LangChain RAG实战------数据预处理篇:从文档加载到嵌入向量化
平台:LangChain + 阿里云百炼(Qwen)+ ChromaDB
本篇介绍RAG系统的数据预处理环节,涵盖文档加载、文本分割、嵌入模型三大核心模块。
目录
一、RAG技术概述
1.1 为什么需要RAG
大语言模型(LLM)虽然具备强大的生成能力,但也存在固有的局限性:
| 问题 | 说明 | RAG解决方案 |
|---|---|---|
| 知识截止日期 | 模型训练数据有时效限制 | 实时检索最新文档 |
| 幻觉问题 | 可能生成看似合理但错误的内容 | 基于真实文档内容生成 |
| 领域知识缺乏 | 通用模型缺乏垂直领域知识 | 注入领域文档作为上下文 |
| 信息无法更新 | 无法动态更新模型知识 | 直接更新向量数据库 |
1.2 RAG核心原理
RAG(Retrieval-Augmented Generation,检索增强生成)通过以下流程解决上述问题:
用户查询 → 向量化检索 → 相关文档匹配 → 上下文组装 → LLM生成 → 回答核心思想:将检索系统获取的相关信息作为上下文,帮助LLM生成更准确、更可靠的答案。
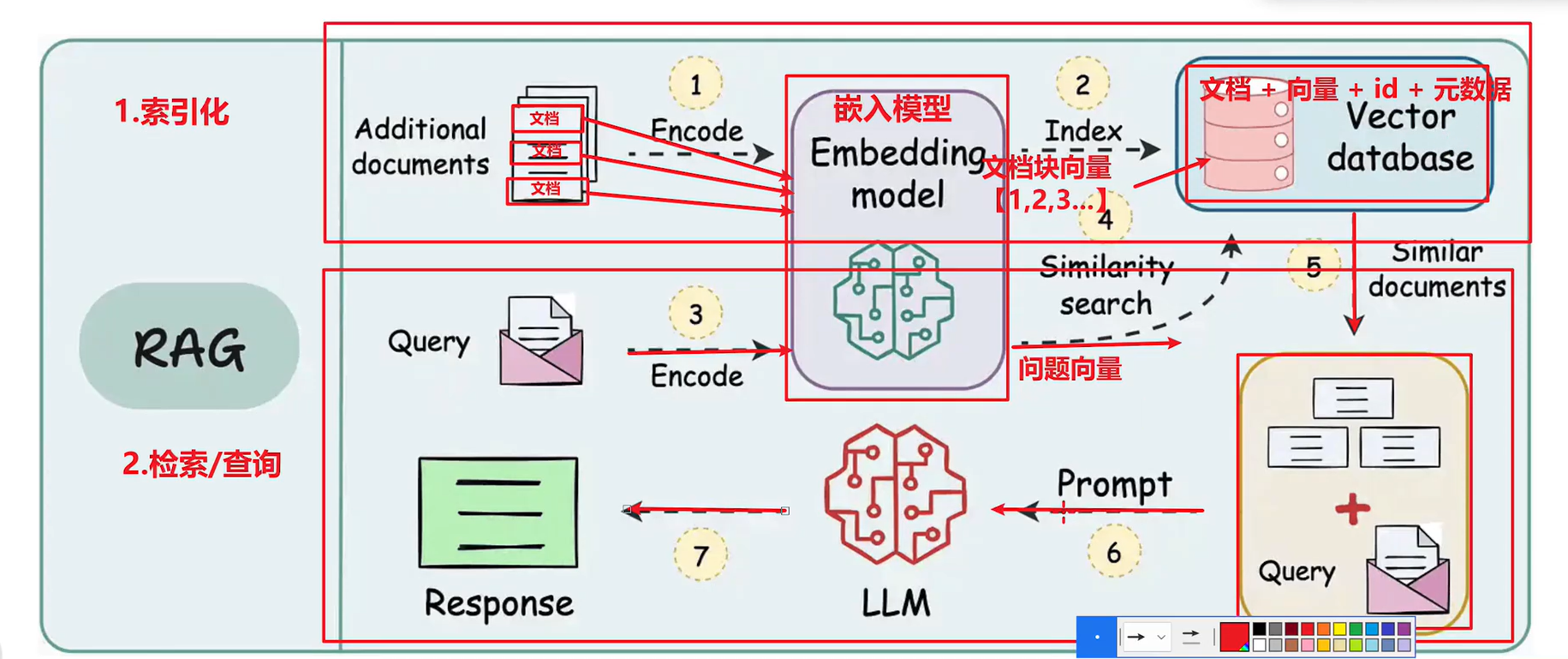
1.3 RAG系统架构
RAG系统主要分为两个阶段:
索引构建阶段(Indexing):
- 文档加载 → 文本分割 → 嵌入向量化 → 存储至向量数据库
检索生成阶段(RAG):
- 用户查询向量化 → 相似度检索 → 上下文组装 → LLM增强生成
二、环境安装与依赖
2.1 基础依赖安装
bash
pip install langchain langchain-openai langchain-core langchain-community
pip install openai chromadb
pip install pypdf python-docx tenacity
pip install tiktoken| 包名 | 说明 |
|---|---|
langchain |
核心框架 |
langchain-community |
第三方集成(ChromaDB等) |
chromadb |
向量数据库 |
pypdf |
PDF文档解析 |
python-docx |
Word文档解析 |
tiktoken |
Token计数工具 |
2.2 环境变量配置
python
import os
# 阿里云百炼 API 配置
os.environ["DASHSCOPE_API_KEY"] = "sk-xxxxxxxxxxxxxxxx"
# OpenAI兼容接口配置
OPENAI_API_BASE = "https://dashscope.aliyuncs.com/compatible-mode/v1"三、文档加载器
3.1 LangChain文档加载器概述
LangChain提供了丰富的文档加载器,支持多种格式:
| 加载器 | 支持格式 | 适用场景 |
|---|---|---|
PyPDFLoader |
论文、技术文档 | |
Docx2txtLoader |
Word (.docx) | 办公文档 |
TextLoader |
TXT | 纯文本 |
UnstructuredHTMLLoader |
HTML | 网页内容 |
CSVLoader |
CSV | 表格数据 |
3.2 PDF文档加载
python
# 01_document_loader.py
from langchain_community.document_loaders import PyPDFLoader
from langchain.schema import Document
# 加载单个PDF文件
loader = PyPDFLoader("document/sample.pdf")
pages = loader.load()
# 加载多个PDF文件
from langchain_community.document_loaders import DirectoryLoader
loader = DirectoryLoader(
path="documents/",
glob="*.pdf",
loader_cls=PyPDFLoader
)
documents = loader.load()
# 查看文档内容
for page in pages:
print(f"页码: {page.metadata['page']}")
print(f"内容: {page.page_content[:200]}...")
print("-" * 50)3.3 Word文档加载
python
# 01_document_loader.py
from langchain_community.document_loaders import Docx2txtLoader
loader = Docx2txtLoader("document/report.docx")
documents = loader.load()
for doc in documents:
print(doc.page_content)3.4 文本文件加载
python
# 01_document_loader.py
from langchain_community.document_loaders import TextLoader
loader = TextLoader("document/readme.txt", encoding="utf-8")
documents = loader.load()3.5 加载结果格式
LangChain的文档加载器返回Document对象列表,每个文档包含:
python
class Document:
page_content: str # 文档内容文本
metadata: dict # 元数据(来源、页码等)
# 示例
document = Document(
page_content="这是文档的文本内容...",
metadata={
"source": "document/sample.pdf",
"page": 0,
"total_pages": 10
}
)四、文本分割策略
4.1 为什么需要文本分割
LLM有token数量限制,且:
- 完整文档太长:无法全部放入上下文
- 检索效率:小块文档更易于精确匹配
- 语义完整性:适当的分块保持语义连贯
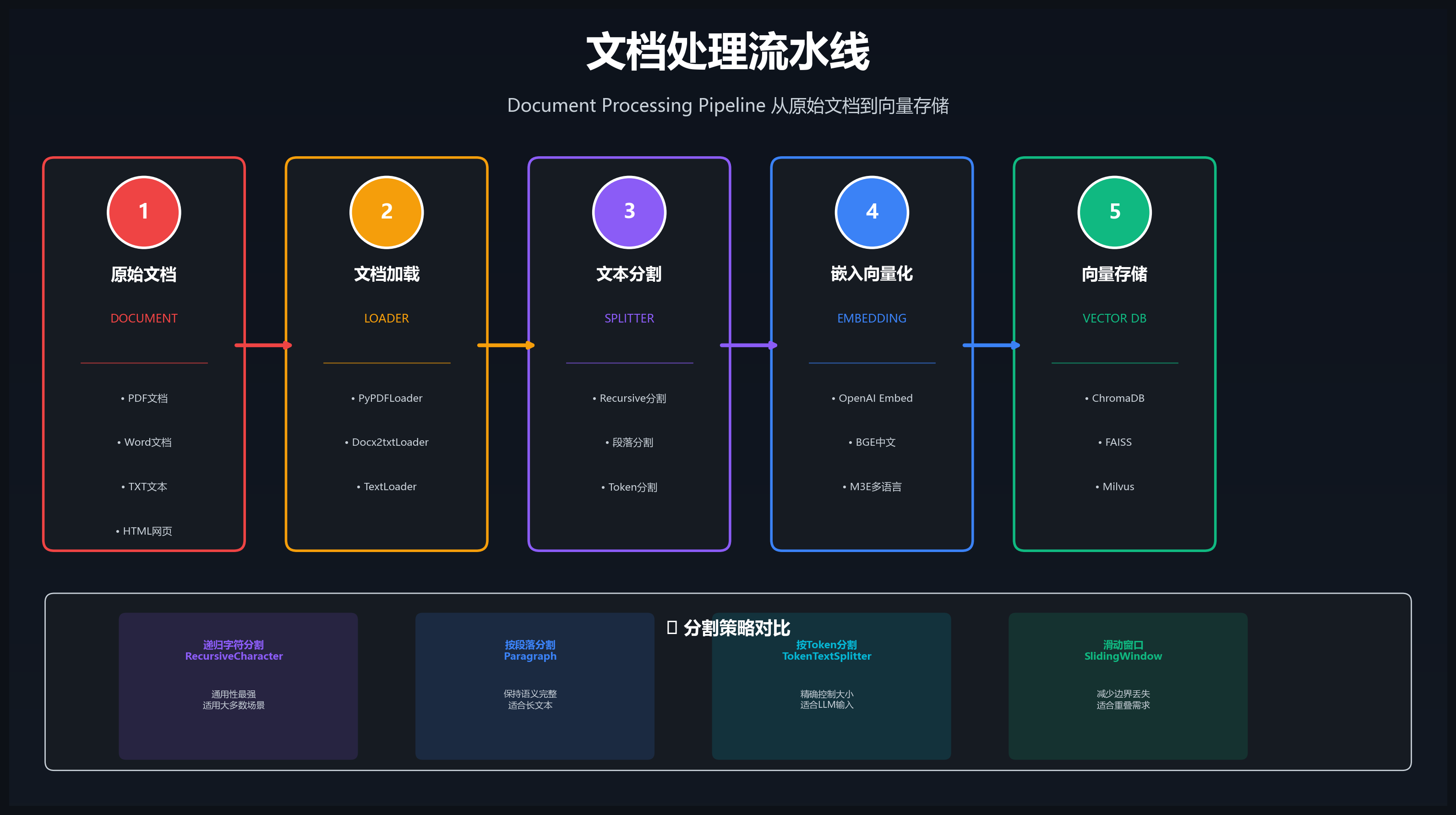
4.2 分割策略对比
| 策略 | 原理 | 优点 | 缺点 |
|---|---|---|---|
| 递归字符分割 | 按字符递归切分 | 通用性强 | 可能切断语义 |
| 按段落分割 | 按自然段落边界 | 保持完整语义 | 块大小不均匀 |
| 滑动窗口 | 重叠切分 | 减少边界丢失 | 冗余信息多 |
| Token分割 | 按token数切分 | 精确控制大小 | 中途切断词 |
4.3 RecursiveCharacterTextSplitter
LangChain推荐使用递归字符分割器:
python
# 02_text_splitter.py
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 创建分割器
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, # 块大小(字符数)
chunk_overlap=50, # 重叠大小(减少边界丢失)
length_function=len, # 长度计算函数
separators=["\n\n", "\n", "。", ",", " ", ""] # 分割符优先级
)
# 分割文档
texts = text_splitter.split_documents(documents)
print(f"原始文档数: {len(documents)}")
print(f"分割后块数: {len(texts)}")
# 查看分割结果
for i, chunk in enumerate(texts[:3]):
print(f"\n--- Chunk {i+1} ---")
print(f"内容: {chunk.page_content[:100]}...")
print(f"元数据: {chunk.metadata}")4.4 按段落分割
python
# 02_text_splitter.py
from langchain.text_splitter import NLTKTextSplitter
text_splitter = NLTKTextSplitter(
separator="\n\n", # 按双换行分割(段落)
chunk_size=1000,
chunk_overlap=100
)
texts = text_splitter.split_text(long_text)4.5 Token感知分割
python
# 02_text_splitter.py
from langchain.text_splitter import TokenTextSplitter
text_splitter = TokenTextSplitter(
chunk_size=500, # 块大小(token数)
chunk_overlap=50, # 重叠token数
encoding_name="cl100k_base" # OpenAI编码
)
texts = text_splitter.split_text(text)4.6 自定义分割器
python
# 02_text_splitter.py
from langchain.text_splitter import TextSplitter
class ChineseTextSplitter(TextSplitter):
"""中文文本分割器"""
def __init__(self, **kwargs):
super().__init__(**kwargs)
def split_text(self, text: str) -> list[str]:
# 按中文标点和换行分割
import re
paragraphs = re.split(r'[\n。!?\n]+', text)
chunks = []
for para in paragraphs:
if para.strip():
if len(para) <= self._chunk_size:
chunks.append(para)
else:
# 进一步分割
sub_chunks = self._split_long_text(para)
chunks.extend(sub_chunks)
return chunks
def _split_long_text(self, text: str) -> list[str]:
chunks = []
start = 0
while start < len(text):
end = start + self._chunk_size
chunk = text[start:end]
chunks.append(chunk)
start = end - self._chunk_overlap
return chunks五、嵌入模型与向量化
5.1 嵌入模型原理
嵌入(Embedding)将文本转换为稠密向量,使语义相似的文本在向量空间中距离更近:
文本 → 嵌入模型 → 向量 [0.12, -0.34, 0.56, ..., 0.89]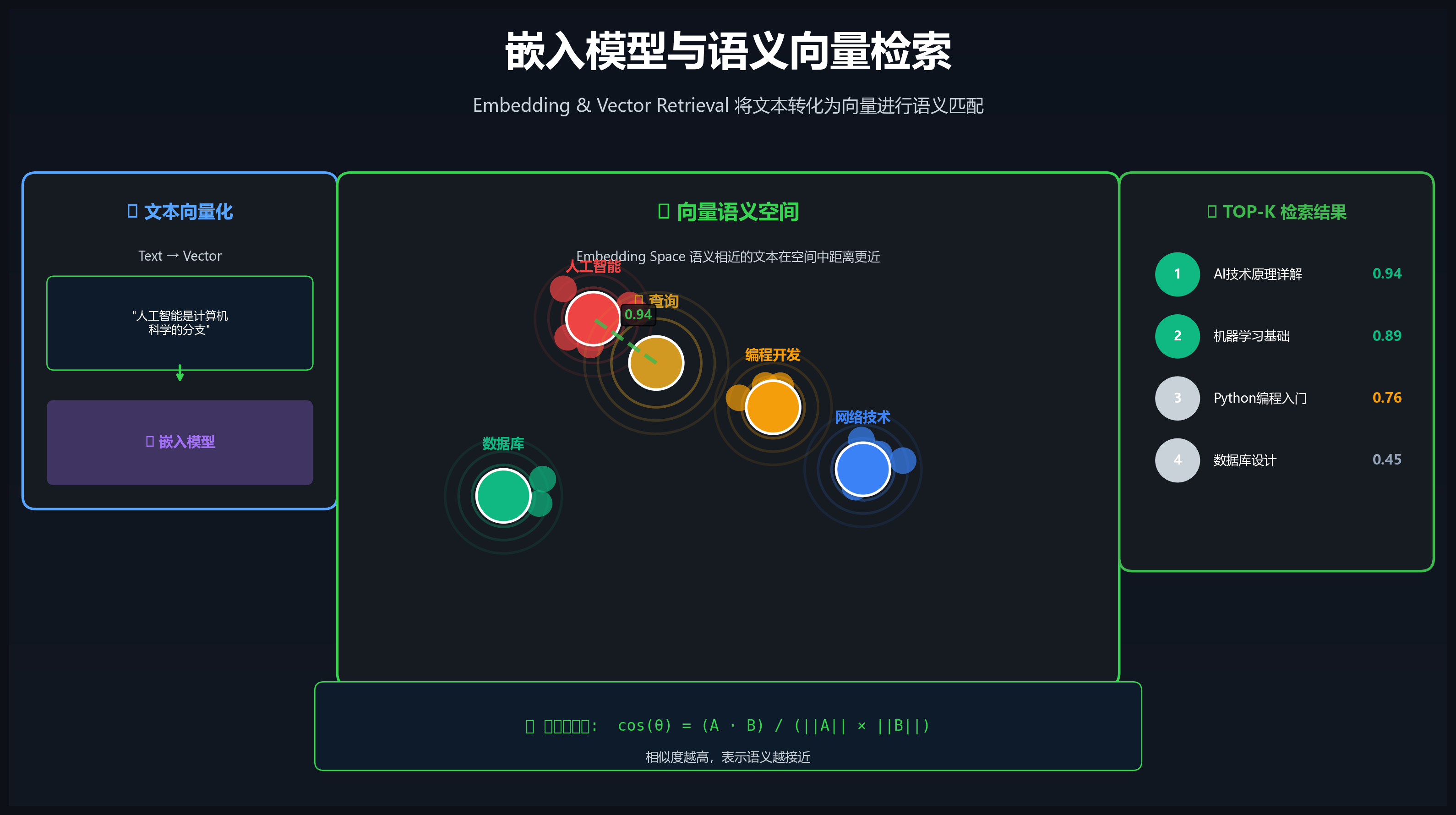
5.2 常用嵌入模型
| 模型 | 提供商 | 维度 | 特点 |
|---|---|---|---|
text-embedding-ada-002 |
OpenAI | 1536 | 通用性强 |
text-embedding-3-small |
OpenAI | 1536/256 | 高效轻量 |
text-embedding-3-large |
OpenAI | 3072 | 高精度 |
m3e-base |
MokaAI | 768 | 中文优化 |
bge-base-zh |
BAAI | 768 | 中英文双语 |
5.3 OpenAI嵌入
python
# 03_embedding.py
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(
model="text-embedding-3-small",
openai_api_key=os.getenv("DASHSCOPE_API_KEY"),
openai_api_base="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
# 单文本嵌入
query = "什么是人工智能?"
vector = embeddings.embed_query(query)
print(f"向量维度: {len(vector)}")
print(f"向量前5位: {vector[:5]}")
# 多文本嵌入
texts = ["文本1", "文本2", "文本3"]
vectors = embeddings.embed_documents(texts)
print(f"嵌入数量: {len(vectors)}")5.4 本地嵌入模型(中文优化)
python
# 03_embedding.py
from langchain_community.embeddings import HuggingFaceBgeEmbeddings
# BAAI BGE中文嵌入模型
embeddings = HuggingFaceBgeEmbeddings(
model_name="BAAI/bge-base-zh-v1.5",
model_kwargs={'device': 'cpu'},
encode_kwargs={'normalize_embeddings': True}
)
# 使用本地模型进行嵌入
query = "人工智能的应用领域"
vector = embeddings.embed_query(query)
print(f"向量维度: {len(vector)}")5.5 向量相似度计算
python
# 03_embedding.py
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
def calculate_similarity(vec1, vec2):
"""计算余弦相似度"""
return cosine_similarity([vec1], [vec2])[0][0]
def euclidean_distance(vec1, vec2):
"""计算欧氏距离"""
return np.linalg.norm(np.array(vec1) - np.array(vec2))
# 示例
vec_a = [0.1, 0.2, 0.3, 0.4]
vec_b = [0.11, 0.21, 0.31, 0.41]
vec_c = [0.9, 0.8, 0.7, 0.6]
print(f"A vs B 相似度: {calculate_similarity(vec_a, vec_b):.4f}") # 高相似
print(f"A vs C 相似度: {calculate_similarity(vec_a, vec_c):.4f}") # 低相似本篇总结
本篇介绍了RAG系统的数据预处理三大模块:
| 模块 | 核心组件 | 作用 |
|---|---|---|
| 文档加载 | PyPDFLoader、Docx2txtLoader | 解析多种格式文档 |
| 文本分割 | RecursiveCharacterTextSplitter | 智能分块,保持语义 |
| 嵌入向量化 | OpenAI Embeddings、BGE | 文本转稠密向量 |
下篇预告 :《LangChain RAG实战------向量存储与检索篇》
将介绍向量数据库选择、语义检索实现、RAG Chain构建等核心内容。