在大数据时代,数据挖掘是从海量繁杂信息中提炼价值的核心利器,而数据预处理更是整个挖掘流程的基石与前提,预处理的质量直接决定后续建模分析与结论推演的精准度。由吕欣教授等编著的《数据挖掘》,立足大数据管理与应用专业知识体系,兼顾理论原理与实战场景,摒弃晦涩空洞的理论堆砌,用通俗易懂的逻辑、贴合专业学习与科研实操的案例,系统拆解数据预处理全流程核心知识。无论是高校相关专业学子入门数据挖掘、夯实基础功底,还是科研从业者开展数据分析、实战建模参考,这本著作都极具指导性与实用性,是深耕大数据领域不可错过的优质读物。
2.1 数据预处理 (Data Preprocessing)
2.1.1 数据预处理概要
🔍 为什么要预处理?
举个🌰:就像大厨做菜前必须洗菜、切菜、去皮一样,数据预处理就是把"脏乱差"的原始数据变成"干净、整齐"的可用食材的过程。
如果不处理直接跑模型?那就是经典的 "Garbage In, Garbage Out"(垃圾进,垃圾出)!🗑️
🧩 数据质量体检表(Data Quality)
在"做菜"前,先得给食材(数据)做个全身体检。定义2-1告诉我们要从这6个维度看数据健不健康:

| 维度 | 灵魂发问 | 翻车现场 |
|---|---|---|
| 完整性 | 信息全吗? | 填表时关键字段留白,缺胳膊少腿 |
| 一致性 | 逻辑对吗? | 同一个人在表A是男,在表B是女 🤷♂️ |
| 准确性 | 是真的吗? | 年龄填了200岁,明显是瞎填的 |
| 可靠性 | 来源信得过吗? | 路边小道消息 vs 官方统计局 |
| 可用性 | 能拿到手吗? | 存取方便,想用就能用 |
| 时效性 | 过期了吗? | 用大清律例来判现在的案子 |
🛠️ 预处理四大金刚!\[\]
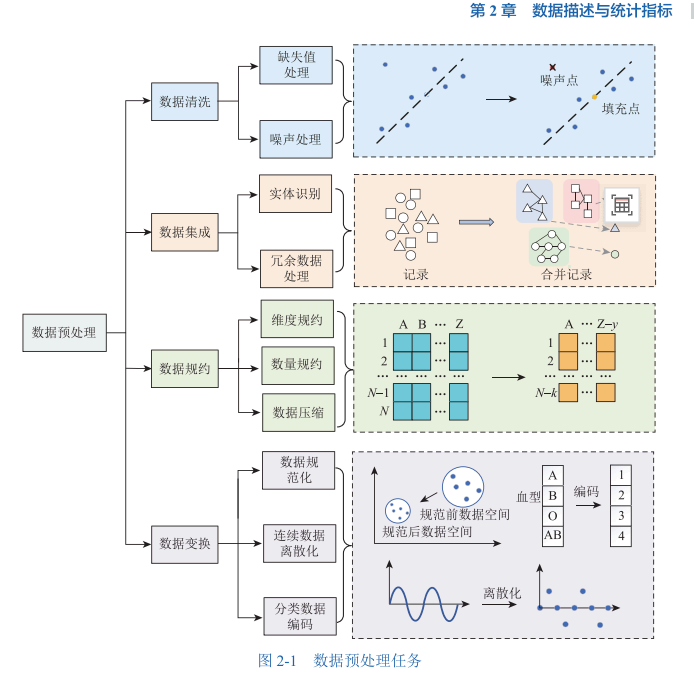
定义2-2提到的预处理主要任务,就是为了解决上面发现的那些毛病:
-
🚿 数据清洗(Data Cleaning):洗掉脏东西(缺失值、噪声)。
-
🔗 数据集成(Data Integration):把不同来源的数据捏在一起。
-
📉 数据规约(Data Reduction):给数据"瘦身",减量不减质。
-
🔄 数据变换 (Data Transformation):把数据整形成适合模型的模样。
2.1.2 数据清洗 (Data Cleaning)
核心目标:填补坑洞(缺失值)+ 消除杂音(噪声)。
🕳️ 1. 缺失值处理(Missing Values)
数据里居然有空值?这可是大忌!我们要根据情况对症下药:
💊 治疗方案大比拼
-
方案A:直接切除 (Deletion) 🔪
-
操作:把有空值的行或列直接删掉。
-
适用 :样本量巨大且缺失很少(<5%)时用整例删除 ;某列缺得太离谱(>70%)时用变量删除。
-
缺点:可能会误删有用信息,痛失好局。
-
-
方案B:人工填坑 (Manual Filling) ✍️
-
操作:靠专家经验手动填。
-
适用:数据量小、需要高精度时(比如医疗记录)。
-
缺点:累死人,还容易带主观偏见。
-
-
方案C:统计学填充 (Mean/Mode Filling) 📊
-
操作:
-
数值型:填平均值(大家都考80分,你也算80分)。
-
离散型:填众数(大家都填C,你也填C)。
-
-
缺点:会让数据变得"平庸",掩盖真实的波动。
-
-
方案D:模型预测 (Model Filling) 🤖
-
操作:用回归、决策树、随机森林等算法去"猜"缺失值。
-
评价 :最高级的玩法,利用了数据间的相关性,但要注意模型别选错了。
-
💡 延伸阅读 :还可以用插值法(线性插值、多项式插值、克里金插值),假装数据是连续的曲线,算出中间缺的那一点。
🔊 2. 噪声处理(Noise Handling)
噪声就是那些因为手抖、设备故障产生的"捣乱数据"。
降噪骚操作
-
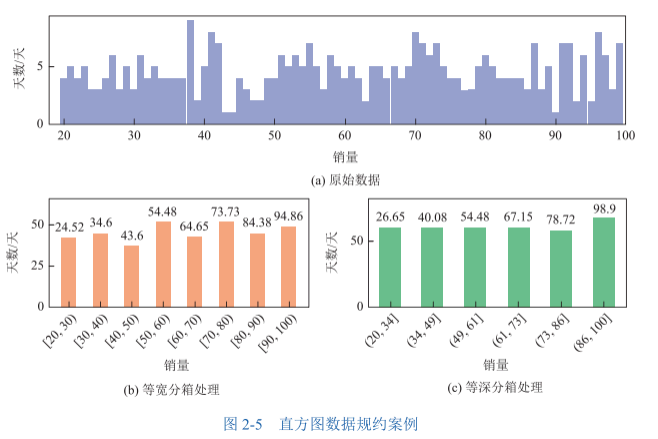
📦 分箱 (Binning):
-
原理:把相邻的数据扔进同一个箱子,用箱子的平均值或中位数代替大家。
-
等宽分箱 vs 等深分箱:一个是箱子宽度一样(比如0-10, 10-20),一个是箱子里装的数量一样(每箱装3个)。
-
效果:磨平棱角,局部平滑。
-
-
📈 回归 (Regression):
-
原理:找一条光滑的函数曲线去拟合数据点。
-
效果:离曲线太远的点就被视为噪声被"拉"回来了。
-
-
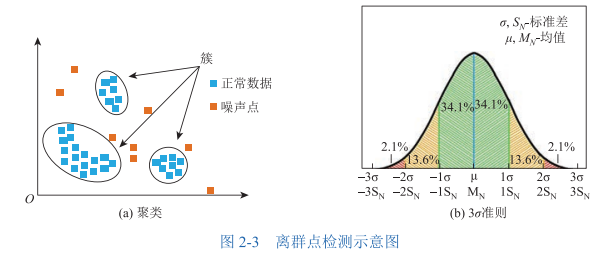
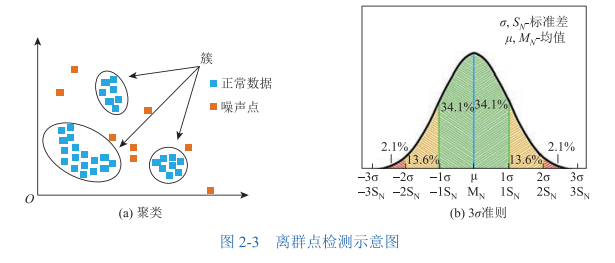
🧐 离群点检测 (Outlier Detection):
-
聚类法:大家都抱团,就你孤零零在外面?那你就是离群点!
-
3σ准则:在正态分布里,超过平均值3个标准差的家伙,概率只有0.3%,抓它!
-
2.1.3 数据集成 (Data Integration)
把来自不同数据库、不同文件的数据合并成一个大家庭。
🚧 拦路虎:实体识别问题
不同数据源描述同一个东西时,经常"鸡同鸭讲"(表2-3):
| 问题类型 | 翻车实录 | 解决方案 |
|---|---|---|
| 同名异义 | 表A的价格是进价,表B的价格是售价 |
改名!加注释区分 |
| 异名同义 | 表A叫gender,表B叫sex |
统一字段名(建立映射表) |
| 单位打架 | 表A用"米",表B用"厘米" | 统一度量衡(秦始皇点赞👍) |
| 格式不一 | 表A是2023-01-01,表B是2023/1/1 |
标准化格式 |
👯♀️ 冗余数据处理
-
重复数据 :完全一样的记录?👉 Ctrl+D 删除!
-
重复属性 :有了"出生年份"又来个"年龄"?👉 合并!
-
高相关属性:如果属性A和属性B的相关系数极高(比如身高和腿长),留一个就够了,多了浪费算力。
2.1.4 数据规约 (Data Reduction)
核心思想:把大数据变小,但尽量不丢信息。就像把高清图压缩成JPG,看着差不多,但体积小多了。
✂️ 1. 维度规约 (Dimensionality Reduction)
砍掉不重要的属性(列)。
-
主成分分析 (PCA):把原数据投影到新的空间,用少数几个"主成分"来代表原来的大部分信息。
-
属性子集选择:
-
合并属性 :把
A1, A2合成新属性A。 -
逐步向前/向后:像选秀一样,最好的留下,最差的淘汰。
-
决策树法:没出现在决策树里的属性,说明它不重要,删!
-
🔢 2. 数量规约 & 数据压缩
- 数量规约:用统计模型(如回归、直方图、聚类)替代实际数据。
- 数据压缩:无损压缩(zip)或有损压缩(小波变换)。
🍜 学习札记
做数据挖掘就像装修房子:
-
数据清洗 是打扫毛坯房:把烂尾的墙补上(填补缺失值),把地上的垃圾扫走(去噪声)。
-
数据集成 是打通房间:把客厅和阳台连起来(合并数据源),但这得注意别把承重墙砸了(实体识别错误)。
-
数据规约 是断舍离 :没用的家具全扔掉(维度规约),只留最核心的软装,房子看着大(效率高)还舒服!
笔记来源:裴同学