一、FastText 介绍
1.作用:作为NLP工程领域常用的工具包,FastText有两大作用
① 进行文本分类
② 训练词向量
模型领域中起着承上启下的作用
上:transformer
下:训练模型 || 大模型
2.FastText工具包的优势
① fastText 工具包中内含的fastText模型 十分简单的网络结构
② 使用fastText模型训练词向量时使用层次softmax结构,来提升超多类别下的模型性能。
③ 由于fasttext模型过于简单无法捕捉词序特征, 因此会进行n-gram特征提取以弥补模型缺陷提升精度
3.FastText安装
优先用:pip install fasttext
报错就用:pip install fasttext-wheel
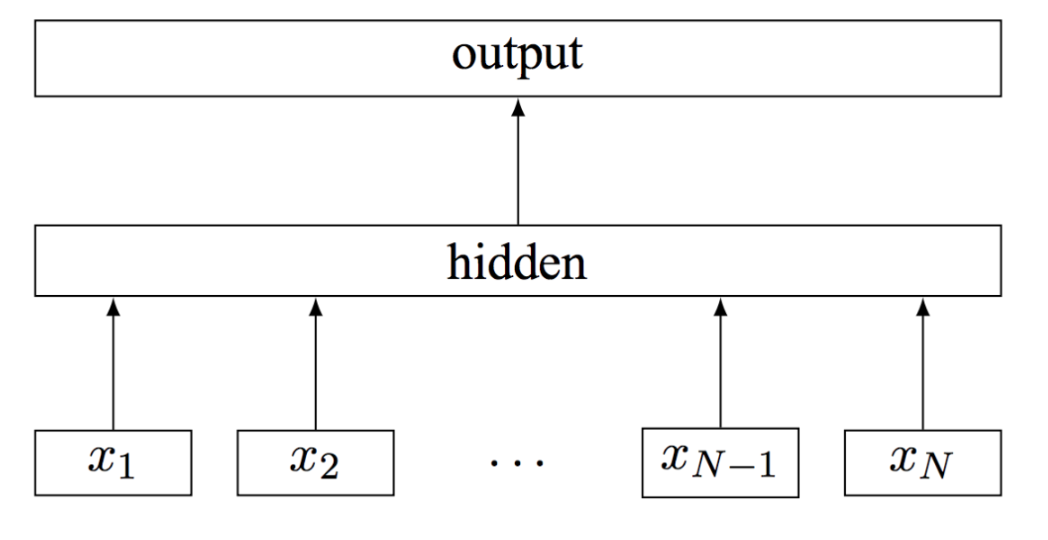
二、FastText 模型架构
FastText 模型架构和 Word2Vec 中的 CBOW 模型很类似, 不同之处在于, FastText 预测标签, 而 CBOW 模型预测中间词.
FastText的模型分为三层架构:
-
输入层: 是对文档embedding之后的向量, 包含N-gram特征
-
隐藏层: 是对输入数据的求和平均
-
输出层: 是文档对应的label
层次softmax(hierarchical softmax)
- 为了提高效率, 在fastText中计算分类标签概率的时候, 不再使用传统的softmax来进行多分类的计算, 而是使用哈夫曼树, 使用层次化的softmax来进行概率的计算.
二、FastText 文本分类
文本分类的过程¶
-
第一步: 获取数据
-
第二步: 训练集与验证集的划分
-
第三步: 训练模型
-
第四步: 使用模型进行预测并评估
-
第五步: 模型调优
-
第六步: 模型保存与重加载
API使用代码
python
# fasttext文本分类API的使用
import fasttext
# 1- 模型训练和预测
def demo01_base():
# 1- 模型训练
model = fasttext.train_supervised(input="data/cooking_train.txt")
# 2- 使用训练好的模型对数据进行预测
result1 = model.predict("Which baking dish is best to bake a banana bread ?")
print(result1)
result2 = model.predict("Why not put knives in the dishwasher?")
print(result2)
# 3- 模型测试
result = model.test(path="data/cooking_valid.txt")
print(result) # (3000, 0.15566666666666668, 0.06732016721925904) 样本条数 精确率 召回率
# 2- 数据基本处理:统一成大小写、标点符号前面加空格。。。
def demo02_preprocessing():
# 1- 模型训练
model = fasttext.train_supervised(input="data/cooking.pre.train")
# 2- 模型测试
result = model.test(path="data/cooking.pre.valid")
print(result)
# 3- 增加训练轮次
def demo03_epoch():
# 1- 模型训练
model = fasttext.train_supervised(input="data/cooking.pre.train",epoch=20)
# 2- 模型测试
result = model.test(path="data/cooking.pre.valid")
print(result)
# 4- 调整学习率
def demo04_lr():
# 1- 模型训练
model = fasttext.train_supervised(input="data/cooking.pre.train",epoch=20,lr=1)
# 2- 模型测试
result = model.test(path="data/cooking.pre.valid")
print(result)
# 5- 设置n-gram参数
def demo05_n_gram():
# 1- 模型训练
model = fasttext.train_supervised(input="data/cooking.pre.train",epoch=20,lr=1,wordNgrams=2)
# 2- 模型测试
result = model.test(path="data/cooking.pre.valid")
print(result)
# 6- 调整损失函数
def demo06_loss():
# 1- 模型训练
model = fasttext.train_supervised(input="data/cooking.pre.train",epoch=20,lr=1,wordNgrams=2,loss="hs")
# 2- 模型测试
result = model.test(path="data/cooking.pre.valid")
print(result)
# 7- 自动超参数调优
def demo07_auto():
# 1- 模型训练
"""
参数解释:
autotuneDuration:查找最优超参数组合的时间,最终找到的参数组合不一定是最优的
autotuneValidationFile:找到最优超参数组合,使用验证集数据对参数效果进行验证
"""
model = fasttext.train_supervised(
input="data/cooking.pre.train",
autotuneValidationFile="data/cooking.pre.valid",
autotuneDuration=60*2
)
# 2- 模型测试
result = model.test(path="data/cooking.pre.valid")
print(result)
# 8- 多标签多分类问题:将问题拆解为单标签多分类问题,loss损失函数需要设置为ova->one vs all
def demo08_ova():
# 1- 模型训练
# 注意:lr的学习率不要过大,如果过大会出现梯度消失/爆炸的情况
model = fasttext.train_supervised(input="data/cooking.pre.train",epoch=20,lr=0.1,wordNgrams=2,loss="ova")
# 2- 预测
"""
k:表示预测结果中目标值最多展示多少个。如果值为-1,那么是尽可能将所有的目标值全部都展示
threshold:阈值。如果预测的目标值的概率超过了threshold,那么才有可能显示出来
result1中输出的概率值是经过sigmoid计算后的结果,计算是__label__baking标签的概率以及不是__label__baking标签的概率。
多标签中每个标签的概率计算是相互独立的
"""
result1 = model.predict("Which baking dish is best to bake a banana bread ?",k=3,threshold=0.5)
print(result1)
result2 = model.predict("Which baking dish is best to bake a banana bread ?",k=-1)
print(result2)
# 3- 模型测试
result = model.test(path="data/cooking.pre.valid")
print(result)
# 9- 保存模型和重新加载模型
def demo09_savemodel():
# 1- 模型训练
model = fasttext.train_supervised(input="data/cooking.pre.train",epoch=20,lr=1,wordNgrams=2,loss="hs")
# 2- 保存训练好的模型
model.save_model("model/cooking_model.pkl")
# 3- 加载训练好的模型
model2 = fasttext.load_model("model/cooking_model.pkl")
result = model2.test(path="data/cooking.pre.valid")
print(result)
if __name__ == '__main__':
# 1- 模型训练和预测
# demo01_base() # (3000, 0.15566666666666668, 0.06732016721925904)
# 2- 数据基本处理
# demo02_preprocessing() # (3000, 0.172, 0.07438373936860314)
# 3- 增加训练轮次
# demo03_epoch() # (3000, 0.48733333333333334, 0.21075392821104225)
# 4- 调整学习率
# demo04_lr() # (3000, 0.5976666666666667, 0.2584690788525299)
# 5- 设置n-gram参数
# demo05_n_gram() # (3000, 0.596, 0.2577483061842295)
# 6- 调整损失函数
# demo06_loss() # (3000, 0.5946666666666667, 0.2571716880495892)
# 7- 自动超参数调优
# demo07_auto() # (3000, 0.536, 0.23180049012541445)
# 8- 多标签多分类问题
# demo08_ova() # (3000, 0.532, 0.23007063572149344)
# 9- 保存模型和重新加载模型
demo09_savemodel()