在真实场景中,如果不在底层数据库预先准备好大量的商品,后续的自动化脚本在执行时就会因为数据量极小,导致没有任何性能瓶颈(慢查询)暴露,高并发压测也就失去了真实的意义
在准备大量数据开始测试前一定要先测试少量数据,防止中间程序代码出错运行失败,造成大量脏数据
1.使用python脚本造数据
安装python 环境的第三方库:
pip install requests利用接口自动化实现上节内容"新建数据"操作
import requests
import random
import time
# --- 全局配置 ---
BASE_URL = "http://localhost:8080"
# 先设定造 10 条数据试试水,成功后再改成 100000
TOTAL_COUNT = 10
def get_token():
"""1. 模拟 Swagger 登录,获取 Token"""
url = f"{BASE_URL}/admin/login"
payload = {
"username": "admin",
"password": "macro123"
}
response = requests.post(url, json=payload)
if response.status_code == 200 and response.json().get("code") == 200:
token = response.json().get("data").get("token")
token_head = response.json().get("data").get("tokenHead")
print("✅ 登录成功,成功拿到 Token!")
# 按照大厂规范,拼接 Bearer 和空格
return f"{token_head} {token}"
else:
print(f"❌ 登录失败: {response.text}")
return None
def create_products(token):
"""2. 带着 Token,循环调用创建商品接口"""
url = f"{BASE_URL}/product/create"
# 构造请求头,把通行证塞进去
headers = {
"Authorization": token,
"Content-Type": "application/json"
}
success_count = 0
print(f"🚀 开始疯狂造数据,目标:{TOTAL_COUNT} 条...")
for i in range(1, TOTAL_COUNT + 1):
# 💡 核心测开技巧:随机化数据。如果所有商品名字和货号都一样,不仅不符合业务,还可能触发数据库唯一索引冲突
random_suffix = random.randint(100000, 999999)
# 构造我们在 Swagger 里摸索出的必填 JSON
payload = {
"productCategoryId": 19, # 之前查到的分类 ID
"brandId": 111, # 之前查到的品牌 ID
"name": f"压测专属自动化商品_Python版_{random_suffix}", # 商品名称
"productSn": f"SN_{time.time()}_{random_suffix}", # 货号必须唯一
"publishStatus": 1, # 1为上架状态,确保C端能查到
"price": random.randint(99, 9999), # 随机价格
"stock": 10000, # 压测高并发不能缺库存
"keywords": "斯米兰一, 压测"
}
try:
response = requests.post(url, json=payload, headers=headers)
res_json = response.json()
if res_json.get("code") == 200:
success_count += 1
print(f"[{i}/{TOTAL_COUNT}] 插入成功: {payload['name']}")
else:
print(f"[{i}/{TOTAL_COUNT}] 插入失败,后端报错: {res_json}")
except Exception as e:
print(f"[{i}/{TOTAL_COUNT}] 请求发生异常: {e}")
print(f"🎉 脚本执行完毕!成功造出 {success_count} 条数据。")
if __name__ == "__main__":
# 业务流转调度
my_token = get_token()
if my_token:
create_products(my_token)运行:
注意:运行前需要保证idea里后端服务器打开,可以访问swagger 前端网站
在Pycharm 运行后截图:
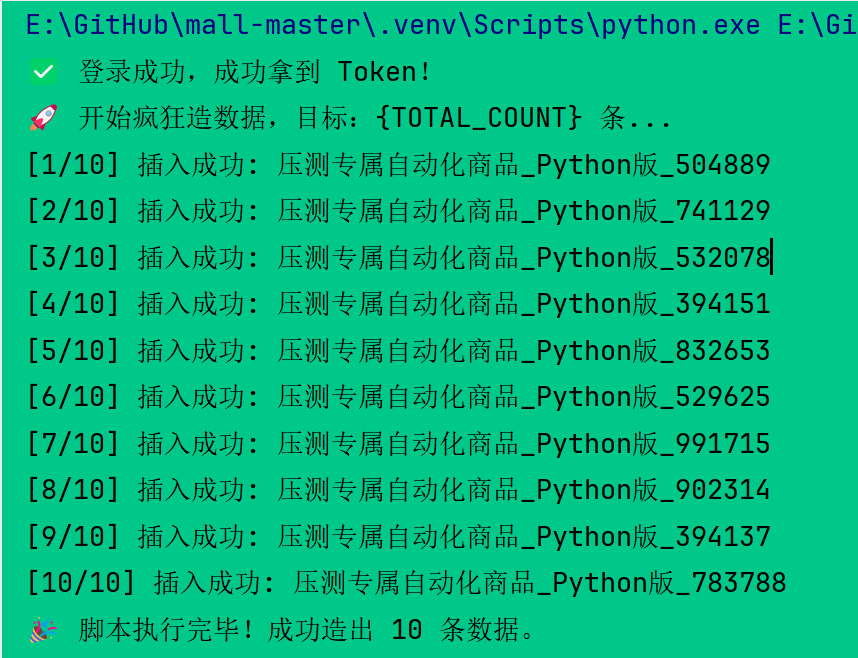
更新navicat 数据库信息,查看新建数据:
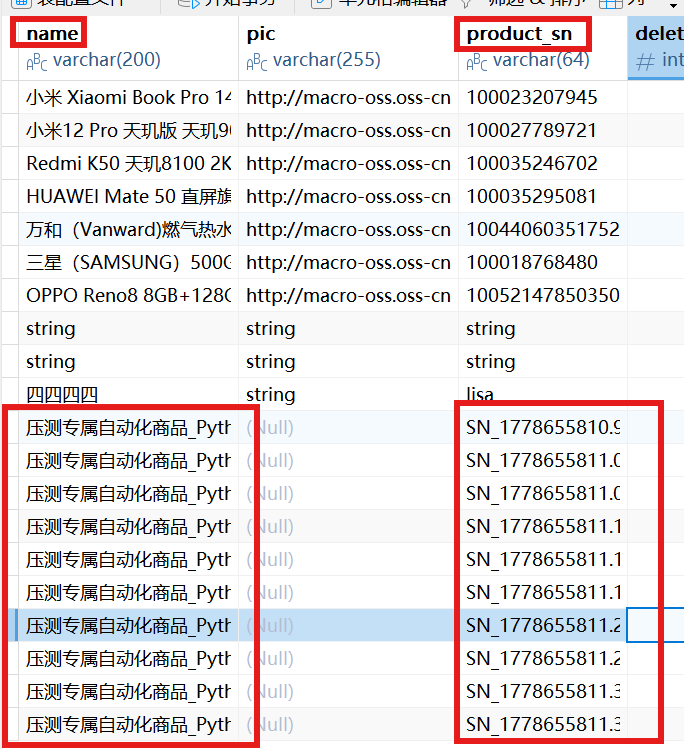
压测成功后将10W条数据打入虚拟机数据库
PyCharm,把 TOTAL_COUNT = 10 改成 TOTAL_COUNT = 100000
全部运行通过后量产数据就结束了!!!