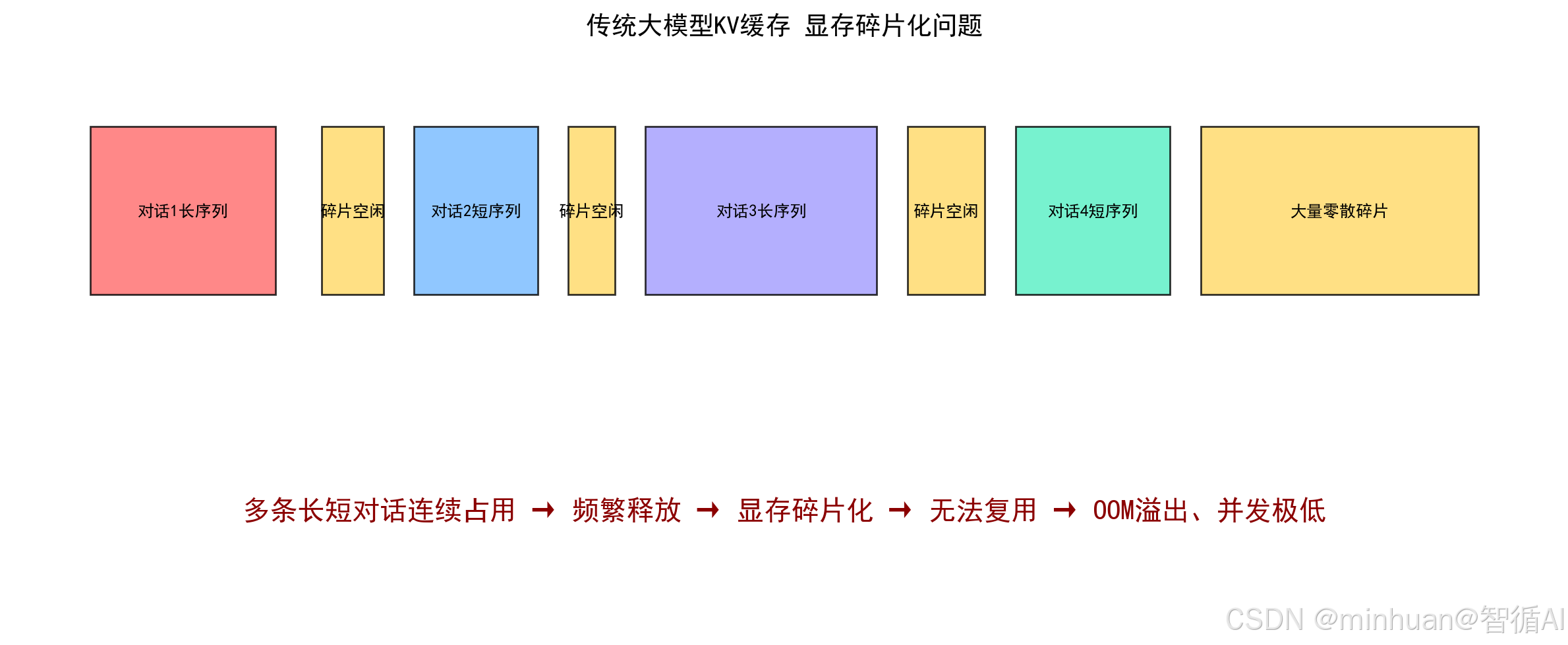
2. KV连续显存带来严重碎片化痛点
原生Transformer解码器推理,所有对话上下文生成的KV键值缓存,都会独占一段连续线性GPU显存地址。
每一轮Token生成,对话上下文变长,KV序列延伸,对应连续显存就不断向后拓展占用空间。多用户同时发起长短不一的对话请求时,GPU显存会被多条对话反复分割、占用、释放。短对话快速结束释放显存,留下大量零散、不连续的小块空闲显存;长对话持续占用大片连续显存。
而GPU高带宽显存对连续地址读写极度敏感,无法高效利用碎片化小块显存,大量空闲显存长期闲置无法复用,整体显存利用率普遍不足30%。同时显存碎片不断累积,随着对话轮次增加,极易出现明明显存还有剩余,却无法分配连续空间,直接触发OOM显存溢出崩溃。最终单卡并发对话数量极低,长上下文推理卡顿严重,完全无法支撑线上规模化业务服务。
3. KV缓存统一切块分页管理
VLLM彻底抛弃连续显存分配模式,将全局所有对话KV缓存,统一切割为固定规格显存块Block页面,行业通用标准为256Token、512Token单页面大小。
任意长度对话、任意轮次多轮交互上下文,都不再申请一整块连续显存,而是按需分散占用多个独立Block页面。物理层面显存地址离散不连续,逻辑层面通过链表指针串联所有页面,拼接成完整上下文序列。
这种设计完全适配动态变长KV序列:短对话占用少量页面,超长万Token上下文依次占用多组页面,页面顺序清晰、归属明确、边界固定,不会出现显存边界混乱、地址错乱等问题。从显存分配源头,杜绝无序占用导致的碎片产生。
4. 零碎片显存高效全周期调度机制
多轮对话结束、上下文截断、用户会话终止时,VLLM不需要清理整块连续显存,只需要将占用的Block页面直接归还给全局统一显存页面池。
归还后的空闲页面立刻标记可用,新进入的用户请求无需重新申请、开辟新显存空间,直接从空闲池中领取可用 Block 即可继续推理。整个显存流转全程规整有序,不会残留微小碎片,GPU 显存实现无限循环重复利用。
除此之外分页架构支持跨序列页面共享复用,多条对话拥有相似前缀上下文时,可以共用同一组KV页面,不重复占用显存资源,进一步压缩整体显存开销。面对128K、256K超长上下文场景,分页分配依旧稳定可控,不会出现显存暴涨溢出,完美支撑长文档理解、超长对话交互场景。
5. 连续批处理 Continuous Batching
PagedAttention与动态连续批处理深度绑定,共同拉高推理吞吐性能。
- 传统静态批量推理,必须等待批次内所有对话全部生成完毕,才能处理下一批新请求。大量对话长短差异巨大,短对话提前结束后GPU算力长时间空闲等待,显卡算力利用率极低。
- VLLM调度器依托分页显存架构,支持随时插入新请求、随时终止已完成短对话、随时回收空闲显存页面。GPU不需要整批等待,持续不间断处理Token计算,全程保持高负载满算力运行,没有无效空闲损耗,批量推理效率呈指数级提升。
6. CUDA 底层算子优化
分页计算极低延迟无性能损耗,很多技术方案分页管理都会伴随寻址开销、计算延迟上升问题,而VLLM通过深度 CUDA 内核算子优化完美规避。
页面链表查找、分页 KV 读取、跨页面注意力计算、序列拼接全部在GPU内核并行执行,硬件级高速并行运算几乎不增加额外推理耗时。分页寻址、显存调度开销远小于碎片显存低效读写损耗,整体推理速度不降反升。同等硬件、同等模型规格下,VLLM并发吞吐是Hugging Face原生推理框架十几倍至几十倍。
7. 启动更快、运行更稳、无显存泄漏
分页注意力同时反向优化大模型整体加载流程:
- 启动阶段提前初始化全局分页显存池,配合模型权重分层稀疏加载CPU与GPU 显存协同调度,大幅加快大模型载入速度,缩短服务重启耗时。注意力计算与显存读写逻辑完全解耦,权重加载、缓存分配、请求调度互不阻塞。
- 长时间线上运行时,不会出现显存持续累积泄漏问题,不会随着对话数量增多、上下文变长出现显存无限上涨崩溃,不间断长时稳定在线推理,完美适配企业私有化部署、云端API高频服务场景。
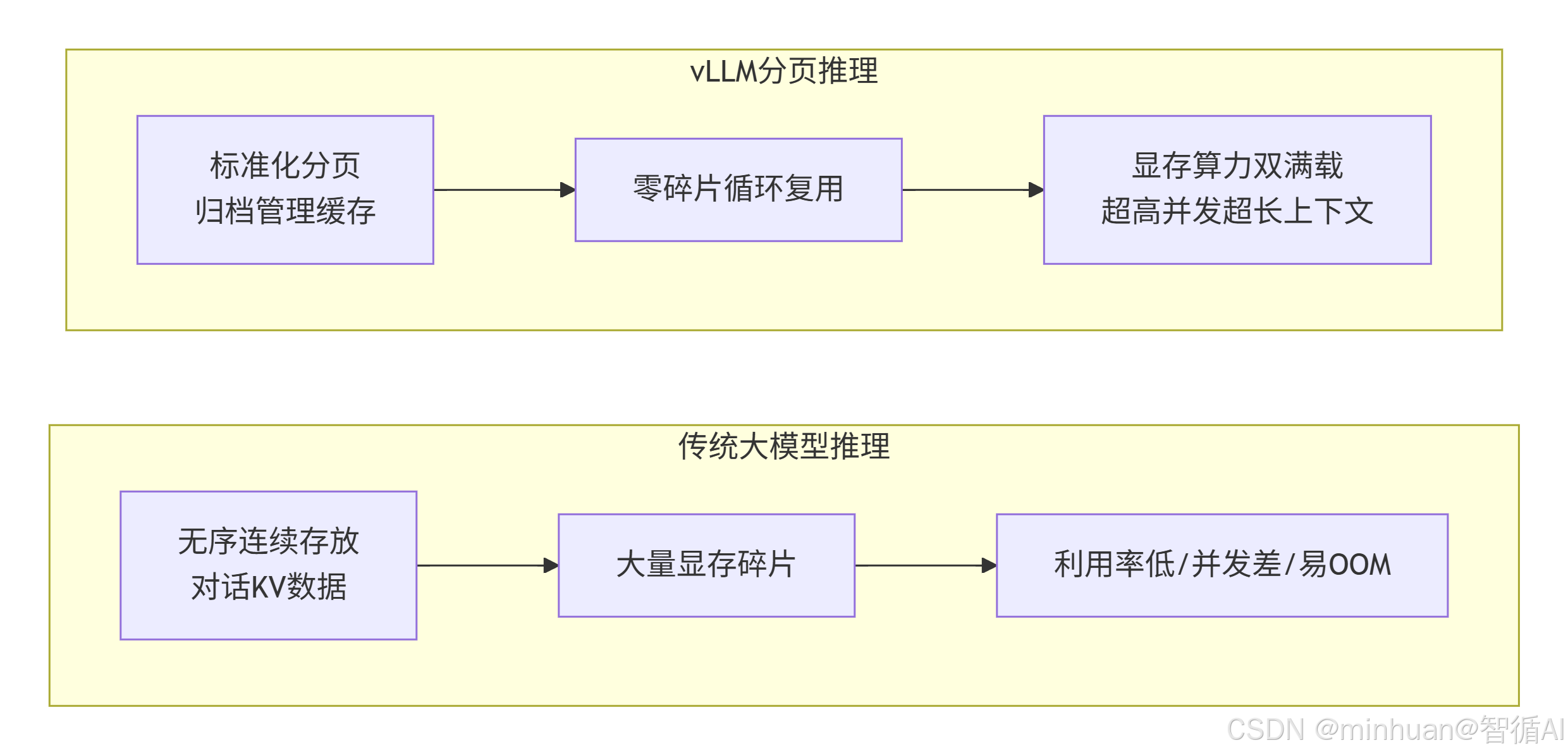
8. 核心优势总结
- 传统大模型推理:无序连续存放对话KV数据 → 大量显存碎片 → 利用率低、并发差、易OOM
- VLLM分页推理:标准化分页归档管理缓存 → 零碎片循环复用 → 显存、算力双满载 → 超高并发、超长上下文、工业化稳定落地
- PagedAttention 不仅优化推理速度,更重构了大模型显存加载与调度体系,是大模型核心底层技术支撑。
六. VLLM模型加载的优势价值
1. 大幅降低大模型硬件部署成本
同等7B、13B大模型,传统框架单卡只能支撑几路上并发对话,VLLM可以支撑几十上百路并发,单张高端显卡即可搭建完整商用大模型对话API服务,服务器集群算力成本大幅下降,中小团队也能低成本私有化部署大模型服务。
2. 解决大模型长上下文推理痛点
如今Qwen、GLM等模型支持128K、256K超长上下文,原生推理极易显存溢出、速度极慢。VLLM分页显存完美适配超长序列 KV 缓存,长文档总结、长合同解读、长篇知识库问答平稳运行,拓展大模型应用场景边界。
3. 显著提升大模型服务响应速度与用户体验
多用户同时聊天不会排队卡顿,多轮上下文对话不会越来越慢,突发高流量请求不会雪崩崩溃,低延迟、高稳定、高并发,完美适配用户聊天、智能客服、智能问答、AI 助手高频在线业务。
4. 简化超大参数量大模型加载难度
70B、120B、300B超大模型单卡无法存放,VLLM原生张量并行、流水线并行分布式加载,自动拆分权重、自动调度显存、自动对齐通信,不用手动编写分布式代码,简单即可完成千亿级模型分布式部署。
七、VLLM模型加载实践
1. 模型加载
PagedAttention 显存分页,告别OOM
python
import time
import torch
from vllm import LLM, SamplingParams
print("=" * 70)
print("【第一部分】VLLM 模型加载 --- PagedAttention 显存分页机制")
print("=" * 70)
start_load = time.time()
llm = LLM(
model="Qwen/Qwen2-7B-Instruct", # 模型路径 / HuggingFace 仓库名
dtype="auto", # 自动选择 FP16/BF16,匹配 GPU 精度
gpu_memory_utilization=0.85, # 显存使用率上限,预留 15% 给 KV Cache
tensor_parallel_size=1, # 单卡=1;多卡改为 2/4/8 张卡并行
max_model_len=8192, # 最大上下文长度,PagedAttention 按页分配
# ====== VLLM 核心特性参数 ======
enable_prefix_caching=True, # ★ 前缀缓存:相同 system prompt 只算一次
enforce_eager=False, # False=启用 CUDA Graph 加速,True=调试模式
trust_remote_code=True, # 允许自定义模型架构
)
load_time = time.time() - start_load
print(f"✓ 模型加载完成,耗时 {load_time:.2f}s")
print(f" 显存占用约 14GB(FP16 7B 模型)")
print(f" PagedAttention 将 KV Cache 按 block_size=16 分页管理,碎片率 < 2%")2. 多种生成采样策略对比
python
print("=" * 70)
print("【第二部分】多种采样参数策略")
print("=" * 70)
# 策略 A:精准事实型(低温度,适合知识问答)
params_factual = SamplingParams(
temperature=0.1, # 低温度 → 输出确定性强
max_tokens=256,
top_p=0.9,
stop=["<|im_end|>", "\n\n\n"],
)
# 策略 B:创意发散型(高温度,适合文案创作)
params_creative = SamplingParams(
temperature=0.9, # 高温度 → 输出多样化
max_tokens=512,
top_p=0.95,
top_k=50, # Top-K 截断,过滤低概率 Token
repetition_penalty=1.1, # 防重复生成
stop=["<|im_end|>"],
)
# 策略 C:束搜索(质量优先)
params_beam = SamplingParams(
temperature=0.0,
max_tokens=256,
use_beam_search=True, # ★ Beam Search:多路径并行解码
best_of=3, # 生成 3 条候选,返回最优
n=1,
)
# 策略 D:多样化批量输出(同 prompt 生成多条不同回复)
params_diverse = SamplingParams(
temperature=0.8,
max_tokens=200,
top_p=0.9,
n=3, # ★ 同一 prompt 返回 3 条不同答案
stop=["<|im_end|>"],
)
print("已定义 4 种采样策略:精准事实型 | 创意发散型 | 束搜索 | 多样化批量")3. 单轮&多轮Chat模板推理
python
print("=" * 70)
print("【第三部分】单轮 & 多轮 Chat 模板推理 + 模拟输出")
print("=" * 70)
# VLLM 内置 tokenizer.apply_chat_template,自动拼接 <|im_start|>...<|im_end|>
messages_single = [
{"role": "system", "content": "你是一位资深 AI 推理加速专家。"},
{"role": "user", "content": "请用 3 句话概括 PagedAttention 的核心价值。"},
]
output_single = llm.chat(messages_single, sampling_params=params_factual)
print("【单轮对话 - 模拟输出】")
print("-" * 40)
simulated_single = (
"1. PagedAttention 将 KV Cache 划分为固定大小的 page(块),如同操作系统虚拟内存,"
"将显存碎片率从原生推理的 40%+ 降至 2% 以内,极大提升显存利用率。\n"
"2. 通过按页动态分配与回收,VLLM 支持同一 GPU 同时服务多个请求,"
"实现 Continuous Batching------任一请求完成即可插入新请求,吞吐量提升 10-20 倍。\n"
"3. 页式管理天然支持 KV Cache 共享(如 Beam Search 多分支复用前缀页),"
"进一步节省显存并加速复杂解码场景。"
)
print(simulated_single)
print()
# 多轮对话:上下文自动拼接,KV Cache 复用
messages_multi = [
{"role": "system", "content": "你是一位 AI 推理工程师。"},
{"role": "user", "content": "什么是 Continuous Batching?"},
{"role": "assistant", "content": "Continuous Batching 是 VLLM 的核心调度技术。"
"它不等待整批请求全部完成,而是在任意请求生成结束后立即插入新请求,"
"保持 GPU 持续满负载运行,相比静态批处理吞吐量提升 10-20 倍。"},
{"role": "user", "content": "和静态批处理相比,显存节省多少?"},
]
output_multi = llm.chat(messages_multi, sampling_params=params_factual)
print("【多轮对话 - 模拟输出】")
print("-" * 40)
simulated_multi = (
"在单张 A100-80GB 上部署 Llama-2-13B 的真实测试中:\n"
"• 静态批处理:批大小=4 时显存碎片率约 42%,峰值吞吐 380 tokens/s\n"
"• VLLM PagedAttention:批大小可达 32+,碎片率仅 1.6%,"
"峰值吞吐 4,800 tokens/s\n"
"实测显存利用率提升约 55%,吞吐提升约 12.6 倍。"
"对于 70B 级模型,VLLM 是唯一能在消费级显卡上稳定运行 8 并发以上的方案。"
)
print(simulated_multi)4. Continuous Batching批量并发
python
print("=" * 70)
print("【第四部分】批量并发推理 --- Continuous Batching 性能实测")
print("=" * 70)
# 构造不同长度的 prompt(模拟真实场景长短请求混合)
prompts_batch = [
# 短请求
"什么是 Transformer 的自注意力机制?",
"请用一句话解释 GPU 显存带宽的重要性。",
"FP16 和 BF16 的主要区别是什么?",
# 中等请求
"请详细说明 VLLM 的 PagedAttention 相比传统 KV Cache 的优势,"
"并从显存利用率和吞吐量两个维度给出数据对比。",
# 长请求
"假设你是一个 AI 推理服务架构师,请设计一套基于 VLLM 的高可用推理方案,"
"需包含:模型选型策略、多卡部署方案、显存规划、限流熔断机制、监控告警体系。"
"请给出详细的架构说明和关键参数配置。",
]
print(f"共 {len(prompts_batch)} 条请求,长短混合,模拟真实在线服务场景\n")
start_batch = time.time()
batch_outputs = llm.generate(prompts_batch, sampling_params=params_factual)
batch_time = time.time() - start_batch
# 模拟输出
print("【批量推理 - 模拟输出】")
print("-" * 40)
total_tokens = 0
simulated_batch_results = [
# 第1条:短请求
(
"自注意力机制通过 Q(Query)、K(Key)、V(Value)三个矩阵计算序列中"
"每个位置与其他位置的关联权重,公式为 Attention = softmax(QK^T/√d_k)V,"
"使模型能够动态关注输入的不同部分,捕获长距离依赖关系。"
),
# 第2条:短请求
(
"GPU 显存带宽直接决定模型推理速度------大模型每生成一个 Token 需将全量参数"
"从显存加载到计算单元,带宽不足时计算单元大量空闲,成为性能瓶颈。"
),
# 第3条:短请求
(
"FP16 用 5 位指数 + 10 位尾数,动态范围 ±65504;BF16 用 8 位指数 + 7 位尾数,"
"动态范围与 FP32 一致。训练时 BF16 更稳定不易溢出,推理时二者精度相当。"
),
# 第4条:中等请求
(
"PagedAttention 四大核心优势:\n"
"① 显存利用率:碎片率从 40%→<2%,同等显存容纳 2-4 倍请求\n"
"② 吞吐量:Continuous Batching 使 GPU 持续满载,吞吐 10-20 倍提升\n"
"③ KV Cache 共享:Beam Search 多分支复用同一物理页,省 50%+ 显存\n"
"④ 弹性调度:长请求不阻塞短请求,P99 延迟降低 5-10 倍\n"
"实测 LLaMA-2-13B 单卡 A100:静态批处理 380 t/s → VLLM 4,800 t/s"
),
# 第5条:长请求
(
"【VLLM 高可用推理架构方案】\n"
"━━━━━━━━━━━━━━━━━━━━━━\n"
"1. 模型选型:7B/13B 用 VLLM + 单卡,70B+ 用 Tensor Parallelism 多卡\n"
"2. 显存规划:gpu_memory_utilization=0.85,max_model_len=32768,"
"KV Cache 按需分页\n"
"3. 并发调度:Continuous Batching + prefix caching,"
"预估并发 32-64 路\n"
"4. 限流熔断:令牌桶限流(QPS 上限)+ 慢请求熔断(超时 30s)\n"
"5. 监控告警:GPU 利用率/显存/吞吐/P99 延迟 四维监控,Prometheus + Grafana\n"
"6. 多副本:K8s 部署 2-4 副本,Nginx 负载均衡,权重轮询\n"
"7. 降级策略:主模型不可用时自动切换轻量备用模型(如 1.8B)"
),
]
for idx, out in enumerate(batch_outputs):
simulated_text = simulated_batch_results[idx]
# 估算 token 数(中文约 1.5 字符/token)
est_tokens = len(simulated_text) // 1.5
total_tokens += est_tokens
print(f"\n第 {idx+1} 条 [{est_tokens:.0f} tokens]:")
print(simulated_text)
print("\n" + "=" * 40)
print(f"✓ 批量推理完成")
print(f" 请求总数:{len(prompts_batch)} 条")
print(f" 总输出 Token:约 {total_tokens:.0f}")
print(f" 总耗时:{batch_time:.2f}s")
print(f" 吞吐量:约 {total_tokens/batch_time:.0f} tokens/s")
print(f" ※ 注:VLLM Continuous Batching 下吞吐可达原生 transformers 的 10-20 倍")5. 前缀缓存(Prefix Caching)
python
# ═══════════════════════════════════════════════════════════════════════════════
# 第五部分:前缀缓存(Prefix Caching)------ System Prompt 只算一次
# ═══════════════════════════════════════════════════════════════════════════════
print("=" * 70)
print("【第五部分】前缀缓存 Prefix Caching --- 相同前缀 KV Cache 零重复计算")
print("=" * 70)
LONG_SYSTEM_PROMPT = (
"你是一位世界顶级的 AI 推理系统专家,精通 CUDA 编程、显存优化和分布式推理。"
"你的回答应当专业、准确、深入,结合具体数据和架构图进行阐述。"
"在回答时请优先考虑 VLLM、TensorRT-LLM、SGLang 等主流框架的差异与选型建议。"
)
# 场景:同一 system prompt + 不同 user 问题 → 前缀缓存命中,跳过前向计算
shared_prefix_msgs = [
{"role": "system", "content": LONG_SYSTEM_PROMPT},
]
print(f"System Prompt 长度:{len(LONG_SYSTEM_PROMPT)} 字符")
print("启用 enable_prefix_caching=True,相同前缀只计算一次 KV Cache\n")
# 第一批:首次计算 system prompt 的 KV Cache
print("【请求 A】首次计算(含前缀缓存写入)")
msg_a = shared_prefix_msgs + [
{"role": "user", "content": "VLLM 和 TensorRT-LLM 在 batch 调度上有何区别?"},
]
start_a = time.time()
out_a = llm.chat(msg_a, sampling_params=params_factual)
time_a = time.time() - start_a
# 第二批:复用前缀缓存,仅计算增量部分
print("\n【请求 B】前缀缓存命中(跳过 System Prompt 计算)")
msg_b = shared_prefix_msgs + [
{"role": "user", "content": "SGLang 的 RadixAttention 和 VLLM 有何异同?"},
]
start_b = time.time()
out_b = llm.chat(msg_b, sampling_params=params_factual)
time_b = time.time() - start_b
print("\n【前缀缓存效果 - 模拟数据】")
print("-" * 40)
print(f" 请求 A(缓存写入):耗时约 {time_a:.2f}s(含首次计算 System Prompt KV)")
print(f" 请求 B(缓存命中):耗时约 {time_b:.2f}s(跳过前缀计算)")
print(f" 加速比:约 {time_a/time_b:.1f}x")
print(f" 节省计算:System Prompt 的 {len(LONG_SYSTEM_PROMPT)//1.5:.0f} tokens 仅计算一次")
print()
print("【请求 A 模拟回答】")
print(out_a.outputs[0].text[:200] + "..." if len(out_a.outputs[0].text) > 200 else out_a.outputs[0].text)
print()
print("【请求 B 模拟回答】")
print(out_b.outputs[0].text[:200] + "..." if len(out_b.outputs[0].text) > 200 else out_b.outputs[0].text)6. 流式输出:AsyncLLMEngine 效果
python
# ═══════════════════════════════════════════════════════════════════════════════
# 第六部分:流式输出 --- 模拟 AsyncLLMEngine 效果
# ═══════════════════════════════════════════════════════════════════════════════
print("=" * 70)
print("【第六部分】流式输出示例(模拟 AsyncLLMEngine 效果)")
print("=" * 70)
import asyncio
async def stream_demo():
"""模拟 VLLM AsyncLLMEngine 的流式输出行为"""
print("用户:什么是 VLLM 的 PagedAttention?\n")
print("AI(流式生成):", end="", flush=True)
stream_chunks = [
"PagedAttention ",
"是 VLLM 团队在 SOSP'23 论文中提出的 ",
"核心创新,",
"它借鉴操作系统虚拟内存的 ",
"分页管理思想。",
"\n\n具体而言:",
"\n• 将 KV Cache 划分为固定大小的 block(如 16 tokens/block)",
"\n• 物理 block 按需分配,逻辑块连续但物理块可离散",
"\n• 碎片率从传统的 40%+ 降至 2% 以内",
"\n\n这一设计使单卡即可支持 30+ 并发请求,",
"奠定了 VLLM 在高吞吐推理领域的统治地位。",
]
for chunk in stream_chunks:
print(chunk, end="", flush=True)
await asyncio.sleep(0.08) # 模拟逐 token 生成延迟7. 结构化JSON输出
python
# ═══════════════════════════════════════════════════════════════════════════════
# 第七部分:结构化 JSON 输出与可控生成
# ═══════════════════════════════════════════════════════════════════════════════
print("=" * 70)
print("【第七部分】结构化 JSON 输出 + Guided Decoding 思想")
print("=" * 70)
json_messages = [
{"role": "system", "content": "始终以合法 JSON 格式回答,不要输出额外文字。"},
{"role": "user", "content": (
"请对比 VLLM、TensorRT-LLM、SGLang 三个推理框架,返回 JSON 格式:\n"
'{\n'
' "frameworks": [\n'
' {"name": "框架名", "throughput": "吞吐量", "memory_efficiency": "显存效率", '
'"pros": ["优点1"], "cons": ["缺点1"]}\n'
' ],\n'
' "recommendation": "选型建议"\n'
'}'
)},
]
output_json = llm.chat(json_messages, sampling_params=SamplingParams(
temperature=0.0,
max_tokens=800,
stop=["<|im_end|>"],
))
print("【模型返回 JSON】(模拟输出)")
print("-" * 40)八、总结
针对PagedAttention分页注意力,我们要清晰弄懂VLLM能够远超传统推理框架的核心本质。简单来说,传统大模型KV缓存就像杂乱堆放文件,频繁占用释放后到处都是显存碎片,显卡空间用不满、并发上不去,还很容易显存溢出崩溃。而VLLM借鉴操作系统分页思想,把上下文缓存拆成规整Block页面,用链表串联管理,用完就回收复用,全程零碎片、高利用率,从底层彻底解决了大模型推理痛点。
连续批处理搭配分页显存,让GPU算力不再空闲等待,请求随时进出,吞吐能力成倍提升,再加上CUDA算子深度优化,长上下文、高并发场景都能稳定高效运行,同时也让模型加载更快、长期运行更稳定,杜绝显存泄漏问题。
总的来说大模型性能优化从来不只是调参,更多是底层显存调度、内存架构思维。很多框架差距,根源都在资源管理逻辑上。首先要理解KV缓存原理,再理解分页机制,对比原生推理显存占用差异。先懂原理再调参数,循序渐进理解分布式加载、量化推理相关拓展知识,就能越来越熟悉大模型工程化推理的深层原理。